Title : π0.5: a Vision-Language-Action Model with Open-World Generalization (CoRL 2025)
논문 링크 : https://arxiv.org/pdf/2504.16054
blog: https://www.pi.website/blog/pi05

1. Introduction
-
Open-world Generalization 필요성
- 로봇 시스템(로봇 암, 휴머노이드 등)이 연구실을 벗어나 실제 환경의 다양성과 예기치 못한 돌발 상황을 처리할 수 있어야만 진정으로 유용해짐
- 최근 대규모 데이터 스케일링을 통해 NLP나 컴퓨터 비전 분야는 눈부신 일반화 성능을 달성했으나, 로봇 공학에서는 단순히 데이터 규모를 키우는 것 이상의 혁신적인 학습 레시피가 요구됨
-
현실 세계 가옥 청소 작업의 복잡성과 한계
- 미지의 주방을 청소하는 작업은 여러 계층의 추론과 일반화가 동시에 필요함.
- 일부 단순 행동(칼이나 접시 집기)은 데이터가 많으면 쉽게 일반화되지만, 새로운 시퀀스로 기존 기술을 변형, 결합하거나 환경의 의미론(어느 서랍을 열어야 하는지, 건조대가 어디인지 등)을 사전 지식 바탕으로 이해해야 하는 고차원적 한계가 존재
- 이러한 복잡한 시나리오를 데이터 수집의 물리적 확장만으로 해결하는 것은 불가능에 가까움
-
인간의 인지 방식에서 착안한 해결채(이종 데이터 전이)
- 인간은 새로운 환경의 문제를 직접 겪은 경험뿐만 아니라 타인의 이야기, 책에서 읽은 지식, 다른 맥락의 경험 등 다양한 정보 소스(Information Sources)를 종합하여 솔루션을 도출함.
- 로봇 역시 직접적인 조작 경험 외에 타 로봇 플랫폼의 데이터, 인간의 언어 지시, Web에 존재하는 데이터 등 이종(Heterogeneous) 소스로부터 지식을 전이받아야 함.
-
VLA(Vision-Language-Action) 모델의 기회
- 다양한 데이터 양식(Modality)을 동일한 시퀀스 모델링 프레임워크(Sequence Modeling Framework)로 캐스팅할 수 잇는 VLA의 유연성 덕분에 이종 데이터의 Co-training이 기술적으로 가능해짐.
-
모델의 데이터 구성 및 성과
- 압도적인 외부 데이터 비중: 전체 학습 데이터 중 실제 가옥에서 수집된 모바일 매니퓰레이터 데이터는 약 400시간에 불과하며, 첫번째 단계 학습 예시의 97.6%는 타 로봇 데이터나 Web 데이터 등 외부 소스로 채워짐
- 일반화 성공: 그럼에도 불구하고 는 이종 지식 전이를 통해 학습에 전혀 사용되지 않은 새 가옥에서 수건 거기, 침대 정리 등 정밀한 작업을 수행하며, 10~15분 길이의 Long-horizon task를 성공적으로 완수함.
-
Simple Hierarchical Architecture 설계
- 1단계(사전 학습): 이종 작업의 혼합 풀에서 모델을 광범위하게 사전 학습함
- 2단계(사후 Fine-tuning): 연속적인 Low-level action 과 High-level action(하위 Sub task 라벨 추론)을 동시에 학습시킴
- 추론 메커니즘: Inference 시 모델은 먼저 Observation을 보고 "배개 재배치하기"같은 Subtask를 추론하고, 이 Subtask에 기반하여 실제 로봇 관절을 움직이는 Action chunk를 추론함
- 이 구조를 통해 low-level 제어는 단순한 고정형 로봇 데이터의 이점을 얻고, high-level 추론은 web 데이터와 human supervise 의 language instruction으로부터 지식을 흡수하는 이원화 효과를 누림.
-
Contribution
- 고도의 일반화가 가능한 VLA모델인 를 제안
- 적절히 고안된 이기종 데이터 분포를 학습할 때 로봇의 일반화 능력이 발현될 수 있음을 개념적으로 증명
- E2E 학습 로봇이 새로운 가옥 안에서 부엌/침실을 청소하는 Long-horizon task를 수행가능

2. Preliminaries
-
Imitation Learning 기반의 VLA 모델 학습
- VLA모델은 일반적으로 로봇의 다양한 데모(시연) 데이터셋 를 활용해 Imitation Learning으로 훈련됨
- 학습의 목표는 Language instruction 과 현재 상태의 Observation 가 주어졌을 떄, 올바른 로봇의 행동 (또는 Action chunk )가 나올 Log-likelihood를 최대화하는 것
Log-likelihood : Likelihood는 모델이 예측한 확률 분포가 실제 정답 데이터와 얼마나 잘 부합하는지 나타내는 가능성. 여기에 Log를 씌우는 이유는 복잡한 확률들의 곱셈 연산을 덧셈으로 바꾸어 컴퓨터가 더 쉽고 안정적으로 계산(최적화)할 수 있도록 만들기 위함.
-
로봇의 Observation 의 정의
- VLA 모델에 입력되는 관측 데이터 는 일반적으로 다음과 같은 두 가지 핵심 요소로 구성됨.
- 하나 이상의 카메라로부터 들어오는 이미지 시퀀스()
- 로봇 관절의 현재 위치와 그리퍼 상태 등을 담고 있는 고유 수용 감각 정보(, Proprioceptive State)
Proprioceptive State: 로봇 관절 모터의 각도, 로봇 팔 end-effector의 위치, 그리퍼의 개폐 상태 등을 의미, 시각 정보와 결합하여 정밀한 제어를 가능하게 함.
- VLA 모델에 입력되는 관측 데이터 는 일반적으로 다음과 같은 두 가지 핵심 요소로 구성됨.
-
Transformer 백본과 토큰화(Tokenization)
- VLA 아키텍처는 최신의 LLM 및 VLM의 설계를 그대로 계승함
- 모델은 각 입력 양식(Modality)에 특화된 토크나이저를 사용하여 텍스트, 이미지, 로봇 상태를 Discrete 또는 Continuous 토큰 표현으로 매핑
- 인코딩된 관측, 지시어, 액션 토큰들은 대규모 Autoregressive Transformer 백본에 입력되어 차례대로 다음 토큰을 예측하는 방식으로 처리됨.
- Weights는 대규모 인터넷 데이터로 먼저 학습된 Pre-trained VLM의 값으로 초기화되어 사용됨.
Tokenization: 글자, 이미지, 로봇 관절값 등 서로 다른 형태의 원본 데이터를 AI 모델(Transformer)이 이해하고 연산할 수 있도록 일정한 단위의 토큰(숫자 혹은 벡터)으로 쪼개고 변환하는 과정
Autoregressive: 이전에 자신이 출력한 토큰(단어나 액션)을 다시 다음 step의 입력으로 사용해 가면서 순차적으로 시퀀스를 생성해 나가는 모델 작동 방시그 ChatGPT가 답변을 한 글자씩 생성해 내는 것과 같은 원리
-
Continuous Action 표현을 위해 발전된 Decoding
- 이미지와 텍스트 입력을 처리하는 토크나이저는 표준 VLM 방식을 그대로 따름.
- 반면 로봇의 액션을 표현하기 위해 기존 연구들은 압축 기반의 토큰화 접근법(예; FAST 토크나이저)를 개발하여 사전 학습에 활용해 왔음
- 최근 VLA 모델들은 연속적인 값을 가진 Action chunk 상에서 더욱 풍부하고 정밀한 표현력을 확보하기 위해 Diffusion 또는 Flow Matching 기술을 도입하여 액션 확률 분포를 표현함.
Diffusion 및 Flow Mathcing:
이미지를 생성하는 AI처럼, 무작위 노이즈(오염 상태)에서 출발해 단계적으로 노이즈를 걷어내며(Denoising) 고품질의 정답을 생성해 내는 생성형 AI기법, 로봇 공학에 이를 적용하면, 투박하고 딱딱한 고정값이 아니라 매우 정밀하고 유연하며 자연스러운 연속적 물리 제어 trajectory를 부드럽게 생성해 낼 수 있음.
-
Flow 모델의 계승 및 'Action Expert'
- 본 연구의 Post-training 단계는 액션 분포를 Flow mathcing 기법으로 표현하는 모델의 핵심 설계를 기반으로 구축
- Flow matching 토큰들은 이전 단계에서 부분적으로 Denoising 된 액션을 입력으로 받아 Flow matching vecter field를 출력함.
- 특히 이 과정에서 모델은 MoE 구조와 유사하게 Action 생성만을 전담하여 전문적으로 처리하는 Action Expert라는 별도의 모델 Weight Layer를 사용함
- 해당 Action Expert는 LLM 백본에 비해 크기가 훨씬 작게 설계될 수 있어 계산 효율성이 매우 뛰어남(300M)
3. The Model and Training Recipe
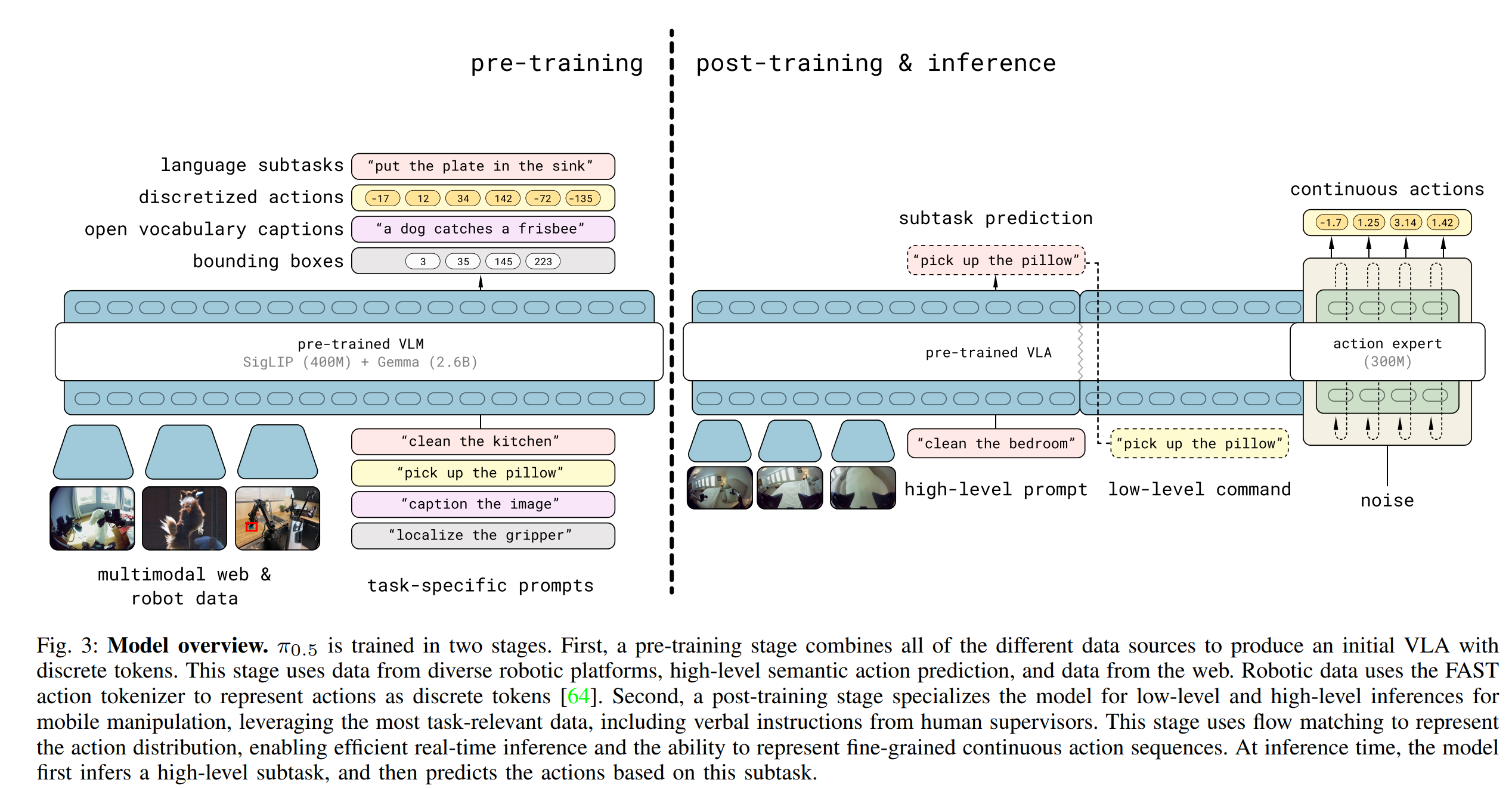
-
학습 단계의 개요
- 모델 가중치는 인터넷 데이터로 Pre-trained된 VLM인 PaliGemma로 초기화됨.
- 이후 학습은 크게 두 단계로 진행됨.
- 1단계: 사전 학습(Pre-training) - 모델을 다양한 로봇 조작 및 Web 기반 데이터셋에 적응시키는 단계
- 2단계: 사후 학습(Post-training) = 모델을 모바일 매니퓰레이션(이동형 양손 조작)에 특화시키고 실시간 Inference 제어 메커니즘을 결합하는 단계
-
Architecture
- 확률 분포 Decomposition
- 모델이 모델링하는 전체 확률 분포는 로 표기됨.
- : 다중 카메라 이미지 및 로봇 Proprioception
- : 최종 작업 프롬프트(예: "설거지 해줘")
- : 모델이 출력하는 텍스트(Subtask)
- : 예측된 저수준 액션 청크
- 수학적으로 이 분포를 High-level 추론과 Low-level 추론으로 다음과 같이 분해함
- 즉, 동일한 단일 Transformer 모델이 High-level text 생성(Subtask, )과 Low-level Action 추론()를 모두 담아내도록 설계
- 모델이 모델링하는 전체 확률 분포는 로 표기됨.
- 멀티모달 토큰 처리 및 Attention Masking
- 입력 데이터 은 텍스트 토큰, 이미지 패치, 그리고 Flow matching continuous action token으로 구성되며, 각 타입에 맞는 전용 인코더나 Expert Weights를 통과함.
- 단방향 정보 흐름과 Leakage 방지:
- 이미지, 텍스트 프롬프트, 로봇 상태 토큰들 사이에는 Bidirectional Attention을 허용
- FAST 액션 토큰은 앞선 이미지/프롬프트 토큰들과 자기 이전의 액션 토큰들만 바라보는 Causal Attention을 사용함.
- 결과적으로 VLM 백본에서 Action Expert쪽으로만 정보가 Directional로 흐르게 설계됨
- 확률 분포 Decomposition
-
Combining discrete & continuous action representations
- 하이브리드 액션 학습의 필요성
- Action을 discrete token(FAST 등)으로 표현하면 대규모 VLA 사전 학습이 매우 빨라지지만, 추론 시 글자를 한 자씩 뽑듯 한 스텝씩 De-noising해야하므로 실시간 제어(Real-time inference)에 불리함
- 반면 Flow matching을 이용해 Continuous한 값을 한번에 De-nosing하면 Real-time inference에는 적합하지만 초기 대규모 학습이 까다로움
- 는 이 두가지 장점을 결합하여, 사전 학습때는 Action을 텍스트 토큰으로 매핑하여 안정적으로 배우고, 사후 학습때는 연속형 액션을 예측하는 소형 Action expert Layer를 추가함.
- Combined Loss
- 모델은 Discrete token 예측과 Flow matching 오차를 동시에 최소화하는 하이브리드 Loss Function을 최적화함.
Cross Entropy Loss(H): Classification이나 text 생성에서 모델이 예측한 정답 확률 분포와 실제 정답 분포 사이의 차이를 측정하는 지표, 여기서는 FAST 토큰으로 표현된 discrete action과 subtask를 정확하게 맞추기 위해 사용
Flow matching 최소화(): 실제 목표 물리 trajectory(Action Vector Field)와 Flow matching을 담당하는 Action expert()가 예측한 vector값 사이의 거리(제곱 오차)를 구하는 수식, 이 오차가 줄어들수록 로봇의 Continuous trajectory가 부드러워짐.(는 두 손실간의 균형을 맞추는 가중치 파라미터)
- 하이브리드 액션 학습의 필요성
-
Pre-training

- 모델은 280k(28만) gradient step동안 다음의 이종 데이터를 섞어 다음 토큰 예측 방식으로 기본 뼈대를 학습
- MM(Diverse Mobile Manipulator data): 실제 가정집 100여 곳에서 수집된 400시간 상당의 모바일 매니퓰레이터 데이터로, 최종 목표 작업과 가장 직결되는 핵심 데이터
- ME(Diverse Multi-Environment non-mobile robot data): 고정형 싱글/듀얼 로봇 암을 통해 더 많은 집안 환경에서 수집한 데이터로, Embodiment는 다르지만 환경적 다양성을 크게 넓혀줌
- CE(Cross-Embodiment laboratory data): 실험실 내 Tabletop 환경에서 수집된 단순 반복 작업 데이터 및 오픈소스 OXE 데이터셋을 포함
- HL(High-Level Subtask Prediction): Long-horizon task을 "이불 펴기", "배개 정돈"같은 Subtask 설명과 사물 Bounding Box로 라벨링하여 로봇이 High-level 계획 능력을 함께 내재화하도록 훈련
- WD(Multi-modal Web data): CapsFusion, COCO, Cambrian-7M 등 인터넷의 대규모 Image Captioning, VQA, 사물 Localization 데이터를 포함하여 기초 시각 인지 지식을 확보
- 모델은 280k(28만) gradient step동안 다음의 이종 데이터를 섞어 다음 토큰 예측 방식으로 기본 뼈대를 학습
-
Post-training
-
사전 학습이 끝난 후, Mobile Control 특화 및 Continuous Action 생성을 위해 80k(8만) step동안 fine-tuning을 수행
- 이때 실험실 데이터(CE)는 배제하고 실제 다양한 환경에서 성공한 MM 및 ME 데이터 위주로 데이터셋을 좁혀 집중 학습
- VI(Verbal Instruction): 전문가들이 실시간으로 로봇에게 적절한 단계별 Subtask Commands를 내리며 주행한 일종의 "high-level 말하기 데모" 데이터셋을 주입. 이를 통해 high-level reasoning능력이 극대화
-
