이번 시리즈는 고려대학교 산업경영공학부 강필성 교수님의 강의를 참고하였습니다. Business Analytics라는 과목이고, 데이터사이언스 분야의 내용이 잘 정리되어 있어 공부하기 좋을 것 같아 이번 시리즈를 연재하게 되었습니다. 부족한 점이 많겠지만 데이터사이언스 공부를 하는데 도움이 되었으면 합니다.
[데이터 기반 의사결정]
데이터 기반 의사결정에는 네 가지 유형의 Analytics가 존재한다.
1. Descriptive
- Explain what happened
- BI solution 제시, Dashboard 제작 등의 활동
- Diagnostic
- Explains why it happened
- Predictive
- Forecasts what might happen
- Machine Learning 모델링 등의 활동
- Prescriptive
- Recommends an action based on the forecast
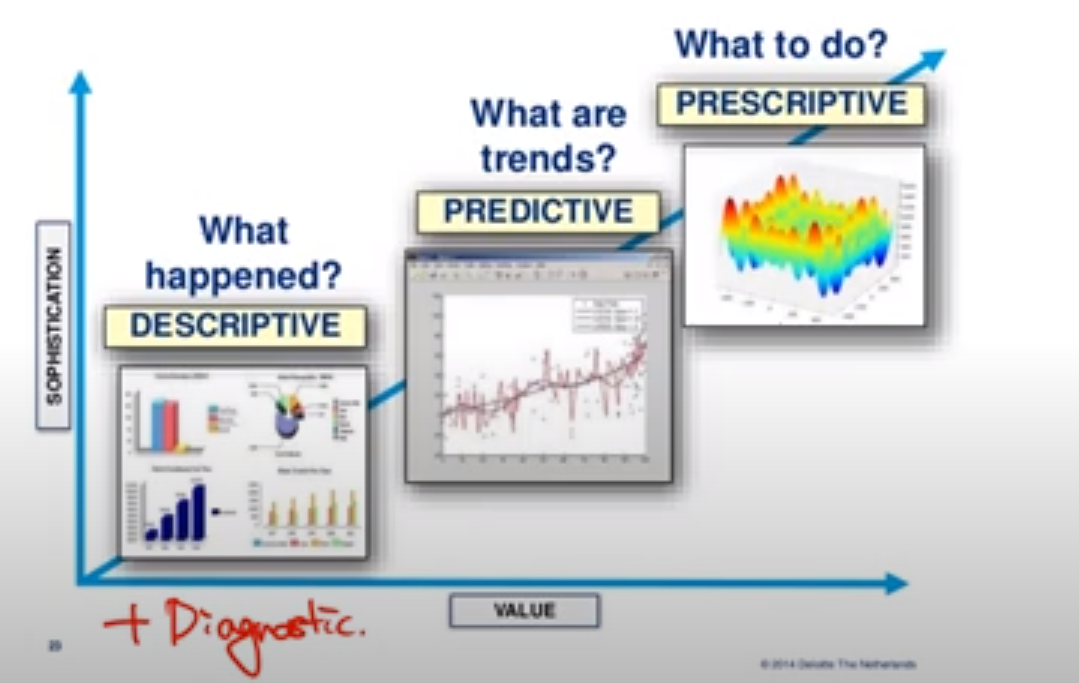
그리고 이와 같은 데이터 기반 의사결정을 위해선 좋은 데이터를 모으는 과정이 꼭 있어야만 한다. 즉, 좋은 데이터가 있어야만 좋은 의사결정을 할 수 있다.
[데이터 과학]
데이터 과학
:다양한 학제간 학문이 융합되어 데이터 기반 의사결정 및 문제해결을 목적으로 하는 학문
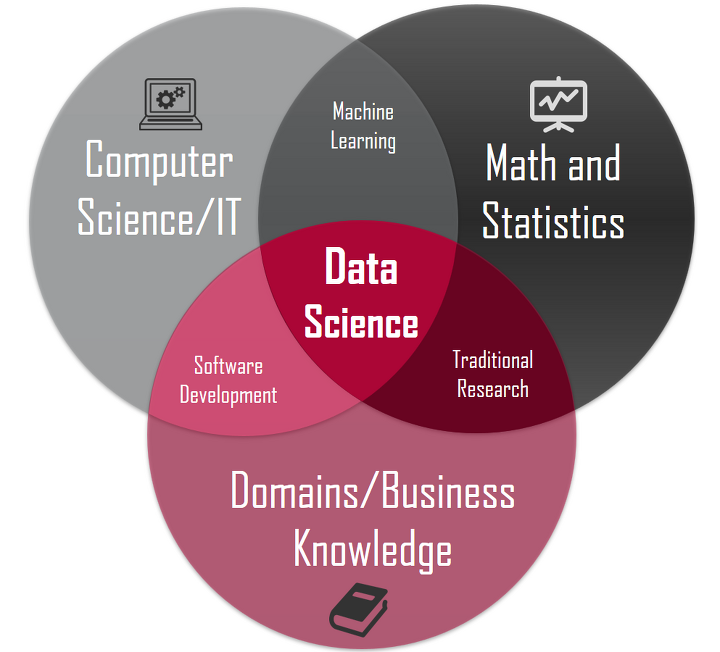
데이터 과학은 귀납법을 통한 분석을 진행하기 때문에 모델링을 할 때 학습한 데이터를 제외하고 새로운 데이터를 만났을 때도, 해당 모델이 좋은 수행능력을 보일 수 있도록 노력해야한다.
과적합 문제, Train-Test data set의 필요성 등과 연관
연역 Vs 귀납
- 연역법: 일반적인 사실이나 원리를 전제로 하여 개별적인 특수한 사실이나 원리를 결론으로 이끌어내는 추리 방법(예: 삼단논법)
- 귀납: 여러가지 관찰된 사실들을 바탕으로 이들의 기저에 깔려있는 일반적인 원리를 추론해내는 방법
이전까지 서양에서 과학이 주로 발달하는데 쓰인 방법은 연역법이였으나, 데이터 과학은 귀납법을 이용하는 학문이다.
[ 데이터 과학의 주요 개념]
1. 빅데이터

빅데이터는 두가지 관점에서의 정의가 존재
- 데이터베이스 규모에 초점을 맞춘 정의
- 일반적인 데이터베이스 SW가 저장, 관리, 분석할 수 있는 범위를 초과하는 규모의 데이터
- 업무 수행에 초점을 맞춘 정의
- 다양한 종류의 대규모 데이터로부터 저렴한 비용으로 가치를 추출하고 초고속 수집, 발굴, 분석을 지원하도록 고안된 차세대 기술 및 아키텍처
빅테이터의 특징, 4V
방대한 양(Volume), 빠른 데이터 생성 및 처리 속도(Velocity), 다양한 형태(Variety) 및 데이터의 내재된 잠재 가치(Value)
다음과 같은 특성을 통해 복잡하고 고도화된 분석 방법론이 아닌 데이터 그 자체로서 가치를 지님.
즉, 데이터가 중요!!
2. 데이터 마이닝
대량의 데이터로부터 의미있는 규칙이나 패턴을 추출하는 일련의 활동

데이터로부터 의미있는 규칙이나 패턴을 추출하는 활동으로, Result가 중요!!
3. 기계학습
특정한 과업(Task)을 달성하기 위해 경험(Experience)이 축적될수록 과업 수행 능력이 향상되는 컴퓨터 프로그램 또는 에이전트를 개발하는 것

특정 목적을 위해 Data(경험)를 이용하여 모델을 개발하는 일련의 과정으로, Methodology가 중요!!
4. 인공지능
환경을 인지하여 보상이 최대화되는 지능적인 행위를 할 수 있는 컴퓨터 소프트웨어
인공지능 Vs 기계학습(Machine Learning) Vs 딥러닝
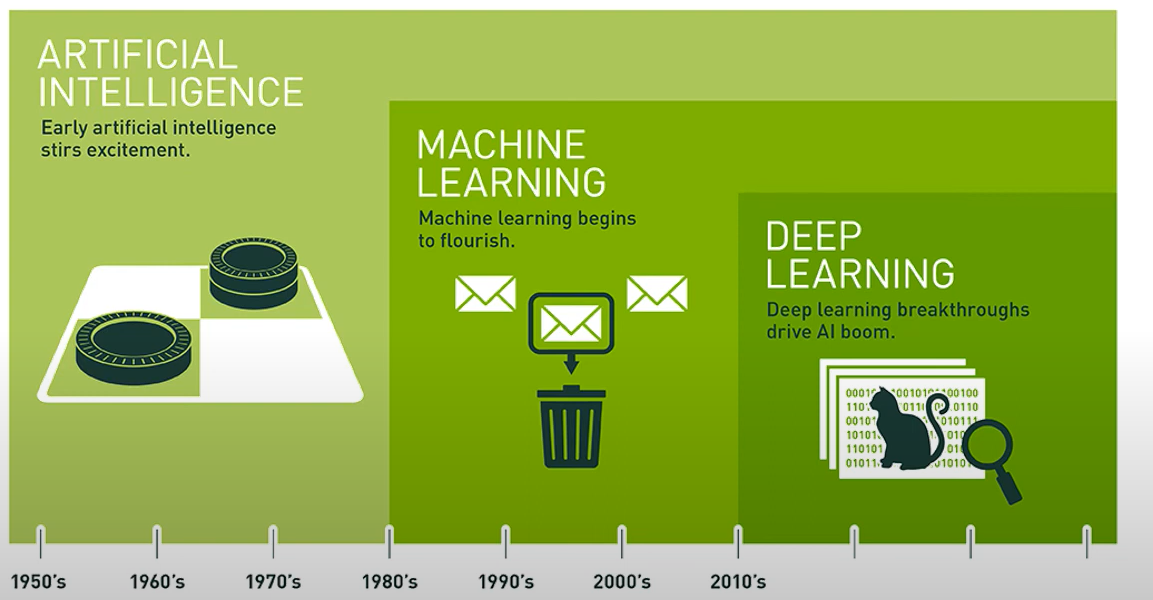
인공지능이 가장 상위의 개념이며, 딥러닝은 기계학습의 한 종류임.
인공지능을 모델링할 때, 연역적인 방법이 아닌 귀납적인 방법을 사용한다면 기계학습에 속하며 딥러닝은 사람이 데이터의 특징을 특정하지 않고도 데이터의 특징을 추출하는 알고리즘이다.
[데이터 기반 문제해결 절차]

1. 문제 정의
흥미로운 문제(매출증대, 비용감소, 공정감소 등 해결될 경우 조직에 도움이 될 것으로 예상되는 문제)를 발굴할 것
ex) 가상계측(APC) 모형개발
2. 분석에 적합한 데이터를 수집하라
데이터의 중요성에 관한 격언들
-
garbage in, garbage out
질 나쁜 데이터를 사용하면 질 나쁜 결과가 도출된다. -
The larger, the better
데이터는 많을수록, 항상 좋다.
만약 필요하다면, 전문가의 지식을 적극 활용하라(특히 정답 데이터를 만들때)
3. 성급한 모델링 이전에 충분히 데이터를 탐색하라
모델링하기 전에 데이터와 친해져야만 한다!
전통적인 통계적 기법을 통해 이상치, 결측치 , 변수간 상관관계 확인, 시계열 데이터라면 주기성은 있는지 등의 기초적인 정보를 하나씩 파악해야 하며, 그 과정에서 데이터 시각화를 사용해야한다.
4. 모델 구축
질문의 속성, 데이터의 특징, 결과의 설명력 포함 유무 등을 고려하여 적합한 분석 알고리즘 선택
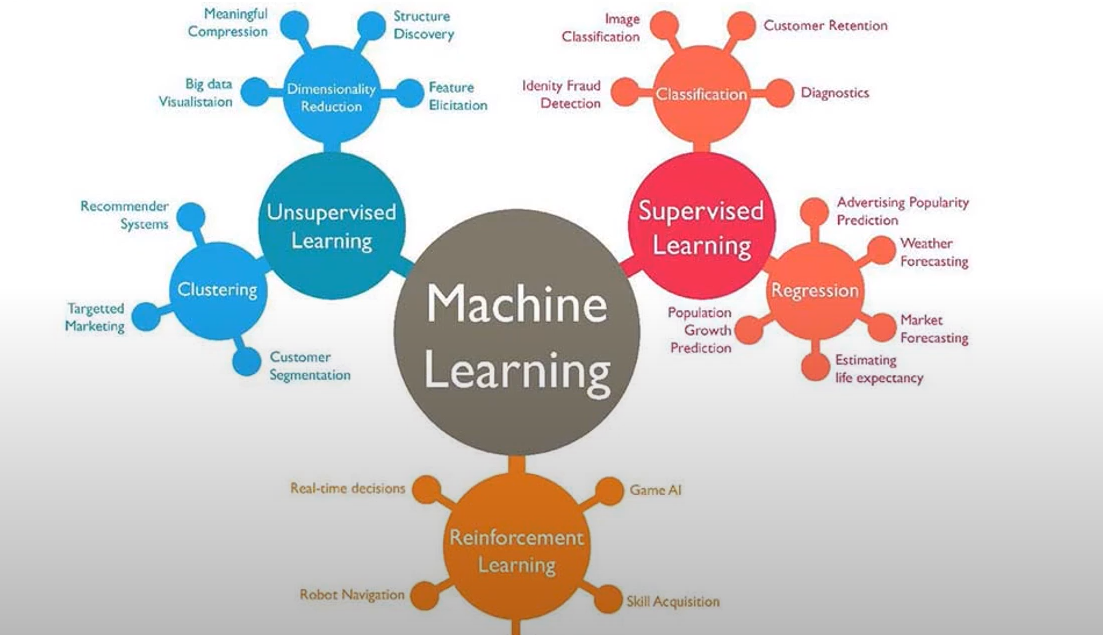
알고리즘을 선택할 때는 다음과 같은 규칙을 생각해볼 수 있다.
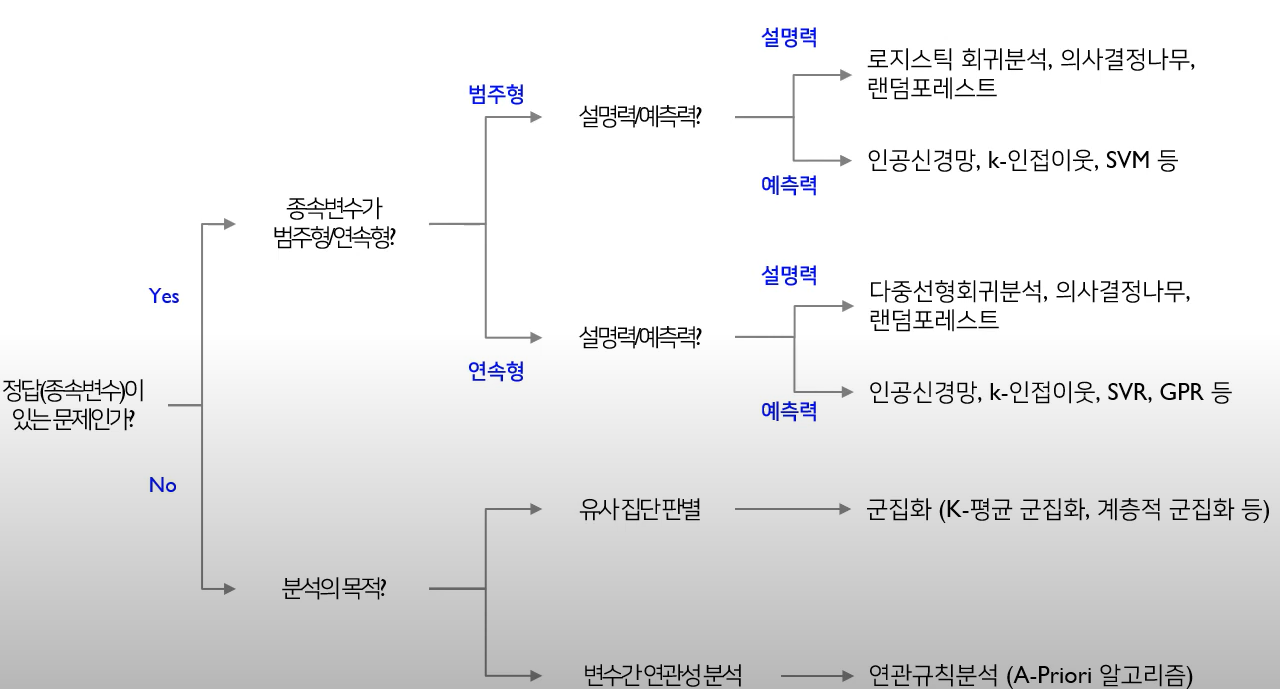
5. 결과 적용
구축된 모델의 시스템 탑재, 시간에 따른 성능 모니터링, 업데이트 주기 결정 등을 통해 결과를 실제로 적용하고 피드백 or 발전시키는 단계이다.
