
이번 글은 Text Clustering에서 사용자의 목표를 고려하여 설명을 포함하는 Clustering을 진행하는 방법론에 관한 연구를 가지고 왔습니다.
Clustering은 알지만 Text Clustering이면 단어의 뜻도 고려해야 할 필요가 있을 것이라고 생각했습니다. 그런데 이 논문은 사용자의 목표까지 고려하는 Text clustering 방법론이라길래 어떻게 단어의 뜻을 고려하여 사용자의 목표에 맞게 군집화를 하는지 그 방법이 궁금해서 공부해봤습니다.
서울대학교 산업경영공학과 DSBA 연구실의 이상민님의 영상을 참고하였으며 참고한 링크는 아래에 있습니다.
DSBA 논문 리뷰 영상
해당 연구 논문 링크는 아래에 있습니다.
논문 링크
[Introduction]
기존 Text Clustering 방법론들은 text Sample을 Vector로 Encoding한 후 Clustering 알고리즘을 진행합니다. 하지만 이런 방법론들은 해석가능한 Cluster를 구축하지 못하며 사용자의 목표를 반영하지 못한다는 문제가 있습니다.
그래서 이를 해결하기 위해 설명을 포함하는 연구가 줄곧 있어왔습니다.
해당 논문의 저자인 Ruiqi Zhong이 참여한 논문들을 살펴보면 다음과 같은 관련 연구가 있습니다.
Explaning Text Clusters
- 저자: 전체 Cluster를 완전히 포괄하지 못함.
- 두 분포 간 차이점을 생성하는 방법론을 제안하였으나 사용자의 목표(Goal)를 반영하지 않음.
Explaining Patterns via Language
- 저자: 제안 방법론과 가장 비슷한 논문
- 사용자의 목표(Goal)를 반영하나, 두 분포(Corpus)간 차이점만을 생성
GoalEX(본 논문)
- 사용자의 목표(Goal)를 반영하고 차이점이 아닌 전체 Corpus에서 Clustering 진행 시 Clustering에 적합한 설명(Explanation)을 생성하는 방법론
[Method]
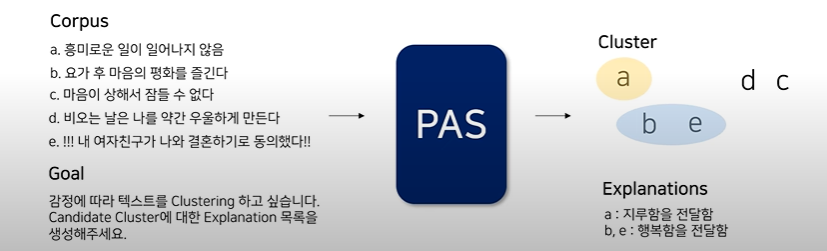
[PAS(Propose-Assign-Select)]
최종 Input-Output
- Input: 텍스트 집합(Corpus) + 목표(Goal)
- output: Corpus 하위 집합(Cluster) + Cluster에 대한 설명(Explanations)
Notation을 먼저 짚고 넘어가면 다음과 같습니다.
Input
X: Corpus (Text 집합)
g: Goal(문자열)
K: Cluster 수 (정수)
Output
: 번째 Cluster
: 번째 Cluster에 대한 Explanation (텍스트)
이때 Output은 3가지 조건을 가져야 합니다.
1) Goal-Related: Explanations이 Goal과 관련이 있어야 한다는 것
사용자의 Goal이 Sentiment를 기반으로 Clustering 하는 것이라면 "긍정적인 Sentiment를 가지고 있음" 이라는 Explanation은 Goal과 관련이 있지만 "스포츠에 관한 것" 이라는 Explanation은 Goal과 관련이 없음
2) Accurate Explanation: 각 Cluster가 Explanations에 의해 정확하게 기술되어야 한다는 것
각 Explanations은 서술어이므로 해당 Cluster의 모든 Sample에 대해 Correct하고 다른 Cluster의 Sample에 대해 Incorrect 해야함.
3) Minimal Overlap and Maximal Coverage: Cluster 간 최소한으로 겹쳐야 하고, Cluster들이 전체 Corpus를 Cover할 수 있어야 한다는 것
이상적으로는 모든 Sample이 각각 하나의 Cluster에 속하는 것이 좋음.
그래서 이러한 Output의 3가지 조건을 해결하기 위한 설계가 바로 PAS이다.
1) Goal-Related -> Propose
2) Accurate Explanation -> Assign
3) Minimal Overlap and Maximal Coverage -> Select
그럼 각 단계에서 어떠한 과정이 이뤄지길래 3가지 조건을 성립시킬 수 있는지 살펴보겠습니다.
[Propose]
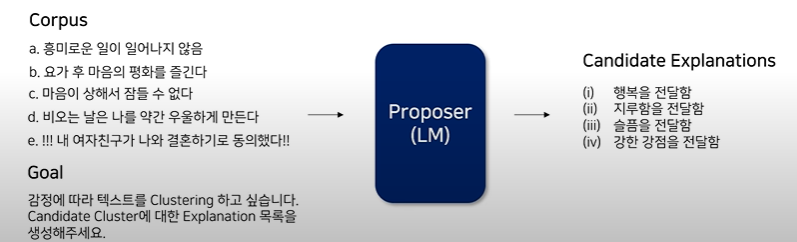
목표: Proposer(LM)에 Corpus를 부여하여 Goal에 관련된 Explanations를 생성
Input: Corpus + Goal
Output: Candidate Explanations
과정: LM에게 'In-context Clustering' 형태의 Prompt를 부여

Goal에 따라 Text를 Clusterinf 하기 위한 Category를 만들라는 Instruction + Category Example, Goal과 Explanation 예시, Corpus 부여 + Goal 설명 + 생성할 Explanation 개수 지정, 출력문 제어 등이 해당 과정이다.
이때 Prompt의 길이 제한으로 전체 Corpus를 반영할 수 없기에 다수의 Prompt를 구성해서 개의 Explanations을 얻을 때까지 반복해야한다.
[Assign]
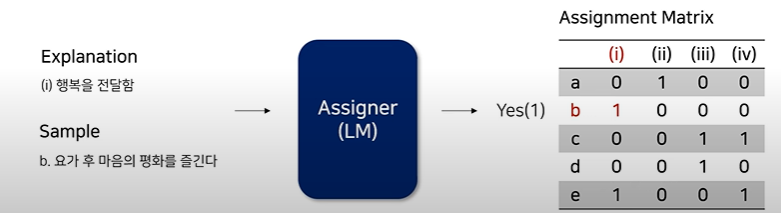
목표: 각 Sample에 적합한 Explanation 할당
Input: Explanation + Sample
Output: Assignment Matrix (Sample[행]에 따라 Explanation[열]이 지정)
과정: 각 Sample이 각 Explanation에 적합한지 여부를 결정하기 위해 언어 모델에게 Text를주고 Explanation에 적합한지 Prompt를 구성

[Select]
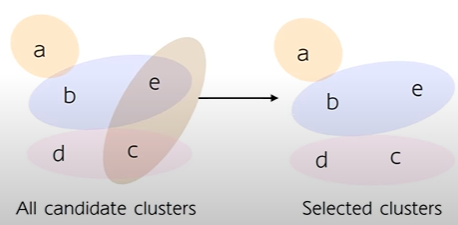
목표: Cluster 간 중복 최소화, 전체 Corpus Coverage 최대화
과정: 각 Sample이 대략 하나의 Cluster에 속하도록 개의 candidate clusters에서 K개의 Clusters를 선택하는 것
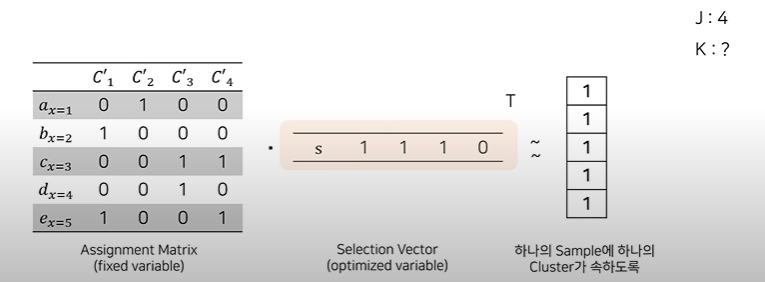
Assignment Matrix를 각 Sample이 대략 하나의 Cluster에 속하도록 근사화시키는 Selection Vector를 찾고자 함.
이때 목표 군집 개수인 개를 맞추기 위해 개의 군집을 줄이기 위해 단위행렬 1의 길이를 조절해준다.
또한 모든 에 대해 가 1이 되는게 이상적이므로 라는 loss function을 구성해준다.
이때 는 Penalty를 부여하는 하이퍼파라미터
따라서 이 loss function으로 Selection Vector를 업데이트해나가는 것이다.
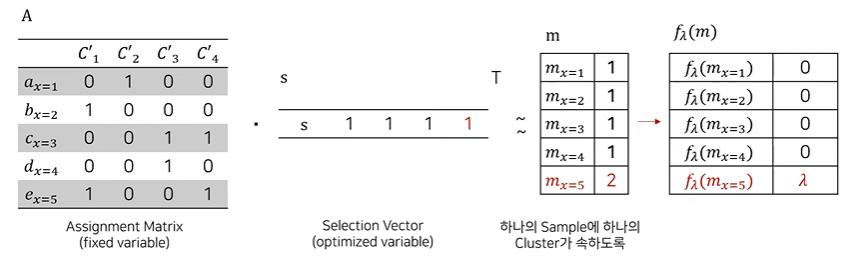
가 1보다 작으면 Sample이 Cluster에 속하지 않는다는 것을 의미하며 1일 때는 이상적인 상황 1보다 클 때는 여러개의 cluster에 속함을 의미한다. 그러므로 miss이면 를 높이기 위해서, overlap이면 를 낮추기위해 loss function을 사용한다.
이때 Loss인 이 열벡터니까 Scalar로 변환해주기 위해 을 적용한다.

하지만 실수 가 곱해지게 되면 loss가 실수가 되는데 Cluster에 속한 여부는 1 or 0으로 판단하기에 loss update를 적용하는 것이 어렵기에 정수 값만을 가지도록 loss function 를 a로 치환하여 계산한다.
그래서 를 a로 치환한 후에 최종적으로 Loss function을 구성한다.
최종적으로 찾은 Selection vector를 통해 J개의 Candidate Clusters에서 K개의 clusters를 선택하게 된다.
[PAS 이후 단계]
Multiple Iteration: 전체 Corpus를 커버하기 위해 5번의 반복을 진행하고,
Commit to a Single Cluster: 필요할 때 각 Sample을 단일 Cluster에 Commit하는 보조 절차를 진행한다.
Multiple Iteration
- Assigner의 Context 길이가 전체 Corpus를 포함할 수 없어 PAS를 5번 반복 진행
- 이전 반복 결과들에서 Explanation이 Assign 되지 않는 Sample을 바탕으로 새로운 Explanation을 생성하는 형태
Commit to a Single Cluster
- PAS가 끝날 때, 일부 Sample은 여러 Explanation에 할당될 수 있음
- 그러나 사용자나 벤치마크는 각 Sample를 가장 적합한 하나의 Cluster에 Commit하도록 요구할 수 있음 LM을 활용해서 각 Sample을 단일 Cluster에 Commit하는 절차를 추가

