Reddit의 아키텍처는 어떻게 진화했을까?

ByteByteGo에서 Reddit의 아키텍처에 대해 자세히 설명한 글을 뉴스레터로 공개했습니다. 대규모 트래픽 처리에 참고할 만한 내용이 많고, Reddit의 시스템 마이그레이션 과정이 잘 드러나 있습니다.
그 중 일부에서 핵심적이라고 생각한 내용을 한국어로 요약/각색하여 공유합니다.
더 자세한 내용은 원문을 참고바랍니다.
원문: Reddit's Architecture: The Evolutionary Journey
https://blog.bytebytego.com/p/reddits-architecture-the-evolutionary
Reddit :: 지구상에서 가장 인기 있는 커뮤니티 서비스
Reddit의 월간 사용자 수는 10억 명이 넘으며, 매우 다양한 주제로 커뮤니티가 형성되어있습니다.
Reddit의 인기를 보여주는 수치들
- Reddit의 월간 순 방문자 수는 12억 명입니다.
- Reddit의 월간 활성 사용자 수는 2018년 이후 366% 증가했습니다.
- 2023년에만 4억 6,900만 개의 게시물이 작성돼었고, 28억 4,400만 건의 댓글과 상호 작용이 발생했습니다.
- Reddit은 2023년에 전 세계에서 가장 많이 방문한 웹사이트 18위에 올랐으며, 8억 4,000만 달러의 수익을 올렸습니다.
수치를 보면, 최근 Reddit의 IPO가 큰 성공을 거둔 것은 놀랍지 않습니다.
이 글에서는 이러한 인기에 따라 Reddit의 아키텍처가 어떻게 진화해왔는지 살펴보겠습니다.
초기 Reddit
초기에 Reddit은 LISP로 작성되었으나, 당시 검증된 라이브러리가 부족하여 Python으로 다시 작성되었습니다.
Python의 경우, 처음에는 Swartz(Reddit의 또 다른 공동 창립자)가 개발한 web.py라는 웹 프레임워크를 사용했습니다. 그리고 2009년 후반에는 웹 프레임워크로 Pylons를 사용했습니다.
Reddit 아키텍처의 주요 요소
아래 그림은 Reddit의 대략적 아키텍처를 보여줍니다.
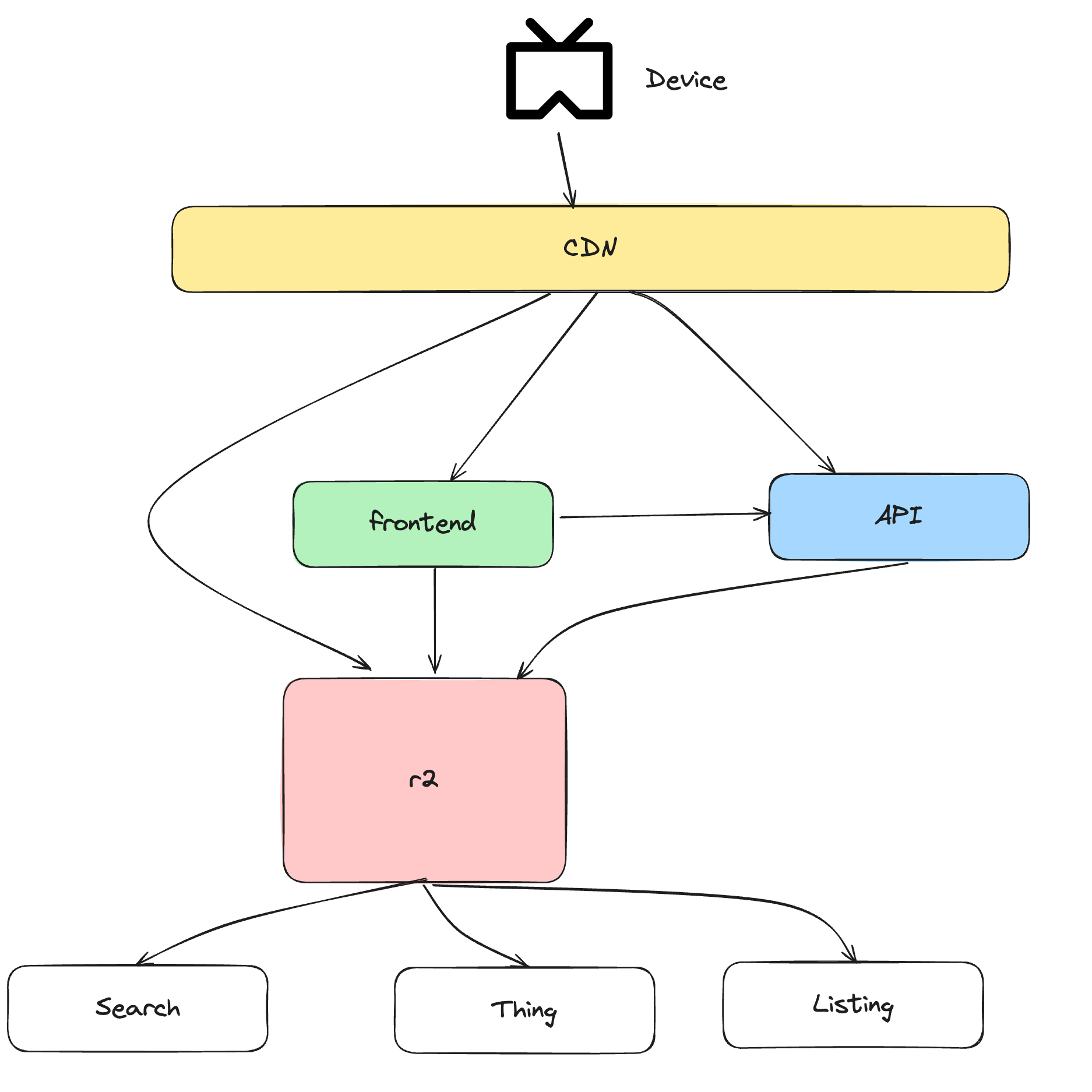
-
CDN(Content Delivery Network): 어플리케이션의 앞단에서 Fastly의 CDN을 사용합니다.
-
프론트엔드 어플리케이션: Reddit은 2009년 초에 jQuery를 사용하기 시작했습니다. 이후에는 타입스크립트를 사용하여 UI를 재설계하기 시작했고, 최신 웹 개발 접근 방식을 수용하기 위해 Node.js 기반 프레임워크로 전환했습니다.
-
R2 모놀리스: 가운데에는 R2라는 거대한 상자가 있습니다. Python으로 구축된 최초의 모놀리식 어플리케이션으로, 검색과 같은 기능과 여러 엔티티로 구성되어 있습니다.
R2 서버
R2는 레딧의 코어 서버고, 하나의 큰 모놀리스 어플리케이션입니다.
크게 아래와 같이 구성되어있습니다.
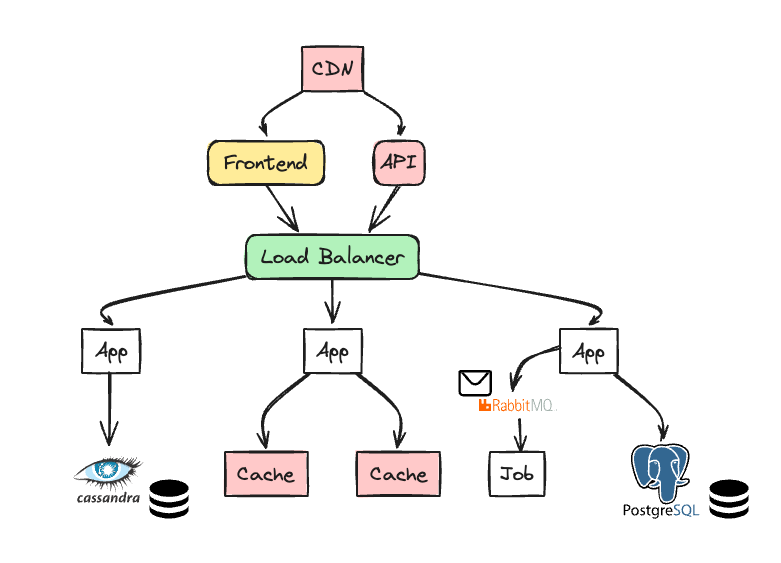
확장성을 위해, 동일한 코드로 여러 서버에 배포되어있습니다.
로드 밸런서가 요청을 적절한 서버 풀로 라우팅해주는 역할을 합니다.
투표와 링크 제출같이 비용이 큰 작업은 비동기 작업 큐(RabbitMQ)로 연기되고, 추후 job 프로세서가 메시지를 처리합니다.
데이터 관점으로 본다면 크게 아래 세가지가 있습니다.
- Postgres: Reddit의 코어 데이터 모델인 RDBMS
- memcached: 데이터베이스 접근을 줄이기 위해, Postgres 앞단에 위치한 캐시
- Cassandra: 복원력과 가용성이 강해, 새로운 기능에 주로 사용하는 NoSQL
확장
Reddit의 인기가 높아짐에 따라 사용자도 급증했습니다. 사용자의 참여를 유지하기 위해 Reddit은 많은 새로운 기능을 추가했고, 어플리케이션의 규모와 복잡성도 증가했습니다.
이러한 변화로 여러 영역에서 설계를 발전시켜야만 했습니다. 설계는 지금도 끊임없이 변화하고 있지만, 몇 가지 주요 영역에서 핵심적인 발전이 있었습니다.
Reddit이 아키텍처와 관련하여 나아가고 있는 방향을 살펴보겠습니다.
GoLang 마이크로서비스와 GraphQL Federation
Reddit은 2017년부터 GraphQL을 사용했고, 지금은 모든 모놀리식 어플리케이션에서 GraphQL을 사용하고 있습니다.
GraphQL이란
GraphQL은 클라이언트가 원하는 데이터만 요청할 수 있도록 하는 API 규격입니다. 클라이언트마다 약간씩 다른 데이터 요구사항을 가지는 시스템에 적합합니다.
또한 Reddit은 마이크로서비스에서 GraphQL을 사용하기 위해, GraphQL Federation을 사용하고 있습니다.
GraphQL Federation은 작은 GraphQL schema를 조합하여 하나의 큰 GraphQL schema로 만드는 방식으로, 마이크로서비스 환경에 적합합니다.
클라이언트는 하나의 슈퍼그래프에만 요청하고, 해당 슈퍼그래프가 요청 데이터를 보고 어떤 서프그래프가 데이터를 가지고 있는지 파악하여 라우팅하는 방식입니다.
Reddit은 서브레딧(Subreddit)과 코멘트와 같은 핵심 엔티티에 대해 Go로 작성된 서브그래프를 추가했습니다.
그렇게 한 동안 Python 모놀리식 서버와 Go 서브그래프는 함께 운영되었고, 점점 더 많은 기능이 Go 서브그래프로 추출됨에 따라 모놀리식을 완전히 종료할 수 있었습니다.
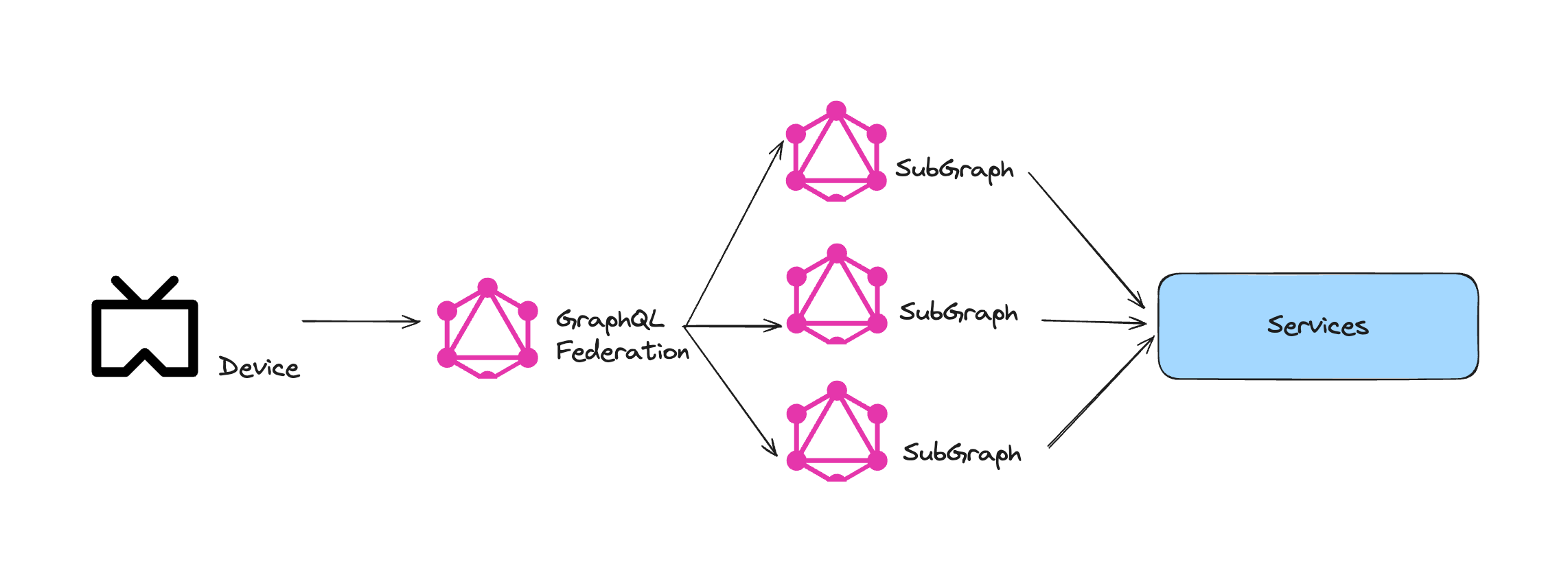
Reddit은 트래픽을 점진적으로 Go 서브그래프 기반으로 전환하면서, 문제가 발생할 경우 다시 모놀리스로 전환하는 기능을 갖추고자 했습니다.
그러나 GraphQL Federation은 점진적 트래픽 마이그레이션을 지원하지 않았습니다. 그래서 Reddit은 Blue/Green 서브그래프 배포를 선택했습니다.
Python 모놀리식과 새로운 서브그래프 모두 같은 스키마를 가지고 있고, 마이그레이션 시 로드밸런서가 트래픽을 퍼센티지에 따라 양쪽에 분산할 수 있도록 했습니다.
지금도 Reddit은 이러한 설계에 따라 최소한의 중단으로 마이그레이션하고 있습니다.
Data Replication (w. CDC, Debezium)
초기 Reddit은 주 데이터베이스의 WAL을 통해 데이터 리플리케이션을 진행했습니다.
WAL(write-ahead-log)이란?
데이터베이스에 대한 모든 변경 사항이 커밋되기 전에 기록되는 파일입니다. 쓰기 작업 중에 장애가 발생하면 로그에서 변경 내용을 복구할 수 있습니다.
주 데이터베이스가 다운되는 것에 대비해 PostgreSQL WAL 파일을 S3에 지속적으로 아카이빙했습니다.
그러나 S3에 스냅샷을 저장하는 과정에서 실패하거나, 밤에 일배치로 스냅샷을 저장해서 낮 시간에는 데이터 불일치 상태인 등 여러가지 문제가 있었습니다.
그래서 CDC(Change Data Capture) 서비스를 이용하기로 했고, 이 과정에서 Debezium과 Kafka Connect가 사용되었습니다.
CDC란?
데이터가 변경되는 시점에 해당 항목을 추적하고, 다른 시스템 및 서비스에 알림을 전송하는 패턴입니다.
행이 추가/삭제되는 등 Postgres에 변화가 일어나면, Debezium이 변경 사항을 Kafka topic으로 전달합니다. 그리고 해당 topic의 downstream 서비스들이 알림을 읽고 리플리케이션 대상 테이블에 변경사항을 똑같이 반영합니다.
Debezium을 통한 CDC를 통해, Reddit은 실시간으로 데이터 리플리케이션을 할 수 있었습니다.
대규모 미디어 메타데이터 관리
초기 Reddit는 미디어 메타데이터가 다양한 시스템에 혼재되어있고, 메타데이터의 변경사항을 감시할 수 있는 방법이 없었습니다. 그리고 데이터를 분류/분석할 수 있는 적절한 메커니즘 또한 없었습니다.
그래서 Reddit은 미디어 메타데이터를 아래와 같이 관리하고자 했습니다.
- 모든 미디어 메타데이터는 공통된 공간에 옮깁니다.
- 50밀리초 미만의 지연 시간으로, 초당 10만 건의 데이터 검색을 지원합니다.
- 데이터 생성/업데이트를 지원합니다.
데이터 스토어로 Postgres와 Cassandra 사이에서 고민했지만, Cassandra에서 디버깅을 위한 임시 쿼리의 어려움과 일부 데이터가 정규화되지 않아 검색할 수 없는 잠재적 위험 때문에 AWS Aurora Postgres를 선택했습니다.
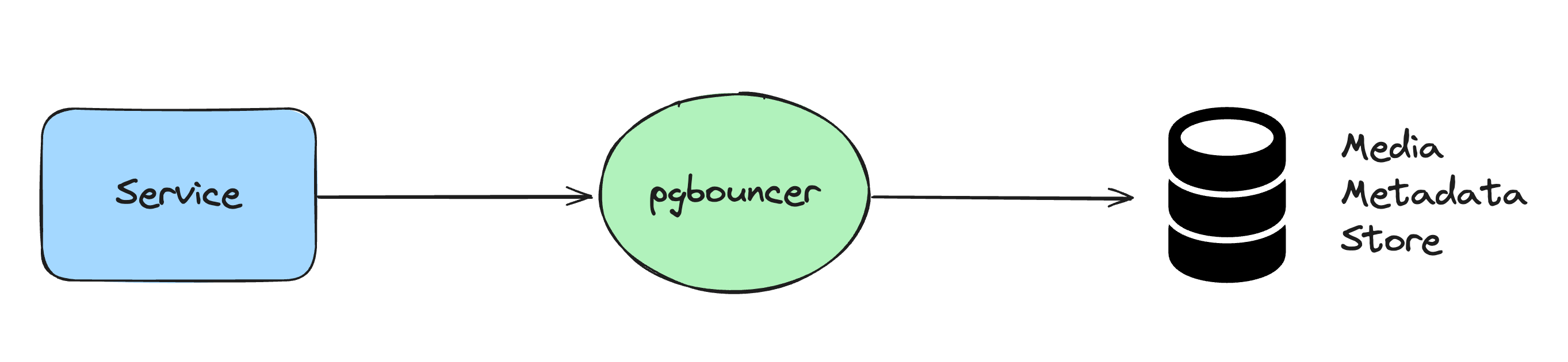
pgbouncer: PostgreSQL용으로 설계된 Connection Pooler
단순히 API로 메타데이터 데이터베이스를 쿼리하는 것으로, 설계는 복잡하지 않았습니다.
그러나 다양한 소스에서 수 테라바이트의 데이터를 새 데이터베이스로 전송하는 동시에, 시스템이 계속 작동하도록 하는 것이 문제였습니다.
그래서 마이그레이션은 아래 프로세스로 이루어졌습니다.
- 미디어 메타데이터의 클라이언트에서 메타데이터 API로의 이중 쓰기를 활성화합니다.
- 이전 데이터베이스에서 새 메타데이터 저장소로 데이터를 백업합니다.
- 서비스 클라이언트에서 미디어 메타데이터에 대한 이중 읽기를 활성화합니다.
- 모든 읽기 요청에 대해 데이터를 비교하고, 문제가 발생하면 수정합니다.
- 새 메타데이터 저장소로 읽기 트래픽을 점진적으로 증가시킵니다.
그 외 추가적인 확장 전략(range-based 파티셔닝, 비정규화된 JSON 타입 필드 이용하여 읽기 요청 처리 등)을 적용한 뒤, 이전 데이터 시스템보다 50% 빠른 성능을 보였습니다.
결론
Reddit의 아키텍처는 요구사항에 따라 끊임없이 진화해 왔습니다. 모놀리식 Lisp 어플리케이션으로 시작한 것이 Python으로 재작성되긴 했지만, 이 모놀리식 접근 방식은 Reddit의 폭발적인 인기를 따라잡을 수 없었습니다.
그래서 서비스 기반 아키텍처로 전환했습니다. 새로운 기능과 문제에 직면할 때마다 사용자 보호, 미디어 메타데이터 관리, 커뮤니케이션 채널, 데이터 복제, API 관리 등 다양한 영역에서 전반적인 설계에 변화를 주어야 했습니다.
Reddit은 지금도 끊임없이 아키텍처에 변화를 시도하고 있습니다. 앞으로 또 어떤 여정을 거칠지 기대가 됩니다.

재밌는 글 감사합니다.