※ 질문 출처: https://github.com/VSFe/Tech-Interview
1. 쿠키와 세션
쿠키와 세션은 백엔드 레벨에서 State를 유지하기 위해 사용하는 개념이다. 일반적으로 백엔드의 API는 REST API로 구현되며 REST API는 HTTP를 사용한다. HTTP는 Stateless한 특징을 가지고 있는데, HTTP의 stateless 특성에도 불구하고 사용자 인증 유지와 같은 특정 상황에서 서버와 클라이언트에서 state를 저장할 필요가 발생한다. 이 경우 쿠키와 세션을 사용한다.
쿠키
쿠키는 브라우저에서 저장하는 키, 값 쌍의 데이터이다. 브라우저에서 저장하므로 각 브라우저마다 쿠키는 독립적으로 존재한다.
쿠키는 브라우저에서 저장하는 데이터지만 데이터를 저장하라고 명령을 내리는 주체는 서버이며, 서버가 response를 보낼 때 Set-Cookie 헤더로 쿠키 정보를 보내면 브라우저가 해당 헤더를 읽고 쿠키를 저장하게 된다.
브라우저에 쿠키가 저장되어있을 경우 브라우저는 서버로 요청을 보낼 때 HTTP의 cookie 헤더에 쿠키 정보를 담아 전송한다. (쿠키의 속성에 따라 보내지 않을 수도 있다)
세션
쿠키가 브라우저에서 저장했다면 세션은 반대로 서버가 클라이언트의 상태를 저장한다.
세션에 클라이언트 데이터를 담게되면 특정한 키(JSESSIONID)를 발급한 후 해당 키에 대응하는 세션에 데이터를 저장한다. 이후 응답을 보낼 때 세션을 찾을 수 있도록 JSESSIONID를 쿠키로 발급해준다.
세션의 로그인 과정
[첫 로그인 시퀀스]
1. 클라이언트가 로그인 요청을 서버로 보낸다.
2. 서버는 전달된 데이터를 검증한다.
3. 검증에 성공했다면 현재 로그인된 유저 객체의 세션에 저장한다.
4. 응답에 클라이언트를 나타내는 고유 키 JSESSIONID를 Set-Cookie 헤더에 담아 반환한다.
5. 클라이언트는 Set-Cookie 헤더에 존재하는 쿠키를 브라우저에 저장한다.
[이후 로그인 시퀀스]
1. 클라이언트가 로그인 요청을 JSESSIONID 쿠키와 함께 보낸다.
2. 서버는 JSESSIONID로 해당 세션에 접근하여 로그인된 사용자가 있는지 확인한다.
3. 로그인된 사용자가 존재하면 로그인이 된 클라이언트로 간주한다.
[로그아웃]
1. 클라이언트가 로그아웃 요청을 서버로 보낸다.
2. 서버는 세션을 삭제하고 로그아웃 응답을 보낸다.
HTTP의 Stateless
HTTP는 무상태 프로토콜이며 서버는 클라이언트의 이전 요청을 저장하지 않는다. 이러한 HTTP의 특성을 Stateless라고 한다.
이에 따른 장점은 아래와 같다.
- 각 요청이 독립적으로 처리되기 때문에 이전 요청과 연결할 필요가 없다.
- 서버 간 공유할 상태가 없어 Scale-out이 용이하다.
- 한 요청의 실패가 다른 요청에 영향을 미치지 않는다.
- 서버에서 상태를 저장하지 않으므로 서버의 자원을 절약한다.
Stateless 측면에서 세션은 과연 적절한 인증 방식인가?
세션을 사용하면 서버에서 State를 유지한다. 따라서 명백히 Stateless 특성을 위반하는 것이라고 볼 수 있다. 따라서 적절한 인증 방식이라고 보기 힘들다. 그럼에도 사용자 인증과 같이 상태 정보를 유지해야만 하는 상황이 존재하며 세션은 구현의 간단함 때문에 여전히 사용되고 있는 기술이다.
세션 대신 JWT를 사용하거나 세션 자체를 서버에 저장하는 것이 아닌 외부 저장소에 저장하는 것으로 Stateless 특성을 유지하는 동시에 State를 관리할 수 있고 복잡도는 늘어나지만 이상적인 상태 유지 로직을 구현할 수 있다.
다중 서버 환경에서 세션의 관리 방안
- 하나의 서버에서 세션을 관리하고 로드밸런서에서 특성 서버로 연결하기
- 장점: 동기화 같은 작업이 필요하지 않음
- 단점: 로드 밸런서의 부하가 걸림, 부하 분산 효과를 못받을 가능성 존재, 해당 서버가 다운되면 상태 정보 유실
- 세션을 만들어 여러 서버와 상태를 공유, 복제
- 장점: 모든 서버가 다운되는게 아닌 이상 상태 정보가 유실되진 않음
- 단점: 모든 서버 사이에서 세션 정보가 공유되어야 하므로 네트워크 부하 발생, 만일 세션의 동기화가 빠르게 이루어지지 않을 경우 세션 정보가 최신이 아닐 수 있음
- 세션을 외부 저장소에 저장
- 장점: 모든 서버가 다운되더라도 상태 정보는 유지, 모든 서버가 확실히 최신 세션 정보를 참조, 서버를 Stateless하게 만들 수 있어 서버 확장에 용이
- 단점: 외부 저장소가 단일 장애 지점이 될 수 있음, 새로운 인프라 구축 비용 발생
2. HTTP 상태 코드
HTTP는 응답을 보낼 때 상태 코드를 함께 보내며 각 상태 코드는 특정한 의미를 담고 있다. 상태 코드의 첫 번째 숫자는 응답의 분류를 결정하고 나머지 두 자리는 해당 분류 내부에서 세부 의미를 결정한다.
HTTP 첫 번째 숫자에 따른 분류는 아래와 같다.
1xx (정보)
2xx (성공)
3xx (리다이렉션)
4xx (클라이언트 오류)
5xx (서버 오류)
일반적으로 자주 쓰이는 응답 코드는 200(성공), 301(영구 이동), 302(임시 이동), 400(잘못된 요청), 401(인증 실패), 403(접근 거부), 404(찾을 수 없음), 500(내부 서버 오류) 등이 있다.
401과 403의 차이
상태 코드 401은 인증 실패를 의미하고 403은 접근 거부를 의미한다. 의미만 보면 비슷하다고 느껴질 수 있는데 401은 말 그대로 인증되지 않은 상태고 403은 인가되지 않은 상태이다.
즉 401은 인증되지 않아 API를 사용할 권한이 없다는 뜻이고 403은 인증은 됐지만 권한이 없어 해당 API 접근에 거부되었다는 뜻이다.
참고로 403의 경우 서버에 index.html이 없을 경우에도 나타나게 된다. 웹 사이트에 접속했을 때 index.html이 없을 경우 서버의 디렉토리 목록을 조회하여 그 결과를 반환하게 되는데, 대부분의 경우 서버의 디렉토리 목록 조회를 금지시켜두기 때문에 403을 반환한다.
200과 201의 차이
상태 코드 200(성공)은 요청이 성공적으로 처리되었다는 뜻이고 201(생성됨)은 서버 측에서 새로운 데이터를 생성하였다는 뜻이다.
필요시 응답 코드를 재정의하여 사용 가능할까?
현재 최신 문서인 RFC 9110의 15. Status Codes 섹션을 확인해 보면
HTTP status codes are extensible. A client is not required to understand the meaning of all registered status codes, though such understanding is obviously desirable. However, a client MUST understand the class of any status code, as indicated by the first digit, and treat an unrecognized status code as being equivalent to the x00 status code of that class.
라고 적혀있다. 즉 상태 코드의 대분류를 지킨다면 응답 코드를 재정의하여 사용할 수 있다.
3. HTTP Method
HTTP 메소드는 HTTP 통신을 수행할 때 해당 요청이 어떤 처리를 수행하길 바라는지를 대략적으로 나타내는 요소이다.
HTTP 메소드는 아래와 같다.
GET - 리소스 조회 요청
HEAD - 리소스 조회를 요청하나, 응답 바디를 요구하지 않음
POST - 리소스 생성 요청
PUT - 리소스 수정 요청 (없다면 생성)
PATCH - 리소스 일부 수정 요청
DELETE - 리소스 삭제 요청
OPTIONS - 서버와 통신 가능한 메소드 조회
HTTP Method의 멱등성
멱등성이란 요청을 N번 보내더라도 결과가 동일하다는 성질을 의미한다.
| 멱등성 O | 멱등성 X |
| GET, HEAD, PUT, DELETE, OPTIONS | POST, PATCH |
멱등성의 기준은 서버의 리소스의 상태를 기준으로 판별한다.
GET, HEAD와 같이 리소스를 조회만 하는 메소드의 경우 당연히 서버의 리소스는 변하지 않으니 멱등하다.
PUT의 경우 동일한 자원에 대해 요청하는 경우 해당 자원을 수정하기만 하므로 요청을 여러번 하여도 서버의 상태는 동일하다.
DELETE 역시 데이터는 삭제된 상태로 변하지 않으므로 멱등하다.
PATCH의 경우 PUT과 동일하게 구현할 경우 멱등성을 보장한다.
GET과 POST의 차이
- GET은 리소스의 조회를 요청하는 메소드이고 POST는 리소스에 대한 처리를 요청하는 메소드이다.
- 일반적으로(즉, 절대적이진 않다) GET은 쿼리 스트링을 통해, POST는 요청 바디를 통해 데이터를 전달한다.
- GET은 멱등하지만 POST는 멱등하지 않다.
- GET은 데이터가 URL에 담기므로 길이 제한이 존재, POST는 바디에 담겨서 길이 제한이 없음
- GET은 데이터가 URL에 노출되므로 보안 측면에서 취약
- GET은 결과를 캐싱 가능
POST와 PUT, PATCH의 차이
POST는 리소스 생성 요청을 의미하고 PUT과 PATCH는 리소스의 업데이트 요청을 의미한다.
가장 큰 차이점은 동일한 리소스에 대해 여러 번의 요청을 보낼 경우 POST는 동일한 데이터를 생성되지만 PUT과 PATCH는 기존 데이터를 덮어쓰기만 한다는 점이다.
이 차이로 인해 POST와 PUT, PATCH 간의 멱등성 차이가 발생한다.
GET에 Body를 사용하지 않는 이유
GET에 Body를 사용하는 것은 금지되어 있지 않다. 다시 말해 사용할 수도 있다.
하지만 HTTP는 프로토콜이다. 서버와 클라이언트 간의 약속된 규정이 존재한다. 일반적으로 GET에는 Body에 데이터를 담지 않는 것으로 기대한다. 따라서 GET에 Body를 넣어 요청을 보낼 경우 구현체에 따라 개발자가 의도한대로 동작하지 않을 수 있으며 따라서 사용하지 않는다.
4. HTTPS
HTTP에 TLS를 적용시켜 보안성을 높인 HTTP를 Secure를 붙여 HTTPS라고 한다. HTTPS는 443 포트를 사용한다.
HTTP는 요청과 응답을 암호화하지 않기 때문에 해커가 패킷을 가로챌 경우 패킷에 존재하는 모든 데이터를 그대로 들여다볼 수 있다. 하지만 HTTPS의 경우 데이터를 암호화하기 때문에 패킷을 해커가 가로채도 그 의미를 알 수 없다.
[HTTPS 통신의 시퀀스]
1. 클라이언트가 서버로 HTTPS 요청
2. 서버가 공개키 + SSL 인증서를 응답
3. 유효한 인증서라면 공개키로 세션키를 암호화하여 서버로 전달
4. 서버는 세션 키를 수신하고 승인
5. 이제 앞으로는 세션 키를 사용하여 암호화하며 통신
세션 키는 TLS 핸드셰이크 이후에 통신에 사용하는 대칭 키를 의미한다.
공개키와 대칭키
공개키와 대칭키는 데이터를 암호화하는 암호화 방식이다.
대칭키는 클라이언트와 서버가 대칭적으로 동일한 키를 사용한다는 의미이며 단 하나의 키를 가지고 암, 복호화를 수행한다. 구현이 간단하고 속도가 빠르지만 키를 안전히 공유하는 것이 어려우며 보안성이 상대적으로 떨어진다.
공개키는 두 개의 키를 가지고 암호화를 수행하는 방식이다. 사용자는 공개키와 비밀키 2개를 지니고 있고 공개키는 모두에게 공개한다. 암호화를 원한다면 공개된 공개키를 이용하여 암호화하여 전달하며 복호화는 사용자만이 알고 있는 비밀키를 이용해야한다. 공개키 방식은 비밀키를 공유할 필요가 없으므로 키 교환 문제가 발생하지 않으며 보안성이 매우 높다.
HTTPS Handshake 과정에서 인증서를 사용하는 이유
HTTPS는 TLS 위에서 동작하며 TLS는 통신의 보안을 준수한다. 보안을 위한 첫 번째 전제는 신뢰성 있는 상대와 통신을 해야한다는 점으로, 서버를 신뢰할 수 있는지 확인할 수 있어야 한다. 따라서 서버는 TLS 핸드셰이크 과정 중 자신을 인증할 수 있는 전자 서명이 포함된 인증서를 제시한다. 클라이언트는 해당 인증서를 통해 서버를 신뢰성을 판별할 수 있다.
SSL과 TLS의 차이
SSL(Secure Sockets Layer)와 TLS(Transport Layer Security)는 둘 모두 암호화 프로토콜이며 SSL이 TLS의 전신이다. SSL은 보안상의 문제로 현재 사용되지 않으며 TLS만 사용되고 있다.
본디 넷스케이프가 개발한 SSL로 널리 알려져 있었으나 여러 보안 취약점을 보완하고 새로운 버전을 출시하며 넷스케이프와 더 이상 관련이 없음을 명시하기 위해 프로토콜의 이름을 변경하여 출시하기 되는데 그것이 TLS이다.
따라서 둘의 차이는 암호화 프로토콜 버전의 차이라고 봐도 무방하다.
5. 웹소켓과 소켓
-
소켓은 전송 계층과 응용 계층 사이의 인터페이스이며, 네트워크 패킷의 종착점이다. TCP, UDP 모두 사용할 수 있으며 (클라이언트 IP, 클라이언트 포트, 서버 IP, 서버 포트)를 통해 하나의 소켓으로 식별된다.서버 소켓이 연결을 대기하고 있을 때 클라이언트 소켓이 연결을 시도하여 accept 하면 서버 소켓은 새로운 소켓을 생성하고 해당 소켓을 통해 클라이언트와 통신한다.
데이터는 흐름은 양방향으로 클라이언트 -> 서버, 서버 -> 클라이언트 모두 가능하다.
-
웹소켓은 웹 환경에서 사용하는 통신 프로토콜이다. HTTP와 달리 양방향 데이터 전송이 가능하며 소켓 통신과 같이 한 번 연결을 맺으면 계속 유지된다. 한 번 맺은 연결을 유지하기 때문에 지속적으로 요청을 보내는 HTTP 폴링 방식과 비교하여 오버헤드가 낮다.웹에서 사용되는 기술인 만큼 처음 웹소켓 연결을 수행할 때 HTTP를 이용하여 연결을 수립한다. 이후 통신에는 웹소켓 자체 프로토콜을 사용한다.
-
Socket.io은 웹소켓 기반의 라이브러리이다. 웹소켓은 HTML5 기반 기술이기 때문에 오래된 브라우저에서는 동작하지 않는다. 따라서 웹소켓을 지원하는 경우 웹소켓으로, 웹소켓을 지원하지 않는다면 http를 사용하여 실시간 통신을 흉내낸다. -
SSE는 Server-Sent-Event의 줄임말로 웹소켓과 비슷하게 실시간 데이터 스트리밍을 가능하게 해준다. 다만 SSE는 서버 -> 클라이언트 측으로만 데이터가 흘러가며 HTTP를 사용한다. 웹소켓과 비교하여 더 가볍다. -
포트는 네트워크 상에서 프로세스를 구분하는 논리적인 번호이다. 65535까지 존재한다.
소켓이 여러 개 있다면 소켓의 포트는 모두 다른가?
같을 수 있다. 소켓은 클라이언트 IP/포트, 서버 IP/포트 4가지의 정보로 유일하게 식별된다. 서버 측의 IP/포트는 동일하더라도 클라이언트 IP/포트가 달라지기 때문에 서버 측에서는 동일한 포트로 여러 개의 소켓을 할당할 수 있다.
사용자의 요청이 무수히 많아지면 소켓도 무수히 많이 생성되는가?
서버 소켓은 새로운 연결을 원하는 클라이언트의 요청이 들어올 때마다 클라이언트 소켓과 연결되는 새로운 소켓을 생성하여 통신한다. 따라서 무수히 많은 소켓이 생성된다.
6. HTTP 버전
- HTTP/0.9
- HTTP의 초기 버전
- HTTP/1.0
- HTTP 헤더의 추가
- HTTP 버전 정보 추가
- 요청 메소드 확장: POST, HEAD
- HTTP 상태 코드 추가
- Content-Type 추가
- HTML 외의 다른 데이터 전달 가능
- HTTP/1.1
- Persistent Connection
- keep-alive 헤더를 통해 커넥션을 닫지 않고 여러 요청을 연속적으로 보낼 수 있게 됨
- 기본적으로 활성화.
- HTTP 1.0에서 사용하고자 하면 헤더에서 명시
- 파이프라이닝
- 요청을 한 번에 전송
- Persistent Connection
- HTTP/2.0
- Binary Frame
- 데이터가 text로 전달되는 것이 아니라 binary frame으로 인코딩되어 전송
- 프레임은 HTTP 2.0의 최소 데이터 단위
- 프레임 내부는 헤더 혹은 데이터가 들어가 있음
- 스트림
- 프레임들은 스트림으로 전달
- 각각의 스트림은 고유의 식별자가 존재하며 이 식별자로 요청/응답 스트림 구분
- 멀티플렉싱
- 전달받은 프레임들을 병렬적으로 처리
- 처리가 된 응답 스트림은 순서와 상관없이 바로 전송
- HTTP/1.1의 HOL 문제를 부분적으로 해결
- 서버 푸시
- 클라이언트가 미래에 필요할 것 같은 리소스를 요청을 하기 전에 미리 전달
- 헤더 압축
- 중복된 내용은 전송하지 않음
- 새롭게 보내는 내용은 압축하여 전송
- Binary Frame
- HTTP/3.0:
- 프로토콜 변경
- TCP가 아닌 구글에서 자체 개발한 UDP 기반의 QUIC 프로토콜 사용
- TCP는 자체적인 프로토콜의 한계로 수행 시간을 올리기에 한계가 있음
- TCP의 자체적인 HOL 문제도 존재
- UDP 기반이지만 패킷 손실에도 대응
- TLS가 기본적으로 내장
- 프로토콜 변경
HOL(Head Of Line) Blocking
앞선 요청에서 지연이 발생하여 뒤에 존재하는 요청들이 모두 지연되는 것을 의미
HTTP/1.1에서는 커넥션을 맺고 여러 요청을 한 번에 보낼 때 앞선 요청에서 지연이 발생할 경우 뒤에 존재하는 요청들이 모두 지연
HTTP/2.0에서는 멀티플렉싱을 사용하여 하나의 커넥션에서 여러 프레임을 병렬적으로 처리하는 것으로 HOL 문제를 부분적으로 해결하였다. 하지만 TCP의 자체적인 문제점으로 스트림을 전송하는 과정 중 패킷이 유실될 경우 동일하게 HOL 문제가 여전히 발생한다.
HTTP/3.0에서 프로토콜을 QUIC으로 바꿈으로서 전송 계층의 HOL 문제를 해결하였다. QUIC는 스트림 자체를 여러 개로 나누어 한 스트림에 지연이 발생하여도 다른 스트림에는 영향을 끼치지 않도록 한다.
상위 HTTP 연결
HTTP 환경에서는 클라이언트가 서버에 요청을 보낼 때 Connection 헤더에 Upgrade, Upgrade 헤더에 변경하고자 하는 프로토콜을 실어 보낸다.
서버가 해당 프로토콜을 지원하는 경우 101 Switcing Protocol로 응답하며 이후에는 해당 프로토콜로 통신한다. 지원하지 않는다면 일반적인 200 응답을 보내게 된다.
HTTPS 환경에서는 TLS를 이용하기 때문에 TLS의 ALPN을 사용하여 클라이언트가 사용할 수 있는 프로토콜의 목록을 서버로 전달하면 서버는 해당 프로토콜 중 하나를 골라 응답을 해주고 이후 서버가 선택한 프로토콜을 이용하여 통신하게 된다.
7. TCP와 UDP
- TCP
- Transmission Control Protocol
- 전송 제어 프로토콜
- 연결 지향
- 데이터를 전송하기 전에 연결을 맺고 전송이 종료되면 연결도 종료
- 3-Way HandShake
- TCP 통신에서 연결을 수립하는 과정을 의미
- 클라이언트 -- (SYN) --> 서버
- 클라이언트 <-- (SYN, ACK) -- 서버
- 클라이언트 -- (ACK) --> 서버
- 4-Way HandShake
- TCP 통신에서 연결을 종료하는 과정
- 클라이언트 -- (FIN) --> 서버
- 클라이언트 <-- (ACK) -- 서버
- 클라이언트 <-- (FIN) -- 서버
- 클라이언트 -- (ACK) --> 서버
- 신뢰성 보장
- 패킷이 유실되었다고 판단되면 재전송
- 패킷의 순서를 헤더의 시퀀스 넘버를 통해 보장
- TCP 헤더 내부의 체크섬을 이용하여 오류를 탐지하고 오류가 발견됐다면 송신자에게 재전송하라고 요청
- 흐름 제어
- Stop & Wait
- 요청에 대한 ACK가 오기 전까지 대기
- 슬라이딩 윈도우
- 특정한 윈도우를 정해두고 해당 윈도우 만큼의 데이터를 전송
- 윈도우의 크기는 3 Way Handshake 때 결정
- 응답을 받고 서버의 버퍼 크기를 기반으로 윈도우를 이동시키며 최종적으로 모든 데이터를 전송
- Stop & Wait
- 혼잡 제어
- Slow Start
- 초기 연결 수립 이후에는 윈도우 크기를 매우 작게하여 데이터를 전송
- 이후 윈도우의 크기를 2배씩 늘림
- 혼잡이 감지되면 윈도우의 크기를 1로 감소
- 빠른 재전송(3-DUP ACK)
- TCP는 응답으로 잘 도착한 패킷의 다음 순번을 ACK에 담아 보냄
- 동일한 번호의 ACK가 3연속으로 오게 될 경우 패킷의 유실로 취급하고 해당 패킷 재전송
- 빠른 회복
- 혼잡이 감지됐을 때 윈도우 크기를 1로 줄이지 않고 반으로 줄이고 천천히 윈도우를 늘리는 기법
- Slow Start
- fast-open
- TCP에서 연결을 수립하는 동시에 데이터를 전송하는 확장 프로토콜
- 최초 통신 시 SYN을 보내는 동시에 서버로부터 쿠키를 수신 (쿠키는 이전에 서버와 통신을 했다는 의미)
- 이후 서버와 통신하기 위해 TCP 연결을 수립할 때 쿠키가 존재한다면 쿠키를 제시하며 동시에 데이터를 전송
- 이후 서버는 클라이언트 측 ACK가 오기 전에 응답 전송 가능
- Transmission Control Protocol
- UDP
- User Datagram Protocol
- 유저 데이터그램 프로토콜
- 비연결형
- 연결을 맺지 않고 바로 데이터를 전송
- 비신뢰성
- 데이터의 신뢰성 있는 전송을 보장하지 않음
- 가벼움
- 데이터와 헤더의 크기가 작아 빠르고 가벼움
- 커스터마이징 가능
- 기본적으로 제공하는 기능이 없기 때문에 원하는 기능을 따로 추가하여 사용 가능
- User Datagram Protocol
Checksum
통신 도중 발생할 수 있는 데이터의 오류 탐지를 위해 사용하는 값.
데이터의 내용을 기반으로 특정한 규칙에 맞춰 값을 생성하고 체크섬 값을 헤더에 담아 보낸다.
클라이언트는 데이터를 받고 해당 데이터를 기반으로 다시 한 번 체크섬을 계산한 후 헤더에 존재하는 체크섬과 비교하여 오류 여부를 알아낸다.
완벽하게 데이터의 오류를 탐지할 수는 없음.
TCP의 Checksum과 UDP의 Checksum
TCP와 UDP 모두 헤더에 체크섬이 존재한다. 단 TCP는 신뢰성 있는 통신을 위해 체크섬을 통한 데이터의 검증을 반드시 수행하고 UDP는 수행할 수도 있고 안할 수도 있다는 차이가 있다. (체크섬 헤더의 값을 모두 0으로 하여 송신하면 수신측은 체크섬을 하지 않아도 된다)
Checksum의 오류 정정
체크섬은 오류의 탐지만 가능하고 정정은 불가능하다. TCP의 경우 오류가 발생했으면 재전송하도록 한다.
HTTP의 프로토콜
HTTP는 TCP를 사용한다. (3.0의 경우 QUIC) HTTP의 경우 상대적으로 속도보다 데이터의 무결성과 신뢰성이 더 중요하기 때문이다.
만일 서버로부터 웹 리소스를 전달받았는데 데이터가 손상됐을 경우 브라우저에서 웹 페이지를 렌더링하는데 애로사항이 꽃 피게 된다. 영상 스트리밍과 같은 경우 실시간 데이터를 처리해야하므로 작은 오류는 넘어갈 수 있지만 웹 페이지의 경우 실시간 데이터 처리가 아니므로 신뢰성이 더 중요하다고 볼 수 있다.
HTTP/3의 UDP(UDP의 문제는 해결되었나)
TCP 스펙의 자체적인 문제로 성능을 끌어올리는데 한계가 존재했기 때문이다.
신뢰성 있는 데이터 전송 로직을 UDP에서 추가적으로 구현하여 UDP의 문제를 해결하였다.
브라우저는 어떤 서버가 TCP를 쓰는지 UDP를 쓰는지 어떻게 아는가
브라우저는 서버가 TCP를 쓰는지 UDP를 쓰는지 알 수 없다.
다만 API를 설계할 때 서버와 클라이언트가 협의하듯이, 특정 요청에 대한 프로토콜 역시 백엔드 개발자와 프론트엔드 개발자가 협의하여 만들어뒀을 것이므로 브라우저는 프론트엔드 개발자가 작성한 JS 코드의 프로토콜대로 요청을 보낼 것이다.
새로운 통신 프로토콜을 구현한다면 TCP나 UDP 중 어떤 프로토콜을 어떤 기준으로 선택할 것인가
상황에 따라 다르다. 신뢰성 있는 전송이 필요한 경우에는 이미 신뢰성 있는 데이터 전송이 이미 구현되어 있는 TCP를 기반으로 구현할 것 같고 속도가 훨씬 더 중요한 이슈라면 UDP를 기반으로 구현할 것 같다.
TCP의 상태
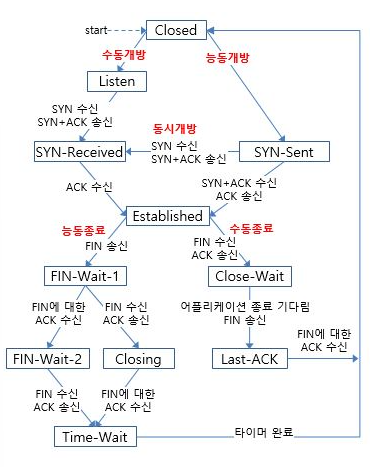
출처: http://www.ktword.co.kr/test/view/view.php?no=657
8. DHCP
DHCP(Dynamic Host Configuration Protocol, 동적 호스트 설정 프로토콜)는 IP 주소 및 기타 네트워크 설정을 동적으로 관리하는 프로토콜이다.
네트워크를 이용하기 위해서는 각 컴퓨터들이 고유한 IP를 가져야 하는데 본디 컴퓨터마다 IP 주소가 수동으로 입력해야 한다. DHCP는 이를 자동화한다.
DHCP는 IP 주소 풀을 가지고 있으며 컴퓨터가 DHCP 서버를 향해 IP를 요청하면 IP를 임대하여 할당해준다. 임대받은 IP는 연장하거나 반납할 수 있다.
DHCP의 계층
DHCP는 응용 계층의 프로토콜이다.
DHCP의 동작 과정
- DHCP Discover
- 단말 -> 서버
- 아이피 주소 할당 요청을 브로드캐스트
- DHCP Offer
- 서버 -> 단말
- IP 정보 및 네트워크 정보를 브로드캐스트
- DHCP Request
- 단말 -> 서버
- 전달받은 아이피를 사용하겠다고 브로드캐스트
- DHCP Ack
- 서버 -> 단말
- IP와 게이트웨이 주소를 최종 승인하여 브로드캐스트(혹은 유니캐스트)
DHCP의 프로토콜
DHCP는 UDP를 사용한다. DHCP를 이용하는 단말은 아직 IP 주소가 할당된 상태가 아니기 때문에 TCP를 사용할 수가 없다. 브로드캐스트를 이용하기 위해 UDP를 사용한다.
DHCP가 제공하는 정보
단말이 사용 할 IP 주소 뿐만 아니라 기타 네트워크 정보들도 함께 제공한다. 기타 정보까지 제공한다는 점이 DHCP 이전에 사용됐던 RARP와의 차이이다.
아래는 DHCP가 제공하는 정보들이다.
- IP 주소
- 서브넷 마스크
- 게이트웨이 주소
- DNS 주소
DHCP의 유효기간
유효기간은 DHCP 서버의 설정에 따라 다르다. 일반적인 공유기에서 동작하는 DHCP의 디폴트 대여 시간은 2시간이다.
9. IP
IP는 인터넷 프로토콜의 약자로 네트워크 통신의 규약을 의미한다. 모든 단말은 고유의 IP 주소를 지니며 해당 주소를 기반으로 통신을 수행한다.
IPv4와 IPv6의 차이
- IPv4
- 가장 널리 쓰이는 주소 체계
- 32비트로 구성
- 43억개의 고유 주소 제공
- 0~255의 10진수로 나타내며 각 숫자는 .으로 구분
- 초기에는 클래스로 나눠 할당했지만 현재는 CIDR을 사용
- IPv6
- IPv4의 주소 부족 문제를 해결하기 위해 등장
- 128비트로 구성
- 사실상 무한대의 주소 개수
- 4자리의 16진수 숫자 8개로 나타내며 각 숫자는 :로 구분
IPv4의 주소 고갈 문제의 해결법
하나의 공인 IP를 여러 기기가 사용할 수 있도록 하는 NAT를 사용한다.
NAT는 네트워크 주소 변환의 약자로 사설 IP를 공인 IP로 변환해주는 기술이다. 패킷이 외부로 나갈 때 사설 IP를 공인 IP로 변환해주고 내부로 오는 패킷은 사설 IP로 변환해서 전달해준다.
외부에서 온 패킷을 받을 때는 어떤 내부 단말로 오는지를 식별할 수 있어야 한다. 일반적으로 PAT를 사용하게 되므로 요청 시 사용했던 포트 번호를 기반으로 내부 단말을 식별하게 된다.
공유기의 고정 주소 제공 원리
공유기에 할당된 IP는 공인 IP이지만 NAT를 이용하여 내부 네트워크의 단말은 사설 IP로 할당할 수 있다. 이때 특정 단말의 IP를 고정하였다면 공유기 내부에 존재하는 DHCP 서버는 MAC 주소와 IP를 매핑하여 고정 주소를 제공한다.
같은 네트워크 내부의 IPv4, IPv6 간의 통신 가능 여부
기본적으로는 불가능하다. IPv4 장치에서 IPv6의 패킷을 이해할 수 없다.
둘 사이의 통신을 위헤서는 IPv6의 패킷을 IPv4 네트워크를 통해 전송하는 터널링을 이용하거나, IPv6의 주소를 IPv4의 주소로 변환해주는 NAT64를 이용해야한다.
IP의 전송 신뢰성
IP는 목적지까지의 패킷을 전달할 수 있다는 것을 보장하지만 신뢰성은 존재하지 않는다. 신뢰성을 얻고 싶으면 상위 계층의 TCP를 사용해야 한다.
IPv4의 Checksum과 TCP의 Checksum의 차이
IPv4의 체크섬은 IP 헤더만을 가지고 계산하게 되므로 IP 헤더의 오류만을 검출한다.
반면 TCP의 체크섬은 TCP 헤더, 데이터, 의사 헤더로 계산하게 되므로 헤더 및 데이터에 대한 오류 검출 또한 가능하다.
TTL
TTL(Hop Limit)는 IP 패킷의 생존 시간을 의미한다. Hop은 라우터를 지나칠 때마다 값이 1씩 줄어들게 되며 0에 도달하게 되면 패킷은 소멸된다.
IP 주소와 MAC 주소의 차이
IP 주소는 3계층에서 단말을 식별하는 주소이고 MAC 주소는 2계층에서 단말을 식별하는 주소이다. IP는 네트워크 상에서 단말의 위치를 나타내고 MAC 주소는 장치의 고유한 식별자를 나타낸다.
IP의 경우 동적으로 재할당이 가능하지만 MAC의 경우 기기별로 변경될 수 없다.
IP 주소를 기반으로 MAC 주소를 찾기 위해 ARP를 사용한다. 반대로는 RARP가 있지만 현재는 DHCP를 사용한다.
10. OSI 7계층
- 물리 계층
- 데이터를 물리적인 전기 신호로 변환하여 전달
- 케이블, 허브
- 데이터 링크 계층
- 물리 계층에서 송수신 되는 데이터의 오류와 흐름을 관리
- MAC 주소
- 브릿지, 스위치, 이더넷
- CSMA/CD, CSMA/CA, Slott Aloha
- 네트워크 계층
- 단말의 주소를 정하고 최적의 경로로 패킷을 전달
- IP 주소
- IP, ARP, RIP, OSPF, NAT
- 전송 계층
- 신뢰성 있는 통신을 보장
- 포트 번호
- TCP, UDP
- 세션 계층
- 응용 계층에서 통신을 관리하는 방법을 정의
- RPC
- 표현 계층
- 데이터의 표현 방식을 결정
- 데이터의 확장자, 인코딩 등
- ASCII, 유니코드, JPG, PNG 등
- 응용 계층
- 응용 프로세스가 직접적으로 사용하여 응용 서비스 수행
- HTTP, SSH, SMTP, DHCP 등
전송 계층과 네트워크 계층의 차이
네트워크 계층은 데이터를 원하는 목적지까지 전달하는 역할만을 담당. 전달을 위해 최적의 경로를 라우팅하고 포워딩한다.
전송 계층은 애플리케이션 간의 통신을 지원하며 데이터의 신뢰성을 보장하고 통신의 흐름과 혼잡을 제어한다.
L3 스위치와 라우터의 차이
현재는 기술의 발달로 L3 스위치와 라우터의 차이가 거의 없다.
과거에는 L3 스위치는 WAN과 연결하지 못하는 대신 라우터에 비해 가볍고 비용이 싸 VLAN간 패킷 전달을 수행할 때 사용되었다. 또한 L3 스위치는 라우팅을 하드웨어적으로, 라우터는 소프트웨어적으로 구현한다.
각 계층은 패킷을 어떻게 부르는가
물리 계층은 비트, 데이터 링크 계층은 프레임, 네트워크 계층은 패킷, 전송 계층은 세그먼트라고 부른다.
헤더의 패킹 순서
헤더는 계층에 도달하는 순서에 맞게 하나씩 추가된다.
예를 들어 응용 계층에서 특정 데이터를 보낸다고 하자. 그렇다면 아래와 같은 순서로 헤더가 추가된다.
- 응용 계층
- 데이터
- 전송 계층
- TCP 세그먼트 헤더 + 데이터
- 네트워크 계층
- IP 패킷 헤더 + TCP 세그먼트 헤더 + 데이터
- 데이터 링크 계층
- 이더넷 프레임 헤더 + IP 패킷 헤더 + TCP 세그먼트 헤더 + 데이터
ARP
ARP는 Address Resolution Protocol의 약자로 IP 주소를 MAC 주소로 변환해주는 3계층 프로토콜이다. IPv4에서만 사용된다.
ARP는 요청과 응답으로 동작하게 된다.
- ARP 요청
- 라우터에서 ARP 요청 패킷을 브로드캐스트
- ARP 요청 패킷에는 (송신자 MAC, 송신자 IP, 목적지 IP)가 담겨있음
- ARP 응답
- 목적지 IP와 자신의 IP가 같은 단말은 자신의 IP와 MAC 주소를 담은 ARP 응답 패킷을 라우터로 유니캐스트
- 라우터는 ARP 테이블에 해당 정보를 등록
- ARP 테이블은 캐시 개념이라 일정 시간이 지나면 소멸
11. 3-Way Handshake
TCP에서 연결을 맺을 때 수행하는 과정을 의미. 연결과 동시에 추가적인 정보(흐름 제어를 위한 시퀀스 넘버, 윈도우 크기 등)도 같이 교환
- SYN
- 연결 요청을 의미
- 능동 개방을 수행하는 단말이 송신
- 송신자의 상태는 SYN-SENT로 변경
- SYN + ACK
- 연결 허락을 의미
- SYN 플래그와 ACK 플래그를 동시에 1로 설정
- 수신자의 상태는 SYN-RECEIVED로 변경
- ACK
- 연결 설정을 의미
- 양측 모두 ESTABLISHED 상태로 변경
ACK, SYN의 전달 방법
TCP 세그먼트의 헤더 내부에 제어 플래그 비트를 통하여 전달되며 비트가 1로 설정되면 활성화된다.
왜 2-Way HandShake가 아닌가?
TCP는 신뢰성이 보장되는 통신을 지향한다. 2-Way Handshake의 경우 서버 입장에서 자신이 보낸 패킷이 상대방까지 도달 가능한지를 확인할 수 없어 신뢰성을 보장할 수 없게 된다.
두 호스트가 동시에 연결을 시도하는 경우
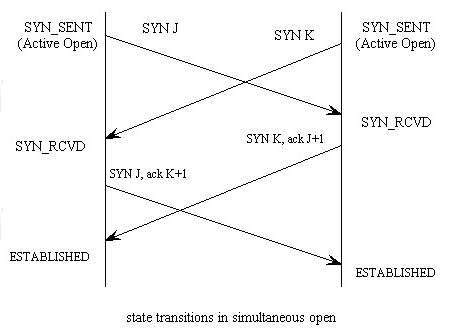
출처: https://ttcplinux.sourceforge.net/documents/one/tcpstate/tcpstate.html
일반적이진 않지만, 가능한 경우이다. 이러한 상황을 양측에서 동시에 연결을 시도한다고 하여 동시 오픈(simultaneous open)이라고 하며 TCP는 이러한 상황에서의 동작 방안도 설계되어 있다.
일반적인 3-way handshake가 진행되나, 마지막 ACK는 수행되지 않고 서로의 SYN + ACK를 수신받으면 양측 모두 바로 ESTABLISHED 상태로 전이된다.
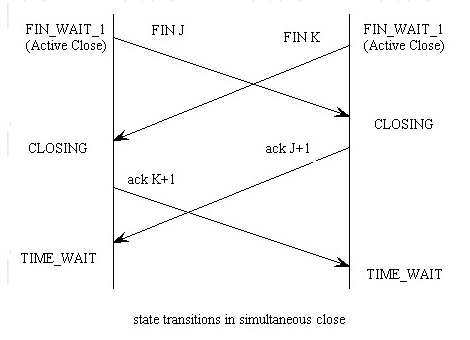
출처: https://ttcplinux.sourceforge.net/documents/one/tcpstate/tcpstate.html
참고로 동시 닫기도 가능하다. 서로 FIN과 ACK를 수신한 후 양측 모두 TIME_WAIT 상태로 전이한다. TCP 상태 전이도에서 Closing 상태가 이때에 대한 상태이다.
SYN Flooding
3-Way Handshake의 동작 원리를 악용하여 공격하는 기법이다.
3-Way Handshake에서 서버는 SYN 패킷을 받으면 SYN + ACK 패킷을 클라이언트에게 전송한 후 클라이언트의 연결을 받기 위한 준비를 한다. (포트를 할당하고, 메모리 공간을 확보하는 등)
이때 클라이언트에서 SYN 패킷만 보내고 SYN + ACK 패킷에 대한 ACK를 보내지 않음으로서 연결을 확립되지 않은 무수히 많은 연결 대기 상태를 만들어 버리는 것
서버의 자원은 점점 고갈되며 서버의 자원이 모두 고갈되면 서버는 서비스 거부 상태에 빠지게 된다.
12. 4-Way Handshake
TCP에서 연결을 끊을 때 수행하는 과정을 의미. 양측 모두 종료 의사를 확인한 후 연결을 종료하기 위해 총 4번의 패킷 교환이 발생.
FIN 수신 측에서 아직 보낼 데이터가 남아있을 수 있기 때문에 3-Way handshake와는 달리 FIN과 ACK를 동시에 보내지 않는다. 따라서 4-Way의 형태가 된다.
연결 종료의 주체는 양측 모두 가능
- FIN
- A가 연결 종료를 요청
- A는 FIN-Wait-1 상태로 전이
- ACK
- B는 FIN 패킷에 대한 FIN + ACK를 전송
- A는 FIN-Wait-2 상태로 전이
- B는 Close-Wait 상태로 전이
- FIN
- B는 자신이 보낼 데이터가 더 이상 남아있지 않다면 자신도 FIN + ACK 패킷을 전송
- B는 Last-ACK 상태로 전이
- ACK
- A는 B가 보낸 FIN 패킷을 수신하고 해당 패킷에 대한 ACK를 다시 전송
- A는 Time-Wait 상태로 전이
- B는 ACK 패킷을 받고 Time-Wait 상태로 전이
4-way handshake 패킷의 식별
TCP 헤더 내부에 존재하는 상태 플래그 속 FIN 비트는 연결 종료를 수행할 때만 사용된다. 따라서 패킷 내부 상태 플래그의 FIN 비트가 켜져있다면 4-way handshake 패킷으로 간주할 수 있다.
긴급한 연결 종료
4-way handshake를 할 여유 없이 긴급히 연결을 끊어야 한다면 TCP 헤더 내부 상태 플래그에 존재하는 RST(Reset) 비트를 켜고 보내는 것으로 강제로 연결을 끊을 수 있다.
이 경우 송신자는 패킷을 전송한 즉시 연결을 종료하고 수신자는 패킷을 수신한 즉시 연결을 종료한다.
4-way handshake 중 연결 종료
TCP는 기본적으로 패킷을 송신하고 RTO 동안 ACK를 받지 못하면 재전송을 시도한다. 그럼에도 불구하고 ACK를 계속하여 수신하지 못한다면 상대방이 연결을 끊었다고 간주하고 연결을 끊게 된다.
따라서 4-way handshake 중 상대방의 연결을 강제로 종료된다면 즉각적으로 확인할 수는 없지만 시간이 지남에 따라 연결이 끊어지게 된다.
TIME_WAIT 상태의 이유
4-way handshake가 종료된 이후에도 TIME_WAIT 상태로 어느정도의 시간동안은 연결을 끊지 않는다. 이는 연결 종료 이전에 특징 패킷이 늦게 도착하는 것을 방지하기 위함이다.
만일 상대로부터 FIN 패킷을 받고 ACK를 보냈지만 상대가 보낸 데이터의 패킷이 아직 도착하지 않았을 수 있다. 이때 연결을 바로 종료하게 되면 상대측의 데이터를 정상적으로 수신할 수 없게 된다.
따라서 FIN 패킷을 받은 이후에도 약간을 대기하여 추가적인 패킷을 수신한 뒤 연결을 종료한다.
13. 네트워크상 웹의 접속 과정
전반적인 접속 과정은 아래의 순서를 따른다.
- DNS 조회
- 도메인을 입력하였을 때 제일 처음으로 수행되는 과정
- 컴퓨터 입장에서 도메인만 보고서는 어느 위치로 가야하는지 알 수 없음
- 따라서 DNS을 이용하여 도메인을 IP 주소로 변환하는 과정이 필요
- 먼저 브라우저와 OS의 DNS 캐시를 확인
- 없다면 DNS 쿼리를 통해 IP를 얻어옴
- HTTP 연결
- HTTP 연결을 위해 TCP 3-Way Handshake 수행
- HTTPS라면 추가적으로 TLS Handshake 수행
- HTTP/3.0이라면 QUIC Handshake만을 수행
- GET 요청 전송
- 서버의 루트 경로로 GET 요청을 전송
- 서버의 응답 수신
- 해당 웹페이지를 렌더링할 때 필요한 HTML, CSS, JS를 수신
- 브라우저 렌더링
- HTML 파싱하여 DOM Tree 생성
- CSS를 파싱하여 CSSOM 생성
- JS를 컴파일
- DOM Tree와 CSSOM으로 Render Tree 구성
- Render Tree 기반으로 각 노드의 크기를 결정
- 최종적으로 각 노드를 화면에 렌더링
DNS 쿼리의 결과
DNS 쿼리의 결과로 얻어진 IP는 해당 도메인에 해당하는 서버의 IP를 가리키고 있다.
웹 서버와 WAS
- 웹 서버
- HTML, CSS, JS와 같은 정적 리소스를 서빙
- HTTP 요청을 처리
- 리버스 프록시 혹은 로드 밸런서의 역할도 수행 가능
- Apache HTTP Server, NGINX
- WAS
- 내부적으로 애플리케이션을 구동시켜 DB와 연동하고 비즈니스 로직을 실행하여 동적인 리소스를 서빙
- 정적 리소스의 서빙도 같이 수행할 수 있음
- 자바의 경우 서블릿 컨테이너라고도 함
- Apache Tomcat
URI, URL, URN
URI, URL, URN은 인터넷 리소스를 식별하는데 사용되는 용어이다.
- URI
- Uniform Resouce Identifier
- 리소스를 식별하는 모든 방식을 뭉뚱그려 URI라고 함
- URL, URN은 모두 URI에 속함
- URL
- Uniform Resource Locator
- 리소스의 위치와 접근 프로토콜을 동시에 나타냄
- 프로토콜://호스트명[:포트번호]/[경로]
- URN
- Uniform Resource Name
- 리소스를 식별하기 위한 이름을 의미
- 특정 리소스를 식별할 수 있는 이름이라면 모두 URN
14. DNS
DNS란 Domain Name System의 약자로 도메인을 IP 주소로 변환해주는 시스템이다. 서버가 계층적으로 구성되어 있는 것이 특징
DNS 쿼리를 요청하면 먼저 로컬 DNS 서버로 요청을 보낸다. 로컬 DNS 서버 역시 IP를 모른다면 루트 네임 서버 -> TLD 네임 서버 -> 권한 있는 네임 서버를 차례대로 방문하여 IP를 알아낸다.
DNS를 설정할 때 주 DNS와 보조 DNS를 설정할 수 있다. 보조 DNS는 주 DNS에 문제가 생길 때 사용되거나 혹은 주 DNS보다 응답 속도가 더 빠를 때 사용된다.
클라이언트 - 서버 구조로 동작하며 DNS 클라이언트를 DNS Resolver라고 한다.
DNS의 계층
DNS는 사용자가 도메인을 입력할 때 직접적으로 호출되는 서비스로, 응용 계층의 프로토콜이다.
DNS의 프로토콜
DNS는 UDP를 사용한다. 다만 패킷의 크기가 클 경우에는 TCP를 사용하여 처리한다.
Recursive Query, Iterative Query
- Recursive Query
- 재귀 함수를 쓰듯, DNS 서버에게 특정 도메인에 대한 IP 주소를 알아와 달라고 요청
- 클라이언트가 요청하면 DNS 서버는 IP 주소를 반환
- Iterative Query
- 클라이언트가 직접 루트, TLD, 권한 있는 네임 서버에 반복적으로 쿼리하여 IP 주소를 알아냄
- 클라이언트가 반복하여 쿼리하는 것으로 IP 주소를 알아냄
DNS 쿼리 손실 대책
DNS는 UDP를 사용하고, UDP는 신뢰성 있는 전송을 보장하지 않는다. 만일 DNS 쿼리에 해당하는 패킷이 유실된다면 특정 횟수만큼 재시도하며 그럼에도 계속해서 패킷이 손실되면 보조 DNS를 이용하거나 TCP를 사용한다.
잘못된 DNS 캐싱 대책
일단 캐싱이 잘못된 상태니 잘못된 캐시를 지워버린다. 이후 DNS 레코드의 TTL의 길이를 짧게 설정한다.
DNS 레코드 타입
- A
- 호스트 이름에 대한 IPv4 주소
- AAAA
- 호스트 이름에 대한 IPv6 주소
- CNAME
- 공식적인 호스트 이름
- MX
- 메일 서버에 대한 호스트 이름
- NS
- 네임 서버에 대한 호스트 이름
- TXT
- 다양한 정보
- SOA
- DNS 영역 시작 정보
- 영역 명칭, 마스터 네임 서버의 이름과 관리자 이메일 주소 등
hosts 파일
hosts 파일은 로컬에 저장해두는 DNS 정보이다. DNS를 이용하기 전에 hosts 파일을 살펴보고 존재한다면 해당 IP를 사용한다.
우선순위는 DNS보다 높다.
15. SOP
SOP는 Same-Origin Policy의 약자로 웹 브라우저의 보안 모델 중 하나이다.
Same Origin은 프로토콜, 호스트, 포트 번호가 동일한 Origin을 의미한다. 셋 중 하나라도 다르다면 다른 출처로 간주한다.
SOP에 의해 다른 출처를 향한 요청에 대한 응답, DOM 접근, 로컬 스토리지, 스크립트 실행 등은 브라우저 레벨에서 차단된다. 즉 다른 측에서 요청에 대한 응답을 정상적으로 보냈다고 하더라도 브라우저에서 차단한다.
따라서 브라우저는 현재 위치한 리소스만 접근할 수 있고 다른 출처에 위치한 리소스는 접근할 수 없게 된다.
CORS
현재 대부분의 웹 개발은 프론트엔드와 백엔드가 분리되어 개발되고 있다. 이때 보통 프론트엔드가 백엔드로 REST API를 통해 데이터를 주고받게 되는데 프론트엔드의 출처와 백엔드의 출처가 다르므로 요청에 대한 응답을 정상적으로 수신할 수 없다.
이러한 경우 SOP를 우회해야한다. SOP를 우회할 수 있는 몇 가지 방법이 있는데 그 중 하나가 CORS(교차 출처 자원 공유)이다. CORS는 SOP를 안전히 우회할 수 있게 해준다.
CORS는 보통 백엔드 측에서 설정한다. 서버 측에서 CORS를 설정함으로서 API에 대한 응답을 보낼 때 Access-Control-Allow-Origin 헤더에 프론트엔드의 출처를 명시하면, 브라우저가 이를 해석하여 리소스에 대한 접근 여부를 결정한다.
Preflight
브라우저는 본격적으로 API에 대한 요청을 서버로 보내기 전에 OPTION 메소드로 사전 요청(Preflight)를 서버로 보낸다.
사전 요청 시에는 현재의 출처와 함께 어떤 메소드와 헤더로 요청을 보낼 것인지를 담아서 보내며 서버는 해당 요청을 받고 현재 서버에서 허용되는 출처와 메소드가 무엇인지를 알려준다.
만일 서버가 알려준 조건에서 하나라도 맞지 않는다면 실제 요청은 진행되지 않는다.
※ 어차피 Access-Control-Allow-Origin 헤더에 나의 출처가 포함되어 있지 않으면 응답을 나에게 보여주지 않는데 Preflight는 왜 있는걸까?
POST, PUT, DELETE는 요청이 서버로 전달되는 즉시 리소스에 영향이 간다. 따라서 실제 요청을 바로 보내버리면 서버측의 데이터에 영향이 갈 수 있다. 따라서 Preflight 과정을 통해 허용된 요청인지를 미리 판별하는 것.
16. Stateless, Connectionless
Stateless는 상태를 비저장하는 특성을 의미하는 용어로, 이전 요청에 대한 정보를 서버 측에서 저장하지 않는다는 것을 의미한다. 따라서 매 요청이 독립적이며 확정성이 뛰어나며 장애 감내성이 우수하다. 하지만 특정한 경우 상태를 유지해야할 필요성이 있을 수 있는데, Stateless의 경우 서버에서 상태를 저장하지 않으므로 추가적인 처리(클라이언트 측에서 토큰 저장, 상태 유지를 위한 인메모리 DB 사용 등)를 해줘야 한다.
Connectionless는 연결을 유지하지 않는 특성을 의미하는 용어이다. 크게 두 가지의 용어로 사용되는데, 통신 자체를 수행할 때 연결을 맺지 않는 경우에서 사용할 때가 있고(UDP의 경우) 통신을 하면서 연결을 맺되 통신이 종료된 이후 바로 연결을 끊어버리는 경우에서 사용할 때도 있다(HTTP 1.0의 방식)
HTTP의 Stateless 구조 채택 이유
Stateless는 추가적인 상태 저장 로직의 구현이 필요하지 않고 단순히 요청-응답만을 송수신하는 것으로 간단히 구현할 수 있다. 초기의 HTTP는 웹에서의 HTML을 요청하고 응답받기 위한 프로토콜이었기 때문에 상태 유지와 같은 부가적인 기능이 필요하지 않았다. 따라서 HTTP는 처음에 Stateless 구조로 구현되었다.
이후 웹이 비약적으로 발전하면서 Stateless 구조에 대한 부가적인 장점(서버의 자원 절약, 뛰어난 확장성) 등이 드러나기 시작했으며 이전 버전과의 호환성을 맞추기 위해 Stateless 구조가 유지되고 있다.
Connectionless의 성능 개선 방안
여기서 의미하는 Connectionless의 의미는 HTTP의 Connectionless로 이해하겠다.
초창기 HTTP는 TCP 연결을 맺은 후 요청과 응답을 송수신하고 연결을 끊는 구조였다. TCP는 연결을 수립할 때 3-way handshake를, 연결을 끊을 때 4-way handshake를 수행하며 매 요청과 응답마다 이를 반복하여 수행하다보니 성능적인 이슈가 있었다.
매 통신마다 연결을 수립하고 끊기 때문에 성능이 떨어지는 것이니, 한 번 연결을 맺으면 유지시키는 것으로 해결할 수 있다. 이는 HTTP 1.1의 Persistence Connection으로 구현되었다.
TCP keep-alive, HTTP Keep-alive
TCP의 keep alive는 연결이 수립된 상대방의 생존 여부를 확인하는 메커니즘이다. 연결이 수립된 후 상대방이 특정한 이유로 인해 강제적으로 네트워크에서 끊어질 수 있는데, 정상적인 4 way handshake가 이루어지지 않으니 한 쪽에서는 상대방과의 연결이 끊어졌는지 확인할 수 없다.
따라서 상대방으로부터 일정 시간 이상 아무런 패킷이 날라오지 않으면 상대방과의 연결이 제대로 수립되어 있는지 확인하는 목적으로 Keep Alive Probe 패킷을 날리게 되며 상대방이 이를 수신했다면 ACK를 보내는 것으로 연결 중임을 확인시키고, 그렇지 않다면 상대방과의 연결이 끊어졌다고 판단하고 연결을 끊어버린다.
HTTP의 Keep alive는 HTTP 1.1에서 추가된 기능으로, TCP 연결을 수립한 후 응답이 전달되어도 연결을 끊지 않고 유지하는 기능이다. HTTP 1.0에서는 Keep-alive 헤더를 명시적으로 보내야 작동하며 1.1 이상의 버전에서는 기본적으로 작동한다.
17. 라우팅, 포워딩
라우팅은 패킷을 목적지까지 보내기 위한 경로를 설정하는 과정이다. 네트워크의 정보를 기반으로 최적의 경로를 탐색한다.
네트워크 관리자가 패킷의 경로를 수동으로 지정(즉, 라우팅 테이블을 직접 구축)하는 정적 라우팅과 라우팅 알고리즘에 따라 자동으로 경로를 설정하는 동적 라우팅으로 나뉜다.
포워딩은 패킷을 특정한 경로로 전송하는 행위를 의미한다. 패킷에 기록된 주소를 보고 목적지 주소로 라우팅된 경로를 따라 패킷을 전달한다.
포워딩 과정
- 라우터가 패킷을 수신한다.
- IP 헤더를 확인하여 목적지 IP를 추출하고 헤더 내부에 존재하는 TTL을 1 감소시킨다. 이때 TTL이 0이 됐다면 패킷을 폐기한다.
- 라우팅 테이블을 기반으로 목적지 IP에 맞는 최적의 경로를 선택한다.
- 목적지 IP 주소가 로컬 네트워크라면 해당 단말로 전송하고, 아니라면 다음 라우터로 전송한다.
라우팅 알고리즘
라우팅 알고리즘은 최적의 경로를 도출하기 위해 라우팅 테이블을 관리하는 알고리즘이다. 크게 거리 벡터 알고리즘과 링크 상태 알고리즘으로 나뉜다.
거리 벡터 알고리즘은 경로 결정을 거리에 의존하는 방식으로 벨만-포드를 사용한다. "거리"는 라우터 수, 레이턴시 등과 같은 요소로 측정하며 자신의 라우팅 테이블의 정보를 주변 이웃과 교환하며 최단 거리가 발견한다면 갱신한다.
왜 벨만-포드를 사용할까?
다익스트라 알고리즘과 비교하여 수행 속도도 느리며, 음수 간선이 존재할 수가 없는 환경이라 벨만-포드를 사용할 이유가 없어 보인다.다익스트라는 전체 네트워크 상황을 알아야만 사용할 수 있다. 하지만 거리 벡터 알고리즘은 주변 라우터와의 데이터를 교환하는 방식이기 때문에 전체 네트워크 상황을 알 수 없어 사용할 수 없다. 벨만-포드에서는 주변 정점들로부터 거리를 갱신하는 과정을 반복하는 것으로 최단 거리를 도출해낼 수 있으므로 거리 벡터 알고리즘에서는 벨만-포드를 사용한다.
링크 상태 알고리즘은 간선에 대한 정보를 다른 모든 라우터에게 전달하여 최단 경로를 도출하는 알고리즘으로, 모든 라우터는 전체 간선에 대한 정보를 알 수 있으므로 다익스트라 알고리즘을 사용한다.
라우팅 프로토콜
라우팅 프로토콜은 라우터 간의 라우팅 정보 교환 혹은 라우팅 테이블의 관리를 수행하는 프로토콜이다. AS 내외부에 따라 IGP, EGP로 구분되며 라우팅 알고리즘이 거리 벡터냐(RIP), 링크 상태냐(OSPF)서도 나뉘어져있다.
포워딩 테이블
라우팅 알고리즘으로 경로가 결정되면 실제로 패킷을 보내야 한다. 포워딩 테이블은 해당 주소로 보내기 위해 어느 라우터로 보내야하는지가 기록되어 있고 이 정보를 기반으로 패킷을 다음 홉으로 보내게 된다.
18. 로드밸런서
로드밸런서는 클라이언트의 요청을 여러 서버로 분산시켜주는 장치를 의미한다. 서버를 다중화하여도 트래픽이 하나의 서버로 몰리게 되면 결국 서버에 큰 부담이 가해지게 되는데 이러한 부담을 분산해준다.
뿐만 아니라 특정 서버가 다운되었을 때 해당 서버로 요청을 보내지 않음으로서 고가용성을 보장하고 서버를 stateless하게 만든다면 scale-out 시 로드밸런서에 새로운 서버를 붙이기만 하면 되므로 확장성도 상승한다. TLS 터미네이션을 통해 보안 통신에서 서버의 부담을 완화시킬 수도 있다.
L4 로드밸런서, L7 로드밸런서
로드밸런스는 작동하는 계층에 따라 L4 로드밸런서와 L7 로드밸런서로 나눌 수 있다. (사실 다른 계층에서도 존재하지만 L4 미만의 계층에는 포트 번호를 이용할 수 없어 자주 쓰이지는 않는다)
L4 로드밸런서는 포트 번호와 프로토콜을 기반으로 부하를 분산시킨다. 패킷의 헤더만 확인하여 동작할 수 있으므로 처리 속도가 빠르다.
L7 로드밸런서는 응용 계층에서 동작하므로 응용 계층 프로토콜인 HTTP의 내용을 분석하여 부하를 분산시킬 수 있다. 따라서 경로 기반 라우팅이 가능하며 TLS 터미네이션도 가능하다.
로드밸런싱 알고리즘
- 정적 로드 밸런싱
- 사전에 정의된 규칙에 따라 로드밸런싱
- 라운드 로빈
- 여러 서버에 순차적으로 트래픽을 할당
- 가중치 기반 라운드 로빈
- 서버 별 우선순위에 따라 가중치를 두어 우선순위가 더 높다면 더 많은 요청을 부담할 수 있게하는 라운드 로빈 기반 로드밸런싱 알고리즘
- IP 해시
- 클라이언트 IP 주소에 해시 함수를 적용시킨 후 특정한 규칙에 따라 알맞은 서버에 트래픽을 분산
- IP를 해싱하므로 같은 네트워크를 사용한다면 동일한 서버로의 접속이 보장
- 최소 연결 방식
- 가장 연결이 덜 되어 있는 서버를 우선하여 트래픽을 처리
장애 관리
로드밸런서는 연결된 서버 중 하나가 다운되었을 때 트래픽을 해당 서버로 보내지 않는 역할도 수행한다. 다른 서버의 다운 여부를 판별하기 위해 헬스 체크를 수행한다.
헬스 체크는 자신과 연결된 서버에게 주기적으로 특정한 요청을 보내는 것으로 서버가 해당 요청에 대한 응답을 보내지 않으면 다운된 것으로 간주하고 더 이상 해당 서버로 트래픽을 보내지 않는다.
DNS 로드밸런싱
따로 로드밸런서를 두지 않고 DNS를 사용하여 트래픽을 분산시키는 방법이다. DNS 서버는 특정 도메인에 대해 IP 리스트를 가지고 있으며 클라이언트가 IP를 요청할 때 적절한 로드밸런싱 알고리즘을 사용하여 각각 다른 IP를 응답함으로서 로드밸런싱을 구현한다.
헬스 체크는 따로 불가능하다.
19. 서브넷 마스크, 게이트웨이
초창기 IPv4의 주소 표현 방식은 Classful Addressing 방식으로, 5개의 서로 다른 주소 구분을 가졌다. 만일 특정한 사용자 집단이 클래스 C 범위(총 256개의 주소)의 주소를 요청했다면 해당 범위 내의 주소를 할당했었는데 만약 그룹 내 사용할 IP의 개수가 10개밖에 되지 않는다면 나머지 주소들은 낭비된다.
IPv4의 주소 고갈 문제가 대두되며 이러한 비효율적인 주소 할당을 개선하고자 Classless Addressing 방식을 고안하게 되는데 이때 사용되는 방식이 CIDR이다. 이 CIDR에서 네트워크 주소와 호스트 주소를 구분시켜주는 것이 바로 서브넷 마스크이다.
게이트웨이는 두 개 이상의 네트워크를 연결시켜주는 장치를 의미한다. TCP/IP에서 볼 때는 '라우터' 그 자체를 의미하나, 응용 계층까지 확대하여 보았을 때는 다른 네트워크, 프로토콜을 사용하는 두 영역을 연결시켜주는 장치를 의미한다.
게이트웨이는 여러 프로토콜 간의 변환을 담당하므로 어느 계층에서도 동작이 가능하며, 이 것이 스위치와 라우터의 가장 큰 차이점이다.
서브넷 마스크의 표현 방식
서브넷마스크는 '255.255.255.0' 혹은 '/24'와 같은 방식으로 표기하며 '255.255.255.0'의 의미는 수를 이진수로 나타냈을 때 비트가 1인 영역까지를 네트워크 주소로 나타낸다는 뜻이며, 이러한 방식이 인간이 보기에 직관적이지 않기 때문에 '/24'와 같은 표기도 같이 사용된다. 이는 주소의 앞 24비트가 네트워크 주소라는 의미이다.
Q. 255.0.255.0과 같은 서브넷 마스크도 가능한가?
불가능하다. 서브넷 마스크는 연속된 1이 나타나도록 구성한 후 이후에는 0만이 나타나야한다. 255.0.255.0를 이진수로 표기했을 때 11111111.0.11111111.0.0이므로, 불가능한 서브넷 마스크이다.
20. 멀티플렉싱, 디멀티플렉싱
멀티플렉싱과 디멀티플렉싱은 전송 계층에서 동작하는 일련의 과정을 의미한다. 여러 개의 데이터를 모아 하나의 연결로 보내는 과정을 멀티플렉싱이라고 한다. 반대로, 하나의 데이터를 받아 적절한 응용 프로그램으로 전달하는 과정을 디멀티플렉싱이라고 한다.
만일 여러 개의 응용 프로그램이 네트워크를 사용하고 있을 때 각각의 응용 프로그램마다 네트워크의 연결을 새로 수립해야한다면 비효율적일 것이다. 멀티플렉싱과 디멀티플렉싱을 이용하면 하나의 네트워크 연결에서 여러 개의 네트워크 통신을 가능하게 한다.
디멀티플렉싱의 과정
다른 프로세스에서 전달된 여러 개의 데이터들이 어떤 프로세스로 전달되어야 하는지 알기 위해 TCP, UDP 헤더의 포트 번호를 확인한다. 포트 번호는 곧 컴퓨터 내부에서 네트워크를 사용하는 프로세스들의 논리적인 식별자이기 때문에 목적지 포트 번호를 통해 어떤 프로세스로 전달되어야 할 지 알 수 있다.
어떤 프로세스로 전달되어야 하는지가 식별되면 해당 포트 번호로 열려있는 소켓을 통해 데이터를 전달한다.
21. XSS
XSS는 사이트 간 스크립팅으로, 자바스크립트를 이용하면 쿠키와 세션 등의 사용자 정보를 탈취하거나 비정상적인 기능을 실행시킬 수 있음을 이용하는 공격 기법이다.
스크립트의 내용이 일회성이냐, 서버의 DB에 들어가서 지속적이냐에 따라 비지속적, 지속적 공격으로 나뉜다.
영문 약자가 CSS가 아닌 이유는 Cascading Style Sheets와 헷갈릴 우려가 있기 때문.
CSRF
CSRF는 사이트 간 요청 위조를 의미하며 자신의 의지와 무방하게 공격자가 의도한 행위를 수행하여 웹 페이지에 여러 악영향을 끼치는 것을 의미한다.
