
자료구조 개념 정리하기 <1>
🖍🖍 알고리즘 백준 문제 마라톤에 문제 주제에 맞춰서 정리해본거라 중구난방일 수 있지만.. 최대한 내가 이해한대로! 알고리즘 튜터님(스파르타 코딩클럽 박현준 튜터님😆)이 집어주신 전체적인 자료구조의 숲을 보는 훈련을 하면서 정리하는게 목표입니다!
🌲 자료구조의 숲 보기
- Linked List는 삽입과 삭제가 빠르게 할 때! => python에서는
list사용하기! - Binary Search(이진 탐색)는 정렬되어 있는 list에서 그냥 반복문 보다 target을 빠르게 찾을 때!
- Recursion(재귀)는 점점 줄여나가도 같은 행위를 반복해서 답을 찾을 때!
🚂 Linked List
- 먼저 Linked List와 우리가 일반적으로 알고있는 Array의 차이!
| 경우 | Array | Linked List |
|---|---|---|
| 특정 원소 조회 | O(1) | O(N) |
| 중간에 삽입 삭제 | O(N) | O(1) |
| 데이터 추가 | 데이터 추가 시 모든 공간이 다 차버렸다면 새로운 메모리 공간을 할당 받아야 한다! | 모든 공간이 다 찼어도 맨 뒤의 노드만 동적으로 추가하면 된다 |
정리를 해보면 데이터에 자주 접근을 해야하고 그 위치를 알아야 할 때는 Array, 데이터를 자주 추가하거나 삭제를 해야 하면 Linked List를 사용하자! 입니다.
🤔 그럼 python 의 list는 뭘까?
일단은 array이긴 한데.. 튜터님의 강의에선 python의 list는 array로 쓸 수도 있고 linked list로 쓸 수 있다고 합니다!? 동적 배열 을 사용한다고 하는데.. 그건.. 나중에.. 알아보려구요..python 의 list는 array로 쓸 수 있고 linked list로도 쓸 수 있다고만 알고 넘어가기😂
- Linked List 코드로 구현해보기
1) Array에서 data를 넣는 한칸 한칸 처럼, linked list에서 data하나 하나를 담고 있을Node를 class로 정의해 줍니다!
2) 모든 Linked List에서 공통적으로append, add(추가), delete(삭제), get(읽기)를 사용하기 위해 Linked List class 를 생성해서 method로 추가 해줍니다!
3) class 내부에 constructor(새로운 linked list를 만들 때마다 반드시 초기 설정을 해줘야 되는 부분을 정의해놓은 method)에서head를 생성하도록 정의합니다.
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self, value):
self.head = Node(value)
# list 끝에 새로운 node 추가하기
def append(self, value):
cur = self.head
while cur.next is not None:
cur = cur.next
cur.next = Node(value)
# list 모든 data 불러오기
def print_all(self):
cur = self.head
while cur.next is not None:
print(cur.data)
cur = cur.next
# 특정 index의 node값 가져오기
def get_node(self, index):
node = self.head
count = 0
while count < index:
node = node.next
count += 1
return node
# 특정 index에 node 추가하기
def add_node(self, index, value):
new_node = Node(value) # 일단 추가할 새로운 Node를 만든다
if index == 0: # 추가하는 Node를 head로 할 때는 index -1에서 오류 발생
new_node.next = self.head # 추가하려는 Node의 next를 기존의 head node로 해주고
self.head = new_node # head Node를 추가한 새로운 node로 변경해준다
return
node = self.get_node(index - 1) # 추가하려는 자리에 있는 원래 Node정보를 받아온다
next_node = node.next # 그 원래 Node의 다음 Node도 받아온다
node.next = new_node # 새로 추가하려는 Node를 원래 그 자리에 있던 Node의 다음으로 연결해준다
new_node.next = next_node # 새로 추가하려는 Node의 다음을 원래 그 자리에 있던 Node의 다음 Node와 연결해준다
# 특정 index의 node 삭제하기
def delete_node(self, index):
if index == 0: # index가 0일 땐, index - 1에서 오류가 발생하므로 따로 정의 해주기
self.head = self.head.next # 기존의 head삭제하면 기존 head의 다음 node가 head가 됨
return
node = self.get_node(index - 1) # 지우려고 하는 node의 전 node를 받아오고
node.next = node.next.next # 그 node의 다음 다음을 다음 node로 바뀌준다!
🔍 이진 탐색
-
어떤 list를 탐색할 때, 반씩 쪼개서 탐색해 보는 것! 그리고 찾으려는 target이 어디 있는지에 따라 탐색하는 구간을 1/2로 줄여나간다!
-
target에 맞게 찾아야 하는 범위를 반씩 줄이면서 탐색하므로 속도가 빠르다 => 시간복잡도: O(logN)
-
하지만 이진 탐색이 이렇게 쉽게 가능한 것은 list가 이미 오름차순으로 정렬되어있기 때문! 따라서 이진 탐색을 쓰려면 먼저
데이터를 일정한 규칙 으로 정렬해야한다!! -
이진 탐색 code
1) 일단 초기에list에서 첫번째와 마지막 index를 변수에 할당해 줍니다.
2) 현재 target이라고 추측하는 수의 index 는처음과 끝의 // 2 즉, 중간 index로 정해 줍니다.
3) 중간 index에 해당하는 data와 target을 비교해서 그에 맞게첫 index와 마지막 index를 갱신해줍니다!
4) 그리고 갱신된 첫번째와 마지막 index로중간 index도 갱신해줍니다!
5) 과정을 계속하면 target을 찾는 범위를 점점 반씩 줄이면서,첫번째 index와 마지막 index가 똑같아질 때까지 반복합니다. 그래도 target과 같은 값이 나오지 않으면False를 반환합니다
6) 처음 예상했던 중간 index의 값과 target값이 바로 일치 해버리면 굳이 비교하지 않고 바로True를 반환합니다!
finding_target = 14
finding_numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
def is_existing_target_number_binary(target, array):
min_index = 0
max_index = len(array) - 1
cur_index = (min_index + max_index) // 2
while min_index <= max_index:
if array[cur_index] < target:
min_index = cur_index + 1
elif array[cur_index] > target:
max_index = cur_index - 1
else:
return True
cur_index = (min_index + max_index) // 2
return False
result = is_existing_target_number_binary(finding_target, finding_numbers)
print(result)🔗 재귀
-
자기 자신을 참조하는 것! 즉,
어떤 함수를 정의할 때 지금 정의하고 있는 함수를 써먹는 것!!라고 이해했습니다😂 -
당연히 항상 이렇게 할 수 있는게 아니고
1) 범위를 줄여나가도
2) 같은 행위를 계속 적용해서 답을 반환할 수 있을 때
재귀 함수를 시도해 봅시다! -
하지만 자기 자신을 계속 부르는 구조이므로 언젠간 끝내줘야 합니다! 그게 바로 탈출 조건 을 만들어 주는 것입니다!
-
Factorial code
def factorial(n):
if n == 1:
return 1
else:
return n * f(n - 1)- 회문 검사 code
def string_check(string):
# 문자가 하나만 있으면 항상 회문입니다!
# 이부분이 탈출조건
if len(string) == 1
return True
if string[0] != string[-1]:
return False
# 문자열의 양끝을 자르고 이 함수를 다시 실행합니다!
# 이게 바로 재귀!!
return string_check(string[1:-1])🧾 알고리즘 문제
🤷♀️ 문제를 대하는 자세!
- 위의 개념과 관련된 문제를 다시 풀어보자!!
- 튜터님이 제시해준 방법으로 문제에 접근하기
1) 문제에 어떤자료구조를 사용할지 생각
-> 이미 알고리즘 문제 시트에서 이걸 제공해주므로 다시 풀 때는 문제를 봤을 때어떤 부분에서 이 자료구조를 사용해야겠다고 캐치 할 수 있는지찾아보자!
2) 문제에서어떤 행위를 통해 결과를 구하고 싶어하는데, 여기서 이행위의 패턴을 파악해 보자!
-> 그런 패턴이 안보이면 예시를 3개.. 10개까지 손으로 써보기
-> 3시간을 붙잡아도 여기서 못 넘어 가겠으면 답을 보자!
3) 패턴을 파악했으면😮 로직을 보고나서 이해가 된다면?
답을 더 보기 전에 그 로직을 스스로 구현 해보자! 구현이 잘 안 되는 로직은 다시 이해해보고 다시 구현을 시도하자.(30분정도..?) 마지막으로 자신이 구현한 방식과 해설을 비교한다. 여기서조건을 어떤식으로 처리해서 코드화하는지 체크✅ 해보자!그 패턴을 코드화 해보자!
4) 최적화를 위해리팩토링을 해보고가독성도 고려해보자!
🎲 나무 자르기
1) 문제에서 어떤 자료구조 or 알고리즘을 쓸지 체크할만한 부분
: 어떤 특정한 수를 기준으로 나무들을 자르는데, 그 수는 제시해준 나무 길이 중에 제일 긴 나무보다는 무조건 작아야 합니다! 따라서 0 부터 제일 긴 나무 높이 사이의 숫자 중에 답을 찾으면 되니까... 어떤 정렬된 숫자 배열이 있을 때, 반씩 쪼개면서 탐색해서 상대적으로 원하는 수를 빠르게 찾을 수 있는.. 이진 탐색!?
2) 행위의 패턴 파악하기
: 일단 여기서의 반복되는 행위는 나무를 자르기 인데.. 그냥 자르지 않아요😂 일단 위에서 말했듯이 0부터 입력한 나무높이 중 제일 큰 수(max(trees))를 이진 탐색 하면서 나오는 숫자로 모든 나무를 잘랐을 때 그 잘린 나무들의 합이 원하는 나무 높이와 같아지면 이진탐색을 끝내면 됩니다!
3) 처음에 내가 구현한 코드
import sys
input = sys.stdin.readline
N, M = map(int, input().split())
trees = list(map(int, input().split()))
min, max = 0, max(trees)
while min <= max:
cut = (min + max) //2
sum = 0
for tree in trees:
if cut < tree:
sum += tree - cut
if len < M:
max = cut - 1
elif len > M:
min = cut + 1
else:
break
print(cut)이걸 처음 풀었을 때도.. 이렇게 해서 똑같이 틀렸는데.. 그때 제대로 이해안하고 흠~ 답이 비슷한데 약간 다르네 이러고만 넘어가서..😂 이번기회에 다시 왜 틀렸나 봤더니❗❗
4) 내가 계속 헷갈려 하고 간과했던 조건!
: 위에서 짠 코드로 실행을 해보면 문제가 생깁니다.. 사실 처음에는 대체 뭐가 문제인지 몰랐는데 예시를 막 넣어보니까 문제점이 확실히 보였어요😞😞
ex) trees = [40 30 5 27] 이고 여기서 얻으려는 높이가 29 일때
나의 원래 코드 대로 쭉쭉 하다 보면...
- 반복문 4번째 실행시
min = 21, max = 24
cut = (21 + 24) // 2 = 22
sum = 31 > 29 => min = cut + 1 = 23 - 반복문 5번째 실행시
min = 23, max = 24
cut = (23 + 24) // 2 = 23
sum = 28 < 29 => max = cut - 1 - 반복문 6번째 실행시
min = 23, max = 23
cut = 23, sum = 28 < 29 => max = cut - 1 = 22
min > max 가 되므로 반복문 중단!
그런데 여기서 답을 cut으로 하면 sum = 28 < 29 되므로.. 안됩니다!
문제에서 원하는 건적어도 가져가려는 높이보다는 잘린 나무의 합이 커야한다!입니다. 따라서 이 경우에는 답을 cut이 아닌 max로 해야 하는 것!!
이렇게 조건을 나눠서 막 더 해봤더니..! sum이 원하는 값보다 작을 때만 max값을 답으로 해주고 나머지는 원래대로 cut을 답으로 해도 문제가 없었습니다!
5) 최종적으로 수정한 나의 코드
- 구글링한 답지를 참고 했을 때 for문을 그냥 돌리는 것 보다 아래와 같이
for문과 if 문을 한줄로 축약하는게 시간이 훨씬 줄었습니다!! 그래서 백준에 제출할 때 python3로 해도 통과가 됬습니다! - 잘라서 더한 나무 길이를
len이라고 선언하고, 조건마다 달라지는 답을 공통으로 받아주기 위해ans변수를 만들어주었습니다!
import sys
input = sys.stdin.readline
N, M = map(int, input().split())
trees = list(map(int, input().split()))
min, max = 0, max(trees)
while min <= max:
cut = (min + max) // 2
len = 0
ans = 0
len = sum(tree - cut if tree > cut else 0 for tree in trees)
if len < M:
max = cut - 1
ans = max
else:
min = cut + 1
ans = cut
print(ans)🎲 하노이 탑
1) 문제에서 어떤 자료구조 or 알고리즘을 쓸지 체크할만한 부분
: 솔직히.. 문제의 어딜 보면 이걸 재귀인지 아닌지 알 수 있을지 잘 모르겠습니다😅 재귀라는 건 자기 자신을 호출하고, N을 쪼개서 즉, N-1이나 N-2가 똑같은 패턴으로 N을 만들어 내는 느낌이 와야하는데.. 처음엔 도저히 그런 느낌을 받을 수 없었어요. 재귀는 직접 쓰면서 아 재귀를 하면 되겠다 깨닫는게 더 좋은 것 같습니다! 재귀 문제를 많이 풀다 보면 문제를 읽다가도 바로 캐치할 수 있을까요..?😂
2) 행위의 패턴 파악하기
: 이건 도저히 간단한게 할 수가 없어서 직접 그려봤습니다❗❗
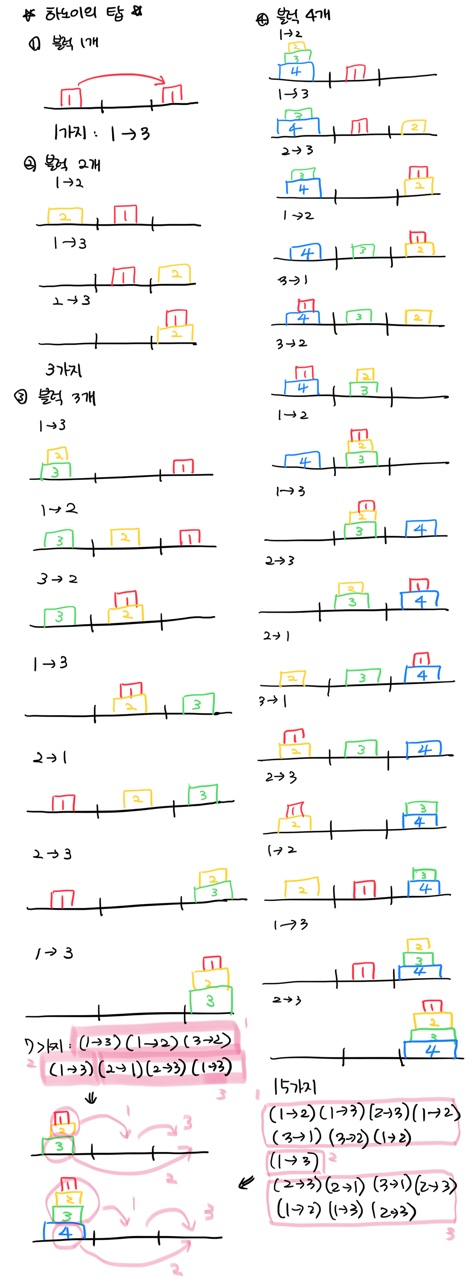
일단 크게 파악할 수 있는 건 맨밑에 있는 가장 큰 블럭을 제외하고 위에 있는 무리를 두번째에 옮겼다가, 첫번째에 있는 가장 큰 블럭을 세번째에 옮기고 두번째에 있는 무리를 그 위에 쌓는 겁니다. 블럭이 총 4개면 3개를 그렇게 옮기고, 블럭이 총 5개면 4개를 그렇게 옮기고..
이렇게 보면 재귀가 맞습니다! f(3)구한걸 f(4)에서 써먹고, f(4)에서 구한걸 f(5)에서 쓰고..그런데 문제에서는 이렇게 옮기는 과정과 횟수 를 출력해라고 했으므로 과정을 return 해줘야 하는 데, 그럴려면 매 과정마다 출력되는게 바뀌니까.. 과정을 나타내는 변수를 함수의 매개변수로 하면..!? (사실 여기가 제일 어려웠습니다. 큰 규칙은 알 것 같은데 그걸 직접 구현하려고 하니 너무 추상적인 느낌이었습니다😢😢)
3) 처음에 내가 구현한 코드
: 규칙을 참고하고 로직을 이해한 뒤 코드 구현을 시도해 보았습니다!
import sys
input = sys.stdin.readline
number = int(input())
def hanoi(N, start, to, via):
if N == 1:
return print(f'{start} {to}')
else:
hanoi(N - 1, start, via, to)
print('1 3')
hanoi(N - 1, via, to, start)
hanoi(number, 1, 3, 2)N-1을 N번째 블럭위에 있는 덩어리라고 하면.. 그 덩어리를 두번째에 옮기고 N 블럭을 첫번째에서 3번째로 늘 옮기는 건 같으니까 그냥 print('1 3') 을 하면 될 줄 알았는데 재귀이므로 hanoi(N - 1, start, to, via) 에서는 처음과 끝이 1과 3이 아닐 수 도 있으므로 그 함수를 실행할 때의 start와 to를 print 해줘야 합니다!
import sys
input = sys.stdin.readline
number = int(input())
def hanoi(N, start, to, via):
if N == 1:
return print(f'{start} {to}')
else:
hanoi(N - 1, start, via, to)
print(f'{start} {to}')
hanoi(N - 1, via, to, start)
hanoi(number, 1, 3, 2)그러면 횟수는 어떻게 구할까요?
횟수에 대한 재귀식은
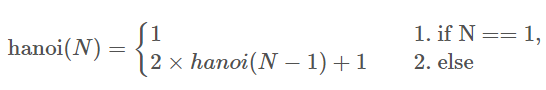
이런 식이 만들어 지면 최종적으로

이렇게 구할 수 있다고 합니다! 여기서 중요한 건 횟수에 대한 재귀식도 위와같이 짜보자 입니다!!😂
4) 최종 정답 코드
import sys
input = sys.stdin.readline
number = int(input())
def hanoi(N, start, to, via):
if N == 1:
return print(f'{start} {to}')
else:
hanoi(N - 1, start, via, to)
print(f'{start} {to}')
hanoi(N - 1, via, to, start)
print(2**number - 1)
hanoi(number, 1, 3, 2) 🎲 색종이 만들기
1) 문제에서 어떤 자료구조 or 알고리즘을 쓸지 체크할만한 부분
: 가로 세로 길이가 N인 정사각형 종이가 있으면 쪼개면서 모두 같은 색인지 체크합니다! 이 말은 작게 쪼개면서 같은 행위를 반복한다! 바로 재귀 입니다😂
2) 행위의 패턴 파악하기
: 일단 입력이 N * N 행렬로 들어오고 거기서 색깔이 다른게 확인 되면 바로 종이를 4등분 합니다...제일 생각해내지 못했던 부분이 잘 랐을 때 기준점을 잡는 부분이었습니다.
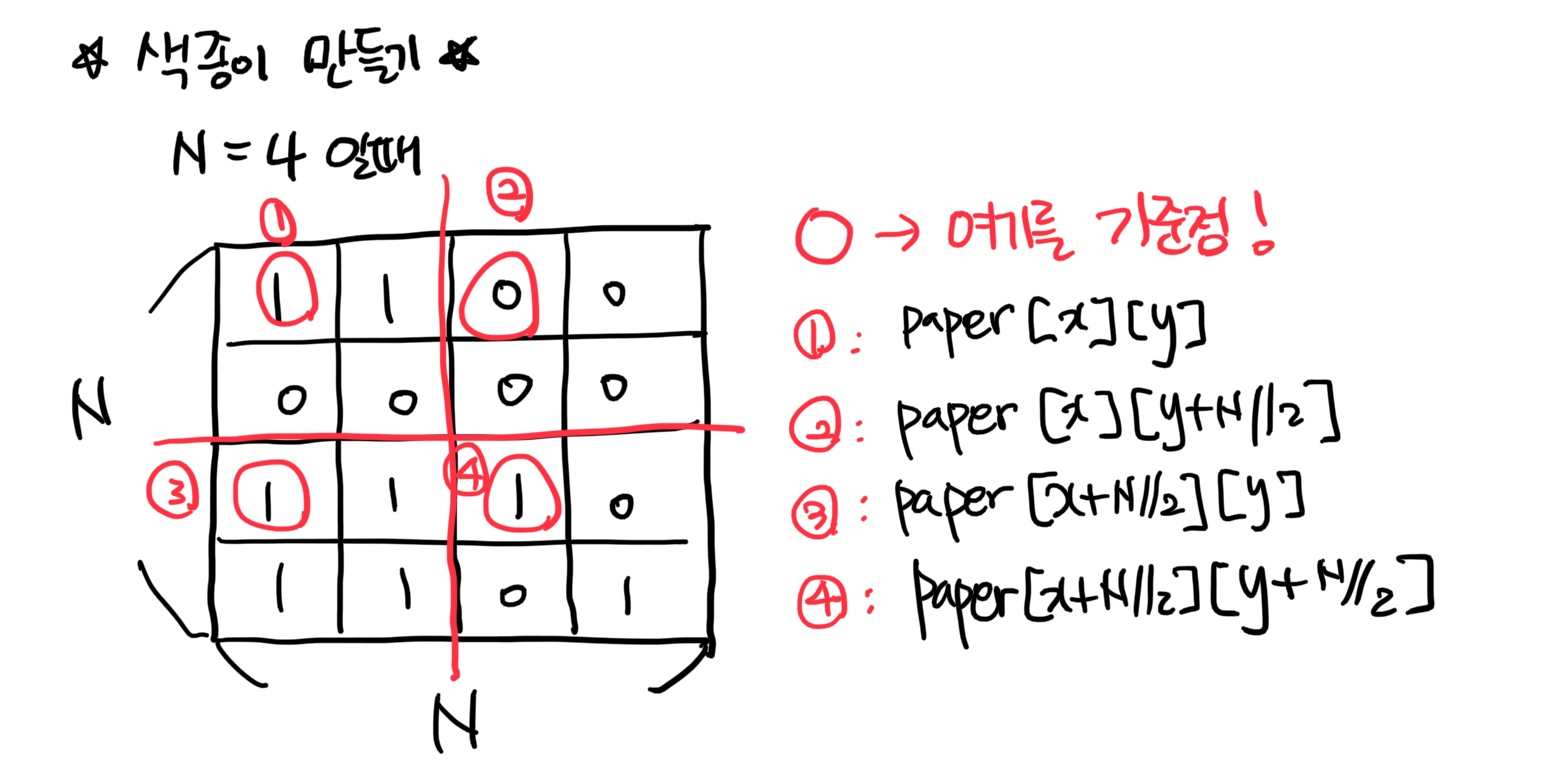
paper 행렬에 있는 모든 성분을 하나하나 다 비교해야 하나..? 라고 생각하니까 for문을 돌리면서 어떻게 비교하지?? 생각 때문에 혼란스러웠습니다😥 그럴 필요 없이 기준점의 색깔과 그 기준점으로 한 정사각형 안의 성분만 for문으로 하나하나 확인해서 비교하면 되는 부분이었습니다!(최종 코드 참고!)
그러면 여기서 계속 바뀌는건 기준점과 종이의 길이 입니다!! 따라서 그 세가지를 매개변수로 한 재귀함수를 구현하면 됩니다.
3) 처음에 내가 구현한 코드
코드라고 할 수도 없었어요😔😔
import sys
input = sys.stdin.readline
number = int(input())
paper = []
for i in range(number):
paper.append(list(map(int, input().split())))
def color_papers(x,y):
for i in range(x):
for j in range(y):
paper[i][j]여기서 막혔습니다.. x와 y를 세로 가로 라고 했을 때 paper 2차 배열에서 저 성분하나를 어떤거랑 비교해서 색깔이 다른 걸 알아야 1/2로 쪼개서도 똑같이 이 작업을 수행하는데.. 그걸 구현을 못했습니다! 그래서 다른 답안 코드를 보면서 이해했습니다!
4) 최종적으로 수정한 코드
- 기준점을 x, y => paper[x][y]는 x행 y열 원소 입니다. 종이의 길이는 N 입니다! 이 기준점 색깔과 다른 원소를 비교해서 종이의 색깔을 판단하고 4등분을 해야할지 말아야 할지 정합니다!!
- 기준점의 색깔과 다른 원소들의 색깔이 다르면 종이를 4등분하는데, 이 때
기준점과 종이 전체 길이가 전부 바뀝니다!따라서, 계속 달라지는 x, y, N 을 재귀함수의 매개변수로 하고 함수를 만듭니다! - 기준점과 정사각형 안의 원소들
색깔이 (값이) 같으면 for문이 끝날 때 까지 if문(색깔이 같은지 다른지 판단)에 걸리지 않고 바깥 반복문을 끝내므로그때의 색깔이 어떤 건지 판단하고 + 1 해줍니다!
import sys
input = sys.stdin.readline
number = int(input())
paper = []
for i in range(number):
paper.append(list(map(int, input().split())))
white = 0
blue = 0
def color_papers(x, y, N):
color = paper[x][y]
for i in range(x, x + N):
for j in range(y, y + N):
if color != paper[i][j]:
color_papers(x, y, N//2)
color_papers(x, y + N//2, N//2)
color_papers(x + N//2, y, N//2)
color_papers(x + N//2, y + N//2, N//2)
return
if color == 0:
global white
white += 1
else:
global blue
blue += 1
color_papers(0, 0, number)
print(white, blue)