
대학교 시절 한 번도 생각해본 적이 없던 분야가 데이터분석.
좋은 쪽으로도 나쁜 쪽으로도 생각해본적이 없는데, 한 번 현직자 졸업생이 와서 강연할 때 생각을 좀 해봤다.
원래 통계학과 나온 사람인데 단순히 이거가지곤 답이 없을 거 같아서 컴공을 복전했던가 부트캠프를 다녔다고 했다.
그래서 두 가지 스킬(통계, 코딩)을 잘 써먹어서 공기업 잘 다니고 있다고 했다.
근데 그 때까지만 해도 판다스라는 모듈 들어본 적이 없다.
안 유명한 게 아니라 내가 그냥 그쪽에 관심 자체가 없다는 소리.
그러다가 막학기 때 학점 사냥하려고 타 학과 파이썬 수업 들으러 갔는데, 그 때 판다스를 처음 만져봤다.
그 당시엔 ipynb 쓰다가 갑자기 py에 빠져서 모든 것을 py 확장자로 해결하려고 했다. 근데 판다스를 만져보니까 py 파일이 다가 아니라는 것을 알게 되었고.
여튼 뭔가 엑셀스럽고 할만하게 생겨서 만만하게 봤다가 엄청 애먹은 모듈이다.
그리고 엑셀같이 숫자 셀들이 하도 많다보니 결과물이 나오더라도 내가 맞게 데이터를 다룬 것인지 아닌지 검증하기도 힘들었고.
암튼 이번 기회에 복습겸 정리를 하려고 한다.
====================================================================
- pandas 모듈 설치 및 import
쥬피터 노트북일 경우,
python 셀을 만들어서 !pip install <모듈명>을 입력.
즉, pandas를 설치한다면 !pip install pandas를 입력하고 실행.
터미널에서 설치할 경우,
1. 아나콘다 프롬프트 실행
2. 설치할 가상환경을 activate.
3. pip install pandas를 터미널 창에 입력.
윈도우 vscode에서 작업하고 있는 중이라면, vscode에 내장된 터미널을 활성화하여 터미널 설치법처럼 하면 된다.
vscode 쥬피터 터미널의 아래쪽을 보면 위 사진과 같은 버튼이 있다.
화살표 아래 버튼을 누르고 탭 중에서 Command Prompt를 선택하자.
이 후 모듈 사용을 할 때는 import pandas as pd 문장을 코드에 추가.
그냥 아나콘다 창을 시작메뉴에서 키는 것이 아니라 vscode 안에서 키는 것이라고 보면 될 듯.
이미 Select Kernel을 가상환경으로 설정해줬고, 이게 반영이 되어 따로 activate를 안해도 가상환경이 설정된 듯.
그러면 저기에서 pip install pandas를 타이핑해주면 설치가 된다.
단, 쥬피터 셀에서 설치할 때는 실행문 앞에 !를 추가하고, 터미널에서 설치할 때는 !없이.
2.파일 읽어오기
2-1. csv 파일

df = pd.read_csv("<파일경로>/<파일명>")
파일경로의 경우엔 https://velog.io/@wintercamo/pythondrill001 에서 이미지 추가 부분에 추가함.
저 문구를 입력하면 csv 파일을 읽어오는데, 에러가 생길 수 있다.
에러는 대부분 인코딩 에러일 것인데, 그럴 경우엔
df = pd.read_csv("<파일경로>/<파일명>", encoding="<인코딩>")을 입력해준다.
이 때 <인코딩>은 cp949, ms949, euc-kr, utf-8 등 다양한 인코딩들이 존재하는데 해당 csv 파일의 인코딩에 맞게 설정을 해야 제대로 읽어진다.
encoding_errors = "ignore"를 사용해서 에러가 나는 경우라도 이를 무시하고 불러오는 방법이 있기는 한데, 판다스 버전에 따라 될 수도 안 될 수도 있는 모양.
2-2. 엑셀 파일
df = pd.read_excel("<파일경로>/<파일명>")
위와 똑같지만 read_excel로 하는 점, 파일명이 csv가 아니라 xls 확장자일 것이다.
그런데 xls 확장자일 경우 xlrd 패키지가 없다는 오류가 발생하는데, 마찬가지로 pip install xlrd를 해주면 된다.
그러나 원본이
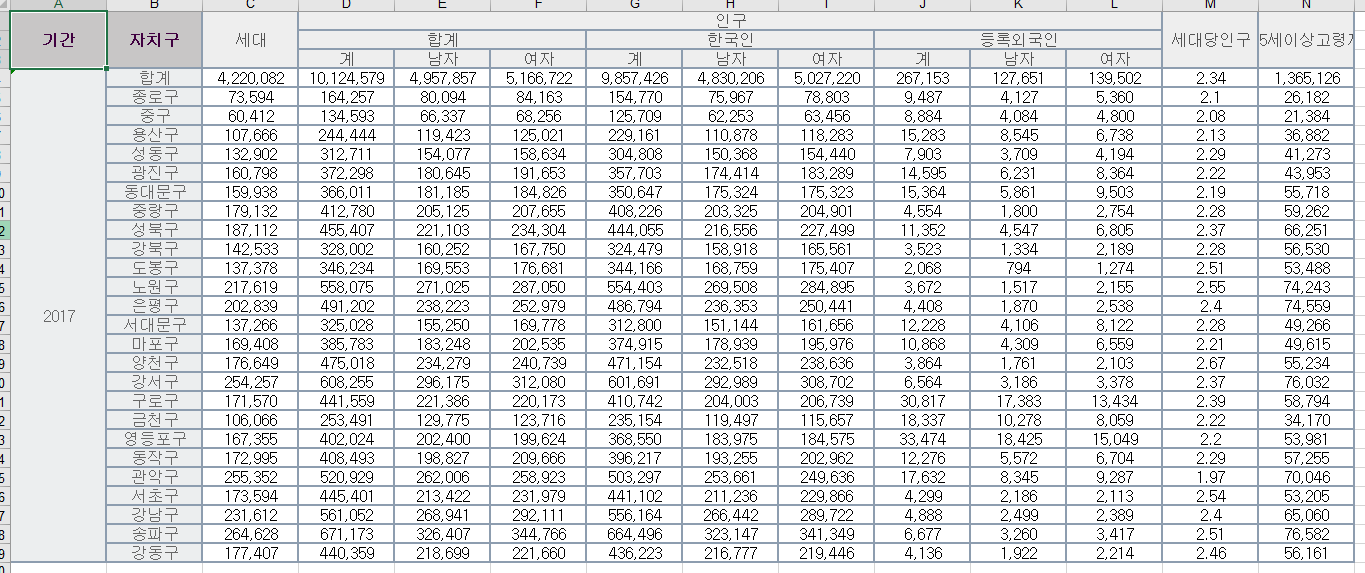
이런식으로 되있는 경우라면 쥬피터의 결과물은

이런 식으로 나오게 된다.
즉, 해당 데이터프레임의 정확한 컬럼명은 남자 합계, 여자 합계, 한국인 남자 합계, 한국인 여자 합계 이런 식이다.
필요없는 인덱스/컬럼을 제거 및 명칭을 변경은 후술할 것이다. 그래서 처음부터 깔끔하게 불러오고자 한다.
일단 위 데이터프레임에서 0~1번째 행을 버리고, 2번째 행을 기준으로 삼고 싶다. 또한, 컬럼은 기간, 자치구, 인구.1, 세대당인구 만 불러오고 싶다.
이런 경우엔 pd.read_excel("<엑셀파일>", header=숫자, usecols=<방법A>) 형식으로 불러와야한다.
header의 숫자에 2를 대입하면 0~1번째를 버리고 2번째 행을 0번째 인덱스, 즉, 기준으로 삼는 것이다.
<방법A>는 문자열 혹은 숫자 리스트를 대입하면 된다.
문자열인 경우엔 "A, B, E, N"을 대입하고, 숫자 리스트의 경우는 [0, 1, 5, -2]를 대입하면 된다.
- 데이터시리즈 / 데이터프레임
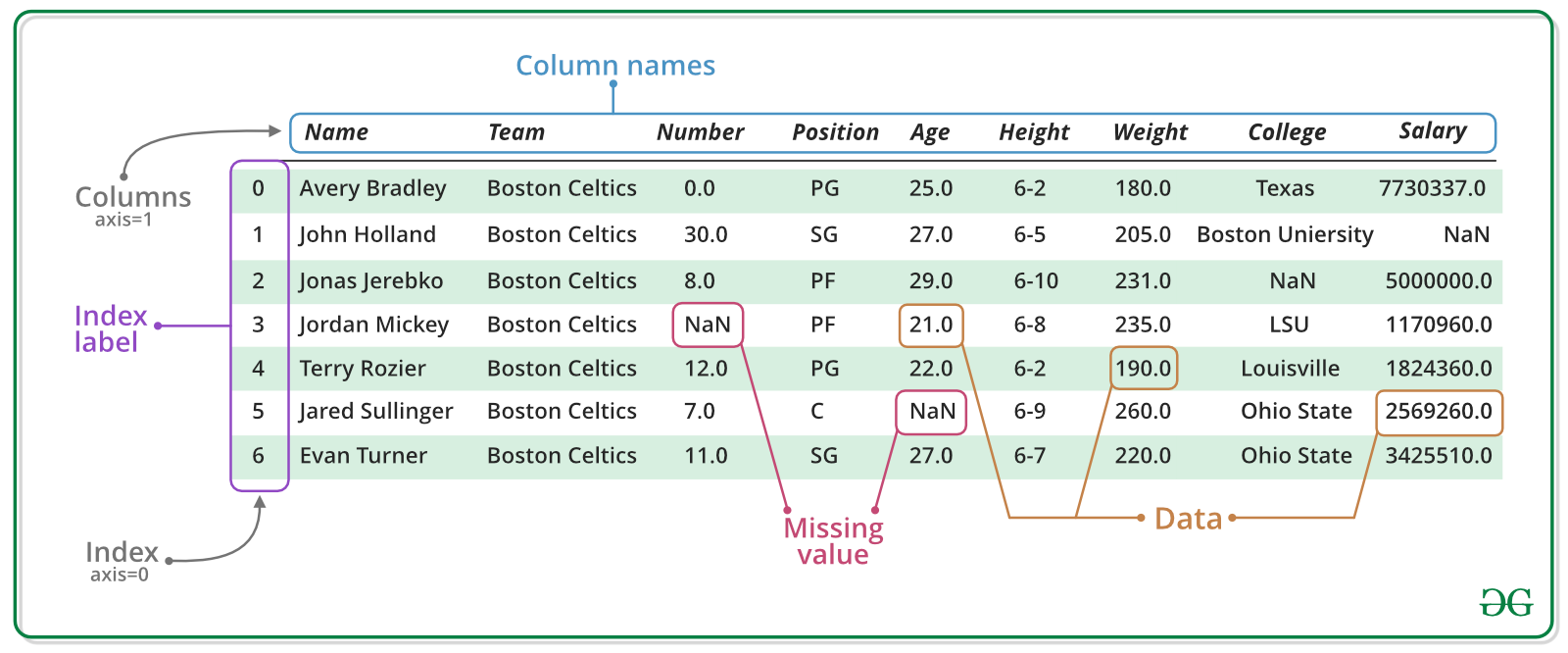
이미지 출처: https://www.geeksforgeeks.org/creating-a-pandas-dataframe/
이런 걸 지겹도록 볼 건데, 데이터프레임이라고 한다.
Name, Team 이런 것들이 컬럼, 0,1,2,이런 게 인덱스, 가운데에 있는 것들을 값(value)라고 한다.
판다스로 데이터를 불러와서 작업을 하다보면 알겠지만, 인덱스나 컬럼의 갯수가 10개 넘어가는 경우는 흔할 것이다.
뭐... 2번의 메소드를 활용하여 불러오는 법도 있지만 직접 생성하는 법도 있다.
df = pd.DataFrame((mxn 형태의 매트릭스), index=<길이가 m인 리스트>, columns=<길이가 n인 리스트>)
인덱스와 컬럼 파라미터엔 넣고자 하는 리스트를 넣어준다. 매트릭스 부분을 아예 넣지 않을 경우엔 np.nan, 즉, 결측값이 들어간다. 이게 싫으면 mxn 형태의 np.배열을 넣으주면 되는데, 차원이 맞아야 대입이 되기 때문에 적절히 변형을 하여 대입할 필요가 있다.
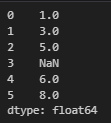
그 다음은 데이터시리즈. s = pd.Series([<넣고 싶은 값들>]) 형태로 선언을 한다. 괄호가 헷갈릴까봐 강조하는데, () 안에 리스트 형태로 넣는 것이다. 아무튼 이게 판다스의 기초적인 데이터구조인데, 이럴 거면 리스트를 쓰는 게 나은 거 아닌가 싶은데, 잘보면 인덱스 번호가 있다.
이게 그냥 리스트와의 차이가 아닌가 싶은데, 아직 어려운 작업을 안 해봐서 그런지 굳이 이걸 쓸 일이 있을까 싶다.
3-1. 데이터프레임 체크하기
근데 우리가 메소드를 사용하여 데이터프레임을 지지고 볶고 할 것인데, 이 때문에 데이터프레임의 형태가 자주 변경이 될 것이다. 데이터프레임이 현재 어떻게 변경되었는지 확인하는 것도 중요한데, 매번 전체를 보는 것은 어렵기 때문에 일부분만 보고 확인을 할 필요가 있다.
이를 위해서 head, tail 메소드를 사용한다. 사용법은
df.head(n), df.tail(n)이다.
n의 디폴트 값은 5이기 때문에 n을 생략한다면
head일 경우, 데이터프레임의 0부터 4번째 인덱스만 보여주고, tail이면 마지막에서 5번째 ~ 마지막 인덱스를 보여준다.
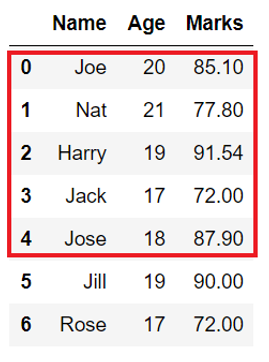
즉, head 메소드를 사용하면 0~6번째 인덱스 중 0~4번째만 보여준다.
3-2. 컬럼 / 인덱스 / 값 조회
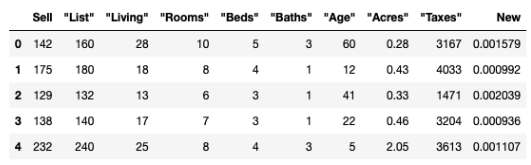
위 데이터 프레임의 컬럼을 보면 Sell, List, Living 등이 있다. 이는 df.columns 메소드를 사용하여 리스트 형태로 호출할 수 있다.
df.index를 하면 df.columns를 한 것과 같은 결과를 얻을 수 있다. 단, index가 단순히 0부터 n번째를 나타내는 상황이 아니라 [20130101, 20130102, 20130103], ["가", "나", "다"] 형태같은 경우에만 이쁘게 조회가 되더라.
df.values를 하면 단순히 np.array같은 형태로 출력이 된다.
특정 컬럼만 조회할 경우 df[컬럼명]을 하면 된다.
특정 행만 조회할 경우 df[0:3]을 하면 0부터 3번째 행만 조회할 수 있다.
이 때 인덱스가 번호가 아니라 날짜데이터와 같은 형태라면 df["130102":"130107]처럼 조회하면 된다.
3-3. info / describe()
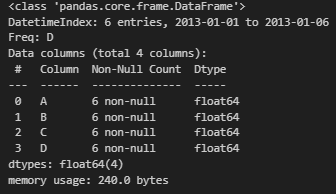
df.info()를 할 경우 위처럼 데이터프레임의 정보가 나온다. 이 중에서 Dtype(데이터타입)은 해당 인덱스의 값들이 int인지 float인지, object(str형이거나 섞여있을 경우) 확인.
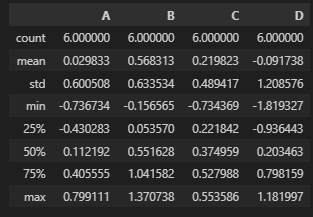
df.describe()를 할 경우, 위처럼 데이터프레임의 기본 통계값을 분석한다.
count는 컬럼 데이터 갯수, mean은 데이터들의 평균, std는 데이터들의 표준편차, min, max는 데이터들의 최소/최대값이다.
25%, 50%, 75%는 각각 하위 25%, 50%, 75%의 값이다.
- 슬라이싱
4-1. loc / iloc
df.loc[m:n, ["A", "B"]]는 A와 B 컬럼 중 m부터 n번째 행만 조회하여 보여주는 것.
m와n을 생략하여:만 남길 경우엔 모든 행들이 슬라이싱 된다.
df.iloc[n]인 경우, n번째 행의 값을 판다스 시리즈로 조회한다.
df.iloc[m:n, a:b]인 경우, a번째부터 b번째의 컬럼 중 m부터 n까지의 행을 출력한다.
대충, loc인 경우는 데이터의 순서, 컬럼/인덱스 명칭을 가지고 슬라이싱하여 조회하는 것이고
iloc은 철저하게 데이터의 순서 번호만을 가지고 슬라이싱하여 조회하는 것이다.
iloc의 경우엔 m:n 형태도 가능하지만 [1, 2, 5, 7]처럼 띄엄띄엄 조회도 가능하다.
4-2. 조건문 활용
df[df["A"] > 0]
즉, A컬럼에서 0보다 큰 값들이 존재하는 행만 조회하는 것.
- 컬럼 이름 변경
만약 컬럼에서 Sell과 Age라는 컬럼명이 마음에 들지 않으면 아래와 같이 바꿀 수 있다.
df.rename(columns={df.columns[0]:"테스트1", "Age":"테스트2" }, inplace=True)
{}, 즉, 딕셔너리 형태를 사용하는데, 딕셔너리 key 위치에 해당하는 곳은 컬럼명을 직접 쓰거나 컬럼이 위치한 index 번호를 넣어준다. 그리고 딕셔너리 value 위치에 해당하는 곳에는 바꾸고 싶은 이름을 입력하면 된다.
inplace 파라미터에는 True를 입력했는데, 해당 df에서 변경한 결과를 그 df에 반영시키겠다는 뜻이다. 이를 입력하지 않으면 해당 셀에서만 바뀐 형태를 보여주고 반영을 시키지 않는 것이다.
즉, inplace를 사용하면 원본이 훼손될 수도 있다는 뜻이므로 주의할 필요가 있다.
- 컬럼 추가 / 삭제
..............................................................................
(추가예정)
..............................................................................
- 데이터프레임 정렬
오름차순(ascending): small -> big.
df.sort_values(by=<컬럼명>, ascending=True, inplace=True)
내림차순(descending): big -> small.
df.sort_values(by=<컬럼명>, ascending=False, inplace=True)
만약 여기서 Rooms의 값을 오름차순을 하고 싶을 경우, 컬럼명은 "Rooms", ascending은 True로 하면 된다. 변경된 결과를 데이터프레임에 반영시키려면 inplace=True를 해주고, 원치 않으면 이를 생략한다.
기타. 시간데이터

어디서 가져오는 게 아니라 판다스에서 지원하는 기능.
pd.date_range("YYYYMMDD", periods=n)을 사용하여 생성.
YYYYMMDD에는 시작 연도/월/일을 입력하고, periods의 n은 자연수를 입력. 그래서 6을 입력하면 시작 연/월/일부터 +6일까지의 날짜데이터가 생성이 되었다.
뭐... 날짜와 관련된 무언가를 할 때는 유용하게 쓰겠네.
