이번 시리즈는 고려대학교 산업경영공학부 강필성 교수님의 강의를 참고하였습니다. Business Analytics라는 과목이고, 데이터사이언스 분야의 내용이 잘 정리되어 있어 공부하기 좋을 것 같아 이번 시리즈를 연재하게 되었습니다. 부족한 점이 많겠지만 데이터사이언스 공부를 하는데 도움이 되었으면 합니다.
[머신러닝]
다음과 같은 데이터 기반 문제해결 절차 중,
문제정의 데이터확보 데이터탐색 모델링 적용/모니터링
머신러닝은 '모델링'에서 다뤄진다.
머신러닝(Machine Learning)이란 특정한 과업을 달성하기 위해 경험이 축적될수록 과업 수행의 성능이 향상되는 컴퓨터 프로그램 또는 에이전트를 개발하는 것
[머신러닝의 종류]
구분기준 1. TARGET(정답)의 유무에 따른 구분
- Supervised learning(지도학습): 입력과 출력 변수가 정해져있고 둘 사이의 관계를 규명하는 것을 주 목적으로 하는 학습
- Unsupervised learning(비지도학습): 출력변수가 없는 데이터의 특징이나 특성을 파악하는 것을 주 목적으로 하는 학습
구분기준 2. 학습 목적에 따른 구분
- Classification(분류): 지도학습의 일부로, 명목형(categorical) 변수를 예측하는 방법론(예: 생산품의 불량/정상 유무)
- Regression(회귀): 지도학습의 일부로, 연속형(continuous) 변수를 예측하는 방법론(예: 생산품의 수율 0~100%)
- Clustering(군집화): 비지도학습의 일부로, 유사한 개체들의 집단을 판별하는 방법론(예: K-means clustering, 계층적 군집화)
- 이상치 탐지: 목적은 지도학습이나, 방식은 비지도학습을 통해 이뤄지는 문제 유형으로, 대부분이 정상 데이터인 상황에서 매우 낮은 확률로 발생하는 이상치 데이터를 탐지하는 방법론(예: 반도체 공정의 불량 웨이퍼 탐지)
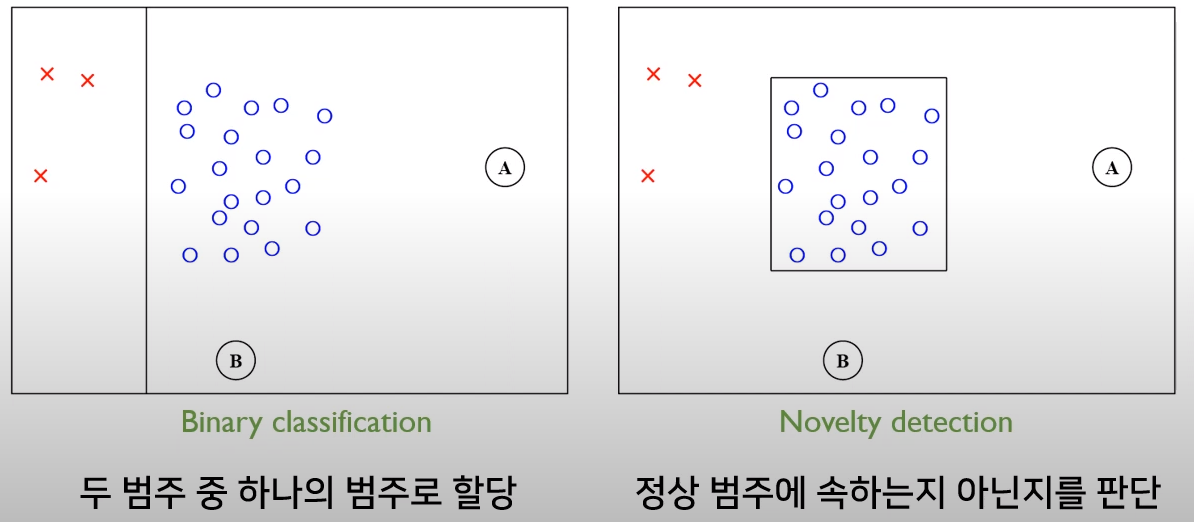
분류와 이상치 탐지 문제의 차이점을 설명하기 위해 교수님의 예를 빌리자면,
분류(Classification)문제가 사과와 바나나의 데이터를 함께 보여주면서 사과와 바나나를 맞추는 문제라면, 이상치 탐지(Anomaly Detection) 알고리즘의 학습 방식은 사과 데이터만 보여주면서 사과(normal)와 사과가 아닌 것(abnormal)을 구분하라는 것이다.
이상치 탐지의 일반화 Vs 특수화
- 일반화: 주어진 데이터로부터 정상 범주의 개념을 확장해나가는 것
- 특수화: 주어진 데이터로부터 정상 범주의 개념을 좁혀가는 것
일반화에 치중할 경우 이상치 데이터 판별이 어렵게 되며, 특수화에 치중할 경우 과적합의 위험(빈번한 false alarm)에 빠질 수 있음
구분기준 3. 사용 데이터에 따른 구분
- 정형 데이터(Structured Data): 기존 방식으로 테이블에 적재된 수치 데이터
- 비정형 데이터(Unstructured Data): 이미지, 음성, 텍스트 등 숫자가 아닌 형태의 정보가 구조화되지 않은 형태로 존재하는 데이터
구분기준 4. 학습 목적과 모델 업데이트 방식에 따른 구분

- Static(정적) Learning은 Short-term, 모델의 결과를 바로 알 수 있고 fully updated, 모델을 업데이트할 때 처음부터 다시 업데이트한다.(like 재건축)
- Incremental Learning은 Short-term, 모델의 결과를 바로 알 수 있고 partially updated, 모델을 업데이트할 때 기존의 모델을 중심으로 일부만 다시 업데이트한다.(like 리모델링)
- Reinforcement Learning은 long-term, 모델의 결과를 모든 과정이 다 끝나야 알 수 있고(like 알파고) Adaptively updated, 모델을 업데이트할 때 계속 적응적으로 업데이트한다.
이번 강의에선 Incremental Learning인 ANN을 제외하곤, 모두 Static Learning에 속한다. 강화학습은 개념이 어렵기 때문에 다루지 않고, 다른 강화학습 강의를 수강하는 것을 추천한다.
