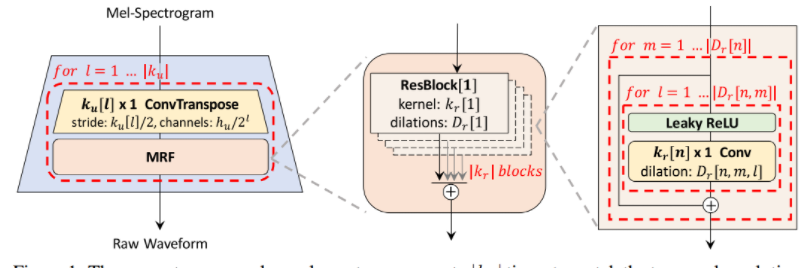
참고 논문 : HifiGAN
이제까지 이미지 도메인에서 GAN을 다뤄보았다.
이제부터 음성 데이터로 진행해서, 목표까지 도달해보려고 한다.
이미지는 기본적으로 2차원의 픽셀로 이루어져있고, RGB 등의 색 채널이 추가되어 3차원으로 이루어져있기도 하다.
음성 데이터의 경우에는 1차원의 신호로 이루어져있다.
GAN의 기본 원리는 그대로이고,
몇 가지 개념들을 이미지 도메인에서 음성 도메인으로 수정하면 된다.
먼저, 음성 합성 기술은 크게 두 단계로 이루어진다.
-
Mel-spectrogram 생성
-
waveform(파형) 생성
MFCC (Mel-Frequency Cepstral Coefficient)
- 음성 데이터를 특징 벡터(Feature)화 해주는 알고리즘을 의미한다.
Mel 은 사람의 달팽이관을 의미한다.
사람의 달팽이관은 간단히 말해서 여러가지 부분으로 구성되어있고,
각 부분은 각기 다른 진동수(주파수)를 감지한다.
즉 어떤 부분은 저주파수, 어떤 부분은 고주파수를 담당한다.
그런데, 이들의 성능이 달라서
사람은 주파수가 낮은 대역에서는 변화를 잘 감지하는데,
주파수가 높은 대역에서는 변화를 잘 감지하지 못 한다.
따라서, 어떤 음성 데이터를 특징 벡터화할때, 사람의 달팽이관의 특성에 맞추어 벡터화하는 것이 더욱 효과적인 feature가 될 것이다.
이렇게 사람의 달팽이관을 고려해서 값을 만들어낸 것을 Mel-scale이라고 한다.
잠깐 간단히 이해하고 넘어가야할 개념으로 푸리에 변환(Fourier transform)이 있다.
간단히 말해서, 어떠한 신호를 여러 주파수를 갖는 주기함수들의 합으로 분해하여 표현하는 것이다.
다시 설명하면, 어떠한 함수 f(x)를 sin, cos 주기함수들의 합으로 분해하는 것이다.
앞서 mel-scale을 한다는 것은
어떠한 음성 데이터를 다양한 주파수 대역의 신호들로 분해해서 뽑아낸다고 할 수 있을 것이다.(푸리에 변환 적용)
그런데, 사람이 내는 음성은 길이의 차이가 있다.
똑같은 단어를 말하는데 있어, 그 발화 속도의 차이가 있는 것이다.
데이터화를 위해서, 길이에 대해 기준을 마련하고 단위 시간으로 잘라낼 필요가 있는데,
이에 대한 연구 결과를 바탕으로 사람은 20~40ms 사이에서는 음소(현재 발음하고 있는 음성)가 바뀔 수 없다고 한다.
따라서 음성 데이터를 20~40ms 단위로 쪼개고, 쪼갠 단위마다 Mel 값을 뽑아서 Feature로 사용한다.
MFCC는 다음과 같은 과정으로 진행된다.
-
Voice Input from the Speaker
-
Pre-Emphasis
-> 사람 몸의 구조 때문에, 실제로 발음한 소리에서 고주파 성분은 많이 줄어든다고 한다. 이를 반영한 필터를 적용하는 과정이다. -
Sampling and Windowing
-> 20-40ms 단위의 프레임으로 분할하는 과정이다. 이때 일반적으로 50% 겹치게 프레임을 나눈다.(연속성) 연속성을 유지하지 않으면 프레임 간 순간 변화율이 무한대가 되어 문제가 생길 수 있다. -
Fast Fourier Transform
-> 각 프레임의 음성 데이터를 여러 주파수로 분리한다. 여기 까지 진행한 데이터로 진행하면 사람의 몸의 구조를 고려하지 않은 데이터라서 성능이 좋지 않다. -
Mel Filter Bank
-> 사람의 몸의 구조를 반영한 필터의 모음을 Mel Filter Bank 라고 한다. 4에서 얻어낸 데이터에 필터를 적용한다.
그렇게 가공된 데이터를 Mel-Spectrogram 이라고 한다. 여기까지만 진행하고 사용하는 경우도 있으며, HifiGAN 또한 그렇다.
6. Discrete Cosine Transform(DCT)
-> Mel-Spectrogram에 대해 DCT 연산을 수행하면 MFCC(Mel-Frequency Cepstral Coefficient)가 출력된다.
7. Output Mel-coefficients
사실 내가 사용하는 입장에서는 모듈화가 진행되어 있어
음성 데이터를 입력해서 간단히 MFCC를 뽑아낼 수 있기 때문에 간단히만 이해하고 넘어간다.
