번역해보면서 공부겸 정리하면 좋아보이는 아티클 링크 하나를 추천받아 이 글을 작성하게 되었습니다.
Journey of web page
링크: https://dev.to/gitpaulo/journey-of-a-web-page-how-browsers-work-10co
번역체이기에 매끄럽지 않은 부분이 있습니다. 감안하고 읽어주시면 감사하겠습니다~ 😂
Journey of web page ✈
Networking models
네트워크 모델은 네트워크를 통해 어떻게 데이터가 전달되는지 파악하기 위해 존재한다. 특히, 이미 널리 알려져서 컴퓨터 관련업을 하지 않는 사람들조차 들어봤을만한 네트워크 모델이 있는데, 그것은 바로 OSI(Open System Interconnection) 모델이다.
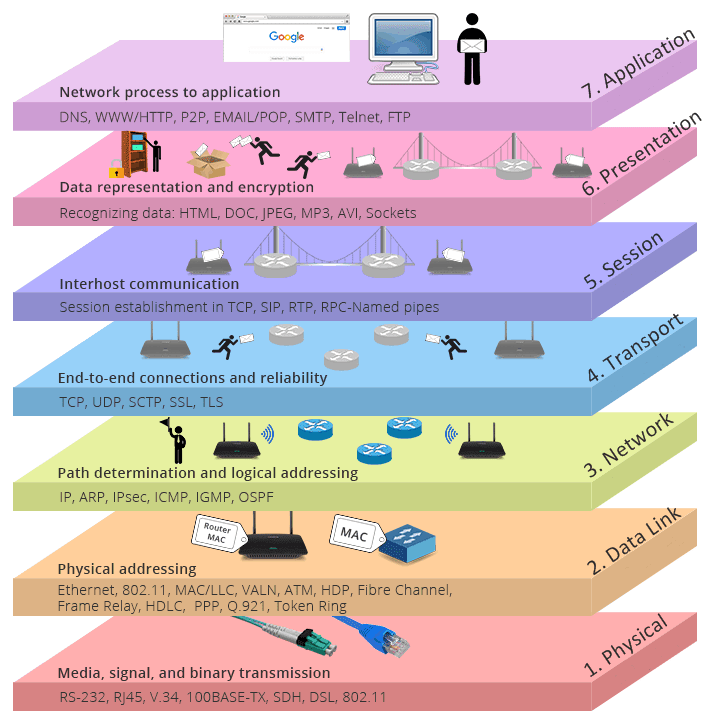
OSI는 컴퓨터 시스템이 네트워크를 통해 통신을 하는 7개의 층에 대해 다룬다. 각각의 레이어들은 이전 레이어보다 추상적으로 더 높은 레벨로 보고 이는 우리가 나중에 다룰 응용 계층까지 이어진다.
OSI 모델이 애플리케이션들이 네트워크를 통해 통신하는 방법에 대한 "개념적인 모델"이라는 것을 염두에 둘 필요가 있다. 프로토콜이 아니다. 프로토콜인지, 개념적인 모델인지에 대해 혼동하지 말자. 프로토콜은 OSI 모델의 층 내부에서 사용되는 엄격한 규약이다.
비슷한 모델 중에 TCP/IP 모델이 있다. 이 모델은 현재의 인터넷 구조를 모델링 하는 데에 사용되기도 하고 네트워크상에서 이루어지는 모든 형태의 통신에 대한 규약을 제공하기도 한다.
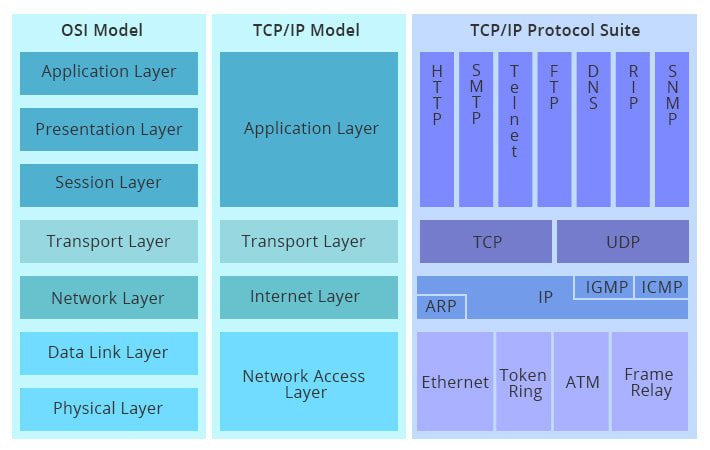
나는 이 글에서 해당 모델에 대한 내용과 이에 연관된 프로토콜들에 대해 알아보는 시간을 가질 것이다.
앞에서 암시했듯이, 애플리케이션에서 다른 곳으로 보내지는 모든 데이터들은 이 계층들을 위아래로 여러 번(가운데에 얼마나 많은 과정이 있냐에 따라 달라진다) 이동해야 한다. 물론 요즘 날에도 이러한 작업이 엄청 빠르게 일어나고 있으며, 이 과정에 대한 자세한 내용은 모든 개발자들이 알고 있어야 한다. 아래는 서버와 클라이언트 사이에서 해당 과정이 어떻게 진행되는지를 표현한 이미지다.
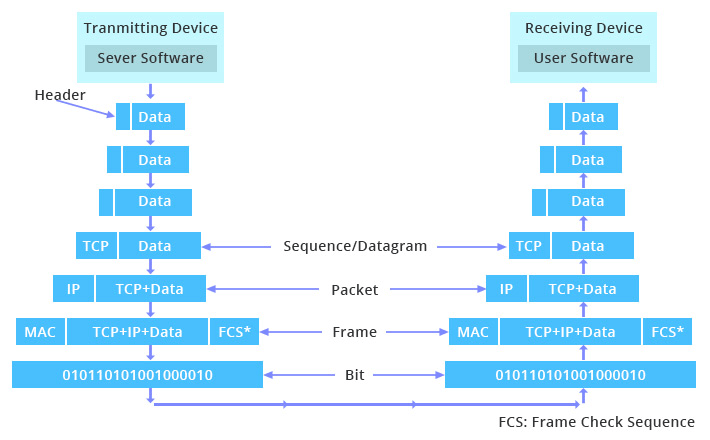
위의 그림을 살펴보자, 유저가 브라우저를 통해 해당 페이지를 탐색할 것을 요청하면: 해당 요청은 일단 첫 번째로 application layer(응용 계층)에 전달되며, 각각의 계층마다 작업을 처리하며 아래로 전달된다. 데이터는 목적지 서버 또는 다른 디바이스가 받도록 네트워크 상의 물리 계층을 통해 전달된다. 이 이후로 데이터는 웹 서버가 해당 데이터를 받아 작업을 할 수 있도록 물리 계층에서부터 모든 층을 거슬러 올라가며 각각의 층이 맡은 작업을 처리한다. 그리고 이 과정은 서버에서 응답을 할 때에도 똑같이 반복된다. 이것이 기계들이 통신을 하는 방법이다.
High-level abstraction of a browser
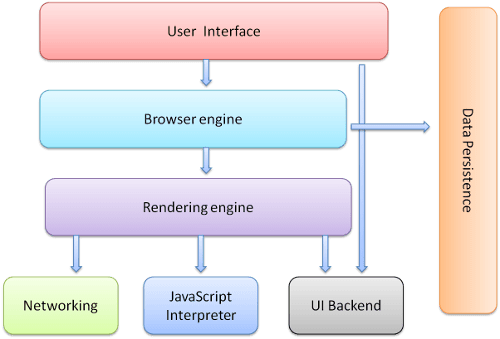
앞으로 나올 섹션들에서 다룰 내용은 브라우저가 화면에 페이지 요소를 디스플레이하는 과정이다. 브라우저에 대한 높은 수준의 이해는 앞으로 다뤄질 내용을 이해하는 데에 있어 아주 중요하다. 브라우저 구성 요소들에 대해 얘기해보자.
- The user interface(유저 인터페이스): 주소나, 뒤로 가기 앞으로가기 버튼, 북마크 메뉴 등등이 바로 유저 인터페이스다. 요청된 페이지를 볼 수 있는 window를 제외한 브라우저의 모든 부분이 이에 해당된다.
- The browser engine(브라우저 엔진): UI와 렌더링 엔진 사이에서 이루어지는 동작을 제어한다
- The rendering engine(렌더링 엔진): 요청한 내용을 띄워주는 역할을 맡는다. 예를 들면, 만약 요청한 콘텐츠가 HTML이라면, 렌더링 엔진은 HTML과 CSS를 파싱하고 그 파싱 한 내용을 스크린에 띄워준다.
- Networking: HTTP request 등 네트워크 요청에 사용되며, 각 플랫폼 하부에서 작동하며 플랫폼마다 독립적인 인터페이스를 가지고 있다.
- UI backend: 콤보 박스나 windows 등 기본적인 위젯을 그리는 데 사용된다. 플랫폼이 따로 정하지 않은 아주 기본적인 인터페이스를 사용하며, 사용자의 OS 인터페이스에 따른 인터페이스를 제공한다.
- Javascript interpreter: 자바스크립트 코드를 해석하거나 실행시키는 데 사용한다.
- Data storage: 브라우저는 쿠키 등의 데이터를 로컬 환경에 저장해야 할 때가 있다. 또한 브라우저는 localStorage, IndexedDB, WebSQL, FileSystem 등의 저장소도 지원한다. 즉 데이터를 저장하는 영역이다.
크롬과 같은 브라우저에서는 성능과 보안 이슈를 위한 멀티프로세싱 작업 방식을 가지고 있다는 것을 알아야 한다. 이는 무엇을 뜻하냐면, 브라우저들은 렌더링 엔진 등 위의 구성요소들을 각 탭에서 구동시킨다는 의미다(각각의 탭은 분리된 프로세스다). 이를 확인하고 싶다면 작업관리자를 열어 크롬의 프로세스들을 체크해보면 된다.
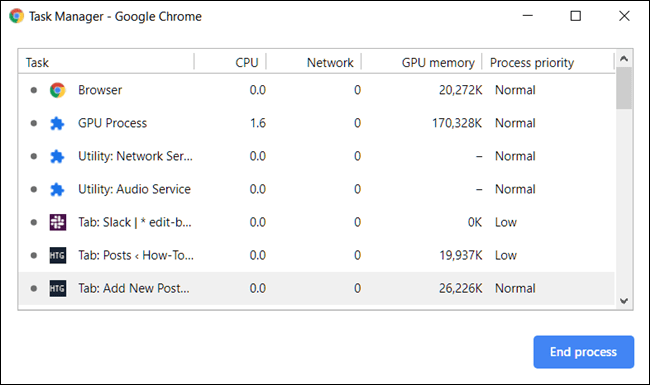
위의 사진에서 볼 수 있듯이, 각 탭들은 작업에 우선순위가 있고 CPU/Nerwork/GPU 통계를 보면 정상적으로 다 작동하는 것을 알 수 있다.
배경지식을 위한 섹션을 마무리 지어보자면, 지금까지 당신이 읽어온 것들은 네트워크와 브라우저가 어떻게 작동하는지에 대한 기본적이고 개념이다. 모든 네트워크들이 OSI/TCP IP 모델을 준수하는 것은 아니며 요즘 날 자주 사용되는 브라우저들은 각각의 방식대로 다른 점들이 있지만 기본적으로 공통되는 개념 아래에 작동한다.
예를 들면 모든 브라우저들은 W3C에서 관리하는 사양을 따르지만 렌더링 엔진들은 다 다르다. Internet Explorer은 Trident를 사용하고, Firefox는 Gecko, Safari는 Webkit, Chrome, Edge, Opera는 Webkit 계열의 Blink를 사용한다.
Journey of a page
브라우저를 열고 www.google.com을 작성하면 발생하는 작업에 대해 알아보자.
Navigation
첫 번째 작업은 올바른 장소를 찾아가는 것이다. 웹페이지를 navigate 한다는 것은 페이지의 요소들이 존재하는 곳을 찾는다는 것을 말한다. 우리에게는, 웹페이지들은 그저 도메인 이름이지만 컴퓨터 관점에서는 IP 주소로 받아들여진다.

만약 www.google.com을 탐색한다면, 페이지 내의 파일들은 93.184.216.34라는 IP 주소를 가진 서버에 존재할 것이다. 만약 한 번도 해당 사이트에 접속해본 적이 없다면, DNS lookup이 먼저 발생할 것이다
Round Trip Time
Round-trip time(왕복 시간)은 브라우저가 요청을 보냈을 때부터 서버에서 요청이 되돌아오기까지 걸리는 milliseconds 단위로 측정된 시간이다. 이는 웹 애플리케이션에서의 성능과 관련된 중요한 요소이며 Time to First Byte(TTFB), 페이지 로드 시간 및 네트워크 지연 시간을 측정할 때 사용된다.
Resolving a web address - The DNS Process(O RTT)
[www.google.com](http://www.google.com) 를 주소창에 친 이후의 과정은 아래와 같다
- 브라우저와 OS 캐시를 체크하고 IP 주소가 있으면 해당 주소를 리턴한다
- 브라우저는 로컬 DNS에 IP 주소를 요청한다
- DNS resolver 은 브라우저 캐시에 IP 주소가 남아있으면 이를 응답한다
- DNS resolver는 root DNS 서버에 해당 URL의 IP 주소를 요청한다
- 루트 DNS 서버는 최상위 도메인(TLD)이. com인 것을 확인 후 ".com"이 등록된 네임서버의 IP Address를 전달한다. 즉 com 도메인을 관리하는 DNS 서버에 문의해보라고 DNS resolver에게. com DNS 서버의 IP 주소를 알려준다.
- DNS resolver는 이제 TLD 서버에게 해당 url(www.google.com)을 문의한다.
- TLD는 루트 DNS에게 authoritative 네임서버의 IP 주소를 전달한다.
- DNS resolver은 마지막 전송을 authoritative 네임서버로 보내며 IP 주소를 요청한다
- authoritative 네임서버는 파일들을 스캔하며 도메인 이름:아이피 주소를 찾을 것이며 해당 주소가 있는지 없는지 반환해 준다.
- DNS resolver은 드디어 브라우저에게 그 브라우저가 통신하고자 하는 서버의 IP 주소를 응답해 준다.
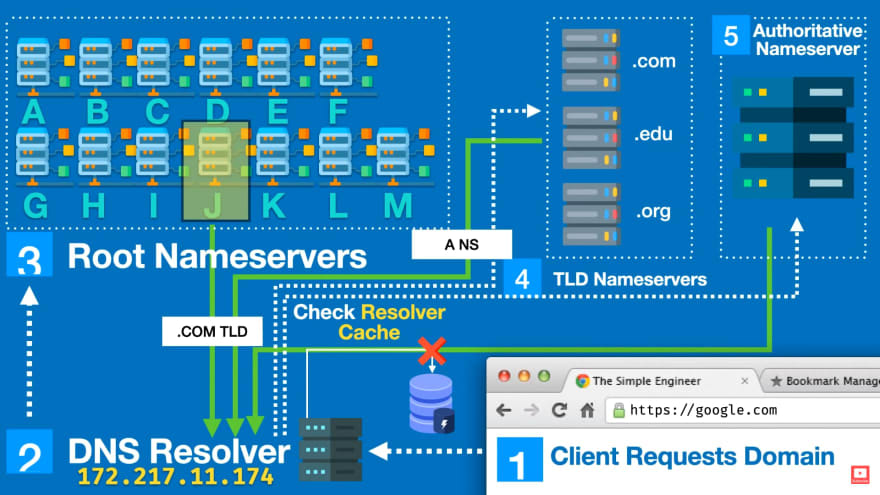
실제로 이 과정은 엄청나게 빠르며 단계마다의 캐싱 작업 덕분에 모든 과정을 하나씩 다 거치는 경우는 거의 드물다. 애초에 빠르게 작동하도록 설계되었다.
Establishing a connection to the server - TCP Handshake (1 RTT)
이제 IP 주소를 알았겠다, 브라우저는 TCP three-way handshake를 통해 서버에 연결을 설정한다.
TCP는 three-way handshake를 신뢰성이 보장된 연결을 위해 사용한다. 연결은 양방향이며 양쪽 다 서로를 synchronize(SYN 동기화) 하며 Acknowledge(ACK 확인) 한다. 이 과정은 아래의 그림에서 볼 수 있듯 세 단계에 걸쳐 진행된다(SYN, SYN-ACK, ACK).
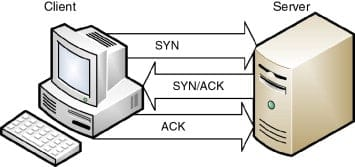
- 클라이언트는 첫 sequence number을 고르고, SYN 패킷의 맨 앞에 설정해둔다
- 서버 또한 자신의 sequence number을 고른다
- 양쪽 다 반대편의 sequence number을 확인하고 이를 +1 하여 acknowledgement number로 사용한다
연결이 성립되었을 때, 각 세그먼트에 대해 ACK가 뒤따른다. 연결은 결국 RST(리셋이나 비정상적인 연결을 끊음)나 FIN(정상적인 연결 종료)에 의해 종료될 것이다.
HTTPS는 HTTP에 암호화를 포함시킨 것이다. 두 프로토콜의 유일한 차이점은 HTTPS는 TLS를 사용하여 일반 HTTP 요청과 응답을 암호화한다는 것이다. 즉, HTTPS는 HTTP에 보안을 얹은 것이다. HTTP를 사용하는 웹사이트는 http://를 주소에 포함하고 있고, HTTPS를 사용하는 웹사이트는 https://를 포함한다.
Establishing a security protocol - TLS Negotiation (~2 RTT)
HTTPS를 통한 안전한 통신이 이루어지기 위해서는 또 다른 "handshake"가 필요하다. 이 handshake, TLS negotiation이라고도 함) 어떤 cyper을 사용하여 통신을 암호화할 건지, 서버를 확인할 건지 결정하고, 실제 데이터 전송을 시작하기 전에 안전한 통신을 할 수 있도록 설정한다.
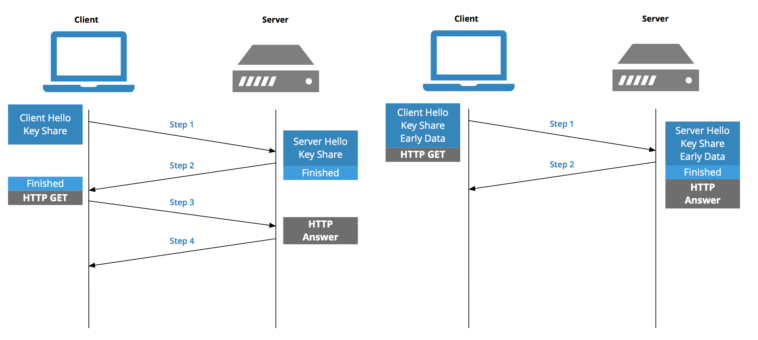
통신을 더 안전하게 하는 것은 페이지가 로딩되는 시간을 지연시키지만, 보안 연결은 브라우저와 웹 서버 간에 전송된 데이터의 암호를 제3자가 해독할 수 없기 때문에 대기 시간 비용을 들일 가치가 있다. TLS는 오늘날까지 많이 발전하여 1.3버전에서는 Round Trip Time을 4에서 2, 또는 상황에 따라 1까지도 줄이는 성과를 이루었다.
Fetching
이제 TCP 연결도 설정했고 TLS exchange도 완료되었으니, 브라우저는 페이지 자원을 불러올 수 있다. 일단 페이지의 마크업 문서를 불러오는 것부터 시작하고, 이 작업은 HTTP 프로토콜을 사용한다. HTTP 요청은 TCP/IP를 통해 전송되며 우리의 경우 TLS로 암호화된다. (google은 HTTPS를 사용함)
HTTP Request
페이지를 불러올 땐 서버의 상태를 변경시키지 않는 요청을 생선 한다. 우리는 HTTP GET 요청을 통해 이를 해결한다.
GET: URI(Uniform Resource Identifier)를 사용하여 주어진 서버에 데이터 요청을 보낸다. 데이터 상태는 변경시키지 않으며 오직 데이터를 받아오기만 한다. 요청을 여러 번 보낸다 한들 당신은 해당 데이터 자원의 상태를 변경시킬 수 없을 것이다.
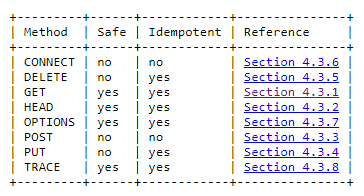
HTTP Response
웹서버가 요청을 받으면 해당 요청을 파싱하고 수행한다. 우리는 요청이 유효하며 파일에 접근이 가능한 상태라고 가정하자. 요청을 하게 되면 HTTP 응답으로 헤더와 요청한 HTML 문서에 대한 정보를 body에 담아서 보내줄 것이다.
HTTP/2 200 OK
date: Sun, 18 Jul 2021 00:26:11 GMT
expires: -1
cache-control: private, max-age=0
content-type: text/html; charset=UTF-8
strict-transport-security: max-age=31536000
content-encoding: br
server: gws
content-length: 37418
x-xss-protection: 0
x-frame-options: SAMEORIGIN
domain=www.google.com
priority=high
X-Firefox-Spdy: h2HTML 문서에 대한 소스코드는 응답의 body에 들어있다.
Parsing
브라우저가 응답을 받게되면, 받은 정보에 대한 파싱을 시작할 수 있다. 파싱은 브라우저가 네트워크를 통해 받은 데이터를 DOM과 CSSOM으로 변환시키는 작업을 말하고, 그 변환시킨 결과물을 토대로 renderer이 스크린에 페이지를 그린다.
DOM은 브라우저가 수신한 마크업 문서의 구조와 그 안의 내용을 구성하는 객체들을 아우르는 표현이다. 이것은 프로그램들이 문서 구조, 스타일, 내용을 변경시킬 수 있도록 페이지를 나타낸다.
DOM은 프로그래밍 언어로 해당 페이지에 요소들에 접근할 수 있도록 문서를 노드와 객체로 표현한다. DOM 트리에는 다양한 노드들이 존재한다. DOM Node 인터페이스에 대한 설명은 아래의 예시를 확인해보자.
Node.ELEMENT_NODENode.ATTRIBUTE_NODENode.TEXT_NODENode.CDATA_SECTION_NODENode.PROCESSING_INSTRUCTION_NODENode.COMMENT_NODENode.DOCUMENT_NODENode.DOCUMENT_TYPE_NODENode.DOCUMENT_FRAGMENT_NODENode.NOTATION_NODE
해당 노드 종류들은 문서의 모든 요소들을 다룬다. 위의 노드들을 사용하여 프로그래밍 언어로 페이지 요소들을 조작할 수 있다.
파싱에 대한 설명을 끝내기 전에, CSSOM에 대해서도 다뤄야 한다.
CSSOM은 자바스크립트 코드로 CSS를 조작할 수 있도록 해주는 API의 집합이다. 이는 DOM과 비슷하지만 DOM은 HTML을 위한 것이라면 CSSOM은 CSS를 위한 것이다. 이를 통해 유저들은 CSS 스타일을 동적으로 변경하고 읽을 수 있다. DOM 트리랑 매우 유사하게 표현되며, 렌더링 과정을 위한 렌더 트리를 형성할 때 돔과 함께 사용될 것이다. 모든 과정을 살펴보며 어떤 식으로 진행되나 알아가보자.
Building the DOM tree
첫 번째 단계는 HTML 마크업 처리를 하여 DOM 트리를 생성하는 것이다. HTML 파싱은 tokenization과 tree 구축을 포함한다.
파싱 알고리즘은 HTML5 문서에 자세하게 설명되어 있다. 앞전에 언급했듯, 알고리즘엔 두 개의 단계가 있다: tokenization과 tree construction.
- Tokenization은 어휘 분석으로, input을 토큰들로 파싱 한다. HTML 토큰들은 start 태그, end 태그, 속성명들, 속성값들 등등으로 나눌 수 있다.
- Tree construction은 파싱 한 토큰들을 트리구조로 만들어 돔트리를 형성하는 것이다.
DOM 트리는 문서의 구조를 표현한다. <html> 요소는 첫 태그이자 돔 트리의 루트 노드가 된다. 트리는 각각의 태그들의 관계와 계층구조를 표현한다. 다른 태그로부터 뻗어 나온 태그는 자식노드가 된다. DOM노드가 많으면 많을수록 DOM트리를 형성하는 데 오래 걸린다. 아래의 그림은 파싱한 결과를 DOM트리로 그려낸 예시다.
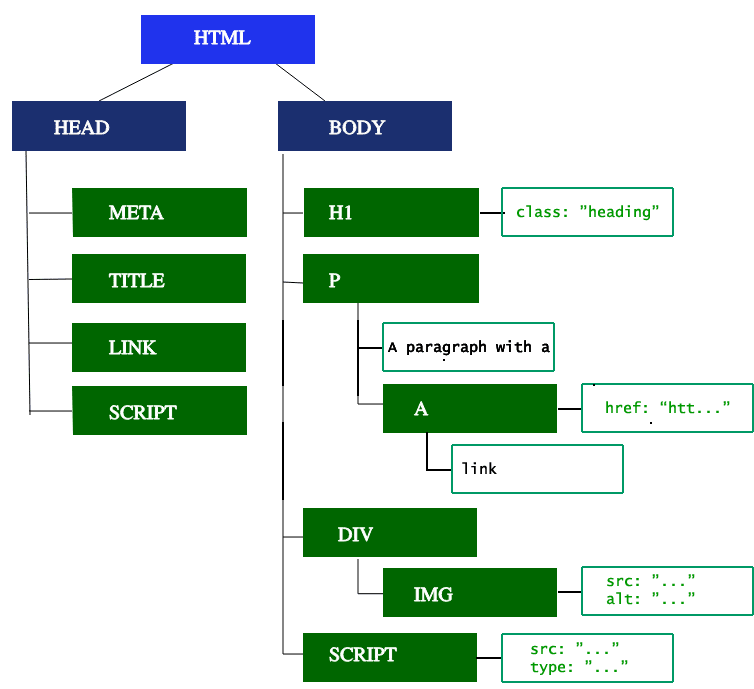
파서가 진행을 막지 않는 요소들, 예를 들면 이미지를 만나면, 브라우저는 해당 자원을 요청하고 계속해서 파싱을 진행할 것이다. 파싱은 CSS 파일을 만나더라도 계속해서 진행이 되지만 script 태그를 만나면(부분적으로 async나 defer 속성을 가지고 있는) HTML 파싱을 멈추고 렌더링을 막는다. 물론 브라우저의 preload 스캐너는 이 과정을 엄청 빠르게 수행하지만, 과도한 script는 큰 병목현상을 발생시킨다.
Building the CSSOM tree
두 번째 순서는 CSS를 처리하여 CSSOM 트리를 구축하는 것이다. DOM 파싱과 비슷하게, 브라우저는 CSS 요소 하나하나를 분석하며 CSS Selector에 맞게 부모, 자식, 형제 노드들을 포함한 트리를 형성한다.
HTML처럼, 브라우저는 전달받은 CSS를 직접 다룰 수 있도록 변환하는 작업을 거쳐야 한다. 여기서부터는 HTML에서 객체를 형성할 때 수행한 작업을 CSS에도 적용하면 된다.
Combining the trees into the render tree
CSSOM과 DOM 트리가 하나의 렌더 트리로 합쳐지면 해당 렌더 트리는 각 요소의 레이아웃을 계산하는 데 사용되며, 계산한 결과물은 픽셀을 스크린으로 그려주는 작업에 사용된다.
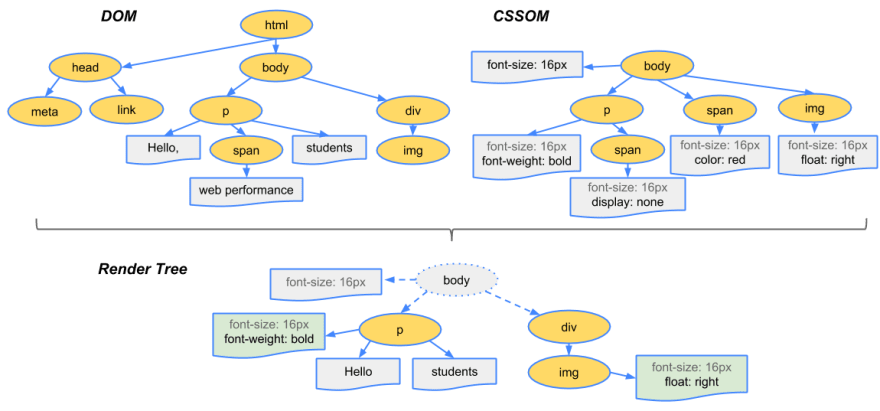
렌더 트리를 구축하기 위해서 브라우저는 아래와 같은 작업을 수행한다:
-
돔 트리의 루트부터 시작하여 각각의 노드들을 탐색한다
-
몇몇 노드들(예를 들어 script 태그, meta 태그 등)은 보이지 않으며, 렌더링 결과에 반영되지 않으므로 생략된다.
-
몇몇 노드들은 CSS를 통해 숨겨지며, 이 또한 렌더 트리에서는 생략된다. 예를 들면, sapn 노드는
display: none속성이 적용되었기에 렌더 트리에서 생략된다. -
visible 노드들은 각각에 맞는 CSSOM 룰을 매칭하여 적용시킨다.
-
콘텐츠 및 계산된 스타일을 사용하는 노드들은 렌더 트리에 추가한다
마지막은 화면에 모든 콘텐츠와 스타일 정보를 가지고 렌더링 하는 것만 남았다. render 트리를 사용하여 layout 단계로 넘어갈 수 있다.
Preload Scanner
브라우저의 메인스레드가 돔트리를 구축할 때 해당 요소들을 스캔해주는 보조 스캐너가 존재한다. 이 보조 스캐너는 preload scanner이라고 부르며, CSS, JavaScript, 웹 폰트 등을 우선적으로 불러오는 역할을 한다. 이는 파서가 해당 자료의 의미를 분석면서 해당 노드가 필요한 데이터를 불러오는 작업까지 하기엔 너무 오래걸리기에 파싱 작업에 추가된 과정이다.
<link rel="stylesheet" src="styles.css"/>
<script src="myscript.js" async></script>
<img src="myimage.jpg" alt="image description"/>
<script src="anotherscript.js" async></script>위의 예시를 보면, preload scanner은 스크립트와 이미지를 찾아내고 그것을 다운로드한다. html을 통해 preload 스캐너와 통신을 할 방법이 있는데, 그것은 async와 defer이라는 속성이다.
async: async속성을 만나면 스크립트가 준비되는 순간 바로 실행시킨다defer: defer속성을 만나면, 스크립트를 페이지 파싱이 완료되면 실행시킨다
CSS를 얻기 위해 기다리는 작업은 HTML파싱과 다운로드를 막지 않지만 JavaScript는 간혹 DOM 객체에 CSS를 불러와서 조작하는 경우가 있기에 막힌다.
JavaScript Compilation
CSS가 파싱되어 CSSOM이 생성되었을때, JavaScript 파일을 포함한 다른 요소들은 다운로드되기 시작한다(preload scanner를 통해). JavaScript는 해석, 컴파일, 파싱 작업 후 실행된다.
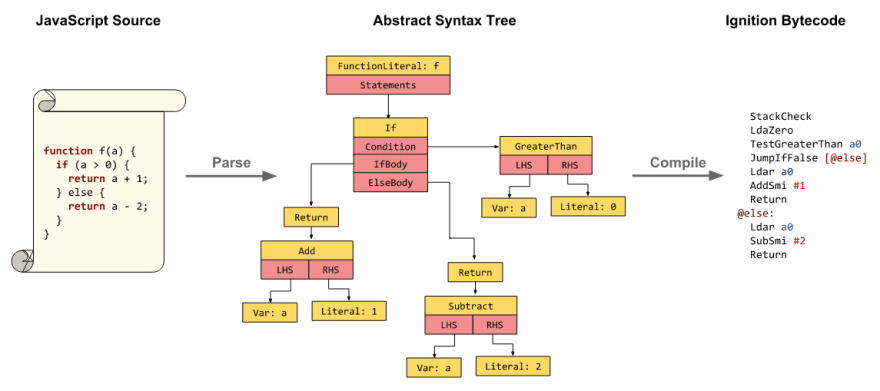
스크립트는 abstract syntax tree(추상구문트리)로 파싱된다. 위의 사진에서 볼 수 있듯, 몇몇 브라우저 엔진은 추상구문트리를 해석기에 넘기고 메인스레드에서 실행될수있도록 bytecode로 변환시킨다.
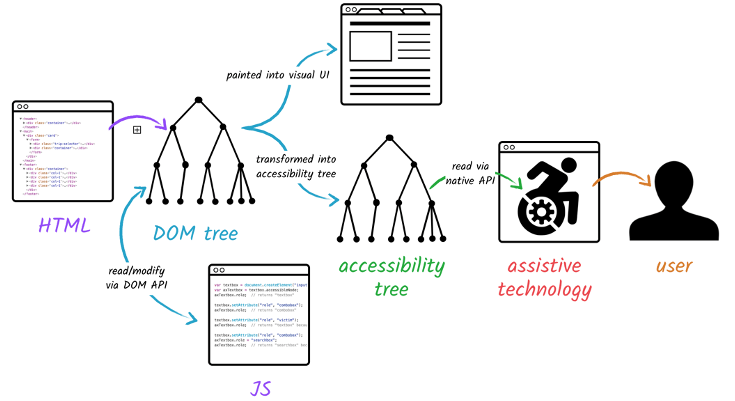
Building the Accessibility Tree
브라우저는 assistive device가 컨텐츠를 파싱하고 해석하는 데에 쓸 수 있는 accessibility tree를 구축한다. AOM(accessibility object model)은 DOM의 시멘틱 버전이라고 보면 된다. 브라우저는 DOM이 업데이트되면 accessibility tree를 함께 업데이트 해준다.
Rendering
모든 정보가 파싱 되었으니 브라우저는 이제 해당 정보를 화면에 띄워줄 수 있다. 이를 위해선 브라우저는 render tree를 사용하여 문서를 시각화할 것이다. 렌더링 과정은 레이아웃, 페인트, 또는 둘을 합치는 과정을 포함한다.
Critical Rendering Path
Critical Rendering Path에 대해 소개하기 좋은 타이밍인 것 같다. 이를 시각화하기 좋은 방법은 그림을 그려보는 것이다.
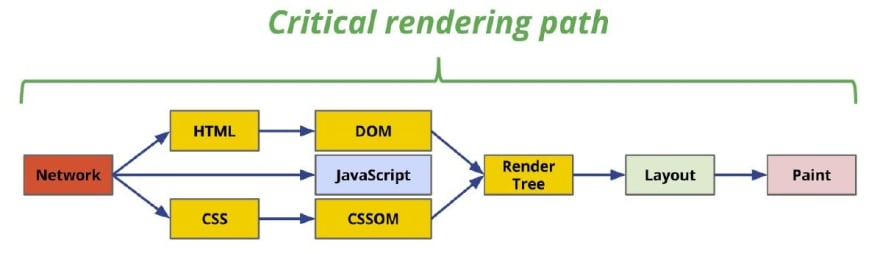
critical rendering path를 최적화하는 것은 첫 렌더링까지 걸리는 시간을 줄여준다. 초당 60프레임을 기준으로 리플로우와 리페인트가 발생하도록 하는 것이 중요하다.
우리는 CRP를 최적화하는 세부적인 내용에 대해 다루진 않을 거지만, 최적화에 대한 기본적인 요점은 로드되는 리소스의 우선순위를 지정하여 페이지 로드 속도 향상시키고, 해당 리소스의 크기를 줄이는 것이다.
그럼 바로 렌더링 단계로 넘어가 보자
Layout
레이아웃은 첫 번째 렌더링 과정이고, 이 과정에서 렌더 트리의 노드들의 기하학적인 배치, 위치가 정해진다. 렌더 트리가 구축되면 레이아웃이 시작된다.
레이아웃은 재귀적인 작업이다. 루트 요소 <html>부터 시작하여 계층적으로 내려가며 재귀적으로 각 요소들의 기하학적 정보를 계산한다.
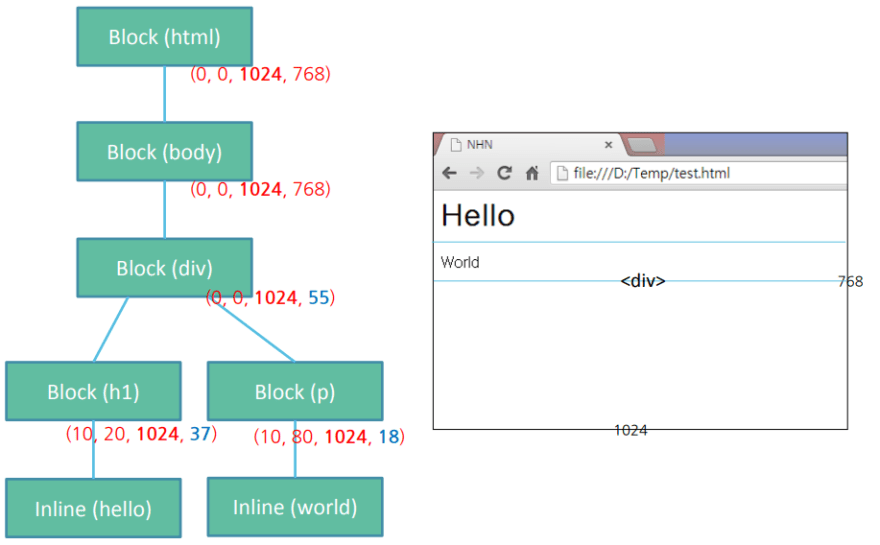
레이아웃 단계가 끝나면, 우리가 블록, 박스라고 부르는 노드들이 위와 같은 형태로 형성된다. 블록과 박스는 DOM 객체와 노드들의 기하학적 정보를 지니고 있다.
Dirty bit system
작은 변화로 인해 모든 레이아웃을 다시 그릴 필요가 없도록, 브라우저는 "dirty bit"시스템을 사용한다. 변화가 생긴 renderer들은 자기 자신과 자신의 하위 요소들에 "dirty"마크를 남긴다.
두 가지 플래그가 존재한다:
- dirty: 노드에 레이아웃 과정이 필요함
- children are dirty: 노드에 레이아웃 과정이 필요한 최소 하나 이상의 자식 노드가 존재함
Layout Algorithm
dirty bit 시스템을 사용하면 브라우저는 layout을 형성하는 알고리즘을 수행할 수 있다.
- 부모 노드가 자기 자신의 width를 결정한다
- 부모 노드가 자식 노드를 탐색하며
- 자식 노드의 렌더 사이즈를 계산한다
- dirty descendant가 있다면 해당 자식 노드를 호출한다
- 부모 노드는 자식 노드의 높이와 마진 값, 패딩 값을 계산하여 자신의 크기를 설정한다. 해당 설정값은 부모 노드의 부모 노드를 그릴 때에 사용된다.
- dirty bit를 false로 설정한다
추가된 중요한 개념은 리플로우에 대한 개념이다. 이전에 언급했듯, 최초로 노드의 크기나 위치가 결정되는 작업을 레이아웃이라고 부른다. 노드의 크기나 위치에 대한 후속적인 재계산들은 리플로우라고 부른다. 예를 들어, 첫 레이아웃 과정이 이미지가 반환되기 전에 실행되었다고 해보자. 이미지의 크기가 지정되지 않았기에, 이미지의 크기가 계산되면 다시 리플로우가 발생할 것이다.
Paint
렌더링의 세 번째이자 마지막 과정이다. 페인팅 단계에서는 브라우저는 레이아웃 과정에서 계산된 모든 박스들을 실제 픽셀 값으로 변환시켜 화면에 나타낸다. 페인팅 과정에는 화면에 모든 요소들, 텍스트, 색깔, 테두리, 등을 그리는 작업과 버튼, 이미지 등을 배치하는 작업을 포함한다. 브라우저는 이를 엄청 빠르게 실행해야 한다.
Painting order
CSS2 문서에서는 페인팅 과정에 대한 정의가 되어있다. 이 명세에는 staking context에 요소들이 쌓이는 순서를 명세한다. 이러한 순서는 뒷 요소로부터 앞으로 진행되기 때문에 페인팅할때 영향을 준다. 블록 renderer에서의 스택 순서는 다음과같다.
- background color
- background image
- border
- children
- outline
Paint layers
페인팅은 레이아웃 트리의 요소들을 여러 레이어로 쪼갠다. 각 요소들을 GPU의 layer로 쪼개는 작업은 페인트, 리페인트 작업을 향상시킨다. video, canvas, CSS속성에 opacity나 3D transform을 가지고있는 요소들과 같이 레이어를 인스턴스화하는 특정 속성과 요소들이 있다. 이 노드들은 그 노드가 지닌 자신들만의 고유 layer에 자식 노드들과 함께 그려질 것이다.
Layer은 성능을 상승시키지만 메모리 관리에 있어서는 큰 비용이 들기 때문에 성능 최적화 를 위해 재사용되어야한다.
Compositing
문서의 각 섹션들이 서로 다른 layer로 그려져 서로를 겹치게 된다면, compositing은 올바른 순서로 해당 요소들이 스크린에 그려졌다는 것을 체크한다.
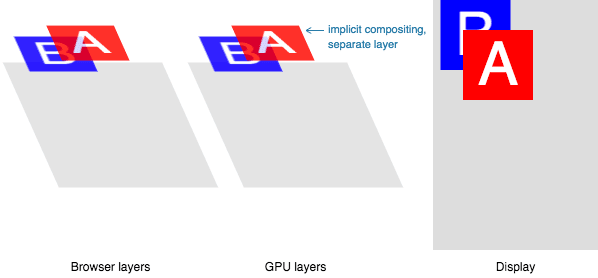
페이지가 요소들을 계속해서 불러올 때마다, 리플로우는 발생할 수 있다. 리플로우는 리페인트와 리컴포짓을 발생시킨다. 만약 이미지의 크기를 정의해둔 상태였다면 리플로우가 필요 없을 것이며, 다시 리페인트 되어야 할 부분만 페인팅 될 것이다. 하지만 이미지 크기를 미리 지정하지 않았다면? 서버로부터 이미지가 도착한다면 렌더링 과정은 다시 layout 단계로 되돌아가 모든 것을 재실행하게 된다.
Finalising
메인스레드가 해당 페이지를 다 그리면, 다 끝났다고 생각할 것이다. 하지만 항상 그런 것은 아니다. 만약 defer속성이 붙은 JavaScript를 불러와서 onload 이벤트가 발동해야지만 모든 것이 실행된다면 메인스레드에 작업이 추가되어 스크롤, 터치, 등 인터렉션을 하지 못하게 된다.
JavaScript Occupied
Time to Interactive(TTI)는 첫 요청에서부터 DNS룩업, SSL 연결을 거쳐 첫 페이지가 로딩되어 유저가 해당 페이지에 클릭 등의 인터렉션을 할 수 있을 때까지 걸리는 시간을 의미한다. 메인스레드가 파싱, 컴파일링, 또는 JavaScript를 실행하고 있다면 사용자 인터렉션에 응답할 수 없다.
예를 들어, 이미지가 빠르게 로딩되었지만 something.js파일이 느린 네트워크 연결로 인해 다운로드가 진행되는 상황이라고 보자. 이 경우에 유저는 페이지 자체는 빠르게 받아볼 수 있지만 스크립트 하일이 다운로드되고 파싱되어 실행되기 전까지 스크롤은 할 수 없을 것이다. 아래의 이미지 예시처럼 메인스레드의 사용을 피해보자.
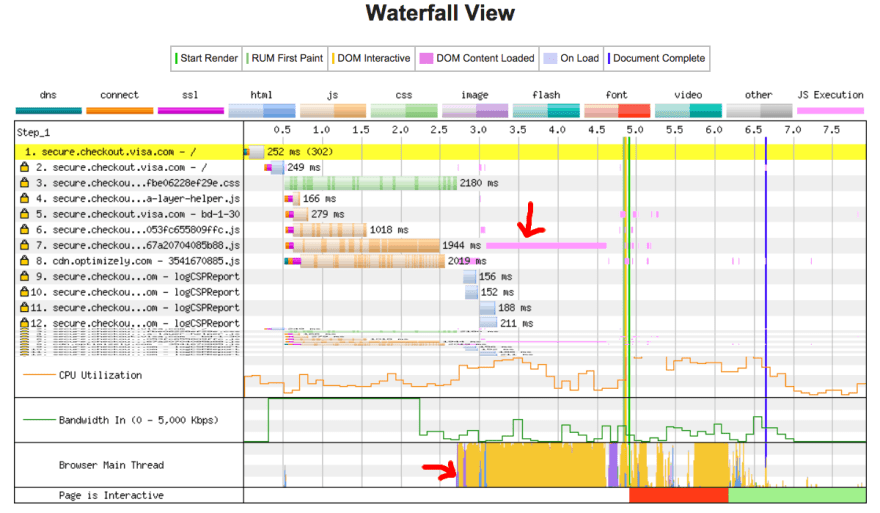
위의 예시는, DOM content load 과정이 1.5초가 걸렸고 메인스 레드가 1.5초 동안 작동하며 클릭 이벤트나 스크린 탭 등의 작업을 할 수 없게 된다.
드디어 유저는 페이지를 탐색할 수 있게 된다! 🎉
지금까지의 모든 과정을 통해 유저는 페이지를 볼 수 있고 작업을 수행할 수 있다.
요약:
페이지가 브라우저에 나타나기 전까지 거쳐야 할 과정들:
- DNS Lookup: 웹 주소의 ip를 찾기 위한 과정
- TCP Handshake: 클라이언트나서버 사이의의 TCP/IP 통신을 설정하는 작업
- TLS Handshake: 암호화를 통해 정보를 보호하는 과정이 추가된 버전
- HTTP communication: 브라우저가 이해할 수 있는 방법으로 통신을 하는 과정
- Browser Parsing:HTTP 요청을을파싱 하는는 과정 - 페이지의 문서가 나타난다
- Browser Rendering: 브라우저의 윈도우에 해당 문서를 띄워준다
- JavaScript Occupied: JS가 메인스레드를 독점할 수 있기에 다 컴파일할 때까지 기다리고 실행시키는 과정
위와 같이 몇 개 안되는 과정에서 엄청난 작업들이 수행되어야 한다는 것은 놀라운 사실이다. 작은 페이지에서 이루어지는 엄청난 과정이라고 볼 수 있다.

와 양도 많고, 봤던 책보다 훨씬 딥한거같네요! 몇 번 다시 읽어봐야겠어요 ㅎㅎ 엄청 고생했네요 젠 ㅎㅎ