문제 상황
아이보리 앱에는 육아 관련 상품을 판매하는 스토어가 있습니다. 이 스토어에서는 각 유저에게 맞는 여러 상품을 추천하여 추천 상품 목록을 제공합니다. 이를 위해 추천 상품 데이터를 주기적으로 최신화하는데, 이 과정에서 문제가 발생했습니다. 추천 상품을 가져오는 과정에서 외부 API를 호출하는데 동기적으로 요청을 하다보니 심각한 지연이 발생했습니다. 해당 기능은 정기적으로 실행되기 때문에 성능 최적화가 필요했습니다.
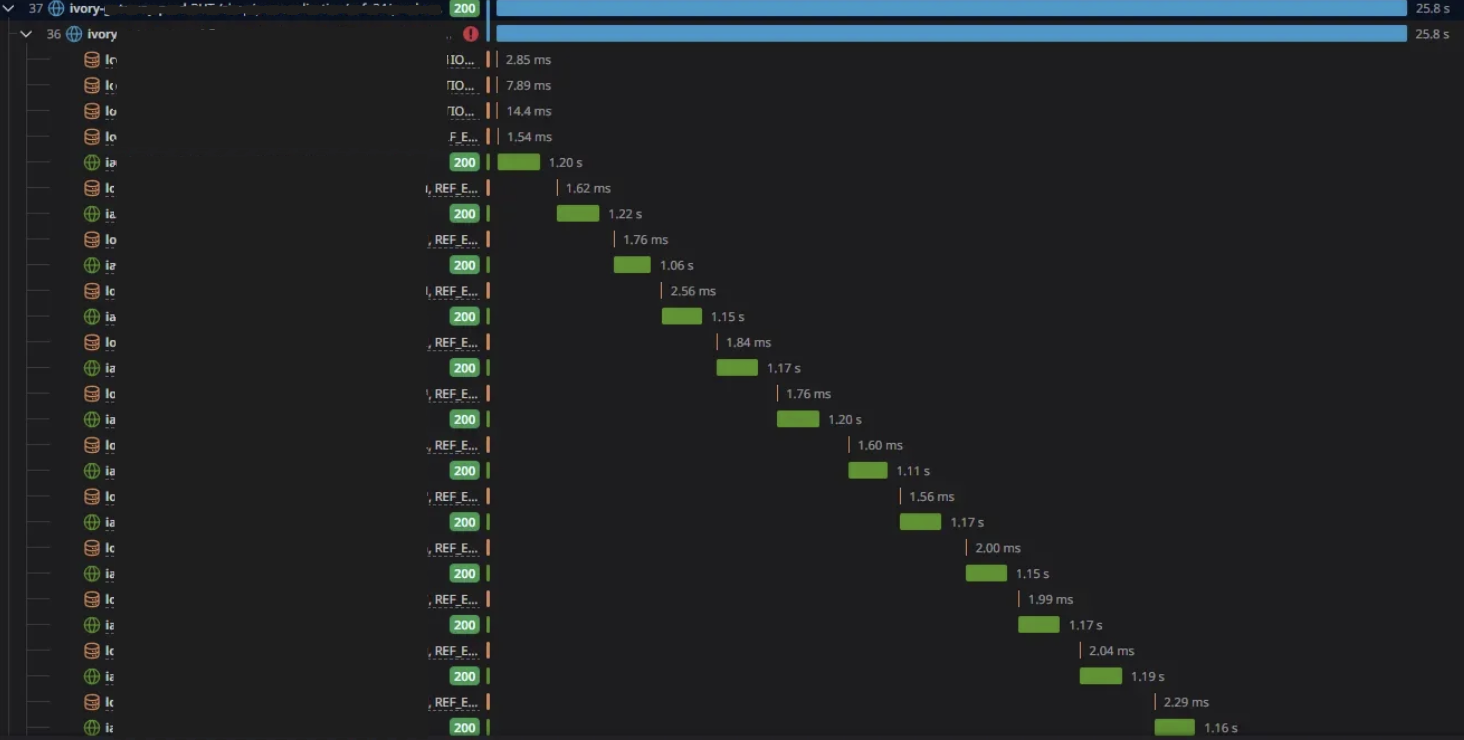
해당 캡쳐는 DB 조회 -> 외부 API 호출 -> 추천 상품 업데이트 과정에서 발생한 지연 과정을 나타낸 DataDog APM에서 제공하는 트레이스 시각화 화면입니다.
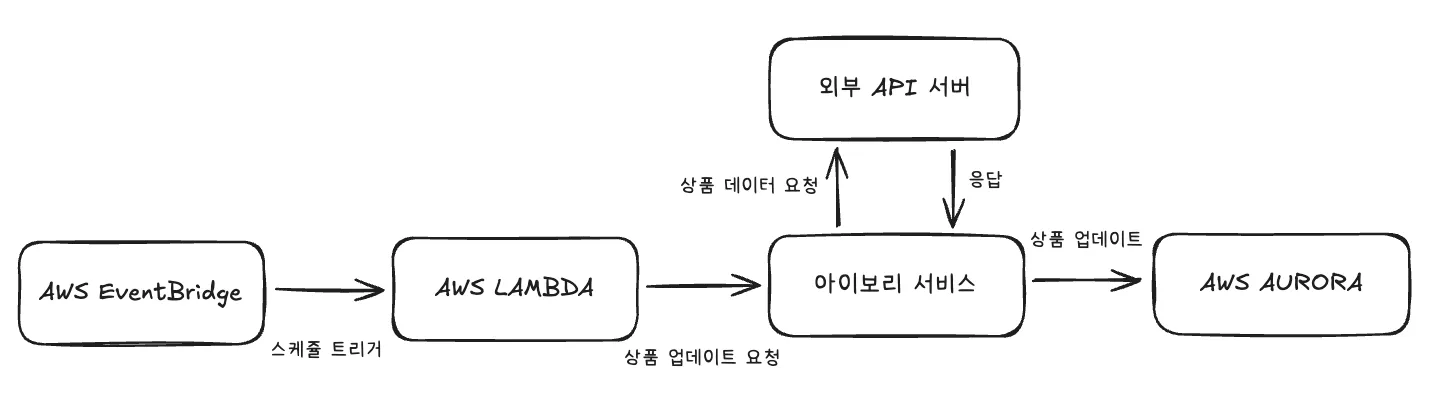
추천 상품 업데이트 아키텍처 다이어그램
코드 처리 과정
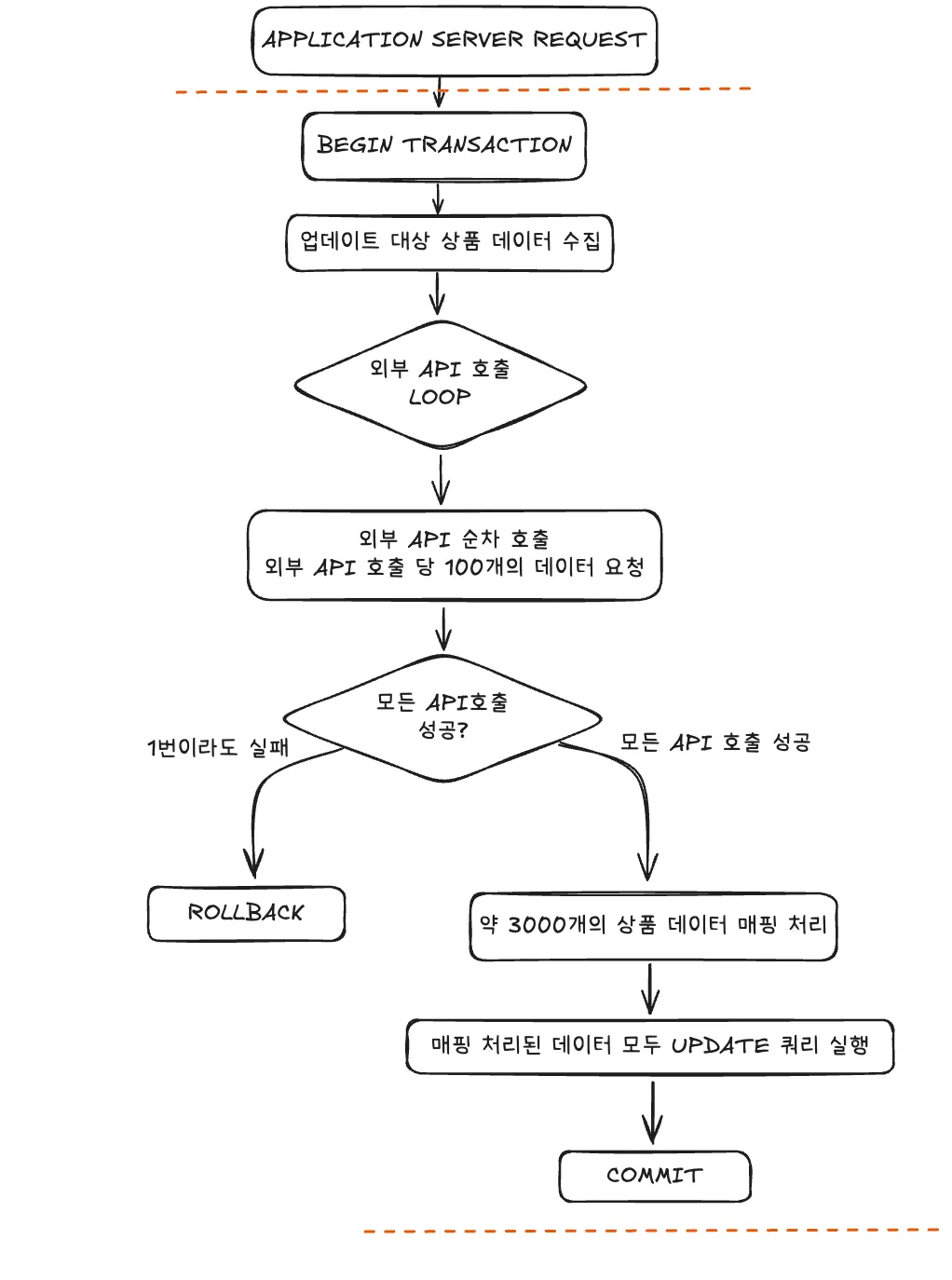
해당 코드
@Transactional
public void problematicFlow() {
// 1. 업데이트 대상 상품 데이터 수집
List<Product> products = getProducts();
// 2. 외부 API 호출 LOOP 커넥션 점유 중
for (Product product : products) {
PersonalizationData data = externalAPI.call(product.getId());
}
// 3. 약 3000개 상품 데이터 매핑 처리
// 4. 매핑 처리된 데이터 모두 UPDATE 쿼리 실행
}APM 트레이스, 아키텍처, 코드 처리 과정을 보면 여러 문제점이 있는 것을 알 수 있습니다. 현재 상황에서도 문제가 발생하고 있지만 서비스가 더욱 커지고 다루어야 할 쇼핑몰의 상품 데이터가 많아진다면 더 많은 문제를 야기할 수 있습니다.
문제점
Lambda 타임아웃 문제
추천 상품 업데이트 로직에서 외부 API를 순차적으로 호출하는 과정에서 호출 당 1초 이상의 대기가 발생하여 응답 시간이 Lambda 타임아웃을 초과하는 문제가 발생했습니다. 이로 인해 Lambda 타임아웃이 지속적으로 발생하며, 실제로는 성공한 작업이 오류로 처리되어 모니터링에 혼란을 야기하고 있습니다. 또한 타임아웃까지의 실행 시간에 대한 불필요한 Lambda 비용이 지속적으로 발생하고 있습니다.
트랜잭션 장기 점유
외부 API 약 30번 호출과 데이터 업데이트 과정이 하나의 트랜잭션으로 묶여 있어 약 30초간 트랜잭션을 점유하고 있습니다. 장기 트랜잭션은 트래픽 집중 시 데이터베이스 커넥션 고갈과 응답 지연을 유발합니다.
비효율적인 데이터 처리
외부 API 호출 중 단 한 번이라도 오류가 발생하면 전체 트랜잭션이 롤백되는 구조로 성공한 데이터까지 삭제되는 비효율이 발생합니다. 한 번의 오류로 유저는 최신화된 데이터를 조회하지 못하는 문제가 발생합니다.
동시성 문제
외부 API 호출을 통해 가져온 대량의 데이터를 한번에 UPDATE 처리하는 과정에서 긴 처리 시간으로 인해 트랜잭션을 오래 점유하고 동시성 문제가 발생할 위험이 있습니다. 멀티스레드 환경에서 동일한 상품에 대한 동시 업데이트가 발생할 경우 레이스 컨디션으로 인한 데이터 충돌이 발생할 수 있습니다.
해결방안 : 메시지 큐
기존 아키텍처는 긴 작업을 동기식으로 처리하는 근본적인 설계 문제로 발생했습니다. 이를 해결하기 위해 메시지 큐를 도입하는 방안을 생각했습니다.
메시지 큐를 도입한 이유는 세 가지 입니다.
1. 비동기 처리를 통한 즉시 응답 구조 확립
비동기 처리 구조를 통해 Lambda는 즉시 응답을 받고, 실제 처리는 백그라운드에서 안전하게 수행할 수 있게 됩니다. 이를 통해 불필요한 대기 시간으로 인한 비용을 절약할 수 있습니다. 또한, 타임아웃 오류와 실제 비즈니스 로직 오류를 분리하여 모니터링의 정확성을 크게 향상시킵니다.
2. Producer-Consumer 구조 분리
기존의 오랫동안 지속되는 하나의 거대한 트랜잭션을 여러 개의 짧은 트랜잭션으로 분할함으로써 데이터베이스 리소스 점유 시간을 최소화할 수 있습니다. Producer는 메시지 발행만 담당하여 즉시 완료되고, Consumer는 각 메시지를 병렬 처리와 짧은 트랜잭션으로 안전하고 빠른 처리가 가능합니다. 이러한 구조는 데이터베이스 커넥션 고갈 문제와 동시성 문제를 방지합니다.
3. 장애 격리 및 부분 복구 메커니즘 구축
메시지 단위로 처리를 분할함으로써 성공한 작업은 그대로 보존하고 실패한 부분만 선별적으로 재시도할 수 있는 메커니즘을 구축할 수 있습니다. 이를 통해 복구 시간을 단축시킬 수 있습니다. 또한, 각 단계별 실패 지점을 명확히 추적할 수 있어 장애 진단과 대응이 훨씬 효율적으로 이루어집니다.
어떤 메시지 큐를 도입하면 좋을까??
먼저 대표적인 메시지 큐인 RabbitMQ, Apache Kafka, AWS SQS를 비교했습니다.
각 메시지 큐를 사용하는데 적합한 환경을 정리했습니다.
RabbitMQ
- 다양한 프로토콜 지원이 필요한 레거시 시스템 연동
- 복잡한 라우팅 로직이 필요한 경우 (토픽 기반, 패턴 매칭)
- 메시지 우선순위 처리가 중요한 비즈니스
Apache Kafka
- 높은 처리량이 요구되는 환경
- 실시간 스트리밍 데이터 처리가 필요한 경우
- 데이터 파이프라인, 이벤트 소싱, CQRS 패턴 구현
AWS SQS
- AWS 생태계를 이미 사용 중인 환경
- 빠른 개발과 배포가 중요한 프로젝트
- 메시지 순서가 크게 중요하지 않은 비즈니스 로직
- 간단한 메시지 처리 로직이 주를 이루는 경우
현재 팀의 규모가 작고 인프라 팀이 따로 존재하지 않은 상황입니다. 그리고 복잡한 라우팅 로직과 높은 처리량이 요구되지 않은 환경이기 때문에 AWS SQS로 충분히 요구사항에 맞는 처리가 가능했습니다. 또한, AWS SQS는 브로커 운영을 AWS가 완전 관리하는 방식이기 때문에 운영이 편하고 빠르게 적용이 가능했습니다.
이러한 과정을 통해 AWS SQS 도입을 결정하게 되었습니다.
트러블 슈팅
AWS SQS 도입 후, 발생한 외부 API Rate Limit 에러
Spring Boot 사용 시 @SqsListener 애노테이션을 통해 메시지를 간단하게 처리할 수 있습니다. 스프링 클라우드 AWS에서는 SimpleMessageListenerContainer 를 통해 다음과 같은 기본값이 설정되어 있습니다.
maxConcurrentMessages: 10 (병렬 처리 가능한 메시지 수)maxMessagesPerPoll: 10 (한 번에 가져올 메시지 수)
이 설정으로 인해 Consumer에서 10개의 메시지를 한 번에 가져와서 10개의 스레드로 병렬 처리하게 됩니다.
이 과정에서 외부 API의 Rate Limit 정책 때문에 몇 개의 메시지 처리 과정에서 Too Many Request(429) 에러가 발생했습니다. 해당 에러 때문에 처리되지 못한 메시지는 SQS에 그대로 남아있게 되고 기본 설정 값이 30초인 Visibility Timeout에 따라 30초 동안 메시지를 확인하지 못하여 재처리가 지연되었습니다. Visibility Timeout을 짧게 설정할 수 있지만 다른 컨슈머가 해당 메시지를 폴링하여 중복 처리하는 문제가 발생할 수 있기 때문에 Visibility Timeout을 조정하지 않았습니다. 그리고 발생한 에러를 직접 로직 내에서 처리하는 것이 더욱 적절하다고 생각했습니다.
이러한 문제를 해결하기 위해 SQS에서 가져온 메시지를 처리하는 maxConcurrentMessages 조정이 필요했습니다.
병렬 처리 개수 조절
외부 API의 Rate Limit 제한 정책과 데이터베이스를 기준으로 병렬 처리 개수를 조절했습니다.
- 외부 API Rate Limit 제한 정책(Leaky Bucket)
- 요청을 버킷에 저장하는 방식으로 갑작스러운 트래픽 제어
- 초당 처리량을 제한하여 일정한 처리
- 버킷의 용량을 초과하면 요청 거절
- 버킷의 총 크기 40개, 초당 2개씩 복구
- 초당 10회 이상 요청시 비정상 패턴으로 간주
- 데이터베이스 상황
- DB 인스턴스가 1대로 운영되고 있어 모든 쓰기 요청을 처리
- 2vCPU로 낮은 동시 처리 능력
외부 API Rate Limit 정책 분석
처리해야 할 메시지가 약 30개 정도인 상황에서 Rate Limit 회복량을 고려해보면, 초당 2개씩 지속 처리할 경우 무제한으로 가능하고 초당 3개 처리 시에도 순증가가 1개로 충분한 여유가 있어 3개 이상도 무리없이 처리가 가능합니다. 하지만 해당 요청뿐만 아니라 다른 기능에서도 외부 API를 활용하는 경우가 있을 수 있기 때문에 병렬 처리 개수를 보수적으로 3개로 설정했습니다.
데이터베이스 상황 고려
데이터베이스가 1대로 운영되고 있고 낮은 동시 처리 능력으로 인해 데이터베이스에 대한 동시 요청 개수를 보수적으로 고려했습니다.
최종 결졍
최종적으로 maxConcurrentMessages의 값과 maxMessagesPerPoll값을 3으로 수정하여 메시지 3개씩 병렬 처리하는 방법을 선택했습니다. 해당 설정은 AwsSqsConfiguration 클래스 내부에서 SqsMessageListenerContainerFactory SQS 메시지 수신 컨테이너 팩토리 클래스 설정을 통해 수정했습니다.
재시도 처리에 대한 고민
SQS 메시지 큐에서 가져오는 메시지와 처리할 수 있는 메시지의 개수를 제한하여 작업처리 속도를 개선했고 Rate Limit 에러 발생을 해결했습니다. 하지만 메시지를 처리하는 과정에서 일시적 네트워크 문제, 서버 측 오류, 다른 서비스에서 동시 호출로 인한 버킷 고갈 등 다양한 문제가 발생하여 에러가 발생할 수 있습니다.
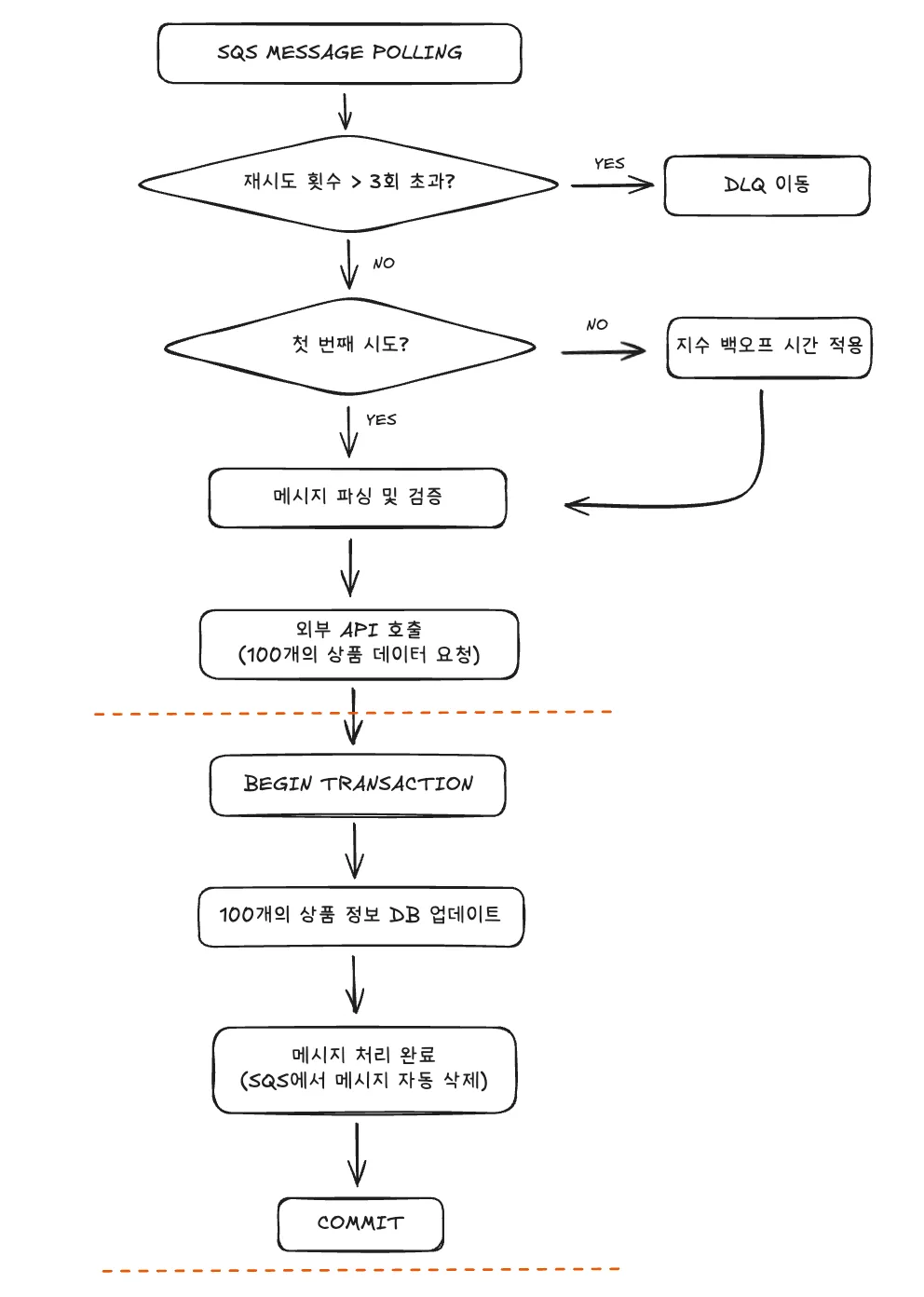
지수 백오프 + 데드 레터 큐 도입 과정
외부 API의 Rate Limit 정책을 고려했을 때 지수 백오프 재시도를 통해 3번의 재시도를 하게 두었습니다. 2초 -> 4초 -> 16초로 재시도하면서 버킷에 필요한 개수가 대부분 회복되기 때문입니다. 이러한 재시도 과정을 통해서 문제가 해결되지 않는 경우는 외부 API에 대한 서버 내부 오류일 가능성이 큽니다. 그래서 무한한 재시도를 방지하고 재시도가 3번을 초과하면 데드 레터 큐에 적재되어 메시지를 수동으로 처리할 수 있도록 구성했습니다.
트랜잭션 분리 과정
하나의 긴 과정으로 이루어진 트랜잭션을 메시지 큐를 도입하면서 Producer - Consumer로 구조로 나누어 트랜잭션을 분리할 수 있었습니다.
그리고 외부 API 호출하는 부분과 데이터 update하는 과정을 트랜잭션 분리하여 짧은 시간동안 트랜잭션을 점유하도록 개선했습니다.
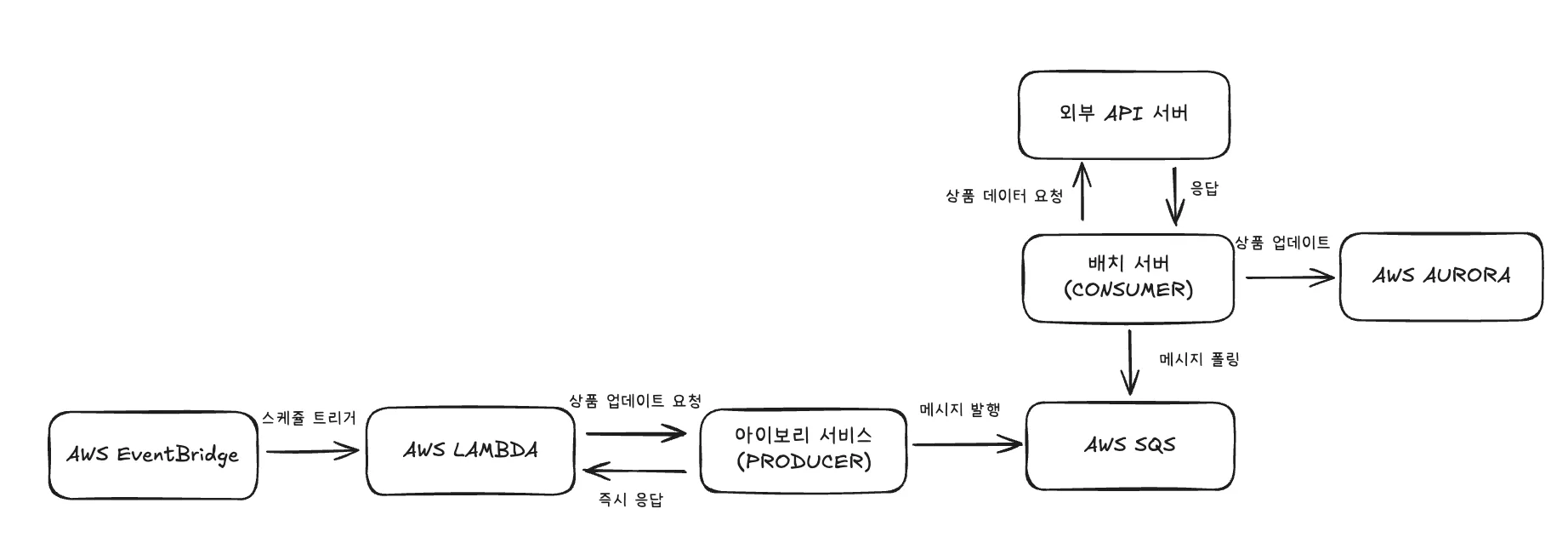
개선된 아키텍처와 코드 처리 과정
결과
Lamda 타임아웃 오류 해결
Producer 측에서 메시지를 생성하고 나면 Lambda에게 즉시 응답을 보내 타임아웃을 방지하고 타임아웃까지 발생한 비용을 절감할 수 있었습니다.
트랜잭션 분리로 커넥션 점유 시간 단축
트랜잭션이 필요한 부분에만 적용하여 빠르게 DB 커넥션 반환이 가능해졌습니다.
병렬 처리로 속도 3배 개선
이전에는 순차적으로 외부 API 호출을 했다면 Consumer에서 스레드 풀을 생성하고 병렬 처리하여 속도가 개선되었습니다.
안전한 작업 처리 가능
재시도 로직을 통해 일시적인 오류를 해결하고 Rate Limit 회복을 가능하게 만들었습니다. 또한, 데드 레터 큐를 통해 무한 재시도를 방지하고 데드 레터 큐에 쌓인 메시지를 분석하여 실패 원인을 찾아 낼 수 있게 되었습니다.
