
Daily Coding 26번
깊이 우선 탐색(DFS, Depth First Search)을 통해 순서대로 노드의 요소를 리스트에 담아 리턴하시오.

위 그림 같은 tree형 자료구조가 입력되면 -> [1, 2, 4, 5, 3] 리턴하시오.
import java.util.ArrayList;
public class DfsSolution {
public ArrayList<String> dfs(tree node) {
ArrayList<String> result = new ArrayList<>();
result.add(node.getValue());
------------------------------오류지점------------------------------
if(!node.getChildrenNode().equals(null)){
------------------------------오류지점------------------------------
for(tree o : node.getChildrenNode()) {
result.addAll(dfs(o));
}
}
return result;
}
public static class tree {
private String value;
private ArrayList<tree> children;
public tree(String data) {
this.value = data;
this.children = null;
}
public tree addChildNode(tree node) {
if(children == null) children = new ArrayList<>();
children.add(node);
return children.get(children.size() - 1);
}
public String getValue() {
return value;
}
public ArrayList<tree> getChildrenNode() {
return children;
}
}
}
null은 .equals() 메서드를 갖고있지 않기 때문에 NullPointerException 발생
import java.util.ArrayList;
public class DfsSolution {
public ArrayList<String> dfs(tree node) {
ArrayList<String> result = new ArrayList<>();
result.add(node.getValue());
if(node.getChildrenNode()!=null){
for(tree o : node.getChildrenNode()) {
result.addAll(dfs(o));
}
}
return result;
}
public static class tree {
private String value;
private ArrayList<tree> children;
public tree(String data) {
this.value = data;
this.children = null;
}
public tree addChildNode(tree node) {
if(children == null) children = new ArrayList<>();
children.add(node);
return children.get(children.size() - 1);
}
public String getValue() {
return value;
}
public ArrayList<tree> getChildrenNode() {
return children;
}
}
}
모든 테스트케이스 통과
Daily Coding 26번
너비 우선 탐색(BFS, Breadth First Search)을 통해 순서대로 노드의 요소를 리스트에 담아 리턴하시오.
public ArrayList<String> bfs(tree node) {
ArrayList<String> result = new ArrayList<>();
Queue<tree> queue = new LinkedList<>();
// ArrayList<tree> visited = new ArrayList<tree>();
// visited.add(node);
// visited.add(true);
// boolean[] isvisited = new boolean[];
queue.add(node);
result.add(node.getValue());
tree s = node;
while (queue.size() != 0) {
// 방문한 노드를 큐에서 추출하고 값을 출력
s = queue.poll();
result.add(s.getValue());
// 방문한 노드와 인접한 모든 노드를 가져온다.
Iterator<tree> i = new LinkedList<>(s.getChildrenNode()).iterator();
while (i.hasNext()) {
tree n = i.next();
// 방문하지 않은 노드면 방문한 것으로 표시하고 큐에 삽입
if (n.getValue()!=null) {
queue.add(n);
result.add(n.getValue());
}
}
}
return result;
}방문처리를 어떻게 해야할지 방법이 너무 생각 안나서 오래 고민했다.
tree타입의 객체는 set을 지원하지 않기 때문에 똑같은 자료구조를 만들어서 값을 바꾸는 방식으로 할 수도 없었다.
그렇다고 contain메서드 같이 요소값이랑 똑같은 값을 이미 추가했는지 비교하는 방식은 같은 자료구조에서 다른 위치에 같은 value값을 갖는 case 때문에 사용하면 안될 것 같다.
public ArrayList<String> bfs(tree node) {
ArrayList<String> result = new ArrayList<>();
Queue<tree> queue = new LinkedList<>();
ArrayList<Boolean> isvisited = new ArrayList<>();
int num = 2;
queue.add(node);
result.add(node.getValue());
tree s = node;
while (queue.size() != 0) {
// 방문한 노드를 큐에서 추출하고 값을 출력
s = queue.poll();
result.add(s.getValue());
isvisited.add(true);
// 방문한 노드와 인접한 모든 노드를 가져온다.
Iterator<tree> i = new LinkedList<>(s.getChildrenNode()).iterator();
while (i.hasNext()) {
tree n = i.next();
// 방문하지 않은 노드면 방문한 것으로 표시하고 큐에 삽입
if (isvisited.size()<num) {
queue.add(n);
result.add(n.getValue());
num++;
isvisited.add(true);
}
}
}
return result;
}위와 같은 방식으로 방문한 횟수를 카운팅해서 비교하면 될 것 같다.
아직은 구조가 완벽하지 않아 널포인트 오류가 뜨고 있다.
public ArrayList<String> bfs(tree node) {
ArrayList<String> result = new ArrayList<>();
Queue<tree> queue = new LinkedList<>();
ArrayList<Boolean> isvisited = new ArrayList<>();
int num = 2;
queue.add(node);
result.add(node.getValue());
tree s = node;
isvisited.add(true);
while (queue.size() != 0) {
// 방문한 노드를 큐에서 추출하고 값을 출력
System.out.println(result.toString());
s = queue.poll();
//result.add(s.getValue());
if(s.getChildrenNode()==null) {
//result.add(s.getValue());
continue;
}
// 방문한 노드와 인접한 모든 노드를 가져온다.
Iterator<tree> i = new LinkedList<>(s.getChildrenNode()).iterator();
while (i.hasNext()) {
tree n = i.next();
// 방문하지 않은 노드면 방문한 것으로 표시하고 큐에 삽입
if (isvisited.size()<num) {
queue.add(n);
result.add(n.getValue());
num++;
isvisited.add(true);
}
}
}
return result;
}디버깅을 통해 전체적인 흐름을 잡아 수정하니 모든 테스트에 통과했다.
위 방법은 child를 기준으로 결과값에 넣는 방식으로 진행했다.
아래 방법처럼 value를 기준으로 할 수도 있다.
public ArrayList<String> bfs2(tree node) { // 방문처리 굳이 안하고 이렇게 해도 된다.
Queue<tree> queue = new LinkedList<>();
ArrayList<String> values = new ArrayList<>();
queue.add(node);
while(queue.size() > 0) {
tree curNode = queue.poll();
values.add(curNode.getValue());
if(curNode.getChildrenNode() != null) {
queue.addAll(curNode.getChildrenNode());
}
}
return values;
}굳이 방문처리를 할 필요없이 이렇게 해도 된다.
Spring Data JDBC 기반의 도메인 엔티티 및 테이블 설계
DDD(Domain Driven Design)
도메인 위주의 설계 기법
- 대상 시스템을 운영하는 환경에 관한 지식
- 구현, 설계하고자 하는 정보, 지식
- ex. 키오스크 프로그램을 만든다고 치면 장바구니, 주문기능이 있어야 겠다고 생각할 것이다. 이런게 도메인 지식이다.
- 서비스 계층에서 비즈니스 로직으로 구현하는 것들
애그리거트(Aggregate)
- 도메인들의 묶음
- 비슷한 범주의 연관된 업무들을 하나로 그룹화 해놓은 것
애그리거트 루트(Aggregate Root)
- 애그리거트 즉, 도메인들의 묶음에서 해당 묶음을 대표하는 도메인
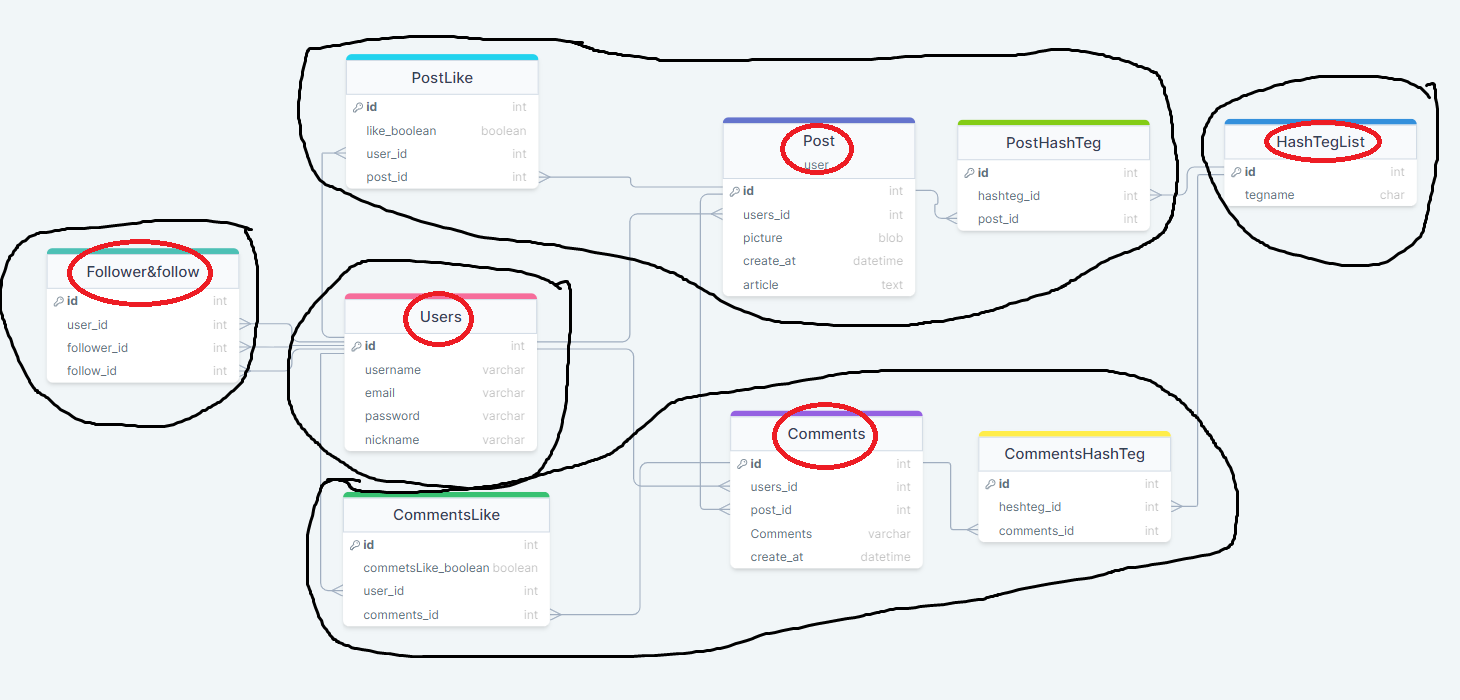
전에 디자인 했던 schema(스키마)다. (사진에 링크 첨부 해뒀음)
위와 같이 검정색 묶음이 애그리거트(Aggregate)고
빨간색으로 표시한게 애그리거트 루트(Aggregate Root)다.
도메인 엔티티 클래스 정의
Spring Data JDBC에서의 애그리거트(Aggregate) 객체 매핑
애그리거트 객체 매핑 규칙
-
모든 엔티티 객체의 상태는 애그리거트 루트를 통해서만 변경할 수 있다.
-
애그리거트(묶음) 내에서 각각의 엔티티 간의 연결은 객체를 참조하는 방식으로 연결한다.
-
서로 다른 애그리거트(묶음)의 애그리거트 루트 간의 참조는 (1대1과 1대N 관계일 때) 객체 참조 대신에 ID(Foreign key)로 참조한다.
(N대N 관계일 때는 외래키 방식인 ID 참조와 객체 참조 방식이 함께 사용)
사용 기능
@Table
-
엔티티와 매핑할 테이블을 지정
-
생략 시 매핑한 엔티티 일므을 테이블 이름으로 사용
@Id
- 기본 키 매핑(식별자로 지정)
- 사용한 멤버변수를 포함한 클래스를 자동으로 같은 이름의 테이블과 매핑시킨다.
@Entity역할까지 해줌. - 직접적인 객체 참조가 아닌 ID 참조(1대N 관계의 애그리거트 루트 간 ID 참조)로 만들려면
AggregateReference클래스로 감싸줘야 함. - N 대 N 관계에서는
AggregateReference로 감쌀 필요가 없다.
@Getter
@Setter
@Table("ORDERS") // 엔티티와 매핑할 테이블을 지정, 생략 시 매핑한 엔티티 이름을 매핑할 테이블 이름으로 사용
// ‘Order’라는 단어는 SQL 쿼리문에서 사용하는 예약어이기 때문에 테이블 이름을 변경
public class Order {
@Id // 기본 키 매핑(식별자로 지정)
private long orderId;
// 매핑 규칙 3번 = 애그리거트 루트와 애그리거트 루트 간에는 객체로 직접 참조하는 것이 아니라 ID로 참조한다.
private AggregateReference<Member, Long> memberId; // 테이블 외래키처럼 memberId를 추가해서 참조하도록 한다.
// AggregateReference클래스로 Member클래스를 감싸면 직접적인 객체 참조가 아닌 ID 참조가 이루어진다.
~~~
} - 1대N 관계일 때 객체 참조 대신에 ID로 참조하게 하려고 감싸는 용도
- 엔티티 클래스 간에 연관 관계를 설정하는 에너테이션
- 같은 에그리거트 관계에서만 사용하는 것
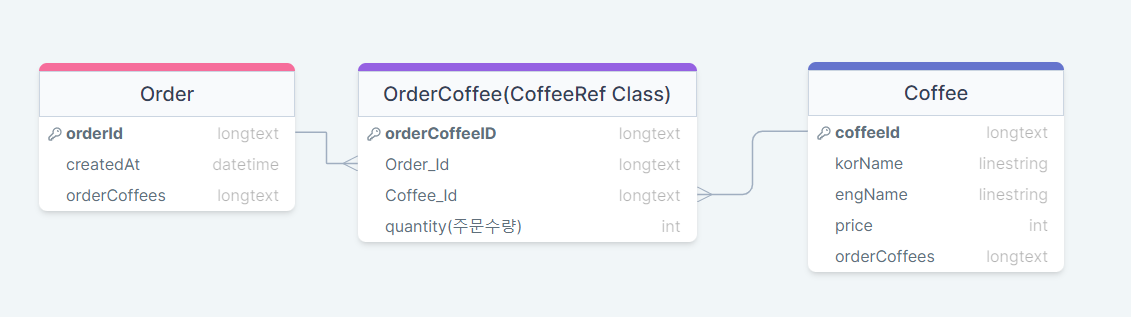
public class Order {
~~~
@MappedCollection(idColumn = "ORDER_ID", keyColumn = "ORDER_COFFEE_ID")
private Set<CoffeeRef> orderCoffees = new LinkedHashSet<>(); // CoffeeRef클래스와 1대N 관계 연결
~~~
} idColumn= 자식 테이블에 추가되는 외래키에 해당되는 컬럼명 지정keyColumn= 외래키를 포함하고 있는 테이블의 기본키 컬럼명을 지정
Spring Data JDBC를 통한 데이터 액세스 계층 구현(2) - 서비스, 리포지토리 구현
사용기능 정리
CrudRepository인터페이스
- 데이터를 데이터베이스의 테이블에 저장, 조회, 수정, 삭제하는 기능을 갖고 있는 인터페이스
- Repository 인터페이스 만들 때 상속해서 사용하면 됨
UriComponentsBuilder 클래스
- URI 객체 생성할 때 쓰는 클래스
URI location =
UriComponentsBuilder
.newInstance()
.path(ORDER_DEFAULT_URL + "/{order-id}")
.buildAndExpand(order.getOrderId())
.toUri();Optional클래스
- 데이터 검증에 대한 로직 만들 때 쓰기 좋은 메서드를 많이 갖고 있다.
Optional.ofNullable= 값이 null이더라도 NullPointerException이 발생하지 않고, 다음 메서드 호출 가능
- 빌더 자동생성
- 메서드, 생성자에 붙여서 사용
- 간단하게 말하자면 new 객체를 하나 만들고 일일이 set으로 멤버변수 하나하나 값을 초기화해서 원하는 객체를 만드는게 아니라 빌더를 통해 한번에 세팅하면서 객체를 만들어 내는 것이다.
- cf) 클래스 레벨에서 @Builder 어노테이션을 붙이면 모든 요소를 받는 package-private 생성자가 자동으로 생성되며 이 생성자에 @Builder 어노테이션을 붙인 것과 동일하게 동작한다고 한다. 즉 클래스 레벨도 결국은 중간 단계를 거쳐 생성자 레벨로 변환되어 동작한다.
쿼리 메서드(Query Method)
Spring Data JDBC에서는 쿼리 메서드를 이용해서 SQL 쿼리문을 사용하지 않고 데이터베이스에 질의를 할 수 있다.
데이터 조회 메서드 정의 예시
find + By + SQL 쿼리문에서 WHERE 절의 컬럼명 + (WHERE 절 컬럼의 조건이 되는 데이터)
- Spring Data JDBC에서는 위 형식으로 쿼리 메서드(Query Method)를 정의하면 조건에 맞는 데이터를 테이블에서 조회한다.
public interface MemberRepository extends CrudRepository<Member, Long> {
Optional<Member> findByEmail(String email);
// Member테이블의 Email열 값이 email인 row를 찾는 메서드
}- cf)
And를 사용하면 WHERE 절의 조건 컬럼을 여러 개 지정 가능findByEmailAndName(String email, String name)
위 방법 말고도 @Query() 에너테이션을 이용해서도 가능하다.
@Query("SELECT * FROM COFFEE WHERE COFFEE_ID = :coffeeId")
service, repository 구현 적용
아래와 같이 커피주문 샘플 애플리케이션을 만들어 봤다.
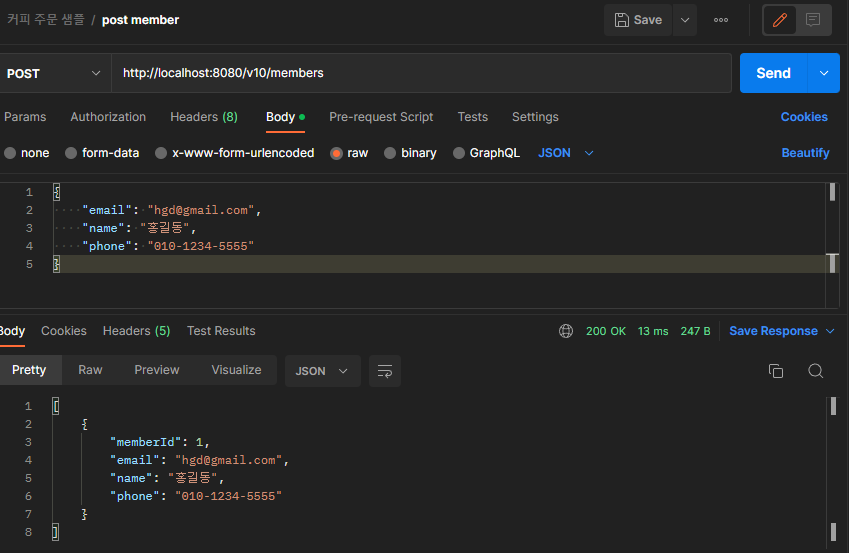
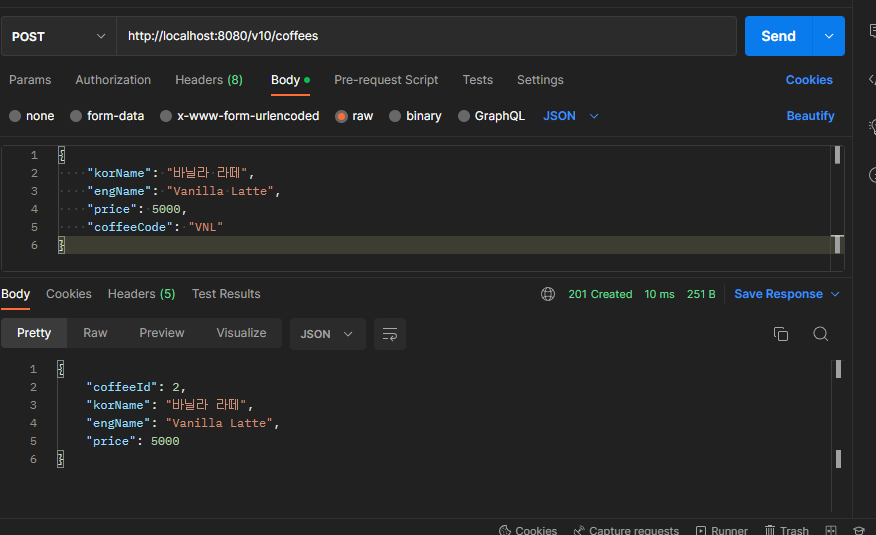
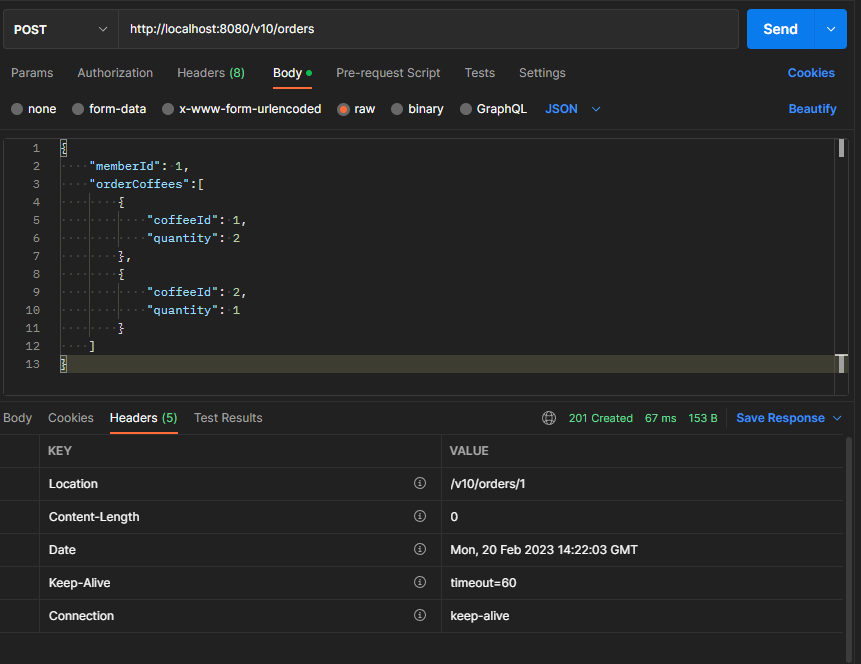
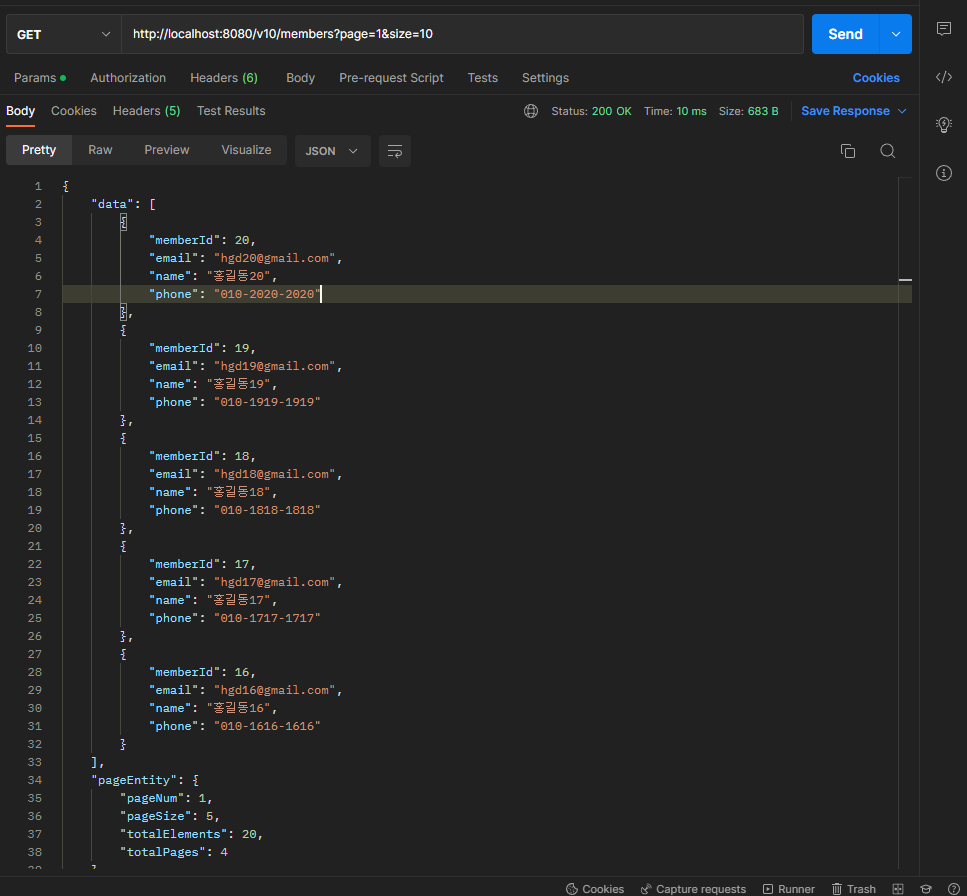
페이지네이션(Pagenation) 기능 구현
풀코드 GitHub 학원에서 올린 실습용 코드를 fork해와서 외부에서는 접근이 안되는 것 같다.
오늘의 정리
- Spring data JDBC는 단방향이다!!
- 위 예제로 설계한 코드에서 coffee객체가 orederId를 참고할 수 없다!!
