이번 시리즈는 고려대학교 산업경영공학부 강필성 교수님의 강의를 참고하였습니다. Business Analytics라는 과목이고, 데이터사이언스 분야의 내용이 잘 정리되어 있어 공부하기 좋을 것 같아 이번 시리즈를 연재하게 되었습니다. 부족한 점이 많겠지만 데이터사이언스 공부를 하는데 도움이 되었으면 합니다.
[Introduction]
Dimensionality Reduction, 차원 축소.
대체 무슨 의미일까?
차원축소라는 용어는 매우 어려워보이지만 쉽게 말하면 독립변수를 줄이는 과정을 의미한다. 데이터 프레임의 관점으로는 열의 개수를 줄인다는 의미이다.
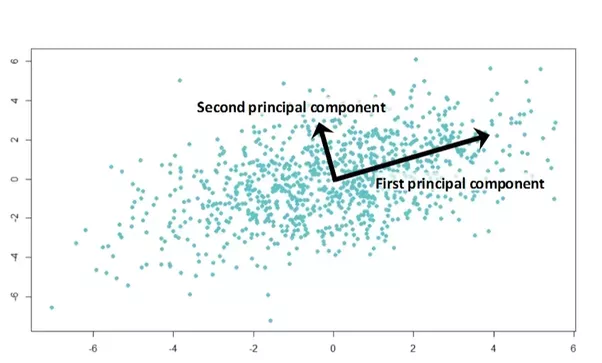
차원축소는 일반적으로 데이터 전처리 과정에서 수행되며 '문서 분류', '추천시스템', '유전 군집화' 등에서 사용된다.
그러면 왜?? 우리는 차원 축소 알고리즘을 사용해야할까?
바로 차원의 저주때문이다.
[차원의 저주(Curse of Dimensionality)]
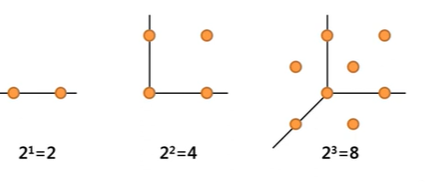
차원의 저주는 변수의 수가 증가할 때 같은 설명력을 계속해서 확보하기 위해서는 데이터의 수가 기하급수적으로 증가해야 한다는 의미이다.
(차원에서 동일한 설명력을 확보하기 위해서는 개의 데이터가 필요하다.)
또한, 오컴의 면도날이라는 원칙에선 "어떤 현상을 설명하기 위한 여러가지 방법이 있다면 가장 간단한 게 가장 최적의 방식"이라고 말한다.
이를 머신러닝의 관점에서 살펴보면,
위와 같이 변수 10개로 가 0.95인 것보다 변수 3개로만 가 0.95인 것이 더 최적의 설명이라는 것을 의미한다.
다음으로, 오리지널 데이터의 차원 수보다 데이터에 내재된 차원의 수가 상대적으로 더 낮은 경우가 있을 수도 있다.
예를 들어 아래와 같은 MNIST Dataset의 경우

차원축소 기법인 PCA나 ISOMAP을 통해 아래와 같이 차원을 줄일 수 있다.
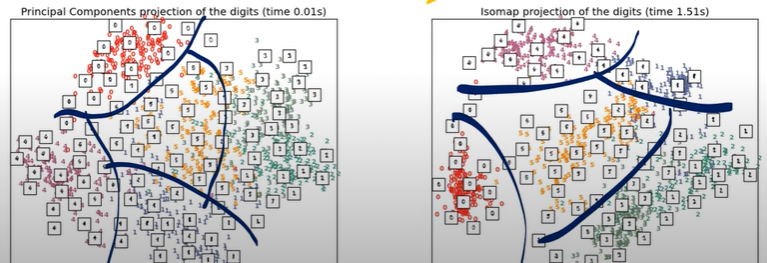
이처럼 차원의 데이터를 5차원으로 줄여도 데이터를 설명하는 데에는 크게 부족함이 없음을 알 수 있다.
고차원의 데이터로 인해 야기되는 문제들은 다음과 같다.
1) 모든 데이터는 로 구성되어 있다. 따라서 Noise()가 포함된 데이터의 경우 과적합으로 모델의 예측 능력을 저해시킬 수 있다.
2) 계산 시간이 증가
3) 동일한 설명력을 확보하기 위한 더 많은 데이터 필요
이 문제를 해결하기 위해선 아래와 같은 방법들이 사용된다.
1) 현업에서는 여전히 도메인을 활용하여 문제를 해결한다.
2) 목적함수에 규제항이 사용된다.
3) 정량적인 변수 감소 방법을 활용한다.
[정리]
이론적으로 모델의 수행능력은 변수의 수가 증가할수록 증가하지만, 이는 모든 변수가 독립적일 때로 한정된다. 따라서 실제로는 모델의 변수들끼리 Dependence가 있으며 Noise가 존재하므로 오히려 변수가 많을수록 모델의 수행능력이 저해된다.
따라서, 우리는 모델이 가장 Best fit이 되는 변수들의 Subset을 찾아보자는 목적으로 차원축소를 수행한다.
결과적으로 변수 사이 상관관계가 감소하고, 사후 과정이 단순화되며(ex. 전처리 공정의 경우 센서의 수를 줄여도 된단 의미), 시각화가 수월해지고 마지막으로 불필요한 변수가 제거된다.
[차원 축소 방법]
1) Supervised VS Unsupervised
- Supervised Dimensionality Reduction
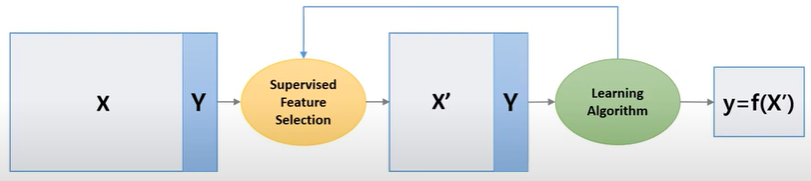
Supervised Dimensionality Reduction는 에서 로 데이터를 축소시킨다고 할 때 Learning Algorithm(선형 회귀 or 로지스틱 회귀) 등을 통해 더 나은 Subset을 찾는 방식으로 일종의 Loop가 존재한다.
- Unsupervised Dimensionality Reduction
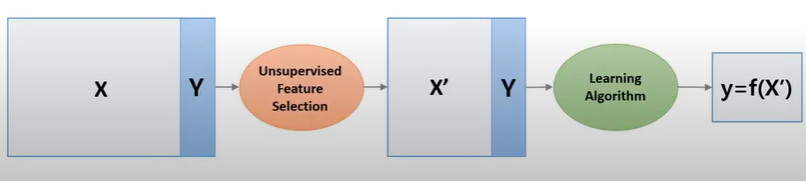
Unsupervised Dimensionality Reduction의 경우 Loop가 없고, 한번에 정량적인 방법을 통해 차원을 축소하는 것을 의미한다.
2) Selection VS Extraction
Variable/feature selection은 기존 데이터 변수 중 Subset을 뽑아내는 방식이다. 반면 Variable/feature Extraction의 경우 새로운 변수를 뽑아내는 것을 의미한다.
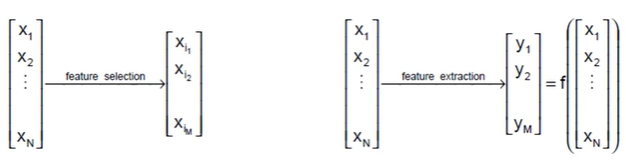
왼쪽처럼 Selection은 변수가 그대로 줄어드는 것이고, 오른쪽인 Extraction은 어떠한 함수 와 같이 원래 들의 조합으로 가 만들어진다.
여기까지 전반적인 차원축소 분야에 대해 살펴보았고, 다음 글에서 자세히 다뤄보도록 하겠습니다. 이번 글에선 차원축소의 의미, 차원의 저주 등을 잘 기억해주시면 좋을 것 같습니다.
