프로그래머스 인공지능 데브코스
1.[1주차] 의도하지 않았던 얕은 복사

프로그래머스 인공지능 데브코스 3기를 시작한지 1주일이 지났다.첫 글을 어떻게 시작할지 고민을 많이 했는데, 1주일간 컴퓨터적 사고력을 기르기 위해 여러 알고리즘 강의를 듣는 중에 떠오른 의문을 해결해보고자 한다.내가 하고자 했던 일은 다음과 같다.하나의 리스트를 만드
2.[2주차]인공지능 수학 - 211213
Enter / Esc : 명령 모드(푸른색), 입력 모드(녹색) 전환Ctrl + Enter / Shift + Enter : 셀 실행DD(명령 모드) : 셀 삭제M / Y : 마크다운, 코드 셀 전환A / B : 위, 아래에 셀 추가앞으로 자주 사용하면서 체득하도록 해야
3.[2주차]인공지능 수학 - 20211214(1)
행렬을 임의의 개수의 조각으로 분해하면계산의 편의성을 얻을 수 있다.행렬 분해의 방법은LU 분해(LU decomposition)QR 분해(QR decomposition)특이값 분해(SVD, Singular Value Decomposition)이 있다.L : lower
4.[2주차]인공지능 수학 - 20211214(2)
선형 시스템 문제를 벡터의 좌표계 변환으로 생각할 수 있다.Ax = b가 있을 때,$$Av{A} = Bv{B}$$행렬 = 좌표계벡터 = 좌표값(행렬 A를 좌표계로 했을 때) 임의의 v는 다양한 좌표계에서 표현될 수 있다기저벡터란, 좌표계를 구성하는 기준 벡터이다.원점을
5.[2주차]인공지능 수학 - 20211215(1)
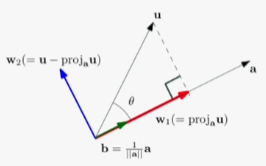
좌표계에서의 벡터의 방향 벡터를 벡터의 길이로 나눈 것 $$ {1 \over ||a||}a $$ 투영 두 벡터 u, a가 있을 때 벡터 u를 a 위에 투영한 벡터를 $$ proj_au $$ 라고 한다. 보완 두 벡터 u, a가 있을 때, 투영과 보완의 개념을
6.[2주차]인공지능 수학 - 20211215(2)
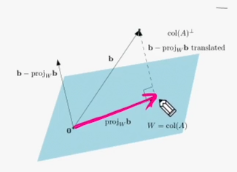
공간(space)은 덧셈연산(+), 스칼라 곱(k배) 연산에 닫혀 있다.n-벡터 집합은 공간이다.그리고 이를 벡터 공간이라고 한다.선형 시스템 Ax=b에 대한 해가 없음에도 불구하고, 달성가능한 최선의 목표(근사치) $proj_wb$ 를 구하는 것b를 col(A)=w에
7.[2주차]인공지능 수학 - 20211216(1)
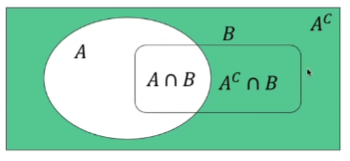
가능한 경우의 수표본 공간의 원소어떠한 사건이 일어나는 경우/표본 공간어떤 집합에서 순서에 상관없이 뽑은 원소의 집합사건 A가 일어날 확률 : P(A)사건 A 나 B가 일어날 확률 : P(A) $\\cup$ P(B)사건 A와 B가 동시에 일어날 확률 : P(A) $\\
8.[3주차]Matplotlib - 20211223
파이썬의 데이터 시각화 라이브러리%matplotlib inline을 통해서 활성화(주피터 노트북).plot() : plotting을 하는 함수.show() : plot을 확인하는 명령plot을 할 도면 선언.figurex = np.array(1, 2, 3, 4, 5)y
9.[3주차] Pandas & Matplotlib - 20211224

Pandas 및 Matplotlib을 이용한 문제이다. 1. Netflix and Code 자료는 https://www.kaggle.com/shivamb/netflix-shows 한국 작품은 총 얼마나 있는가? country column을 기준 "South Ko
10.[4주차]Flask - 20211227
Flask를 활용한 간단한 web app을 구현하고,Postman을 활용하여 get / post 테스트를 해보았다.이를 좀더 구체화시키기 위해 다음과 같은 과제를 수행한다.앞서 간단히 진행한 get / post 과제는 자원 관리 CRUD(Create, Read, Upd
11.[4주차] AWS - 20211228
이전에는 클라우드 서비스 마이크로소프트 Azure를 사용해보았었는데, 프로그래머스 데브코스에서는 AWS를 다뤄보게 되었다. AWS는 인스턴스를 생성한 후에, 보안 key 파일을 가지고 ssh 접속을 해야 한다. ssh 접속은 평소 자주 사용하던 mobaXterm을
12.[4주차] EDA - 20211229
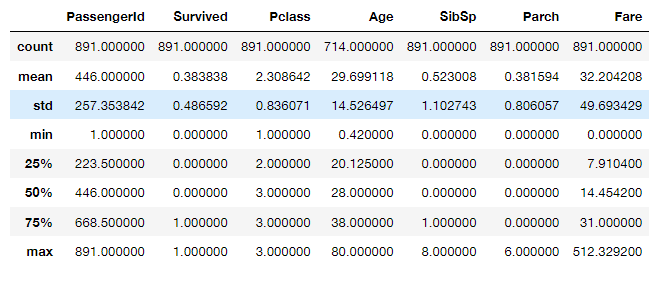
데이터 그 자체만으로부터 인사이트를 얻어내는 접근법타이타닉 데이터목적이 무엇인가?데이터 안의 변수는 어떤 것이 있는가?데이터의 생김새 파악하기데이터 타입 확인하기titanic_df.corr()titanic_df.isnull().sum()
13.[5주차]django - 20220104
대규모 프로젝트에 적합내장되어 있는 기능이 많음(기본적인 덩치가 큼)Micro 웹 프레임워크소규모 프로젝트에 적합pip install djangopip freezedjango-admin startproject <project name>지정한 이름의 폴더가 생기고,
14.[5주차]django - 20220105

Model models.py 를 통해 데이터 베이스 객체를 생성한다. default : 기본적으로 어떤 값이 들어갈지 정할 수 있다(초기값) max_length : 최대길이, CharField의 경우에는 필수 정의 admin 생성한 model은 admin.py를
15.[6주차] ML basics - 20220112
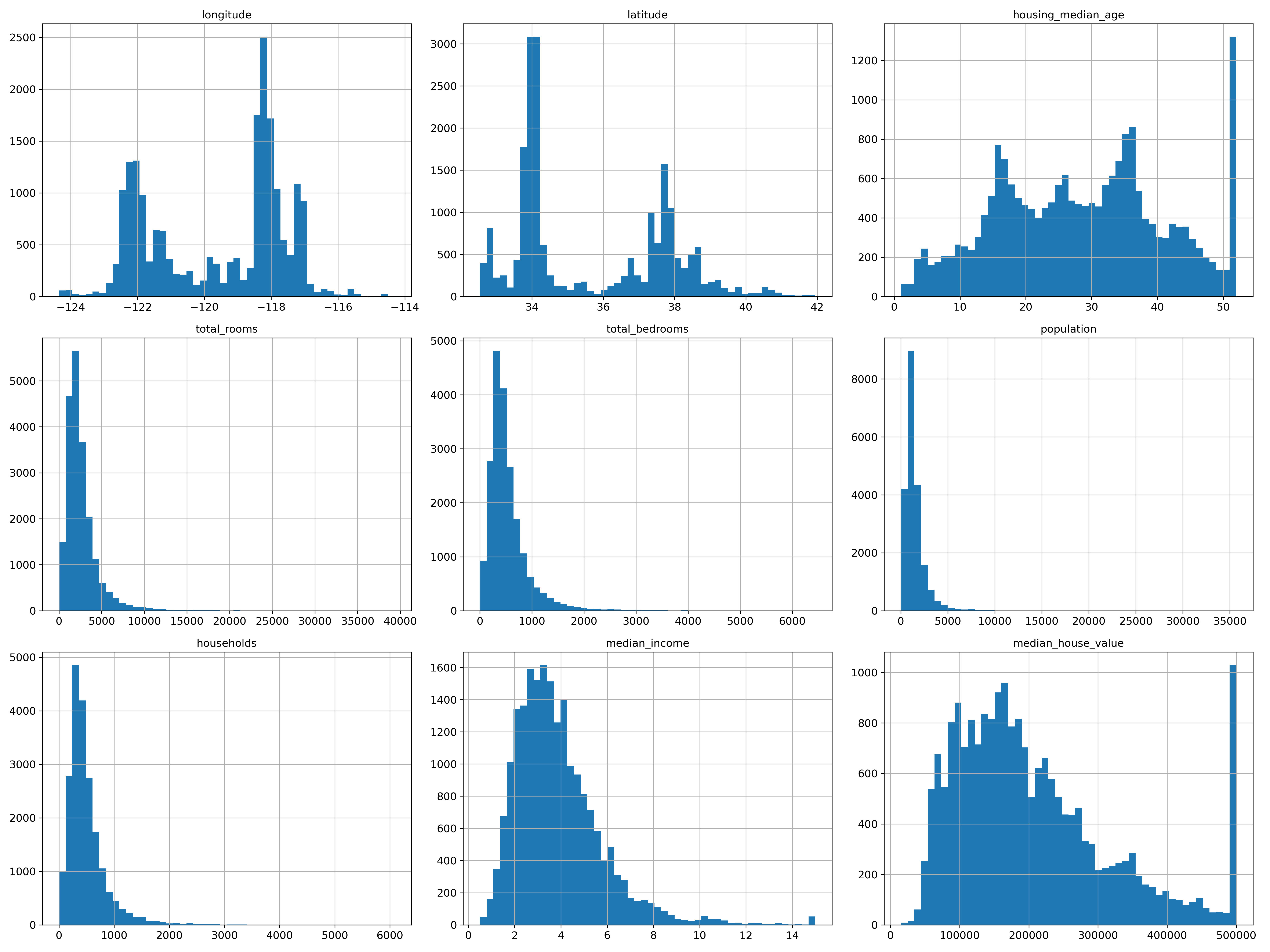
End-to-End ML project example 주택값 예측 문제 데이터 : 문제 정의 지도학습 / 비지도학습 / 강화학습 : label이 있기 때문이다 분류 문제 / 회귀문제 : 배치학습 / 온라인 학습 성능측정지표 선택 평균 제곱근 오차(root
16.[7주차] 프로젝트 준비
추후 마지막 프로젝트를 진행할 팀을 정해야했는데,관심 주제인 GAN을 제시했을 때 안타깝게도 이번 기수에크게 GAN에 관심있는 사람이 없었다.내가 선택할 수 있는 방법은 크게 3가지 였는데,관심도가 떨어지는 다른 주제를 선택해서 팀에 합류한다.1과 병행하고, GAN을
17.[7주차] MNIST GAN example
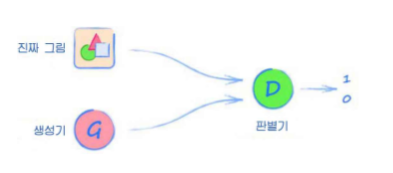
훈련용 데이터테스트 데이터 판별기 성능 확인(진짜 가짜를 구별할 능력이 있는지)생성기 능력 확인특이한 점은 현재 손실값으로 MSE loss를 사용하기 때문에0.5의 제곱, 즉 0.25가 나오는 것이 생성기와 판별기의 밸런스가 맞는 상태라는 것이다.초기에는 판별기가 앞섰
18.[7주차] 얼굴 생성 example
사용 데이터HDF는 계층적 데이터 형식(Hierarchical Data Format)을 뜻한다.용량이 큰 데이터에 효율적으로 접근하기 위한 데이터 형식이다.HDF 데이터로 묶어내는 예제 코드h5py 라이브러리를 이용하여 데이터셋에 접근할 수 있다.또한 이 데이터셋은 딕
19.[7주차] 합성곱 GAN - 20220118
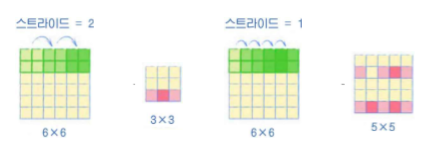
이전 예제에서 활용한 Fully connected layer를 활용했을 때는, 이미지가 불명확하다, 픽셀 사이의 이어짐이 명확하지 않다 메모리 소비량이 크다 는 문제점이 있다. 또한 이미지 도메인에서는 지역화(localized)된 특성이 있다. 예를 들어 눈과
20.[7주차] 얼굴 만들기(CNN GAN)- 20220120
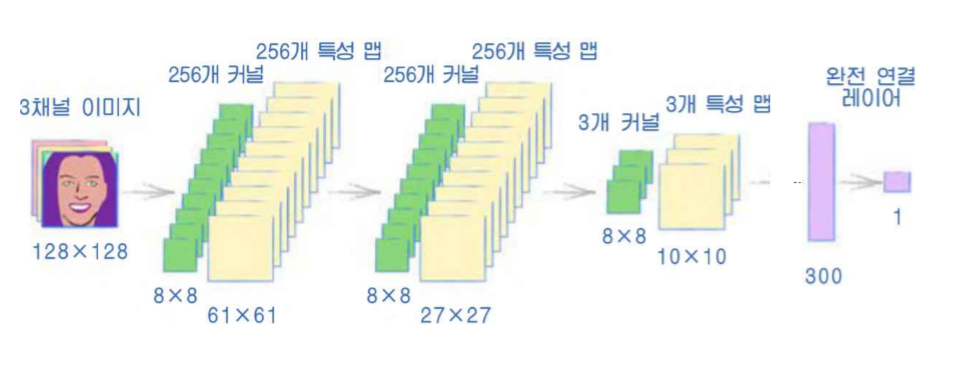
앞서 만들어보았던 GAN에 CNN을 적용할 수 있다이를 위해서는 약간의 수정이 필요하다.이미지를 임의의 사이즈로 crop해주는 일을 해주려고 한다.데이터셋을 구성할 때, crop 시켜주는 부분을 활용하고CNN 커널을 이용하기 위해 4차원 형태(batch_size, ch
21.[7주차] 조건부 GAN - 20220120
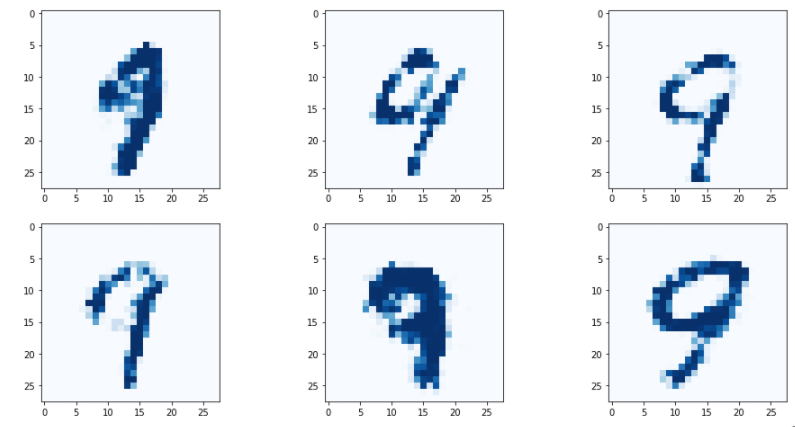
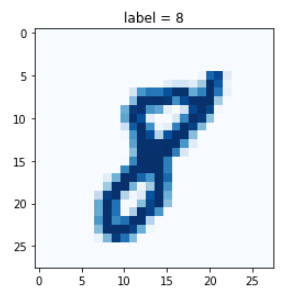
이제까지 만들어온 GAN 출력물들은,임의의 랜덤 시드값에 대해서 결과를 만들어냈다.mnist 예제로 들자면,3을 목표로 3 이미지를 만들어내는 것이 아니라,어떠한 시드 값에 대해 만들어진 이미지가 3 이미지였다.즉, 내가 결과에 대한 의도를 생성기에 전달하지는 않았다.
22.[7주차] 음성 합성 개념 - 20220121
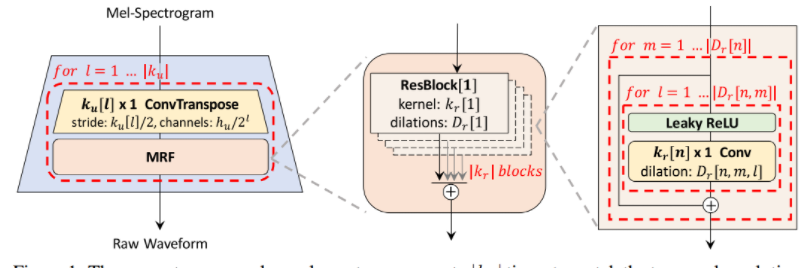
참고 논문 : HifiGAN이제까지 이미지 도메인에서 GAN을 다뤄보았다.이제부터 음성 데이터로 진행해서, 목표까지 도달해보려고 한다.이미지는 기본적으로 2차원의 픽셀로 이루어져있고, RGB 등의 색 채널이 추가되어 3차원으로 이루어져있기도 하다.음성 데이터의 경우에는
23.[10주차] 국뽕봇 프로젝트

서브 프로젝트로 팀을 만들어 국뽕봇 만들기를 수행하고 있다.목표는 유튜브 등에서 볼 수 있는 소위 국뽕채널이 일정한 패턴을 보인다고 가정, 그 패턴을 흉내내는 봇을 만드는 것이다.이를 위한 시작 단계로, 이러한 국뽕 영상의 제목을 흉내내는 봇을 만드려고 하며,일정 수의