문제 상황
실제 서비스 운영 중 겪었던 데이터베이스 성능 문제에 대해 공유하고자 합니다.
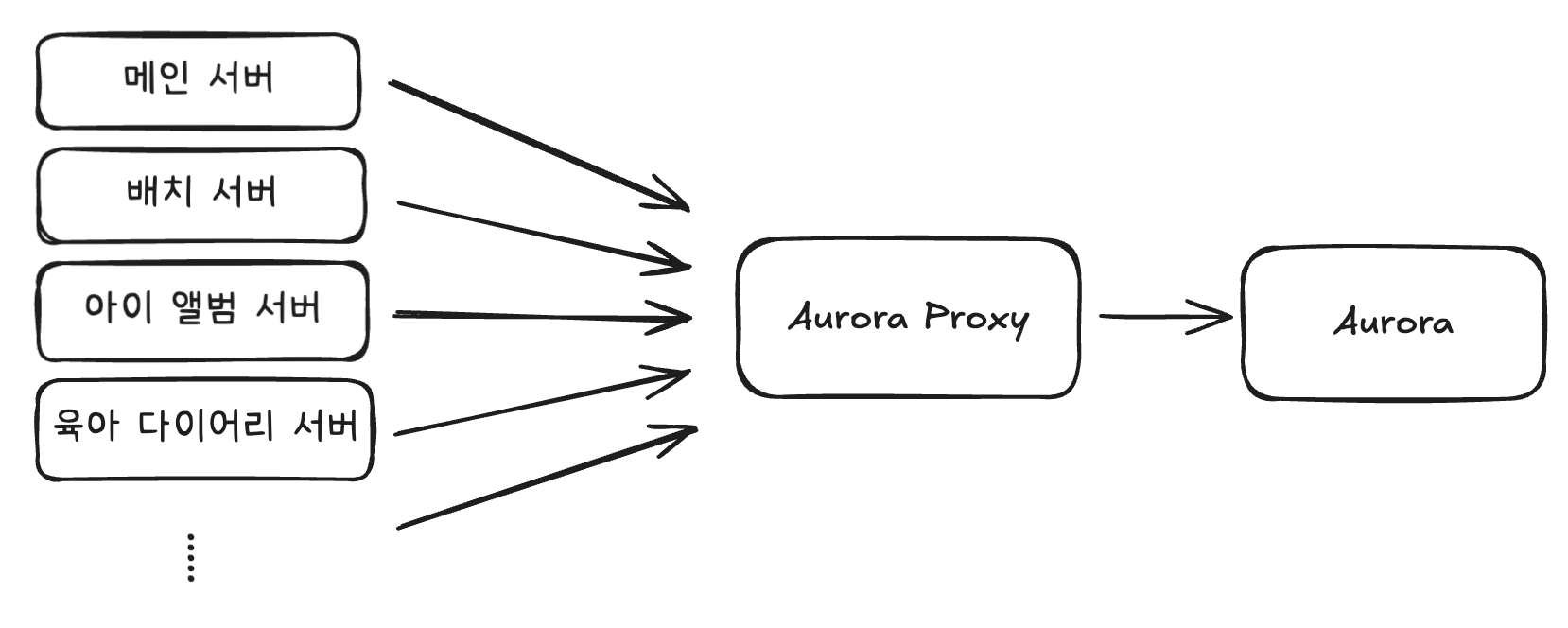
문제가 된 회사 서비스 아키텍처는 여러 개의 애플리케이션 서버가 하나의 데이터베이스를 사용하는 구조였습니다.
초기에는 이러한 구조가 문제가 없었지만 서비스를 이용하는 유저가 늘어나면서 문제가 발생했습니다.


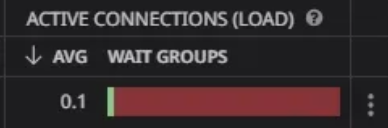
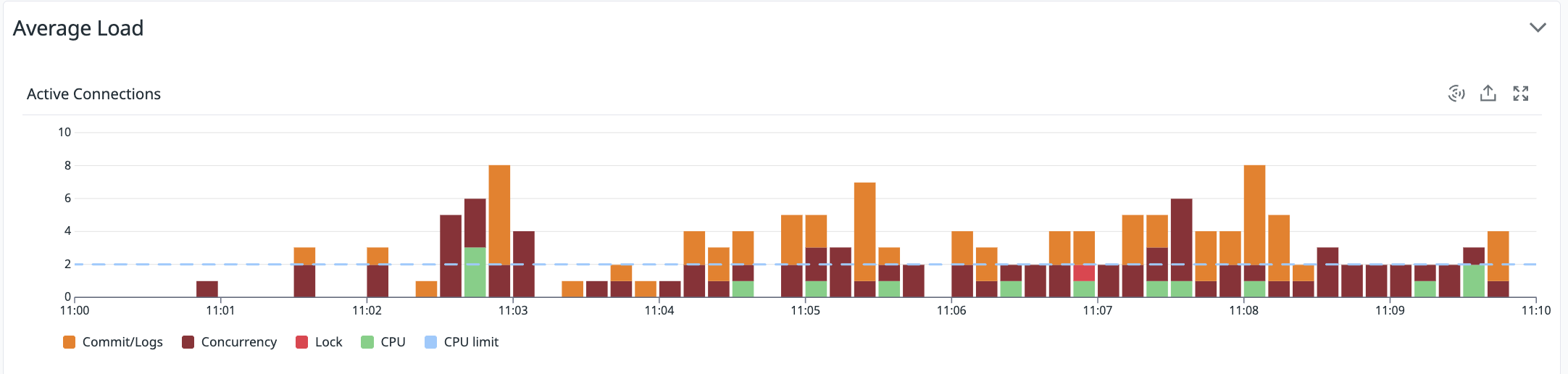
해당 이미지는 Datadog의 Database Monitoring에서 제공하는 Active Connections의 현황과 대기 원인입니다.
여기서 알 수 있는 문제점이 있습니다.
- Active Connections이 대부분 Concurrency(동시성) 대기와 wait/io/table/sql/handler 로 사용됩니다.
- Concurrency 대기로 인해 DB 인스턴스에서 제공하는 권장 Active Connections 개수를 초과하고 있습니다.
두 가지 문제점은 어떠한 결과를 초래할까요?
첫 번째, Concurrency 대기는 응답 시간 지연을 발생시킵니다.
빈번하게 호출되는 SELECT 쿼리의 Active Connections를 확인했을 때, 문제점이 드러났습니다. 위 이미지의 빨간색으로 표시괸 부분이 Concurrency Wait 비율을 나타내는데, 전체 대기 시간의 대부분을 차지하고 있는 것을 확인할 수 있습니다.
CPU 사용률 자체는 낮은 편임에도 응답 시간 지연이 발생하고 있었습니다. 이는 하드웨어 리소스 부족이 아닌 동시성 제어 메커니즘으로 인한 성능 저하임을 알 수 있습니다. 즉, 여러 연결이 동일한 리소스에 접근하려고 할 때 발생하는 대기 시간이 전체 성능 병목의 주요 원인으로 되고 있는 상황입니다.
단일 Aurora 인스턴스에서 모든 읽기 요청을 처리하기 때문에 쿼리들이 서로 대기하며 연쇄적인 지연을 발생시키고 있는 상황입니다.
두 번째, 응답 지연으로 인해 Active Connection 개수가 권장 개수를 초과하면서 DB 리소스 경합을 악화시키고 DB CPU 사용률을 폭증시킵니다. 실제로 쇼핑몰 할인 이벤트 알림을 전송했을 때 DB CPU 사용률이 100%까지 치솟는 문제가 발생했습니다. 특히 많은 사용자가 앱 접속으로 인증 처리를 위한 UPDATE 쿼리 요청이 급증하여 Concurrency 대기 현상이 악화되고, 이로 인한 악순환으로 응답 지연 문제가 더욱 심화되었습니다.
세 번째, DB CPU 사용률 폭증으로 인한 DB 인스턴스 마비로 연결된 모든 서비스를 중단시킵니다. 쇼핑몰 할인 이벤트 알림 전송으로 인해 DB CPU가 100%에 도달하면서 새로운 요청 처리가 불가능해졌고, 결국 전체 서비스가 마비되었습니다.
가장 심각한 문제는 단일 장애점(SPOF) 구조였습니다. 하나의 Aurora 인스턴스에 모든 Read/Write 요청이 집중되어 있어, 해당 인스턴스에 문제가 생기자 전체 서비스가 마비되었습니다.
결과적으로 서비스가 일시적으로 중단되면서 고객들의 불만이 폭증했고, 이에 따른 CS 문의가 급격히 증가하여 비즈니스 운영에 직접적인 타격을 입었습니다. 해당 문제를 통해 단일 DB 인스턴스 구조의 위험성과 확장 가능한 아키텍처의 필요성을 느끼게 되었습니다.
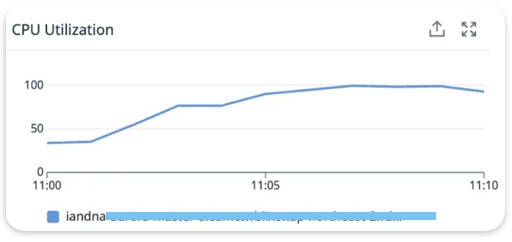
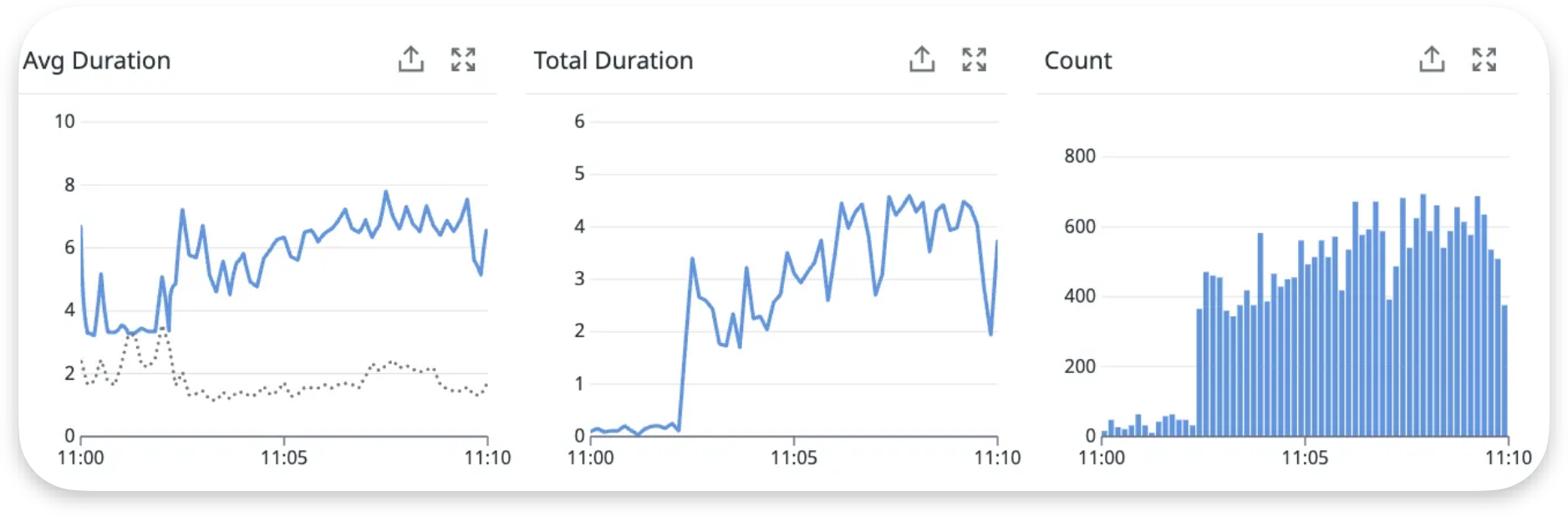
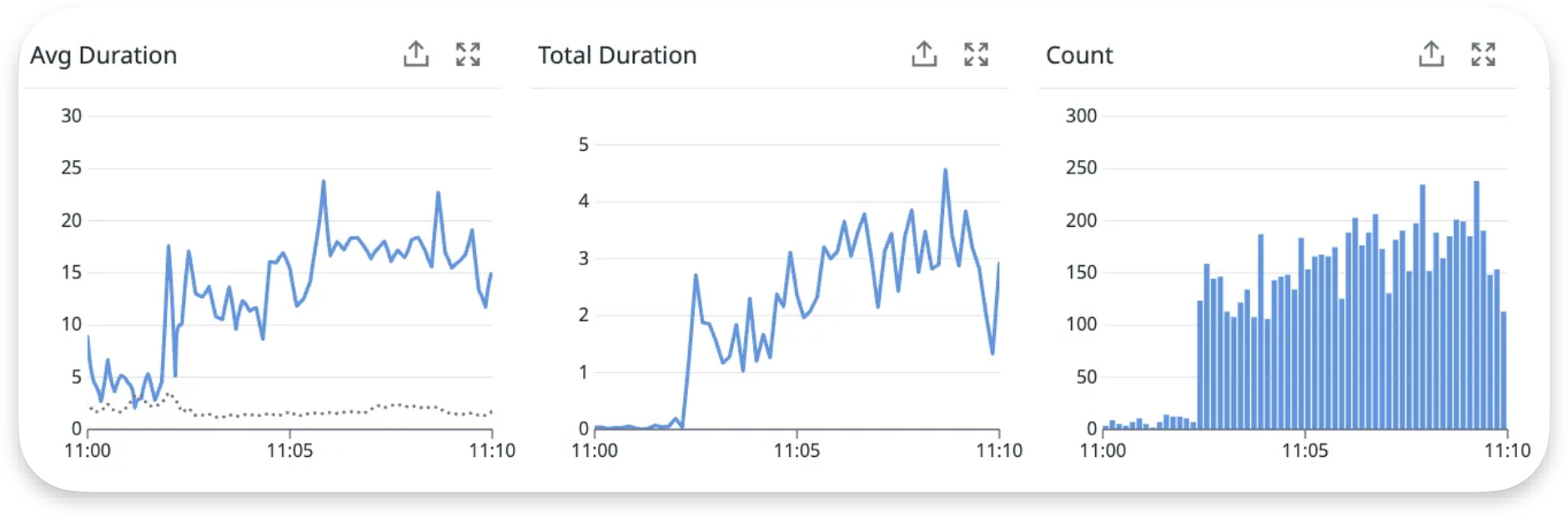
위 이미지는 DB 요청량이 급증하여 모든 서비스가 중단된 10분 동안의 메트릭 정보들입니다.
두 개의 쿼리 대시보드를 봤을 때, 전체 쿼리 평균(점선)에 비해 Avg Duration이 급증한 것을 알 수 있습니다. 특히 두 번째 쿼리의 경우 평상시 3-5ms에서 최대 24ms까지 약 5-8배 증가했습니다. 그리고 평소보다 6-7배 정도 요청량이 급증하여 쿼리 실행 시간과 대기 시간이 더해져 심각한 병목 현상이 발생했습니다.
중요한 것은 Total Duration이 지속적으로 4-5초를 유지한 점입니다. 이는 개별 쿼리가 빨라도 대량 동시 실행으로 인한 누적 부하가 시스템 한계를 초과했음을 의미합니다.
또한, Active Connections가 평상시 1-3개에서 8개까지 급증하여 이후 Concurrency 대기도 급증하는 현상이 발생했습니다.
💡DB CPU 사용률 100%에 도달하면 발생할 수 있는 문제
- DB 처리 지연
- CPU 100% 상태는 모든 쿼리 처리 속도를 저하시킴
- 새로운 쿼리 요청은 DB 내부의 실행 큐에 적재된 상태로 대기
- 애플리케이션 DB 커녁션 풀 고갈
- 쿼리를 보낸 애플리케이션 스레드는 DB 커넥션을 반환하지 못함
- 애플리케이션 DB 커넥션 풀을 모두 소진
- 애플리케이션 스레드의 Blocking 상태
- 새로운 DB 요청을 처리해야 하는 스레드는 커넥션 풀을 얻을 때까지 Blocking 상태로 대기
- 애플리케이션의 요청 처리 스레드 풀 고갈
- 계속된 요청으로 대기 상태의 스레드가 누적됨
- 애플리케이션 서버의 전체 요청 처리 스레드 풀이 고갈
일시적인 Aurora 인스턴스 장애 해결
인증과 관련된 Update 쿼리를 수정하여 요청량이 몰렸을 때 DB CPU 사용량이 급증하는 현상을 방지했습니다.
하지만 여전히 높은 Concurrency 대기 현상이 발생하고 있어 근본적인 문제는 해결되지 않았습니다. 언제든 요청량이 몰리는 상황이 발생한다면 동일한 문제는 다시 발생할 것입니다.

DB Replication 도입을 통한 근본적인 문제 해결
DB Replication을 도입한 이유에 대해서 설명드리겠습니다.
현재 겪고 있는 데이터베이스 문제를 해결하기 위해 DB 인스턴스 스케일업, DB Replication, DB 샤딩 이렇게 세 가지 주요 기술을 검토했습니다.
DB 인스턴스 스케일업은 인스턴스 타입 변경만으로 구현할 수 있어 애플리케이션 코드 수정 없이 즉시 적용 가능하다는 장점이 있습니다. 하지만 현재 겪고 있는 wait/io/table/sql/handler와 Concurrency 대기 문제는 여전히 단일 인스턴스에 모든 부하가 집중되는 구조적 문제에서 발생하므로 근본적인 해결이 어렵습니다.
특히 높은 비율의 테이블 핸들러 대기는 여러 세션이 동일한 테이블과 인덱스에 동시 접근하면서 발생하는 경합으로, CPU나 메모리를 늘린다고 해서 해결되지 않는 문제입니다. 또한 현재 DB 인스턴스 스펙에서 더 큰 인스턴스로 변경 시 비용이 기하급수적으로 증가하지만 성능 개선 효과는 그에 비례하지 않으며, MAU 3만 수준에서는 과도한 투자가 됩니다.
무엇보다 스케일업으로는 단일 장애점 문제가 해결되지 않으며, 트래픽이 지속적으로 증가하면 결국 물리적 한계에 도달하게 됩니다. 따라서 임시방편일 뿐이며 근본적인 해결을 위해서는 부하 분산을 통한 구조적 개선이 필요합니다.
DB Replication은 읽기 부하를 여러 인스턴스로 분산시키는 방식으로, AWS Aurora에서 제공하는 콘솔로 쉽게 설정이 가능합니다. 특히 현재 발생하고 있는 Concurrency 대기 문제를 직접적으로 해결할 수 있으며, 여러 읽기 서버로 구성하여 Read/Write 요청을 효과적으로 분산시킵니다. 읽기 요청이 여러 인스턴스로 분산되어 각 DB 서버가 처리해야 하는 Active Connection 수가 감소합니다. 이로 인해 각 DB 서버의 전체 메모리 사용량이 줄어들고, 동시 처리 부담 감소로 CPU 효율성이 향상되며, 동시성 경합(버퍼 풀 경합, 테이블 핸들러 경합)이 줄어듭니다.
또한 트래픽 분산을 통해 잠재적인 DB 인스턴스 장애 현상을 방지할 수 있고, Master 장애 시 Replica가 자동으로 승격하는 Failover 메커니즘을 통해 단일 DB 구조의 한계까지 해결할 수 있습니다.
기존 애플리케이션 코드에서는 Read/Write 분리 로직만 추가하면 되므로 개발 리스크가 크지 않은 장점도 있습니다.
반면 DB 샤딩은 데이터를 여러 데이터베이스로 수평 분할하여 읽기와 쓰기 성능을 모두 분산시킬 수 있는 해결책입니다. 하지만 샤딩 키 설계, 데이터 재분배와 같이 높은 기술적 요구사항을 요구합니다. 기존 애플리케이션의 전면적인 수정이 필요하고, 여러 DB 인스턴스 관리와 데이터 일관성 보장이라는 운영상의 복잡성도 감수해야 합니다.
현재 MAU 3만 수준의 서비스에서는 샤딩이 제공하는 확장성이 과도하다고 판단됩니다. 또한, 개발팀에서 샤딩을 도입하여 발생할 수 있는 위험 상황과 개발 비용은 높을 것으로 예측되어 도입이 어렵다는 결론을 내렸습니다.
결론은 현재의 팀의 상황과 비즈니스 요구사항을 종합적으로 고려한다면 DB Replication 도입이 가장 적절한 판단이라고 생각했습니다. 물론 완벽한 방안은 아니지만 나중에 서비스가 더욱 성장하고 Write 트래픽 병목 현상이 발생한다면 샤딩이나 다른 고도화된 기술을 도입할 것 같습니다.
Read Replica 도입을 통한 아키텍처 개선안
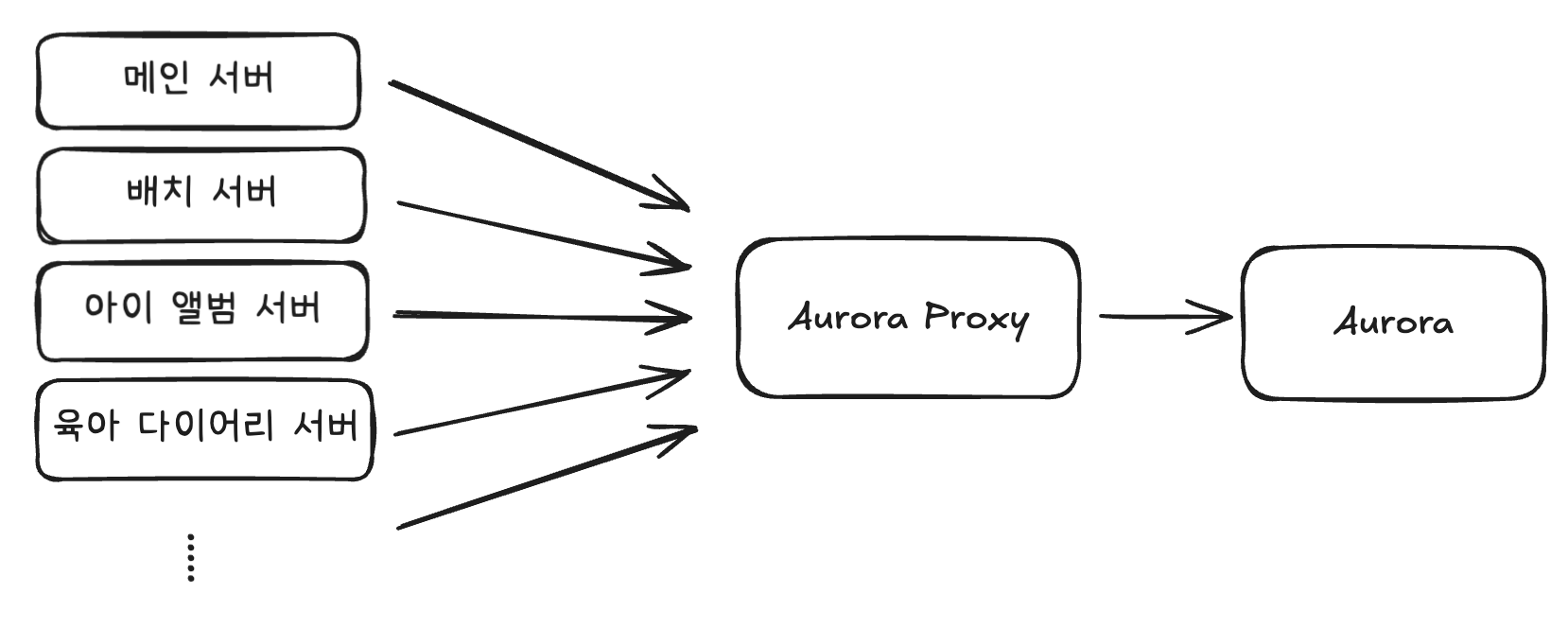
지금까지 언급됐던 문제 사항들을 해결하기 위해 다음과 같은 아키텍처로 개선할 예정입니다.
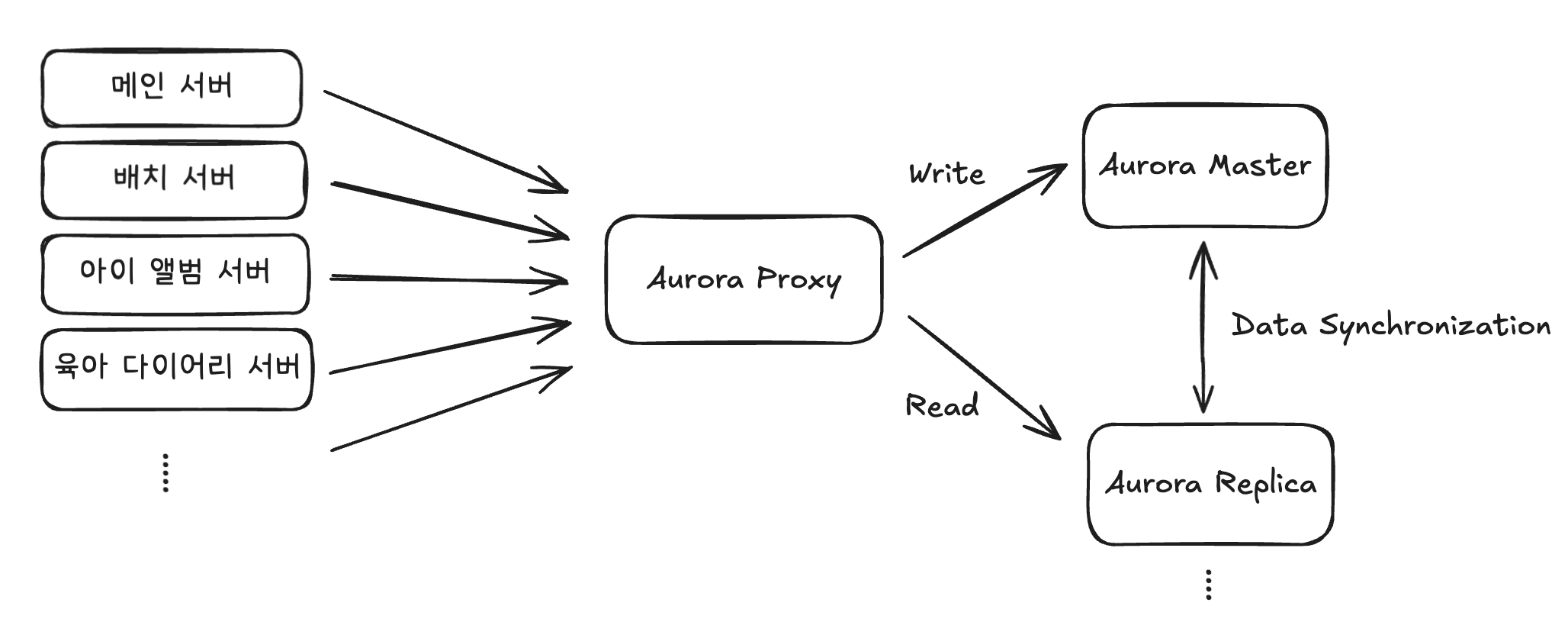
Replica 서버는 최소 2대 이상으로 설정하여 증가하는 읽기 요청을 분산하고 Aurora의 자동 Failover로 고가용성을 보장할 수 있게 됩니다. Aurora Proxy는 애플리케이션의 쿼리 유형에 따라 Write 요청은 Master로, Read 요청은 여러 Replica 중 하나로 자동 라우팅하며, 각 Replica는 Master와 실시간으로 데이터 동기화를 유지합니다.
이 구조를 통해 이전에 단일 인스턴스에서 발생했던 wait/io/table/sql/handler 대기와 Concurrency 경합 문제가 해결되며, Active Connection 수가 각 인스턴스별로 권장 임계값 이하로 안정화됩니다. 특히 요청이 6.5배 증가하는 상황에서도 부하가 여러 인스턴스로 분산되어 안정적인 서비스 운영이 가능합니다.
DB Replication 도입 과정
실제 코드가 아닌 대략적인 설정 코드임을 알립니다.
DatabaseConfig.class
@Configuration
public class DatabaseConfig {
@Primary
@Bean("masterDataSource")
public DataSource masterDataSource() {
return DataSourceBuilder.create()
.url("jdbc:mysql://master-endpoint")
.build();
}
@Bean("replicaDataSource")
public DataSource replicaDataSource() {
return DataSourceBuilder.create()
.url("jdbc:mysql://replica-endpoint")
.build();
}
@Bean
@Primary
public DataSource routingDataSource(
@Qualifier("masterDataSource") DataSource master,
@Qualifier("replicaDataSource") DataSource replica) {
RoutingDataSource routingDataSource = new RoutingDataSource();
Map<Object, Object> dataSources = new HashMap<>();
dataSources.put("master", master);
dataSources.put("replica", replica);
routingDataSource.setTargetDataSources(dataSources);
routingDataSource.setDefaultTargetDataSource(master);
return routingDataSource;
}
}RoutingDataSource.class
@Component
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return TransactionSynchronizationManager.isCurrentTransactionReadOnly()
? "replica" : "master";
}
}Replication 설정 시 고려할 문제
Master - Replica 간 데이터 정합성 문제
Master에서 데이터를 생성하고 난 후, 생성된 데이터를 다른 트랜잭션(Replica)에서 조회하면 해당 데이터가 존재하지 않는 문제가 발생할 수 있습니다.
해당 문제를 해결하기 위해 같은 트랜잭션(Master)에서 처리하거나 저장된 엔티티를 활용하여 데이터 정합성 문제를 방지할 수 있습니다.
💡Amazon RDS와 Amazon Aurora의 동기화 성능 비교
- Amazon Aurora
- 공유 스토리지: Master/Replica가 동일한 클러스터 볼륨 사용
- 로그 기반 복제: 전체 데이터가 아닌 redo log만 전송
- 병렬 처리: 다중 스트림 동시 처리 가능
- Amazon RDS
- 바이너리 로그: 전체 데이터 변경사항 네트워크 전송
- 순차 처리: 바이너리 로그 순차적 적용
적용 결과
프로덕션 코드에 Replication 설정을 마치고 나서 AWS Aurora 설정으로 생성된 Replica를 연결하는 과정이 남은 상황입니다.
하지만 다니던 회사가 경영난으로 인해 팀 전체가 권고 사직을 받게 되었고 최종적으로 적용하지 못했습니다.
만약 Replication이 성공적으로 적용되었다면 어떠한 변화가 생겼을까요?
Concurrency 대기 대폭 감소
- 현재 약 70% 이상을 차지하는 wait/io/table/sql/handler 대기 문제가 읽기 작업 분산을 통해 해결되며, 모든 작업이 하나의 DB에서 경합되는 기존 방식과 달리 Replica로 부하가 분산되어 Concurrency 대기가 대폭 감소하게 됩니다.
Active Connection 정상화
- 작업 부하가 물리적으로 분산되어 각 DB가 권장 임계값 이하에서 안정적으로 운영되며, 각 인스턴스가 효율적으로 처리할 수 있게 됩니다.
장애 상황 예방
- 읽기 처리 용량이 확장되어 요청량이 급증해도 여유롭게 처리할 수 있습니다.
- Master 서버가 비정상적으로 종료되었을 때 자동 Failover로 복구 시간을 단축하고 데이터 손실을 최소화할 수 있습니다.
비용 효율성 및 확장성
- 대형 인스턴스 1개 대신 중형 Master와 소형 Replica 구성으로 Scale-out 방식의 비용 절감 효과를 얻을 수 있습니다.
- Aurora의 공유 스토리지와 redo log 기반 복제로 복제 지연이 밀리초 단위로 최소화되며, 향후 요청량 증가 시 Replica를 추가 생성하여 점진적 확장이 가능합니다.
