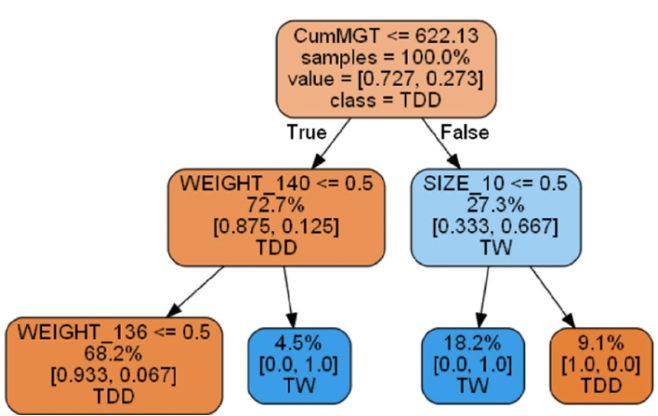
Decision Tree의 기본적인 원리
- 데이터를 분석하여 이들 사이에 존재하는 패턴을 예측 가능한 규칙(Rules)들의 조합으로 나타냄
- 모양이 ‘나무’와 같다고 해서 의사 결정 나무라고 불림
- 질문을 던져서 대상을 좁혀 나가는 ‘스무고개’ 놀이와 비슷한 개념
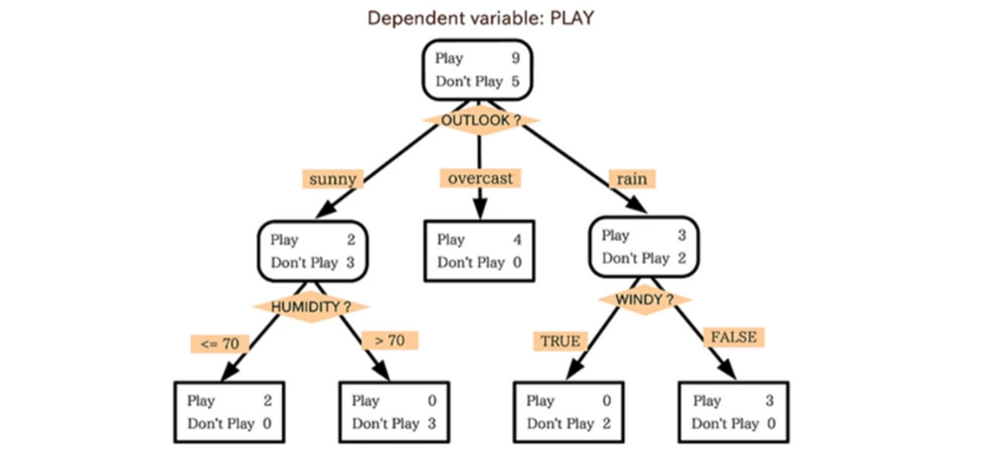
Model Complexity
- Linear Regression과 다르게 Model의 Complexity를 극한으로 높일 수 있음 (Overfitting이 일어날 수 있음)
- 아래 예제와 같이 만약 Terminal node 수가 3개 뿐이라면 새로운 데이터가 100개, 1000개가 주어진다고 해도 의사결정나무는 정확히 3 종류의 답(Rule)만을 출력하게 됨
Classification Measuring Impurity for Split
- 순도(Homogeneity)를 최대로 증가시키는 방향
- 불순도(Impurity) 혹은 불확실성(Uncertainty)을 최소로 감소시키는 방향
- Measuring Impurity 1: Gini Index (Max 0.5, 0일 때 가장 잘 나누어진 것)
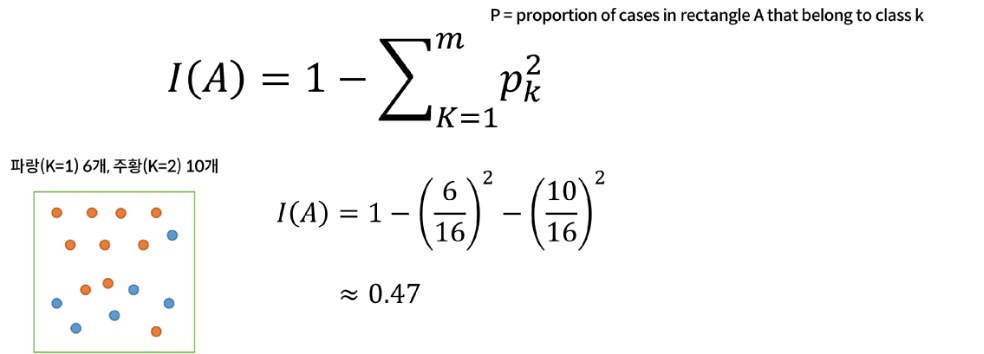

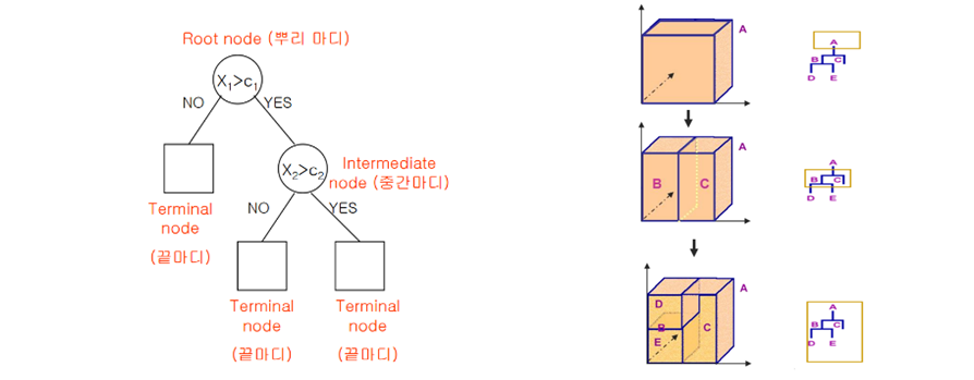
Decision Tree Split 하는 원리
- First Step은 불순도가 가장 낮은 Feature와 포인트를 찾음
- 이 포인트가 Root Node가 되는 것
- 그 후 Information gain이 가장 큰 포인트를 찾아서 Split을 진행함

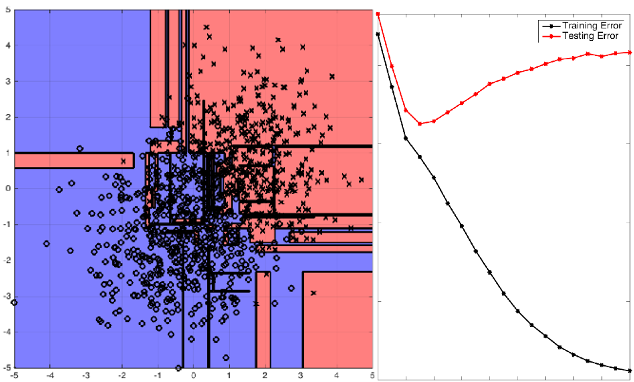
Decision Tree 100% Purity, 0% impurity
- 무한히 Partitioning (Split)을 하게 되면 100% Purity, 0% impurity가 됨
- Overfitting 발생
Decision Tree Pruning
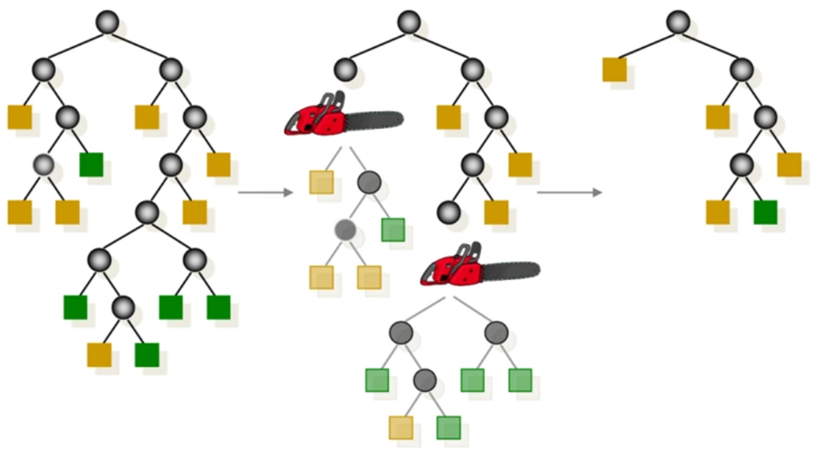
- 모든 Terminal node의 불순도가 0, 순도가 100%인 상태를 Full Tree라고 정의함
- Full tree를 생성한 뒤 적절한 수준에서 Terminal node를 잘라 줘야함
Decision Tree의 장점
- Rule Extraction: 가장 중요하고 강력한 해석력을 가짐
- Simple 하지만 직관력이 있음: Simple is the Best
- Model이 복잡해 질수록 해석력은 현저히 떨어지게 됨