현재 프로젝트 성능을 개선하기 위해 인덱싱, 캐싱, 로드 밸런싱을 적용했었습니다.
여기서 데이터베이스를 다중화하여 읽기 성능을 개선할 수 있는 방법인 데이터베이스 리플리케이션에 대해서 알아보고 적용해보겠습니다.
데이터 베이스 리플리케이션
리플리케이션(Replication)이란??
리플리케이션(Replication) 이란 한 서버에서 다른 서버로 데이터를 동기화 하는 것을 의미합니다.
원본 데이터를 가지는 서버는 Source 서버, 복제된 데이터를 가지는 서버를 Replica 서버라고 합니다.
예전에는 Master 서버, Slave 서버로 많이 불려왔지만, 최근에는 윤리적인 문제로 이러한 명칭을 잘 쓰지 않는 추세입니다.
리플리케이션을 적용하면 원본 서버와 여러 개의 복제 서버로 구성할 수 있는데, 여기서 여러 장점이 생깁니다.
리플리케이션 왜 사용할까??
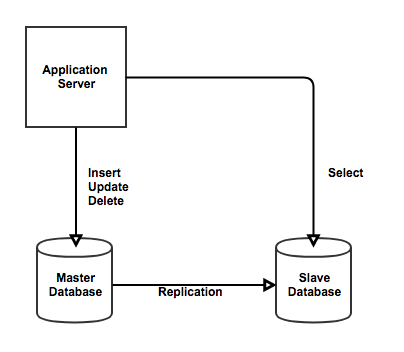
읽기 성능 향상
대표적으로 리플리케이션을 적용하면 읽기 성능이 향상됩니다.
Replica 서버를 생성하여 Read 쿼리를 처리하고 나머지 CUD(Create, Update, Delete)작업은 Source 서버에서 처리합니다.
즉, 여러 대의 복제 서버를 통해서 스케일 아웃을 했기 때문에 Read 작업을 분산하여 읽기 성능을 향상할 수 있습니다.
대부분의 서비스는 Read 작업이 대부분이기 때문에 리플리케이션으로 읽기 성능을 향상할 수 있습니다.
데이터 백업
리플리케이션은 데이터를 동기화하는 작업이기 때문에 백업에 활용됩니다.
데이터베이스가 애플리케이션의 요청을 처리하며, 백업 과정을 동시에 수행할 수 있습니다.
Replica 서버에서 데이터 백업을 실행하여 Source 서버에서 백업 시 발생하는 문제를 해결할 수 있습니다.
데이터 분석
분석용 쿼리는 대량의 데이터를 조회하고 집계 연산을 사용하기 때문에 쿼리 자체가 무거운 경우가 많습니다.
그래서 복제 서버에서 분석용 쿼리를 실행하다면 실 서비스에 영향을 주지 않게 되어 안정적으로 서버를 운영할 수 있습니다.
데이터의 지리적 분산
서비스가 전 세계에서 운영되고 있는 상황에서 한 지역에만 데이터베이스 서버가 존재한다면 지리적으로 멀리 떨어져있는 지역은 느린 서비스를 경험할 수 밖에 없습니다.
이러한 문제를 해결하는 방법은 각 국가별로 복제 서버를 두고 리플리케이션을 통해 동기화하여 지리적 이슈를 해결할 수 있습니다.
MySQL의 리플리케이션 구조
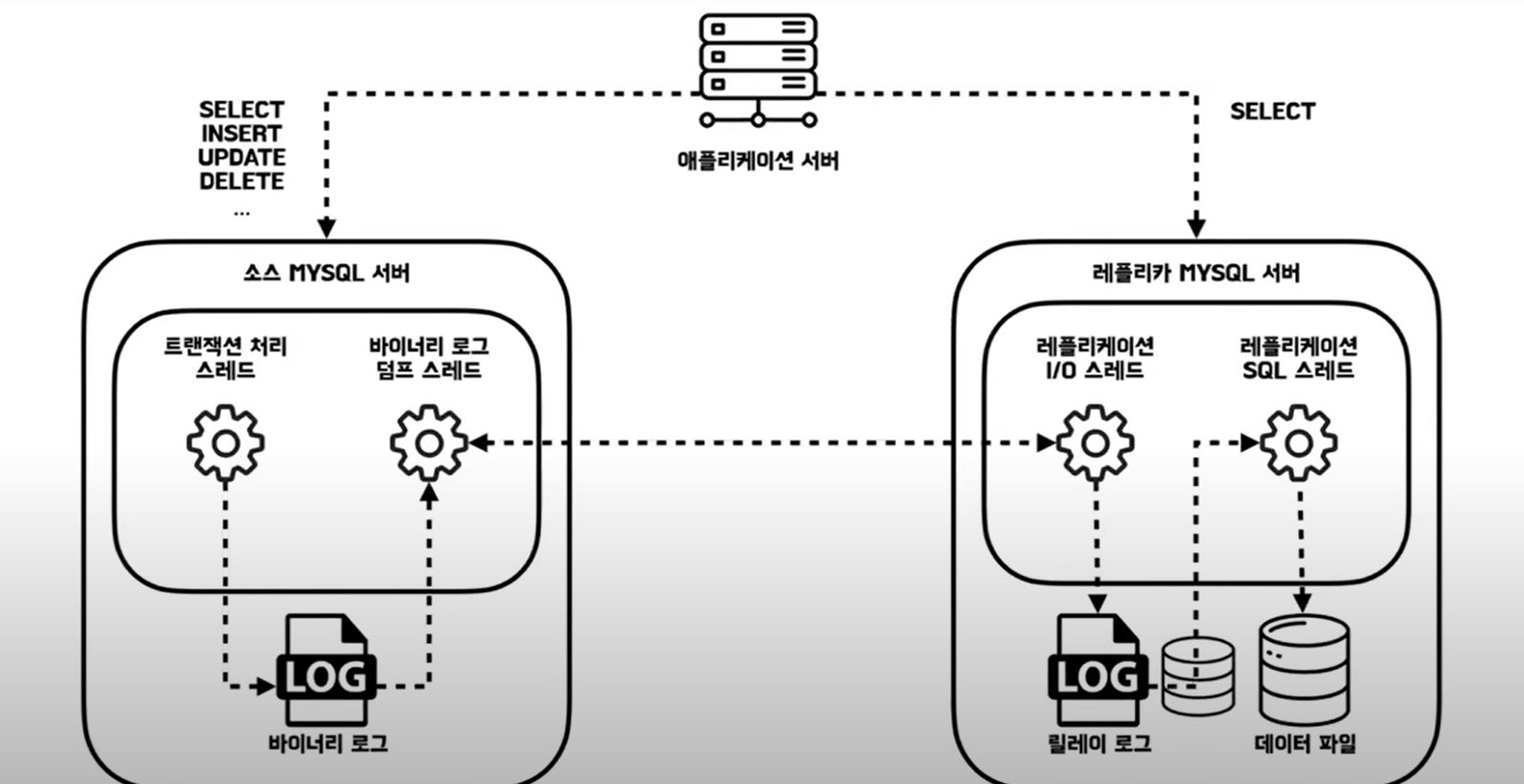
바이너리 로그 (binlog)
MySQL에서 발생되는 모든 변경사항(이벤트)는 바이너리 로그 파일에 순차적으로 기록됩니다.
바이너리 로그에는 변경 내역과 테이블 구조 변경, 계정 권한 변경 등의 정보가 저장됩니다.
리플리케이션은 Replica 서버가 Source 서버의 바이너리 로그를 읽어와 Replica 서버에 순차적으로 적용하는 과정으로 이루어집니다.
바이너리 로그 덤프 스레드 (Binary Log Dump Thread)
바이너리 로그 덤프 스레드는 리플리케이션 작업이 Replica 서버로부터 요청되었을 때, Source 서버로부터 생성됩니다.
바이너리 로그 덤프 스레드는 바이너리 로그의 이벤트를 읽어 Replica 서버로 전송하는 역할을 수행합니다.
이벤트를 읽을 때, 바이너리 로그 파일에 대해 잠금을 수행하고, 읽기 작업이 끝나면 잠금을 즉시 해제합니다.
리플리케이션 I/O 스레드 (Replication I/O Thread)
Replica 서버에서 리플리케이션 작업이 시작되면, 리플리케이션 I/O 스레드를 생성하며, Source 서버로 부터 바이너리 로그를 가져옵니다.
가져온 이벤트들은 Replica 서버의 릴레이 로그(Relay Log)에 저장됩니다. 릴레이 로그는 Source 서버로 부터 가져온 바이너리 로그 이벤트를 Replica 서버에 파일로 저장한 것 입니다.
리플리케이션 I/O 스레드는 오직 바이너리 로그를 읽고(Input) 릴레이 로그를 쓰는 작업(Output)만을 수행합니다.
리플리케이션 SQL 스레드 (Replication SQL Thread)
리플리케이션 I/O 스레드가 릴레이 로그를 작성하면, 리플리케이션 SQL 스레드는 릴레이 로그에 기록된 이벤트를 읽고 실행하는 역할을 수행합니다.
주의해야 할 점
비동기 복제
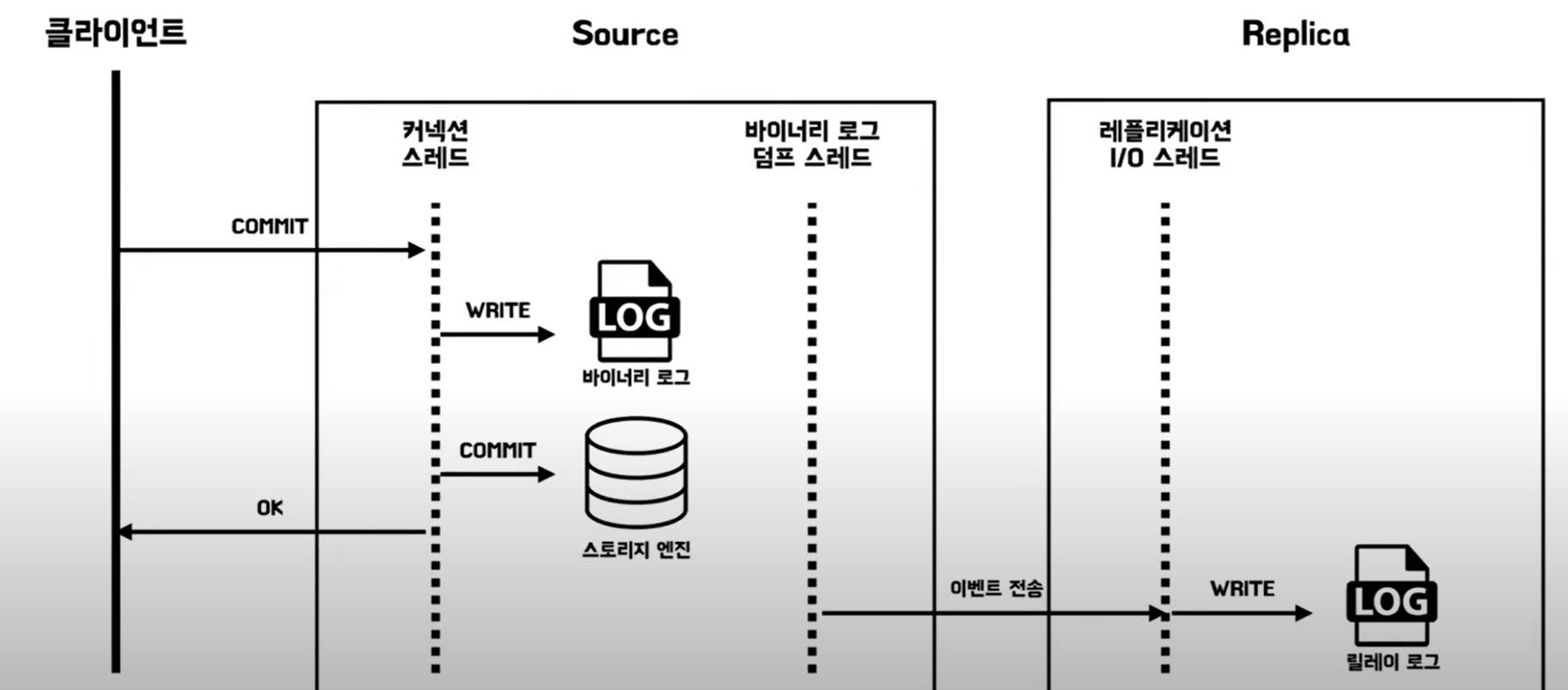
복제 동기화 방식 중에서 비동기 복제 방식은 Source 서버가 Replica 서버에서 변경 이벤트가 정상적으로 전달되었는지 확인하지 않습니다.
그래서 Source 서버에 장애가 발생한다면 Source 서버에서 최근까지 적용된 트랜잭션이 Replica 서버로 전송되지 않을 수 있습니다.
반동기 복제
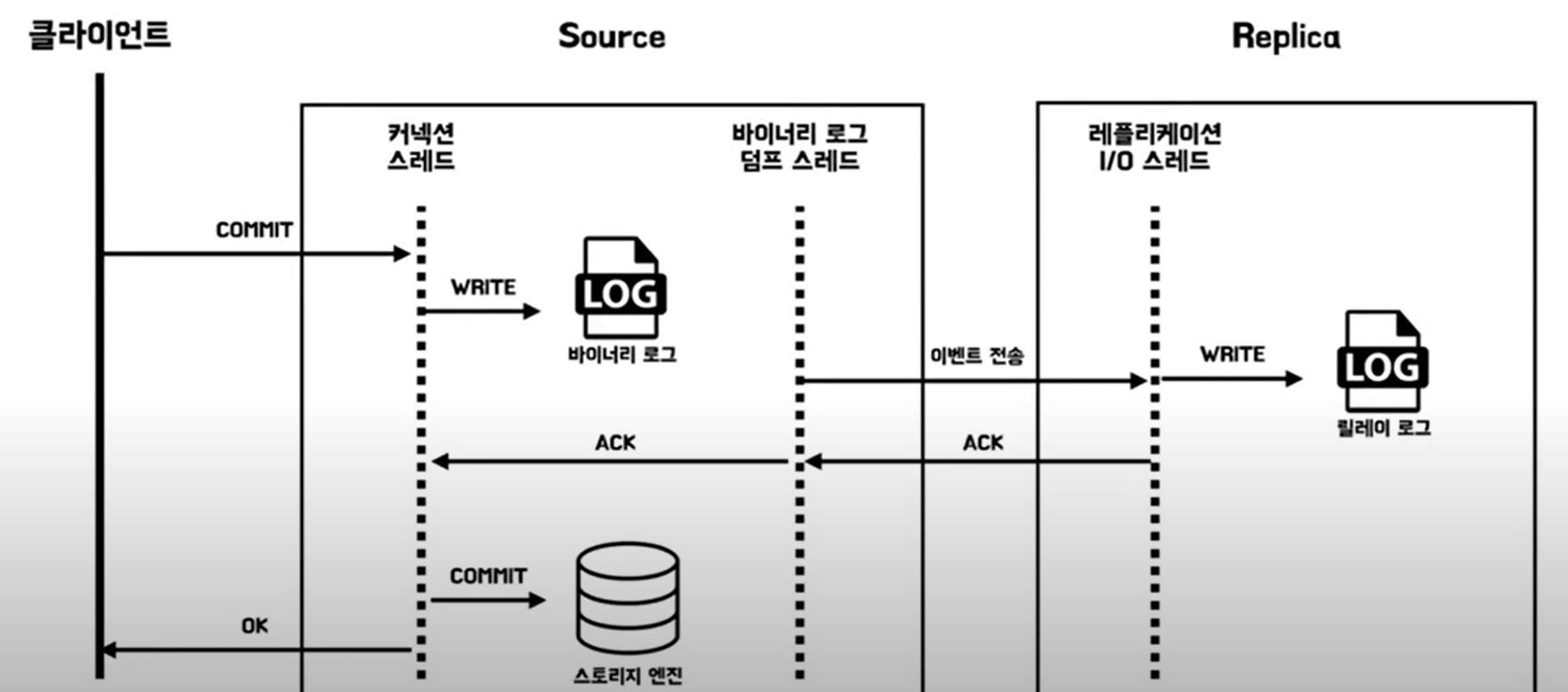
반동기 복제방식은 Replica 서버가 Source 서버로부터 전달받은 변경 이벤트를 릴레이 로그에 기록한 후, 응답을 보내면 그때 트랜잭션을 완전히 커밋하는 방식입니다.
하지만 전송이 보장된 것이지 적용이 보장된 것은 아니고 서버의 응답을 기다리기 때문에 비동기 방식보다 트랜잭션 처리가 길어질 수 있습니다.
복제 서버 생성
기존 프로젝트에서 RDS를 사용하고 있고 RDS에서 읽기 전용 복제본을 생성할 수 있기 때문에 RDS를 이용해서 복제 서버를 생성하겠습니다.

이렇게 RDS를 사용하면 MySQL 서버에서 추가적인 설정을 하지 않아도 복제본을 생성할 수 있습니다.
하나의 Source 서버에 하나의 Replica 서버를 두어 싱글 레플리카 복제 형태를 구성했습니다.
yml
spring:
datasource:
write:
jdbc-url: jdbc:mysql://{Source 서버 엔드 포인트}
driver-class-name: com.mysql.cj.jdbc.Driver
username: name
password: 1234
read:
jdbc-url: jdbc:mysql:{Replica 서버 엔드 포인트}
driver-class-name: com.mysql.cj.jdbc.Driver
username: name
password: 1234DataSource에 대한 yml 설정입니다. write에는 Source 서버에 대한 정보를 입력하고 read는 Replica 서버에 대한 정보를 입력합니다.
DataSourceConfig.java
@Configuration
public class DataSourceConfig {
private static final String SOURCE_SERVER = "SOURCE";
private static final String REPLICA_SERVER = "REPLICA";
@Bean
@Qualifier(SOURCE_SERVER)
@ConfigurationProperties(prefix = "spring.datasource.write")
public DataSource writeDataSource() {
return DataSourceBuilder.create()
.build();
}
@Bean
@Qualifier(REPLICA_SERVER)
@ConfigurationProperties(prefix = "spring.datasource.read")
public DataSource readDataSource() {
return DataSourceBuilder.create()
.build();
}
@Bean
public DataSource routeDataSource(
@Qualifier(SOURCE_SERVER) DataSource sourceDataSource,
@Qualifier(REPLICA_SERVER) DataSource replicaDataSource
) {
DataSourceRouter dataSourceRouter = new DataSourceRouter();
HashMap<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put("write", sourceDataSource);
dataSourceMap.put("read", replicaDataSource);
dataSourceRouter.setTargetDataSources(dataSourceMap);
dataSourceRouter.setDefaultTargetDataSource(sourceDataSource);
return dataSourceRouter;
}
@Bean
@Primary
public DataSource dataSource() {
DataSource determinedDataSource = routeDataSource(writeDataSource(), readDataSource());
return new LazyConnectionDataSourceProxy(determinedDataSource);
}
}DataSource 설정 클래스 입니다.
@Qualifier를 통해 특정 빈을 식별할 수 있도록 설정했습니다.
@ConfigurationProperties를 통해서 yml 파일에 등록된 해당 설정을 읽어와 DataSource에 적용합니다.
writeDataSource() 와 readDataSource()는 각각 쓰기 작업과 읽기 작업을 처리하는 데이터 소스를 생성합니다.
routeDataSource()에서는 @Qualifier를 통해 정의한 SOURCE_SERVER와 REPLICA_SERVER 데이터 소스를 주입받습니다.
그리고 생성한 dataSourceRouter에 각각 쓰기 및 읽기 데이터 소스를 매핑한 맵을 설정하고 기본 데이터를 쓰기 데이터 소스로 설정합니다.
dataSource()는 @Primary를 통해 여러 개의 빈이 같은 타입일 때 기본적으로 사용될 빈으로 지정합니다.
그리고 위에서 설정한 writeDataSource()와 readDataSource()를 routeDataSource()의 파라미터로 사용합니다. 그렇게 생성한 routeDataSource는 LazyConnectionDataSourceProxy로 래핑하여 지연된 연결을 사용합니다.
DataSource 설정 클래스로 애플리케이션의 읽기와 쓰기 작업을 별도의 데이터 소스로 분리할 수 있습니다.
DataSourceRouter.java
public class DataSourceRouter extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
return readOnly ? "read" : "write";
}
}AbstractRoutingDataSource 클래스는 실제 데이터 소스를 설정하고, 특정 로직에 따라 적절한 데이터 소스를 선택할 수 있도록 지원합니다.
determineCurrentLookupKey()를 구현하여 데이터 소스를 동적으로 라우팅하는 기능을 정의해야 합니다.
TransactionSynchronizationManager.isCurrentTransactionReadOnly() 메서드는 현재 트랜잭션이 읽기 전용이면 true, 아니면 false를 반환합니다.
Service 계층에서 사용한 @Transactional(readOnly = true) 를 통해서 읽기 작업과 쓰기 작업을 나누겠습니다.
@Transactional(readOnly = true) readOnly 설정이 true로 되어있기 때문에 읽기 작업을 수행하여 Replica 서버에 요청을 보내게 됩니다.
CRD 작업을 했을 때, Source 서버에 요청하는 로그

Read 작업을 했을 때, Replica 서버에 요청하는 로그

RDS에서 설정한 DB 식별자를 통해 Source 서버와 Replica 서버에 요청이 잘 전송된 것을 확인할 수 있습니다.
