
Daily Coding
입력 받는 배열의 순서를 뒤집어 리턴하라.
- 반복문 사용금지
- 재귀로 풀 것
import java.util.Arrays;
public class ReverseArr {
// 0번 인덱스를 마지막으로 보내기
// 보낸 요소 빼고 재귀
// 맨 앞 인덱스 뒤에 붙이기 반복
public int[] reverseArr(int[] arr){
if(arr.length==0) return arr;
int[] result1 = Arrays.copyOfRange(arr,0,1);
int[] result2 = reverseArr(Arrays.copyOfRange(arr,1, arr.length));
int[] result = new int[arr.length];
System.arraycopy(result2, 0, result, 0, result2.length);
System.arraycopy(result1, 0, result, result2.length, result1.length);
return result;
}
}
//입력
System.out.println(Arrays.toString(reverseArr.reverseArr(new int[]{1, 2, 3, 4, 5})));
//출력
[5, 4, 3, 2, 1]모든 테스트케이스 통과
Section2 - 관계형 데이터베이스
설계
Schema & Query Design
schema(스키마) = DB에서 데이터가 구성되는 방식과 서로 다른 엔티티 간의 관계에 대한 설명
Entity(엔티티) = 정보의 단위
데이터베이스 설계
관계형 DB 키워드
- 데이터(data): 각 항목에 저장되는 값
- 테이블(table; 또는 relation) : 사전에 정의된 열의 데이터 타입대로 작성된 데이터가 행으로 축적된다.
- 칼럼(column; 또는 field) : 테이블의 한 열
- 레코드(record; 또는 tuple) : 테이블의 한 행에 저장된 데이터
- 키(key) : 테이블의 각 레코드를 구분할 수 있는 값. 각 레코드마다 고유한 값을 가진다. 기본키(primary key)와 외래키(foreign key) 등이 있다.
- 관계(relationship) : 테이블간의 관계는 관계를 맺는 테이블의 레코드 수에 따라 나뉨.
(관계를 나타내기 위해 외래 키(foreign key) 사용.)
관계 종류
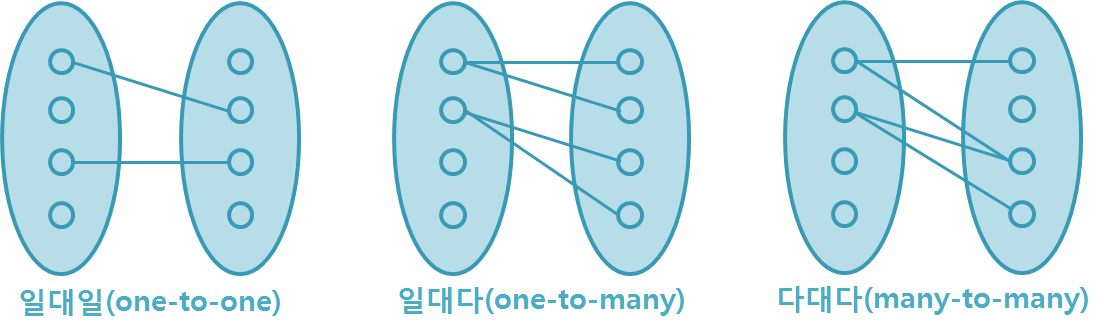
1:1 관계
하나의 레코드가 다른 테이블의 레코드 한 개와 연결된 경우
- 자주 사용하지 않음
- 1:1로 나타낼 수 있는 관계라면 데이터를 연결하지 않고 직접 저장하는 게 나을 수 있다.
1:N 관계
하나의 레코드가 서로 다른 여러 개의 레코드와 연결된 경우
- 주로 소수테이블의 넘버(기본키)를 다수테이블에 넣어 외래키를 넣는 방식으로 관리
N:N 관계
여러 개의 레코드가 다른 테이블의 여러 개의 레코드와 관계가 있는 경우
- Join 테이블을 만들어 관리
(조인 테이블을 위한 기본키(primary key)는 반드시 있어야 한다.) - 양방향에서 다수의 레코드를 가질 수 있다.
자기참조 관계(Self Referencing Relationship)
때로는 테이블 내에서도 관계가 필요하다.
ex. person이라는 테이블의 각 레코드(사람)간의 관계가 있을 수 있음.
SQL 내장함수
GROUP BY 로 조회된 결과를 필터링
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s);
//예시
SELECT CustomerId, AVG(Total)
FROM invoices
GROUP BY CustomerId
HAVING AVG(Total) > 6.00cf. WHERE은 레코드를 필터링
이 밖에 자주 사용하는 COUNT(), SUM(), AVG(), MAX(), MIN()는 SQL Practice 참고
SELECT 실행 순서
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
SELECT CustomerId, AVG(Total)
FROM invoices
WHERE CustomerId >= 10
GROUP BY CustomerId
HAVING SUM(Total) >= 30
ORDER BY 2FROM invoices: invoices 테이블에 접근WHERE CustomerId >= 10: CustomerId 필드가 10 이상인 레코드들을 조회GROUP BY CustomerId: CustomerId를 기준으로 그룹화HAVING SUM(Total) >= 30: Total 필드의 총합이 30 이상인 결과들만 필터링SELECT CustomerId, AVG(Total): 조회된 결과에서 CustomerId 필드와 Total 필드의 평균값을 구함ORDER BY 2: AVG(Total) 필드를 기준으로 오름차순 정렬한 결과를 리턴
Instagram 스키마 디자인
- 게시물(Post) 작성 기능
- 게시물에 댓글 달기 및 좋아요 기능
- 해시태그 기능
- follow 기능
위 네가지 기본 인스타그램 기능을 구현하기 위해 필요한 데이터들의 스키마를 그려보았다.
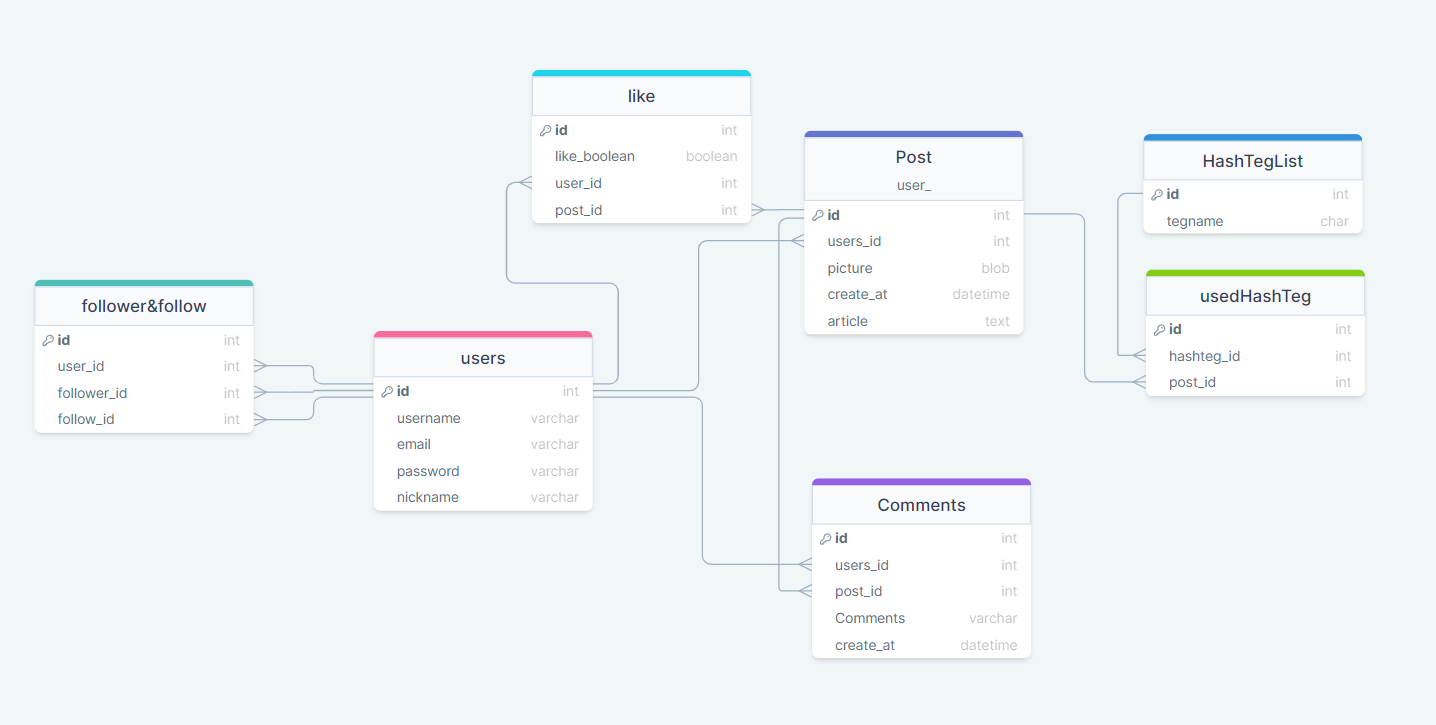
like기능과 hashteg 기능 모두 comments(댓글)에서도 쓸 수 있는 기능이니까 추가해보자.
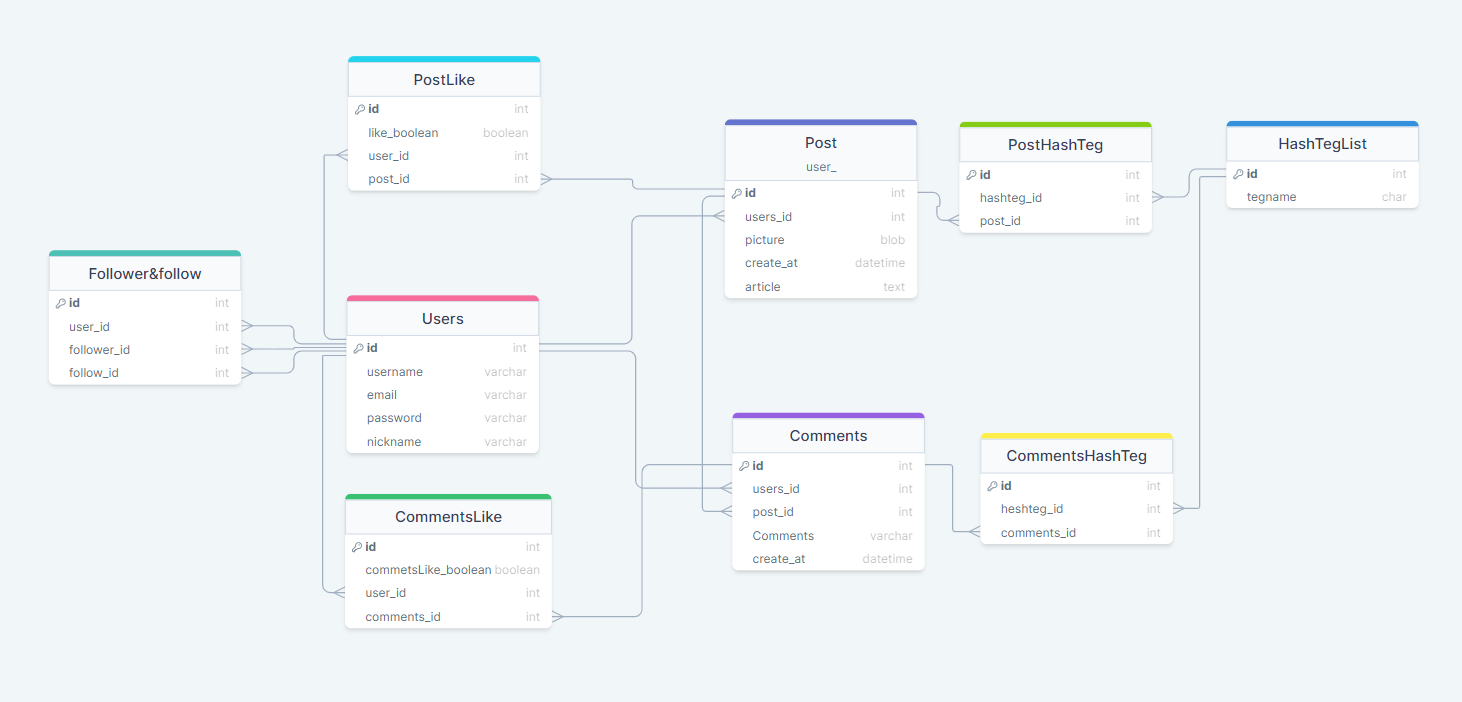
ans
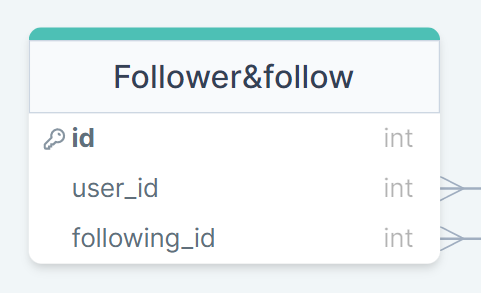
나를 팔로우 하는 유저의 정보는 해당 유저의 팔로잉_id에 남아 있기 때문에 굳이 추가적인 데이터(follow_id)로 조회하지 않아도 된다.
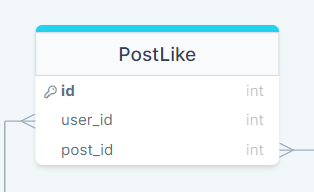
Like의 경우 boolean 데이터를 굳이 작성할 필요가 없다.
테이블에 값이 존재하면 그것 자체로 불린의 역할을 해줄 수 있다.
물론 위의 두가지 사항을 수정하지 않아도 구현은 된다. 다만, 굳이 쓰지 않아도 되는 데이터들이 추가 되므로써 성능에 낭비가 있을 것이다.
