※ 질문 출처: https://github.com/VSFe/Tech-Interview
1. Key
- 슈퍼키
- 테이블의 행을 고유하게 식별할 수 있는 속성들의 집합
- 고유하게 식별할 수 있는 모든 속성들의 쌍
- 후보키
- 슈퍼키 중에서 유일성과 최소성을 모두 만족시키는 요소를 의미
- 최소성을 만족하므로 이 이상으로 키의 집합을 줄여버리면 유일성을 상실
- 기본키
- DBA에게 선택된 후보키를 의미
- NOT NULL과 UNIQUE 제약 조건이 자동으로 걸림
- 대체키
- 기본키로 선택되지 못한 후보키의 집합을 의미
- 외래키
- 현재 테이블과 연관되어 있는 다른 테이블의 행을 식별하는 키를 의미
- 정규화로 인해 나눠진 테이블을 조인하기 위한 연결 고리
기본키의 수정
기본키는 DML를 사용하여 기본키에 가해져 있는 NOT NULL과 UNIQUE를 만족시킨다면 수정이 가능하다.
먼저 MySQL은 기본키를 기준으로 Clustered Index를 구성한다. 기본키를 수정하게 되면 기본키에 걸려있는 인덱스를 재구성해야 한다. 따라서 오버헤드가 크다. (이때, Clustered Index라고 해서 기본키를 수정하면 데이터의 물리적인 저장 위치가 바뀌지는 않는다)
또한 해당 기본키가 다른 테이블의 외래키로 제약 조건이 걸려있다면 다른 테이블에 존재하는 값들까지 모두 변경할 필요가 있다. 이 역시 오버헤드가 크다.
보통 기본키는 절대 바뀌지 않는 유일한 값(Auto Increment, UUID)등을 사용하여 수정을 할 일도 거의 없을 뿐더러 위와 같은 이유에서 수정을 하지 않는 것이 좋다.
기본키 없는 테이블
MySQL은 기본키 없이 테이블을 생성할 수 있다. 이것은 사용자의 눈에만 보이지 않는 것으로 InnoDB는 내부적으로 기본키에 해당하는 임의의 칼럼을 추가해버린다. 하지만 해당 컬럼은 사용자가 접근할 수 없고 InnoDB의 내부적 동작에서만 사용된다.
외래키의 NULL
PK와 달리, FK에는 NULL을 넣을 수 있다. 모든 레코드가 다른 테이블과 관계를 맺지 않을 수 있고 관계를 맺고 있지만 상대쪽 테이블의 레코드가 아직 삽입되지 않은 상태일 수도 있다.
이런 경우에도 테이블에 레코드를 정상적으로 삽입할 수 있어야 하기 때문에 FK에는 NULL을 허용한다.
UNIQUE 칼럼의 쿼리 성능
특정 칼럼에 UNIQUE 제약 조건을 걸어두면 UNIQUE 컬럼에는 자동으로 세컨더리 인덱스를 생성하기 때문에 해당 컬럼을 조건으로 하는 쿼리를 수행하면 자연스레 커버링 인덱스가 될 확률이 높아진다.
또한 UNIQUE는 값이 1개임을 보장하므로 DB에서 조건에 일치하는 값을 찾았을 때 더 이상 탐색을 수행하지 않고 조기 종료할 수 있다.
이러한 CPU 레벨에서 드는 비용이므로 UNIQUE가 아닌 인덱스와 비교했을 때는 엄청나게 유의미할 정도로의 차이가 나진 않는다.
2. RDB, NoSQL
- RDB
- 관계형 데이터베이스
- 데이터들을 행과 열로 이루어진 표의 형태로 저장하고 데이터 사이의 종속성을 관계로 표현하는 데이터베이스
- 데이터들이 체계적으로 구조화되어 있고 데이터의 일관성을 보장하기 위해 여러 제약 조건을 지원
- 데이터의 중복을 방지하기 위해 정규화 수행
- 트랜잭션을 통해 원자성, 일관성, 독립성, 지속성을 보장(ACID)
- 데이터를 질의하기 위해 SQL 사용
- NoSQL
- Not only SQL의 줄임말
- SQL을 사용하지 않는 모든 종류의 데이터베이스를 의미
- 데이터의 체계적인 구조화를 지양
- 정규화를 하지 않고 있는 그대로의 데이터를 저장하는 것을 선호
- 사용자가 언제든 동시 접근 가능(BA)
- 동기화로 인해 데이터가 시간에 따라 변할 수 있음(S)
- 분산된 데이터가 최종적으로는 일관된 상태를 유지(E)
NoSQL의 장단점
- 장점
- 데이터 모델이 유연하여 구조에 제약을 받지 않음
- 데이터를 있는 그대로 삽입하며, JOIN이 없으므로 수평적 확장에 용이
- RDB와 비교하여 뛰어난 성능을 발휘할 때가 있음
- 단점
- 트랜잭션을 지원하지 않으므로 데이터의 일관성이 떨어짐
- 데이터의 중복이 발생
RDB의 부하 가능성
RDB는 NoSQL과 다르게 정규화를 수행하여 데이터를 여러 분산된 테이블에 나눠 저장한다. 분산된 데이터를 조회하려면 조인하여 데이터를 가져와야하는데 조인은 비용이 큰 작업이다. NoSQL은 데이터를 있는 그대로 저장하므로 조인할 필요가 없고 따라서 이 경우 RDB에 많은 부하가 걸릴 수 있다.
RDB는 데이터의 정합성을 보장하기 위해 트랜잭션을 사용한다. 이러한 작업 역시 부하가 걸리는 작업이기 때문에 데이터의 크기가 커질 수록 NoSQL에 비해 성능적인 차이가 커지게 된다.
NoSQL 활용 사례
NoSQL은 데이터 모델이 유연하므로 데구조가 자주 바뀌는 데이터(로그 등)를 저장할 때 유용하다.
수평적 확장이 용이하므로 매우 많은 데이터를 저장하여 데이터베이스를 분산시켜야할 때 NoSQL을 사용할 수 있다.
데이터의 일관성이 중요하지 않으며 복잡한 쿼리가 필요하지 않을 떄는 NoSQL을 사용하여 데이터의 유연성, 확장성을 확보할 수 있다.
3. 트랜잭션, ACID
트랜잭션은 데이터베이스에서 수행되어야 하는 논리적인 작업 단위를 의미한다. 작업을 시작하고 정상적으로 수행됐다면 내용을 DB에 영구 반영(커밋) 시킬 수도 있고, 혹은 그 이전의 상태로 돌아갈 수도 있다(롤백)
트랜잭션은 ACID라고 불리는 4가지 주요 특성이 존재한다.
- 원자성(Atomicity)
- 트랜잭션은 논리적인 작업의 단위이므로 작업 전체가 성공하거나 실패하여야 함
- 특정 트랜잭션이 A, B, C라는 작업으로 묶여있다면 A와 B는 성공했지만 C가 실패했다면 A와 B는 성공했어도 롤백되어야 함
- 일관성(Consistency)
- 트랜잭션이 종료되고 난 뒤의 변경된 데이터는 일관된 상태(제약 조건 등을 만족)여야 함
- 트랜잭션이 종료되어도 DB의 상태는 논리적으로 바른 상태여야 함
- 고립성(Isolation)
- 각 트랜잭션은 독립적이여야 함
- 특정 트랜잭션이 다른 트랜잭션에 영향을 끼치면 안됨
- DB의 고립 수준은 설정 가능
- 지속성(Durability)
- 트랜잭션이 커밋되고 난 뒤 데이터는 영구적으로 저장되어야 함
- DB에 문제가 생기더라도 로그 등을 통해 복구가 가능해야 함
지속성 보장 기법
- Write-Ahead Logging
- 트랜잭션의 내용을 디스크에 쓰기 전 먼저 로그에 기록하는 방식
- 로그에 작업 내용을 쓰는데 성공했을 경우에 정상적으로 디스크에 씀
- 로그에 기록한 이후 서버가 다운됐다 하더라도 남아있는 로그로 복구 가능
- MySQL에서는 Redo Log라고 함
트랜잭션의 활용 사례
특정 작업이 하나의 쿼리가 아닌 여러 개의 쿼리로 이루어진다고 하자.
예를 들어 계좌이체라는 작업이 있다. A 계좌에서 특정 금액을 뺀 후 B 계좌에 특정 금액을 더해줘야 할 것이다. 만일 이 작업에 트랜잭션을 걸지 않고 각각의 쿼리를 따로 실행할 경우 A 계좌에서 특정 금액을 빼는데 까지는 성공했지만 B 계좌에 특정 금액을 더하는 쿼리가 실패할 경우 A 계좌에는 돈이 빠져나갔지만 B 계좌에는 돈이 들어오지 않는 상황이 발생한다.
이와 같이 특정 작업이 여러 개의 쿼리로 이루어져 있을 경우 해당 작업을 하나의 트랜잭션으로 묶어 활용할 수 있다.
읽기 트랜잭션
읽기는 데이터베이스의 상태에 변화를 주지 않으므로 트랜잭션을 걸지 않아도 무방하다.
하지만 격리 수준을 명시적으로 설정하는 경우라던지 여러 개의 조회 작업을 수행할 때 조회의 일관성을 보장해야하는 경우라면 트랜잭션을 사용할 수 있다.
4. 트랜잭션 격리 수준
트랜잭션의 격리 수준은 트랜잭션을 수행할 때 고립성의 정도를 결정하는 옵션이다.
크게 4가지의 격리 수준이 존재한다.
- READ UNCOMMITED
- 다른 트랜잭션에서 커밋하지 않은 데이터도 볼 수 있는 격리 수준
- 다른 트랜잭션의 작업이 완료되지 않았는데도 볼 수 있는 Dirty Read 발생 가능
- READ COMMITTED
- 다른 트랜잭션에서 커밋한 데이터만 볼 수 있는 격리 수준
- 다른 트랜잭션이 현재 데이터를 수정할 경우 읽어온 데이터가 달라지는 NON-REPEATABLE READ 발생 가능
- REPEATABLE READ
- 한 트랜잭션 내에서 읽어온 데이터의 일관성을 보장하는 격리 수준
- 다른 트랜잭션이 현재 테이블에 값을 삽입할 경우 새로운 데이터가 읽어지는 Phantom Read 발생 가능(하지만 드묾)
- MySQL의 기본 격리 수준
- SERIALIZABLE
- 트랜잭션을 순차적으로 진행시켜 데이터의 정합성을 보장하는 방법
- 동시 처리량이 크게 떨어져 일반적으로 사용되지 않음
트랜잭션 격리 수준 구현
- READ UNCOMMITED
- InnoDB 버퍼 풀에 있는 내용을 그대로 읽어 오는 식으로 동작
- READ COMMITTED
- 쿼리 실행 시 Undo Log에 있는 내용을 읽어오는 식으로 동작
- 갭 락 없이 레코드 락만 적용
- REPEATABLE READ
- 트랜잭션 시작 시 Undo Log에 있는 내용을 읽어오는 식으로 동작
- 자신이 수행한 트랜잭션 ID에 해당 하는 정보는 그대로 보여줌
- 넥스트 키 락 적용
- SERIALIZABLE
- REPEATABLE READ와 유사하지만 모든 SELECT 문에 공유 락을 걸도록 변경
모든 DBMS가 4가지의 격리 수준을 모두 구현하고 있진 않다. MySQL의 경우 4가지의 격리 수준을 모두 구현하고 있지만 Oracle DB의 경우 REPEATABLE READ를 구현하고 있지 않다.
이는 락을 이용하여 구현할 수 있기 때문이기도 하고 READ COMMITED 수준의 격리 수준으로도 충분하기 때문인 것으로 추정된다.
Undo, Redo Log
InnoDB에는 버퍼 풀이 존재한다. Disk의 IO 작업은 매우 큰 비용이 들기 때문에 메모리 상에 존재하는 버퍼 풀에 데이터를 저장해두는 것이다. (그리고 주기적으로 한 번에 디스크에 쓰며 이는 백그라운드 스레드가 수행한다)
하지만 버퍼 풀은 메모리에 존재하기 때문에 DB에 장애가 발생하면 해당 데이터는 휘발된다. 이렇게 되면 지속성을 보장할 수 없게 되기 때문에 데이터를 변경하고 커밋하기 전에 먼저 리두 로그에 기록한 뒤 데이터를 변경시킨다.
리두 로그에 있던 데이터를 쓰는 도중 장애가 발생한다면 (정확히 말하자면 페이지의 일부만 기록된 상태에서 장애 발생 시) 해당 페이지는 복구할 수 없다. 리두 로그는 변경할 페이지의 위치와 변경 값만을 기록하기 때문이다. 나머지 변경 값을 기록해도 다른 바이트가 이미 손상된 상태이기 때문에 온전히 페이지를 복구할 수 없다.
따라서 연속된 데이터 영역으로 구성된 Double write Buffer를 따로 두어 기록해둔 후 해당 내용을 디스크에 다시 한 번 더 쓴다. 이때는 전체 페이지의 내용이 저장된다. 이 데이터를 이용하여 이전 상태의 전체 블록을 재현한 후 리두 로그의 내용을 기반으로 복구하게 된다.
Undo 로그는 트랜잭션의 ROLLBACK을 위한 로그이다. 데이터를 변경시킬 때 변경시키기 전의 데이터를 저장해둔다. 이후 트랜잭션을 수행하다 ROLLBACK을 해야하는 경우 Undo 로그의 내용을 기반으로 롤백시킨다.
스토리지 엔진
(MySQL) 기준 MySQL의 서버의 구조는 매우 크게 보았을 때 MySQL 엔진과 스토리지 엔진으로 나뉘어 진다.
MySQL 엔진은 쿼리를 파싱하고 옵티마이저를 통해 최적의 쿼리 실행 계획을 수립하는 역할이다.
이후 실행 계획을 수립한 뒤 실제로 데이터를 가져오는 작업을 수행해야하는데 이러한 작업을 수행하는 주체가 스토리지 엔진이다. 스토리지 엔진은 여러 종류가 존재하고 원하는 엔진을 쓸 수 있지만 일반적으로 기본 스토리지 엔진인 InnoDB를 사용한다.
5. 인덱스
인덱스는 데이터베이스의 데이터의 레퍼런스를 특정한 자료구조에 삽입하여 해당 컬럼을 기준으로 조회를 할 때 데이터의 조회를 빠르게 할 수 있게 하는 자료구조이다.
인덱스와 DML
인덱스는 조회의 속도를 높여주지만 반대로 데이터를 수정할 때는 인덱스의 수정을 필요해지므로 수정의 속도는 느려진다. 따라서 데이터의 수정이 잦다면 인덱스를 걸지 않는 것이 유리할 수도 있다.
인덱스가 A 컬럼에 걸려있다고 하자. 이때 B 컬럼의 데이터를 수정한다면?
B 컬럼에는 인덱스가 걸려있지 않으므로 데이터를 수정할 때 인덱스까지 수정하지 않고, 따라서 수정하는 속도가 느려지지는 않는다.
ORDER BY, GROUP BY와 인덱스
인덱스의 중요한 성질 중 하나는 조건으로 건 컬럼이 정렬된 순서대로 레퍼런스들이 저장된다는 점이다. 이러한 점을 이용하면 정렬을 이용하는 Order by 조건을 최적화할 수 있다.
만일 인덱스가 없는 상태에서 Order by를 수행한다면 데이터를 가져온 뒤 추가적으로 정렬을 수행해야한다. 하지만 인덱스를 타는 상태에서 Order by가 수행된다면 인덱스를 타면서 데이터를 그냥 가져오기만 해도 데이터는 이미 정렬된 상태를 유지하므로 정렬에 대한 비용이 없어진다.
Group by 역시 특정한 컬럼을 기준으로 그룹핑을 하기 위해 데이터를 가져오고 같은 컬럼끼리 묶은 뒤 그룹핑하는 과정이 필요한데, 인덱스를 타며 데이터를 가져온다면 데이터는 이미 정렬된 상태를 유지하므로 그 상태에서 바로 그룹핑을 할 수 있다. 따라서 그룹핑에 대한 비용이 크게 줄어든다.
이 때문에 테이블에 적절한 인덱스를 걸어주는 것으로 단순한 조회뿐만 아니라 Order by와 Group by의 역시 크게 최적화할 수 있다.
PK, FK와 인덱스
MySQL 기준 PK와 FK 모두 기본적으로 인덱스가 생성된다. PK의 경우 클러스터드 인덱스가 생성되며 FK는 세컨더리 인덱스가 생성된다.
이는 절대적인것은 아니며 클러스터드 인덱스가 다른 컬럼에 이미 생성되어 있을 경우 PK와 FK에는 인덱스를 걸지 않을 수 있다.
인덱스와 물리적 저장 위치
인덱스는 데이터의 물리적 저장 위치에도 영향을 끼친다. 정확히 말하자면 클러스터드 인덱스가 영향을 끼치는 것으로, 클러스터드 인덱스는 실제 정렬된 순서대로 데이터를 저장한다. 세컨더리 인덱스의 경우 물리적 저장 위치에 대한 레퍼런스만 저장하기 때문에 물리적 저장 위치를 변경하진 않는다.
NoSQL의 인덱스
대부분의 NoSQL 역시 인덱스를 지원한다. RDB에 동일하게 B-Tree 기반의 인덱스도 생성할 수 있지만 텍스트 검색에 최적화된 역색인 등을 지원하기도 한다. 기본적인 원리는 RDB와 크게 다르지 않다.
커버링 인덱스
인덱스가 복합 컬럼으로 지정됐다고 하자(A, B) 이 경우 A를 기준으로 먼저 정렬한 후 이후 A가 동일한 값을 가진 데이터들에 대해 B를 기준으로 정렬한다. 따라서 커버링 인덱스를 위해 인덱스를 건 컬럼의 순서대로 컬럼을 명시해야한다. (하지만 반드시 모든 컬럼을 조건을 걸 필요는 없다)
만일 인덱스가 (A, B, C)일 경우 A 혹은 A, B는 인덱스를 탈 수 있지만 B 혹은 B, C는 인덱스를 탈 수 없다. 하지만 순서를 바꿔서 인덱스를 탈 수 있는 경우라면 옵티마이저가 알아서 순서를 바꿔 인덱스를 탄다는 점에 유의. (만일 조건을 B, A라고 적어도 알아서 A, B로 바꿔서 인덱스를 탄다)
6. 클러스터링, 리플리케이션
- 클러스터링
- DB를 수평적인 구조로 분할
- SPOF 회피 가능
- Active & Active 구조
- 분산한 DB들을 모두 Active 상태로 두고 운용하는 것
- 부하 분산, 장애 지점 다중화 등 다양한 장점 존재
- 여러 DB가 동시에 쓰기를 처리하므로 데이터 동기화 처리가 복잡
- Active & StandBy 구조
- 하나의 DB만 Active로 두고 나머지 DB는 StandBy 상태로 두고 운용하는 것
- StandBy DB는 대기하다가 Active DB에 장애 발생 시 Active로 전환됨
- 부하 분산이 되진 않지만 고가용성은 확보 가능
- 리플리케이션
- DB를 수직적인 구조로 분할
- 쓰기를 담당하는 하나의 Master 노드와 읽기를 담당하는 여러 개의 Slave 노드로 구성
- 슬레이브 노드가 마스터 노드의 로그 파일을 복사한 후 그대로 데이터를 저장하는 방식으로 데이터를 비동기적으로 동기화
- 대부분의 요청은 읽기가 대부분이므로 대부분의 경우 부하 분산의 효과도 누릴 수 있음
- 장애 발생 시
- 슬레이브 노드
- 슬레이브 노드에 장애가 발생했다면 다른 슬레이브 노드가 해당 노드의 작업까지 같이 분산해서 수행
- 이후 장애 복구 시 마스터 노드로부터 변경 로그를 수신받고 데이터를 동기화
- 마스터 노드
- 마스터 노드의 장애가 감지되면 남아있는 슬레이브 노드들 사이에서 새롭게 마스터 노드를 선출
- 슬레이브 노드
분산 트랜잭션
단일 환경에서는 DB에서 지원하는 트랜잭션을 사용하면 트랜잭션의 ACID를 그대로 가져갈 수 있지만 분산 환경에서는 물리적으로 DB가 분리되어 있기 때문에 이러한 방법이 불가능하다.
따라서 분산 환경에서 데이터의 정합성을 보장하기 위한 여러 관리 방식이 존재한다.
- 2PC
- 트랜잭션을 2가지 페이즈에 나눠서 수행
- 분산 트랜잭션을 관리하는 코디네이터 존재
- 먼저 코디네이터가 각 DB로 부터 데이터를 쓰도록 함
- (준비 페이즈) 이후 각 DB에게 커밋 가능 여부를 질의, 하나라도 불가능하다는 답변이 오면 모든 변경 사항을 ROLLBACK
- (커밋 페이즈) 모두가 가능하다면 모든 DB에 커밋 명령을 내림
- 커밋되기 전까지 Row 단위 Lock이 지속. 따라서 코디네이터에 장애가 발생해버리면 Blocking이 유지
- SAGA
- 트랜잭션을 작은 로컬 트랜잭션으로 분리하고 실패 시 보상 작업(Undo)을 수행
- 트랜잭션을 비즈니스 로직에 맞춰 순차적으로 수행하고 다음 작업 대상에게 이벤트로 전달
- 만일 특정 작업 중 오류가 발생하여 롤백이 필요하다면 보상 트랜잭션을 전파하여 롤백이 된 것처럼 구현
리플리케이션과 정합성
리플리케이션에서 마스터 노드에서 쓰기 작업이 일어난 이후 슬레이브 노드에게 데이터 동기화 작업이 이루어지지 않았을 때 사용자가 읽기 작업을 수행할 경우 원래 존재해야하는 데이터가 사용자에게 보이지 않는 문제가 발생할 수 있다.
먼저 마스터 노드의 커밋 자체를 뒤로 미루는 방법이 있다. 슬레이브 노드로 부터 트랜잭션을 잘 수신했다는 ACK를 받기 전까지는 커밋을 하지 않는 것이다. 성능이 조금 떨어질 수는 있지만 데이터의 정합성이 지켜질 확률은 올라간다.
두 번째는 마스터 노드가 쓰기를 수행한 후 특정 시간까지는 읽기 작업도 마스터 노드가 수행하거나 슬레이브 노드로의 데이터 전송을 동기적으로 수행하는 방법이 있다. 거의 확실하게 정합성을 지킬 수 있지만 리플리케이션의 장점이 다소 퇴색된다.
혹은 마스터에서 쓰기 작업을 완료했다면 그 내용을 캐시에 쓰고 캐시에 내용이 있다면 캐시에 존재하는 내용을 우선적으로 보여주는 방법도 있다. 이후 슬레이브 노드에 쓰기 작업이 완료되면 캐시를 만료시킨다.
다중 트랜잭션의 교착 상태
만일 트랜잭션 A가 컬럼 a를 잠그고 컬럼 b를 잠그려고 한다고 하자. 이때 트랜잭션 B가 동시에 컬럼 b를 잠근 후 컬럼 a를 잠그려한다면 두 트랜잭션 사이에서 교착 상태가 발생하게 된다.
아래와 같은 해결방안이 있다.
- 트랜잭션의 타임아웃을 설정한 후 타임아웃이 지나면 트랜잭션을 실패시키기
- 트랜잭션의 락을 거는 순서를 통일
샤딩
샤딩은 수평적으로 분할한 DB에 적절한 로직에 따라 데이터를 분산 저장하는 것을 의미한다. 만일 단일 DB에 데이터를 분산 저장하면 이를 파티셔닝이라고 한다.
리플리케이션과 비교했을 때 복잡도는 올라가지만 전반적인 성능은 샤딩이 더 높다. 쓰기와 읽기가 모두 분산되고 데이터 또한 분산화되기 때문에 대량의 데이터 역시 저장하기 수월하다.
하지만 리플리케이션은 데이터의 정합성을 지키기 수월하다는 큰 장점이 있다. 샤딩의 경우 특정 샤드에 장애가 발생하면 해당 구역에 저장된 데이터를 읽을 수 없지만 리플리케이션은 상대적으로 이런 장애 발생에 대해 조금 더 유연하다는 장점이 있다.
즉 쓰기의 비율이 높고 대용량의 데이터가 저장되는 경우 샤딩이 유리하다. 하지만 데이터의 정합성이 더 중요하다면 리플리케이션을 사용하는 것이 유리하다.
7. 정규화
데이터를 저장할 때 중복된 데이터를 저장하지 않기 위해 테이블을 적절히 나누는 것을 정규화라고 한다.
이를 통해 데이터를 수정할 때 발생할 수 있는 이상현상들을 방지할 수 있지만 무거운 조인 연산이 필요하다.
정규화는 1, 2, 3, BCNF, 4 5 총 6개의 종류가 있으며 일반적으로는 3 ~ BCNF까지 수행한다.
- 제1정규화
- 테이블의 컬럼이 원자값을 갖도록 테이블을 분해
- 하나의 컬럼에는 하나의 값만 갖도록 함
- 제2정규화
- 부분적 함수 종속을 제거
- 모든 기본키의 요소가 다른 컬럼들을 유일하게 결정지어야 함
- 제3정규화
- 이행적 함수 종속을 제거
- 기본키가 아닌 요소가 다른 컬럼을 결정짓는다면 이행적 함수 종속이 존재하는 것
- 컬럼에 A, B, C가 존재하고 A가 기본키, C는 기본키가 아닌 B에 의해 결정된다고 하자
- A에 의해 B가 결정되고 B가 결정되므로 C가 결정된다. 즉 A -> B -> C이므로 이러한 상황을 이행적 함수 종속이라 한다.
- BCNF
- 모든 결정자가 후보키가 되도록 테이블을 분해
- 어떤 컬럼이 다른 컬럼을 결정짓는다면 해당 컬럼은 후보키가 되어야 함
이상현상
- 삽입 이상
- 새 데이터를 삽입하기 위해 불필요한 데이터(NULL 포함)를 함께 삽입해야하는 이상현상
- 갱신 이상
- 특정 값을 갱신했을 때 그 속성의 다른 속성값과 불일치가 발생하는 이상현상
- 삭제 이상
- 삭제할 때 꼭 필요한 데이터까지 함께 삭제되는 이상현상
정규화로인한 테이블의 변화
1 정규형
| 학번 | 이름 | 연락처 |
|---|---|---|
| 1001 | 홍길동 | 010-1234-5678, 010-9876-5432 |
↓
| 학번 | 이름 | 연락처 |
|---|---|---|
| 1001 | 홍길동 | 010-1234-5678 |
| 1001 | 홍길동 | 010-9876-5432 |
2 정규형
| 학번 | 수강과목 | 교수이름 |
|---|---|---|
| 1001 | 수학 | 이순신 |
| 1001 | 영어 | 김유신 |
수강 과목만이 교수 이름을 결정 중 -> 부분적 함수 종속
↓
| 학번 | 수강과목 |
|---|---|
| 1001 | 수학 |
| 1001 | 영어 |
| 과목 | 교수 |
|---|---|
| 수학 | 이순신 |
| 영어 | 김유신 |
3정규형
| 학번 | 이름 | 학과 | 학과장 |
|---|---|---|---|
| 1001 | 홍길동 | 컴퓨터공학 | 이순신 |
| 1002 | 김철수 | 경영학 | 김유신 |
학과가 학과장을 결정 중 -> 이행적 함수 종속
↓
| 학번 | 이름 | 학과 |
|---|---|---|
| 1001 | 홍길동 | 컴퓨터공학 |
| 1002 | 김철수 | 경영학 |
| 학과 | 학과장 |
|---|---|
| 컴퓨터공학 | 이순신 |
| 경영학 | 김유신 |
역정규화
정규화를 수행하면 테이블이 나눠지게 되고 추후 조회를 위해서는 나눠진 테이블을 JOIN으로 합치는 과정이 필요하다. JOIN은 비용이 큰 연산이기 때문에 정규화로 나눠둔 테이블을 다시 합치기도 하는데 이를 역정규화라고 한다.
조인을 줄이기 위해 나눠뒀던 테이블을 합치거나, 계산량을 줄이기 위해 count 컬럼을 만들어버린다거나, 하나의 테이블 자체를 나눠서 분리시켜버리는 등 다양한 상황에서 적용할 수 있다.
정답이 존재하는 분야가 아니기 때문에 트레이드오프를 적절히 고려하여 역정규화를 수행해야한다.
8. View
테이블이나 또 다른 뷰를 기반으로 한 논리적인 가상의 테이블을 View 혹은 Stored Query라고 한다. 실제로 데이터를 가지고 있는 것은 아니며, 원본 테이블의 데이터를 보거나 변경할 수 있는 창과 같은 역할을 한다.
복잡한 쿼리문을 뷰로 지정하여 반복적으로 사용할 수 있다. 실제 테이블처럼 사용할 수 있기 때문에 조인이 가능하다 (FROM 절에 작성하는 서브쿼리가 인라인 뷰인 이유)
하나의 테이블에서만 조회하며 데이터를 가공하지 않은 View는 단순 뷰라고 하며 두 개 이상의 테이블에서 조회하며 데이터를 가공 처리한 View를 복합 뷰라고 한다.
View와 수정
View는 테이블처럼 활용할 수 있지만 데이터의 수정에는 제약이 있다. 단순히 수정할 수는 없고 가공하지 않은 raw data가 담겨져 있어야만 수정할 수 있다.
distinct, 집계 함수, 연산 혹은 함수 등 기타 처리가 들어갔을 경우에는 데이터의 수정이 불가능하다. 이는 데이터를 수정하려고 해도 어떤 행을 수정해야할지 모호해지기 때문이다.
9. Join
Join은 하나의 SQL로 여러 테이블의 정보를 한 번에 조회하는 방법이다.
조인의 종류는 아래와 같다.
- 조건
- 동등 조인
- 조인 조건을 =을 사용하여 같은 값을 가지는 행을 연결하여 결과를 생성
- 비동등 조인
- 부등호, BETWEEN 등의 연산자를 사용하여 특정한 범위를 만족하는 행을 연결하여 결과를 생성
- USING 사용 불가
- 동등 조인
- 처리 결과
- 내부 조인
- 조건에 부합하는 행들만 연결하여 결과를 생성
- 외부 조인
- 조건에 부합하지 않는 특정 테이블의 행들도 모두 포함하여 결과를 생성
- LEFT OUTER, RIGHT OUTER, FULL OUTER
- 내부 조인
- 조건 생략
- 자연 조인
- 대상 테이블의 모든 공통 컬럼을 조건으로 하여 결과를 생성
- 공통 컬럼이 없다면 크로스 조인과 결과 동일
- 크로스 조인
- 가능한 모든 조합으로 결과를 생성
- 자연 조인
- 기타
- 셀프 조인
- 자기 자신과의 조인을 통칭
- 테이블 별칭 필수
- 셀프 조인
JOIN의 구현
- Nested Loop Join
- N개의 테이블을 N개의 반복문을 사용하여 조인하는 방법
- 드라이빙 테이블의 행 하나를 읽은 후 드리븐 테이블의 모든 행과 비교
- 따라서 드라이빙 테이블의 행이 작을 수록 효율적임
- 소규모 데이터를 조인할 때 사용
- 인덱스가 없다면 Full Table Scan이 발생하여 비효율적
- N개의 튜플들을 블록 단위로 읽어 반복을 줄이는 Block Nested Loop Join도 존재
- Hash Join
- 해시 테이블을 이용하여 조인하는 방법
- 드라이빙 테이블의 조인 대상 컬럼에 해시 함수를 적용시켜 해시 테이블을 만든 후 드리븐 테이블에도 동일하게 해시 함수를 적용시켜 조건을 비교
- 데이터의 수가 너무 많다면 해시 테이블 자체를 파티셔닝 시킨 후 같은 구역에 존재하는 레코드끼리만 조건을 비교하는 Grace Hash Join 사용
- Sort Merge Join
- 조인 컬럼을 기준으로 레코드를 정렬시킨 후 병합하며 조인하는 방법
- 대용량의 데이터를 대상으로 조인하거나 조인 컬럼에 인덱스가 없을 경우 사용

내가 작성한 코드에서 어떤 구현을 사용하여 조인할 것인지 확인하기 위해서는 쿼리의 실행 계획을 참고한다. 위 예제의 경우 Nested Loop Join을 사용할 예정이라는 것을 확인할 수 있다.
JOIN과 인덱스
조인의 성능에는 인덱스도 큰 영향을 끼친다. 조인 역시 특정 컬럼을 기준으로 조건을 비교하는 것이므로 디스크에서 데이터를 읽어들여 조건을 검사하는 과정이 필요하다. 이때 조건으로 걸려있는 컬럼에 인덱스가 걸려있다면 조회의 성능이 올라가므로 자연스럽게 조인의 성능도 올라가는 원리이다.
Nested Loop Join을 생각해보자. 드라이빙 테이블의 한 레코드를 가져온 다음 드리븐 테이블에서 이 레코드의 조건 컬럼과 일치하는 레코드를 찾을 것이다. 이때 드리븐 테이블에 인덱스가 걸려있지 않다면 Full Table Scan을 할 수밖에 없지만 인덱스가 걸려있다면 매우 빠르게 해당 컬럼을 찾는 것이 가능하다.
3중 조인
3중 이상의 조인은 중간 조인의 결과로 나온 테이블과 남아있는 테이블의 조인을 반복하여 결과 집합을 만들게 된다. 이때 조인의 순서에 따라 연산의 개수가 달라질 수 있다.
3개의 행렬을 곱하는 문제를 생각해보자. 어떻게 곱하든 결과는 동일하지만 어떤 순서로 곱하느냐에 따라 연산의 수가 크게 달라질 수 있다.
이처럼 어떤 테이블과 먼저 조인하느냐에 따라 쿼리의 수행 속도가 달라질 수 있고, 옵티마이저는 최소한의 연산을 하도록 조인의 순서와 조인 방식을 선택하게 된다.
10. B-Tree
B-Tree는 Balenced Tree의 약자로, 정렬된 상태를 유지하는 동시에 균형 잡힌 상태를 유지하는 자료구조이다. 자식 노드의 수에 따라 차수를 가지며 2개를 초과하는 자식 노드를 가질 수 있다는 점이 이진 트리와의 가장 큰 차이점이다.
모든 리프노드는 같은 깊이를 가지며 검색, 삽입, 삭제가 모두 O(log N)으로 수행된다. 연산이 매우 효율적으로 동작하기 때문에 DB에서 인덱스를 구성할 때 사용된다.
B+Tree는 B-Tree에서 기능이 추가된 트리라는 의미로 + 기호가 붙은 자료구조로, 기본적인 구조는 B-Tree와 동일하지만 데이터가 리프 노드에만 저장되며 리프 노드끼리로는 연결되어 있다는 점이 다르다. 리프 노드끼리는 연결되어 있기 때문에 범위 검색에 매우 유리하다. (순차 IO가 가능)
데이터가 모두 리프 노드에 존재하기 때문에 중간에 데이터를 찾아 바로 탐색을 끝낼 수가 없다는 단점이 있다.
왜 인덱스로는 레드 블랙 트리를 사용하지 않을까?
레드 블랙 트리는 노드에 하나의 데이터만 저장한다. 하지만 B+Tree는 하나의 노드에 여러 개의 데이터를 저장할 수 있기 때문에 높이의 차이가 발생하고 이 경우 연산의 시간에 차이가 발생한다.범위 쿼리의 경우에도 B+Tree가 리프 노드들끼리 연결되어 있기 때문에 압도적으로 빠른 성능을 자랑한다.
B+ Tree는 내부적으로 배열처럼 데이터들이 차례대로 저장되어 있어 다음 데이터의 참조가 매우 빠르게 이루어진다. 반면 Red Black Tree의 경우 다음 노드를 참조 포인터를 따라 이동해야하기 때문에 다음 노드의 접근 속도가 느리다.
인덱스 역순 스캔
인덱스를 오름차순으로 생성했다하더라도 역방향으로 읽으며 내림차순 데이터를 가져올 수 있다. 이를 인덱스 역순 스캔이라고 한다.
인덱스 역순 스캔은 일반적인 인덱스 스캔에 비해 속도가 느리다.
- 페이지의 잠금이 인덱스 스캔에 더 유리하다.
인덱스 스캔은 그냥 잠금을 걸고 해제하면 되지만 인덱스 역순 스캔의 경우 여러 추가적인 과정이 필요하다. - 페이지 내에서 인덱스 레코드는 단방향으로 연결되어 있다.
B+Tree의 리프 노드는 양방향 연결 리스트로 이루어져 있기 때문에 역방향 스캔에 큰 문제가 없지만 노드에 접근하고 나서부터는 레코드들이 단방향 연결 리스트로 이루어져 있어 역방향 스캔 시 느리다.
출처: https://tech.kakao.com/posts/351
11. Lock
Lock은 다른 트랜잭션이 접근하지 못하도록 특정 데이터 영역을 점유하는 것을 의미한다. 데이터의 무결성을 보장하기 위한 방법으로, 일반적으로 쓰기 작업 시 걸린다.
잦은 Lock은 성능 저하의 주된 원인이므로 최대한 Lock을 적게 사용하는 것이 좋다.
Lock의 종류
- 락 모드
- 공유 락
- 읽기를 위한 락
- 다른 트랜잭션의 읽기는 허용하지만 수정은 불가능
- 여러 트랜잭션이 동시에 공유 락을 걸 수 있음
- 배타 락
- 쓰기를 위한 락
- 다른 트랜잭션의 읽기와 수정을 모두 막음
- 단 하나의 트랜잭션만이 배타 락 소유 가능
- 읽기까지 막는 이유는 다른 트랜잭션이 잘못된 값을 읽어갈 수 있기 때문(커밋되지 않은 상태거나, 롤백되는 경우)
- 공유 락
- 락 전략
- 낙관적 락
- 충돌은 거의 일어나지 않을 것이라고 생각하여 락을 걸지 않으며 작업을 수행
- version 혹은 타임스탬프 컬럼을 추가하여 데이터의 버전을 관리
- 락을 걸지 않고 작업을 수행하다가 데이터를 쓰는 시점에서 버전을 살펴보고 충돌을 감지
- 충돌 발생 시 어플리케이션 레벨에서 처리
- 실제로 충돌이 거의 발생하지 않는다면 높은 성능을 자랑
- 비관적 락
- 충돌이 발생할 것이라고 생각하여 락을 걸면서 작업을 수행
- 확실하게 데이터의 무결성을 보장 가능
- 성능이 다소 떨어지고 교착 상태 발생 가능
- 낙관적 락
- 락 범위
- 테이블 락
- 테이블 전체에 적용시키는 락
- 모든 레코드에 대한 접근을 막음
- 레코드 락
- 레코드 단위로 적용시키는 락
- MySQL은 레코드 자체에 락을 거는 것이 아닌 인덱스에 락을 검
- 범위 락
- 레코드 사이 범위에 적용시키는 락
- 특정 범위에 새로운 데이터가 삽입되는 것을 방지
- 넥스트 키 락
- 레코드 그 자체와 레코드 사이 범위 모두에 적용시키는 락
- 레코드에 대한 수정 방지와 특정 범위에 새로운 데이터가 삽입되는 것을 동시에 방지
- 테이블 락
Lock 교착 상태
Lock을 건 클라이언트가 다양한 사유로 인해 무한정, 혹은 장시간 Lock을 소유하게 될 수 있고 이 경우 교착 상태에 빠지게 된다. DB 레벨에서 이러한 상황을 커버하는 로직이 구현되어 있다.
InnoDB에서는 innodb_deadlock_detect 옵션이 켜져있다면 주기적으로 교착 상태를 감지하여 특정 트랜잭션을 강제로 롤백하여 교착 상태를 해제한다.
어느 한 트랜잭션이 Lock을 장시간 소유하고 있는 경우에도 교착 상태가 발생할 수 있다. innodb_lock_wait_timeout 이상으로 Lock을 소유하게 되면 롤백 후 락을 해제하여 교착 상태를 해결한다.
만일 클라이언트의 세션이 종료된다면 해당 세션이 소유하고 있는 모든 락을 해제하는 것으로 교착 상태를 예방한다.
12. 대용량 트래픽 처리
- DB 자체를 분산하는 방법
- 샤딩이나 리플리케이션을 이용하여 요청을 분산
- DB가 SPOF가 되는 문제도 방지할 수 있음
- 분산으로 인해 관리할 지점이 늘어나고 인프라 구축의 난이도가 상승하는 단점 존재
- 수직적 스케일링
- DB를 사용하는 서버의 스펙 자체를 업그레이드 하는 방법
- 비용 대비 한계가 존재
- 가장 간단한 방법이긴 함
- DB의 성능을 최적화하는 방법
- DB를 사용하는 쿼리 등을 최적화하여 자체적인 처리율을 늘리는 방법도 존재
- 서버의 로그를 확인하여 적절히 인덱스를 새로 추가
- JOIN과 같은 무거운 연산을 피하기 위해 역정규화도 고려 가능
- 배치 작업이 가능하다면 배치 처리를 이용하기
- 캐시 레이어를 추가하는 방법
- 캐시 레이어를 새로 추가하여 DB로 오는 트래픽을 분산하는 방법
- 관리 지점이 늘어나지만 적절히 이용한다면 큰 성능 향상을 기대할 수 있음
13. 스키마
스키마는 데이터베이스 내에서 데이터가 가진 구조와 관계, 성질을 나타낸 것이다.
데이터가 어떤 테이블로 나타나는지, 테이블 내에 어떤 컬럼이 있으며 타입은 무엇인지, 테이블 간의 관계는 어떻게 되며 제약 조건은 어떻게 되는지 등을 나타내는 메타데이터라고 할 수 있다.
스키마 덕분에 데이터가 저장될 규격이 정해지므로 일관성 있는 데이터의 보관이 가능하고 제약 조건을 통해 무결성 보장이 가능해진다.
스키마 3계층
스키마는 3계층으로 나뉘어진다.
- 외부 스키마
- DB의 사용자 입장에서의 필요한 데이터만 노출시키는 뷰
- 응용 프로그램 프로그래머 입장에서는 DB의 전체 구조를 다 알 필요는 없음
- DBA가 작성한 뷰를 이용하여 프로그래밍이 가능
- 이러한 뷰를 외부 스키마라고 함
- 개념 스키마
- DBA가 설계한 데이터의 규격을 나타냄
- 전체 시스템에 저장되는 데이터의 구조, 관계, 무결성을 정의
- ER 다이어그램으로 표현
- 내부 스키마
- 데이터가 물리적으로 디스크에 어떻게 저장될 지를 표현
14. 커넥션 풀
데이터베이스와 연결을 하기 위해 커넥션이 필요하다. 이러한 커넥션은 생성하고 종료하는데 오버헤드가 존재하며 매 요청마다 DB와의 커넥션을 생성하고 종료하는 과정을 반복하면 이러한 오버헤드가 쌓여 성능적인 하락을 야기시킬 수 있다.
따라서 DB와 이미 연결되어 있는 커넥션들을 미리 생성하고 요청마다 커넥션을 대여하고 반납받는 방식으로 커넥션의 생성, 종료 오버헤드를 최대한 줄이는 방법을 커넥션 풀이라고 한다.
커넥션 풀을 사용하면 DB와 연결되어 있는 커넥션의 수가 제한되므로 DB의 부하를 의도한 범위로 제한시킬 수 있는 장점도 있다.
커넥션 수립
- JDBC Driver 로딩
JDBC 드라이버에 대한 종속성을 추가하고 Class.forName을 이용하여 메모리에 로드해둔다. 이는 JDBC 버전이 4.0 이상이라면 생략할 수 있다. - 커넥션 생성
로드한 드라이버에서 DB에 대한 정보를 전달하여 커넥션을 생성한다. DB와의 커넥션을 TCP로 수립된다. - 쿼리문 생성
Statement 혹은 PreparedStatement와 같은 SQL 문장 커넥션으로부터 생성하고 SQL을 바인딩한다. - 쿼리 실행
쿼리문을 실행시킨다. 쿼리 정보와 그에 대한 응답은 TCP 소켓 통신으로 송수신한다. - 결과 처리
만일 select 문이라면 ResultSet으로 결과 집합을 처리하여 적절한 가공을 수행한다. - 자원 반납
사용한 ResultSet, Statement, Connection을 반납한다. 반납은 생성한 순서의 역순으로 한다.
15. 데이터 읽기 전략
DB는 데이터를 조회하기 위해 디스크에서 메모리로 데이터를 로드한다. 이때 DB의 옵티마이저는 쿼리의 상황을 고려하여 데이터를 어떻게 읽을지를 결정하고 그에 맞춰 데이터를 읽어 들인다.
Table Full Scan
Table Full Scan은 인덱스를 사용하지 않고 디스크에 저장되어 있는 테이블의 데이터를 처음부터 끝까지 모두 읽어버리는 것이다.
기본적으로는 쿼리에서 활용할 수 있는 인덱스가 없다면 Table Full Scan으로 데이터를 들고온다. 다만 인덱스를 탈 수 있음에도 불구하고 Table Full Scan을 하는 경우가 있는데 바로 저장된 데이터의 개수가 적은 경우이다.
인덱스를 이용하여 데이터를 들고오는 경우 B+ Tree의 리프 노드까지 내려간 이후 리프 노드에 저장된 PK를 이용하여 물리적 저장 위치로 이동하는 과정이 추가된다. 또한 물리적 저장 위치에서 데이터를 들고오는 작업은 순차 I/O가 아닌 랜덤 I/O이므로 꽤나 비용이 높다. 따라서 저장된 데이터의 개수가 적다면 그냥 바로 디스크로 이동하여 전체를 다 조회하는 것이 더 빠르다.
마찬가지의 이유로 인덱스를 타도 조회할 데이터의 수가 너무 많으면 Table Full Scan으로 데이터를 적재한다.
Index Range Scan
Index Range Scan은 범위 쿼리에서 데이터를 읽어오는 방법이다. 조건절에 인덱스가 걸려있는 경우에 사용되며 조건을 최초로 만족하는 값을 인덱스를 통해 리프 노드까지 탐색한다. 이후 리프 노드의 연결리스트를 이용하여 데이터를 읽다가 조건을 마지막으로 만족하는 데이터가 나오면 해당 위치까지만 데이터를 읽고 종료한다.
인덱스에서 데이터를 들고오는 것이므로 자연스럽게 정렬된 상태가 유지되며 만일 커버링 인덱스(실제 저장 위치까지 갈 필요없이 인덱스만으로 원하는 데이터를 들고올 수 있는 경우)가 된다면 랜덤 I/O에 대한 부하가 줄어들어 성능은 더욱 높아진다.
Index Full Scan
Index Full Scan은 말 그대로 인덱스를 이용하여 전체 데이터를 가져오는 방법이다. 정상적으로 인덱스를 타는 경우는 아니다. 오히려 인덱스를 잘 활용하지 못하는 경우이기 때문에 Full Scan이 이루어진다.
인덱스를 이용하여 데이터를 들고와야 하는 경우 랜덤 I/O 때문에 Table Full Scan과 비교하여 이점이 없다. 따라서 거의 사용되지 않는 전략이지만, 만일 들고와야할 데이터가 커버링 인덱스로 처리가 된다면 Index Full Scan을 이용하여 데이터를 들고온다. 인덱스의 크기가 테이블의 크기보다 더 작기 때문에 디스크 I/O에 소비되는 비용이 적어지기 때문이다.
Loose Index Scan
Loose Index Scan은 집계 함수를 최적화할 때 사용되는 전략으로 인덱스의 전체 레코드를 읽을 필요가 없을 때 사용된다.
만일 어떤 테이블의 인덱스가 (A, B)로 걸려있고 다음과 같은 쿼리를 날린다고 생각해보자
SELECT A, MIN(B)
FROM table
GROUP BY A인덱스가 (A, B)로 걸려있으므로 A와 MIN(B)를 가져오는데에는 첫 번째 원소만 읽으면 된다. 따라서 컬럼의 값이 A와 동일한 다른 레코드는 읽을 필요가 없으며 이 경우 옵티마이저는 첫 번째 원소만 읽고 바로 다음 대상 레코드로 이동하며 읽게 된다. 이를 Loose Index Scan이라고 한다.
Index Skip Scan
Index Skip Scan은 원래라면 인덱스를 활용할 수 없는 상황에서도 활용하게 하는 전략이다.
만일 어떤 테이블의 인덱스가 (A, B)로 걸려있다고 하자. 이때 쿼리의 조건으로 B만 걸리게 되면 인덱스를 활용할 수가 없다. 하지만 A의 카디널리티가 매우 낮은 경우에는 옵티마이저가 A의 조건을 강제로 생성시킨 후 Index Range Scan을 수행하는데 이를 Index Skip Scan이라고 한다.
Count 쿼리의 성능 차이
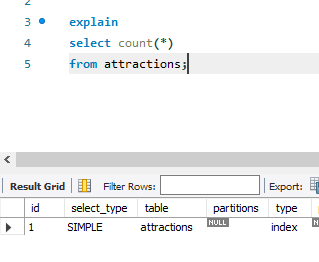
count(*)의 경우에는 행의 개수만 세면 되므로 Index Full Scan으로 데이터를 스캔한다.

count(1)의 경우에는 모든 행을 1로 매핑한 후 개수를 센다. count(*)과 동일한 동작이므로 같은 실행 계획으로 처리된다.
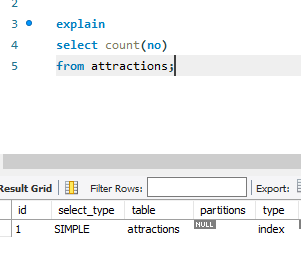
count(column)인 경우에 해당 컬럼에 대응하는 인덱스가 존재하는 경우 커버링 인덱스가 가능하므로 마찬가지로 Index Full Scan한다.
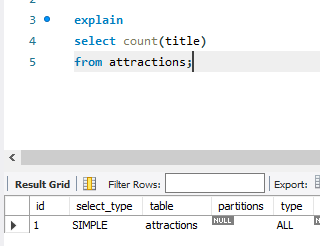
인덱스가 존재하지 않는 컬럼에 대해 count할 경우 Table Full Scan으로 카운팅한다.
16. SQL Injection
SQL Injection은 입력창에 SQL 구문을 입력하여 백엔드 서버에서 해당 입력 값을 처리할 때 쿼리문을 실행되기를 기대하는 공격 기법이다.
만일 서버에서 아래와 같은 코드로 사용자를 검증한다고 해보자
String sql = "SELECT * FROM users WHERE password = " + password이때 사용자가 비밀번호 입력란에 ' ' OR 1=1을 입력하게 되면 인증 상의 우회가 발생한다.
DB 라이브러리의 예방책
SQL Injection을 예방하는 방법은 간단하다. raw 쿼리를 그대로 적용시키는 것이 아니라 PreparedStatement를 사용하는 것. PreparedStatement는 플레이스홀더에 값을 전달하는 방식인데, setString을 호출할 때 자동으로 SQL Injection을 예방해준다.
Hibernate같은 ORM을 사용할 때도 내부적으로 PreparedStatement를 사용하여 SQL Injection을 예방한다.
