논문 리뷰
1.[논문 리뷰]Goal-Driven Autonomous Exploration Through Deep Reinforcement Learning

Title : Goal-Driven Autonomous Exploration Through Deep Reinforcement Learning(ICRA 2022 and IEEE RA-L paper) 논문 링크 : https://ieeexplore.ieee.org/docu
2.[논문 리뷰] Goal-guided Transformer-enabled Reinforcement Learning for Efficient Autonomous Navigation
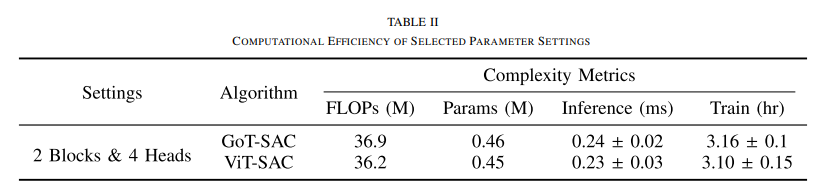
Title : Goal-guided Transformer-enabled Reinforcement Learning for Efficient Autonomous Navigation(IEEE Transactions on Intelligent Transportation Sys
3.[논문 리뷰]End-to-End Urban Driving by Imitating a Reinforcement Learning Coach
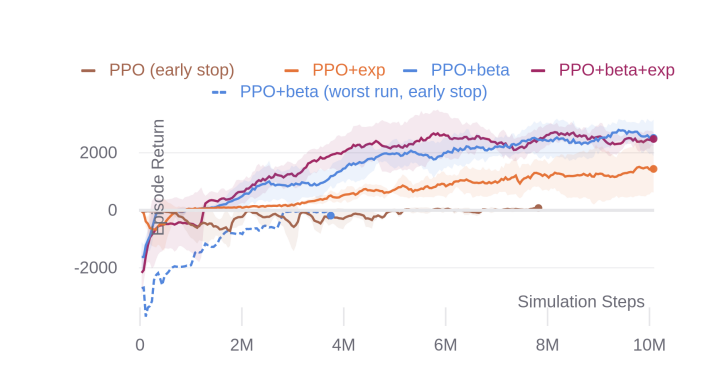
Title : End-to-End Urban Driving by Imitating a Reinforcement Learning Coach (by Zhejun Zhang, Alexander Liniger, Dengxin Dai, Fisher Yu and Luc van G
4.[논문 리뷰] LATTE: LAnguage Trajectory TransformEr
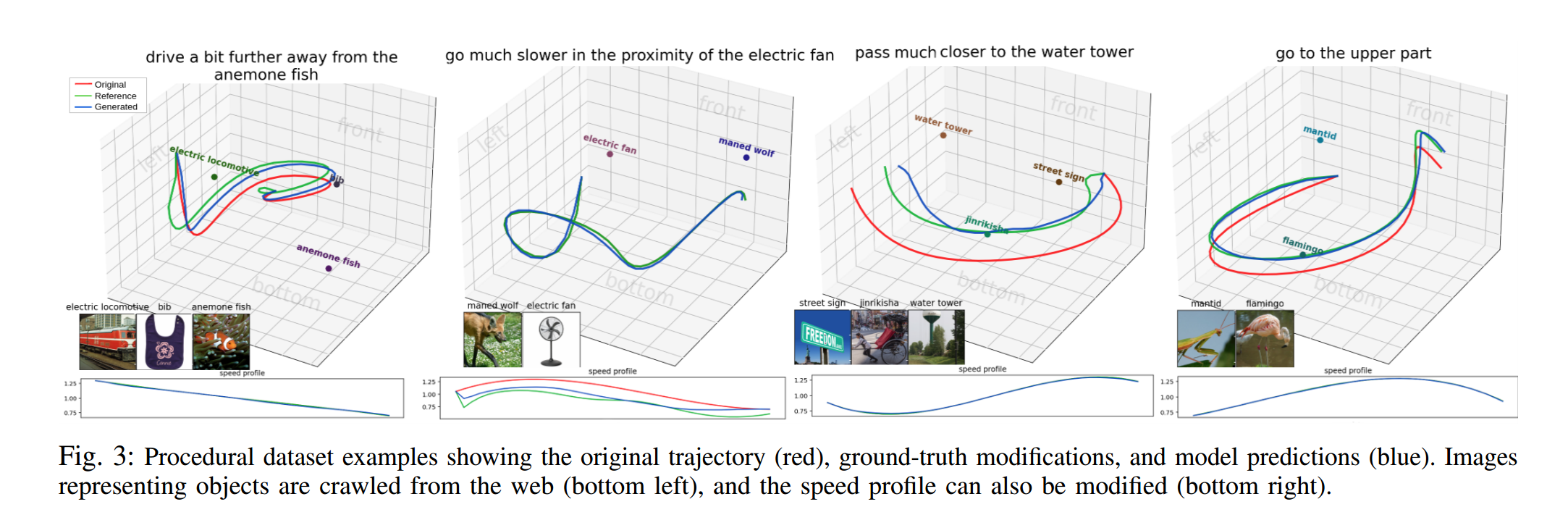
Title : LATTE: LAnguage Trajectory TransformEr (by Haitong Wang, Aaron Hao Tan, Student Member, IEEE and Goldie Nejat, Member, IEEE, published at 2023
5.[논문 리뷰] MOKA: Open-World Robotic Manipulation through Mark-Based Visual Prompting

Title : MOKA: Open-World Robotic Manipulation through Mark-Based Visual Prompting(by Kuan Fang, Fangchen Liu, Pieter Abbeel and Sergey Levine, Robotic
6.[논문 리뷰] VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models

Title : VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models (by Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun
7.[논문 리뷰] ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
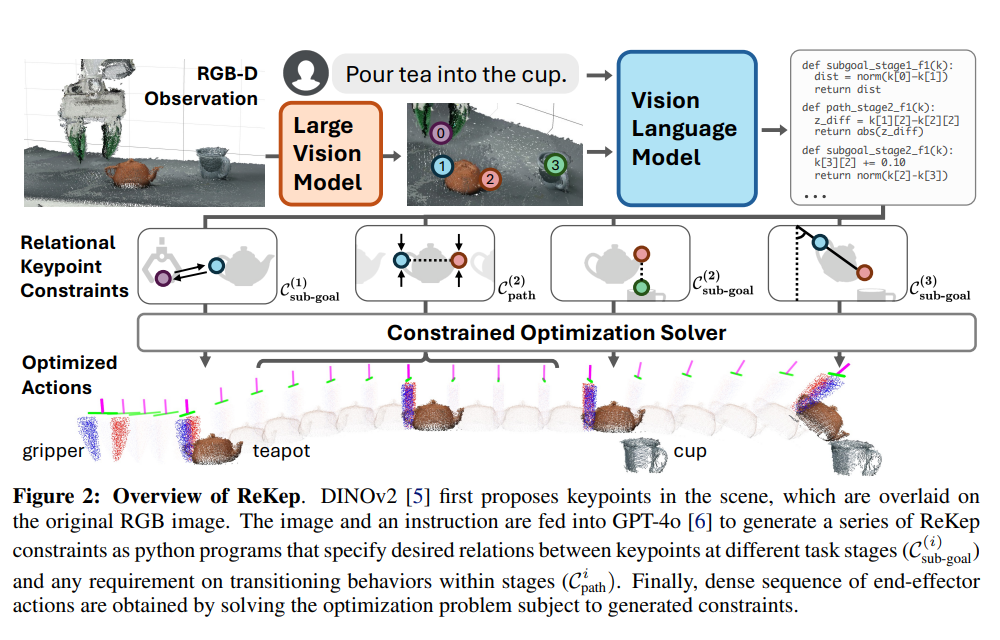
Title : ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation (by Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzh
8.[논문 리뷰] LUMOS: Language-Conditioned Imitation Learning with World Models
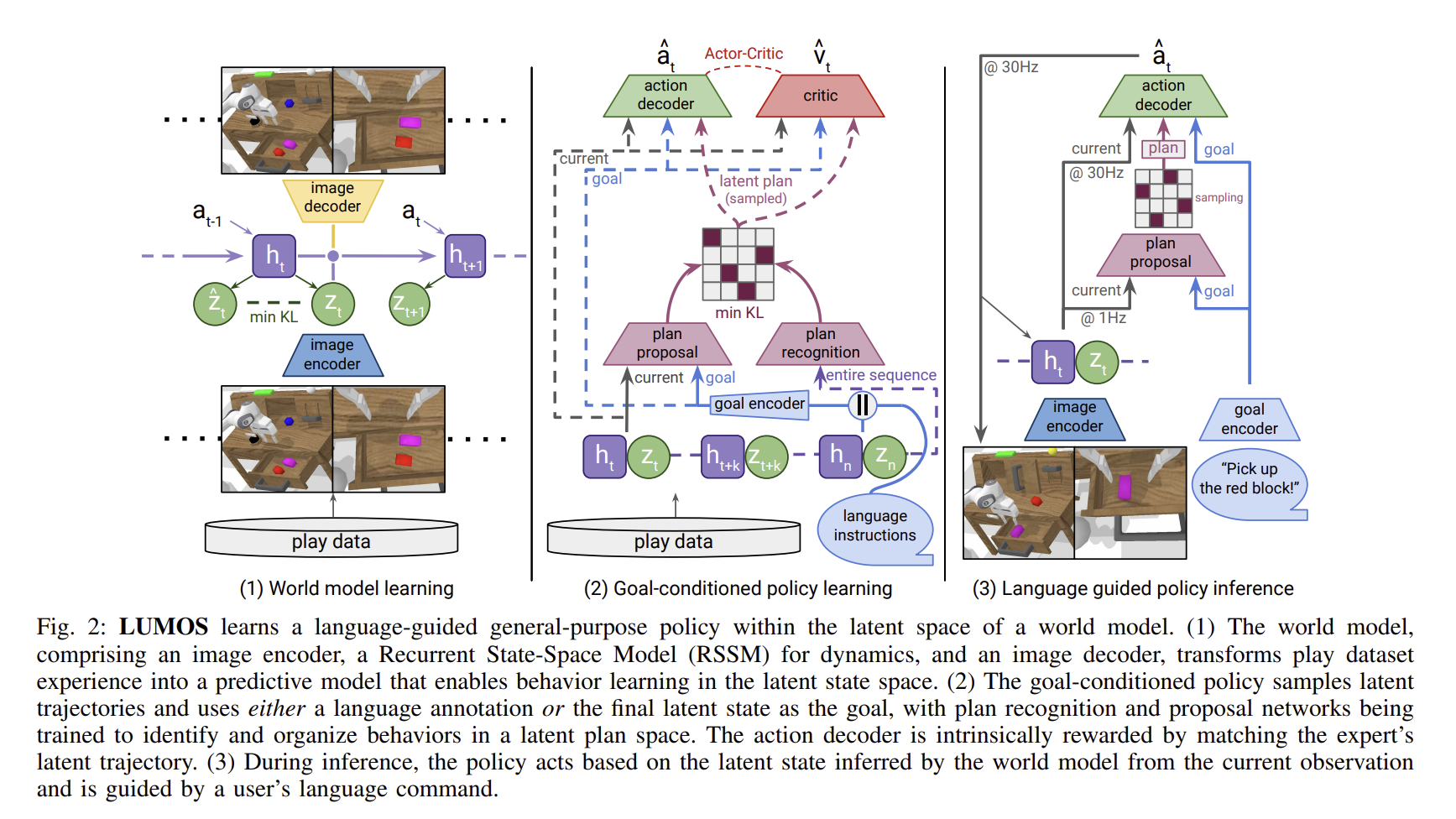
Title : LUMOS: Language-Conditioned Imitation Learning with World Models (by Iman Nematollahi, Branton Demoss, Akshay L Chandra, Nick Hawes, Wolfram B
9.[논문 리뷰] What Can RL Bring to VLA Generalization? An Empirical Study
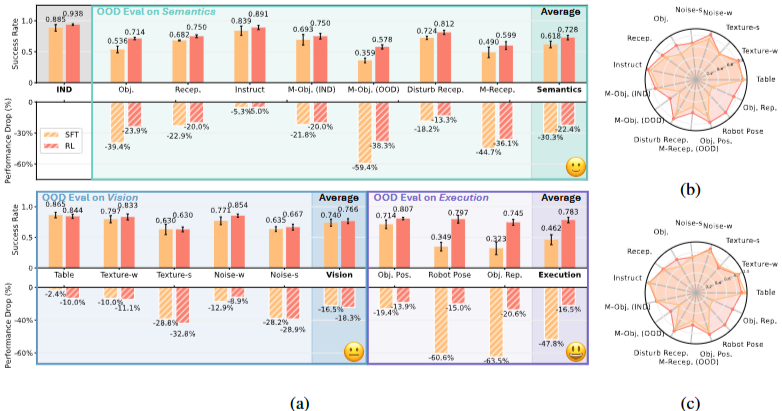
Title : Goal-Driven Autonomous Exploration Through Deep Reinforcement Learning(ICRA 2022 and IEEE RA-L paper) 논문 링크 : https://openreview.net/pdf?id=qm
10.[논문 리뷰] MEM: Multi-Scale Embodied Memory for Vision Language Action Models
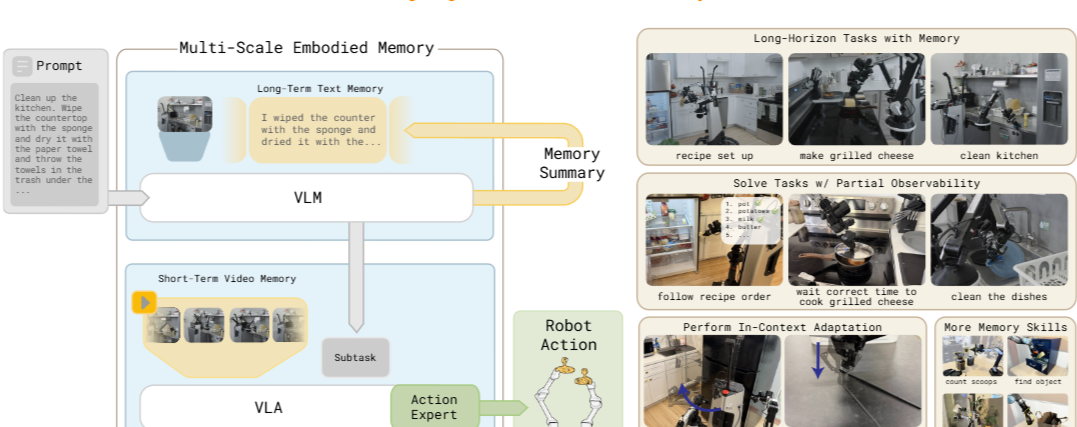
Title : MEM: Multi-Scale Embodied Memory for Vision Language Action Models(Arxiv 2026) 논문 링크 : https://www.pi.website/download/Mem.pdf blog: https://w
11.[논문 리뷰] WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RL
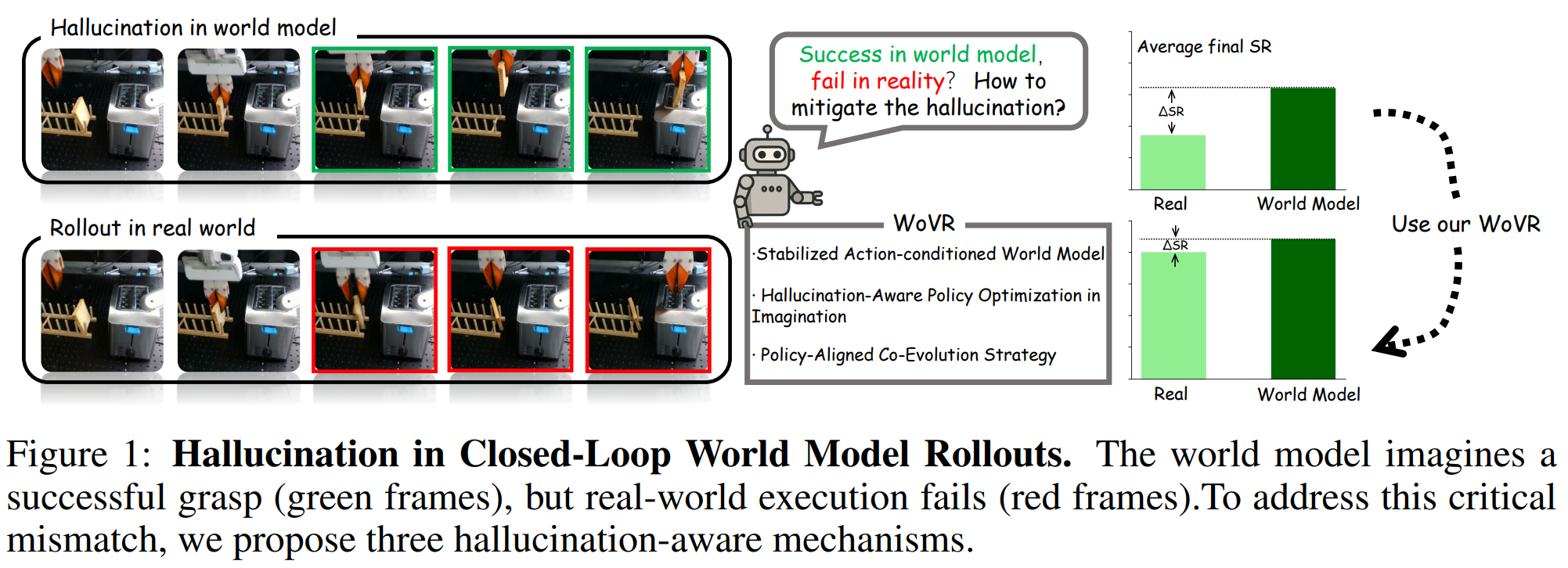
Title : WoVR: World Models as Reliable Simulators for Post-Training VLA Policies with RL(Arxiv 2026)논문 링크 : https://arxiv.org/pdf/2602.13977blog:
12.[논문 리뷰] World-VLA-Loop: Closed-Loop Learning of Video World Model and VLA Policy
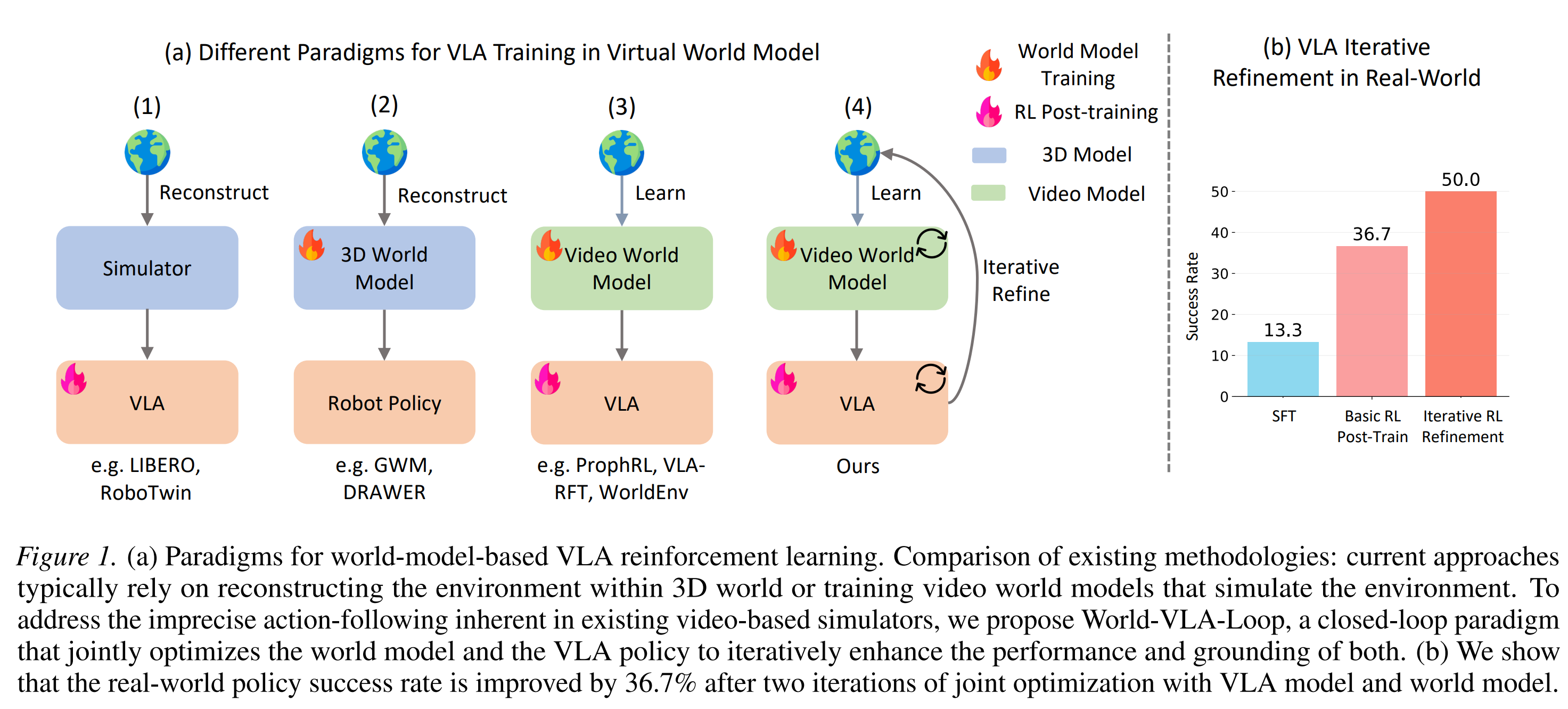
Title : World-VLA-Loop: Closed-Loop Learning of Video World Model and VLA Policy(Arxiv 2026)논문 링크 : https://arxiv.org/pdf/2602.06508blog: https&#
13.[논문 리뷰] VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model

Title : VLAW: Iterative Co-Improvement of Vision-Language-Action Policy and World Model(Arxiv 2026) 논문 링크 : https://openreview.net/pdf?id=Ro0eQ0ly3q b
14.[논문 리뷰] CTRL-WORLD: A CONTROLLABLE GENERATIVE WORLD MODEL FOR ROBOT MANIPULATION
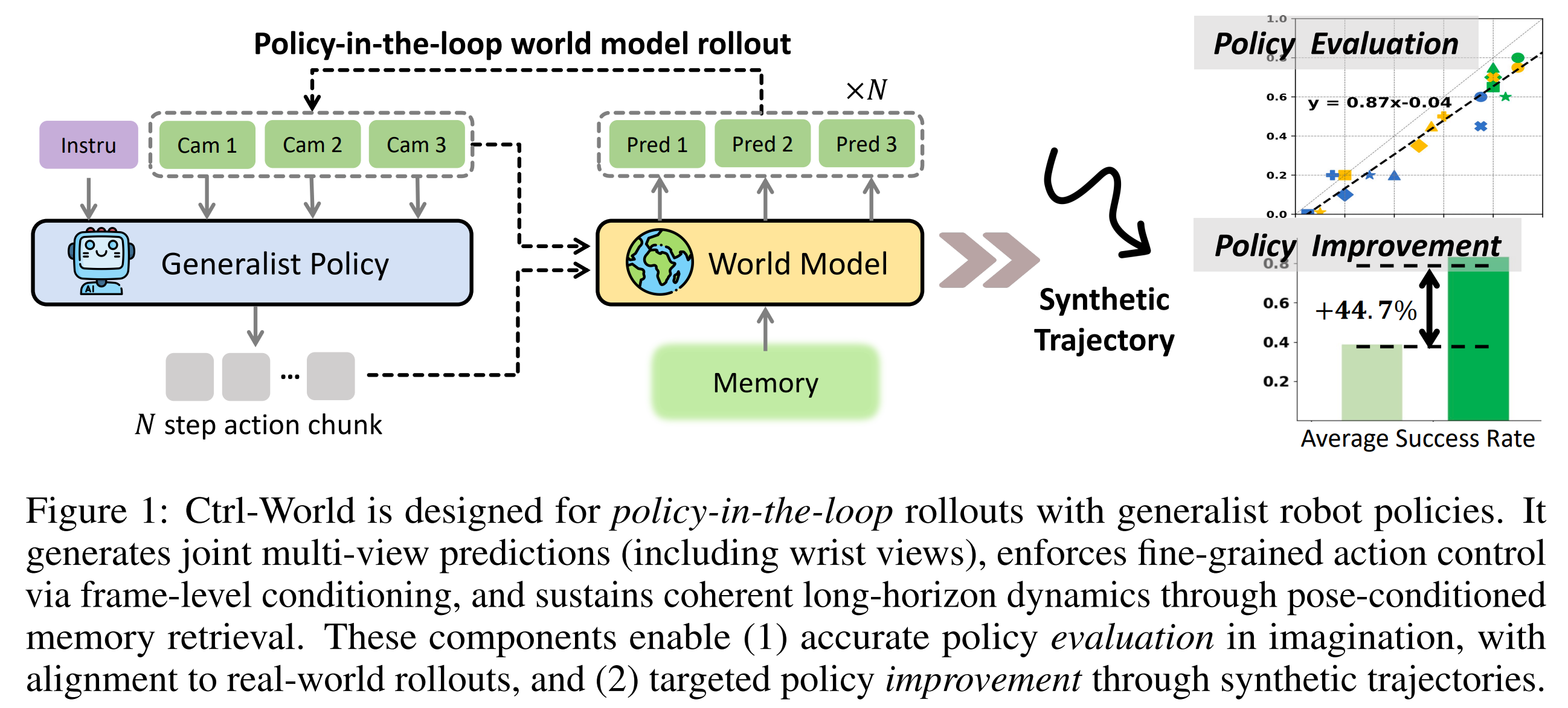
Title : CTRL-WORLD: A CONTROLLABLE GENERATIVE WORLD MODEL FOR ROBOT MANIPULATION(ICLR 2026)논문 링크 : https://arxiv.org/pdf/2510.10125blog: https&#x
15.[논문 리뷰] View-Invariant Policy Learning via Zero-Shot Novel View Synthesis

Title : View-Invariant Policy Learning via Zero-Shot Novel View Synthesis(CoRL 2024)논문 링크 : https://arxiv.org/pdf/2409.03685blog: https://s-
16.[논문 리뷰] Act, Sense, Act: Learning Non-Markovian Active Perception Strategies from Large-Scale Egocentric Human Data
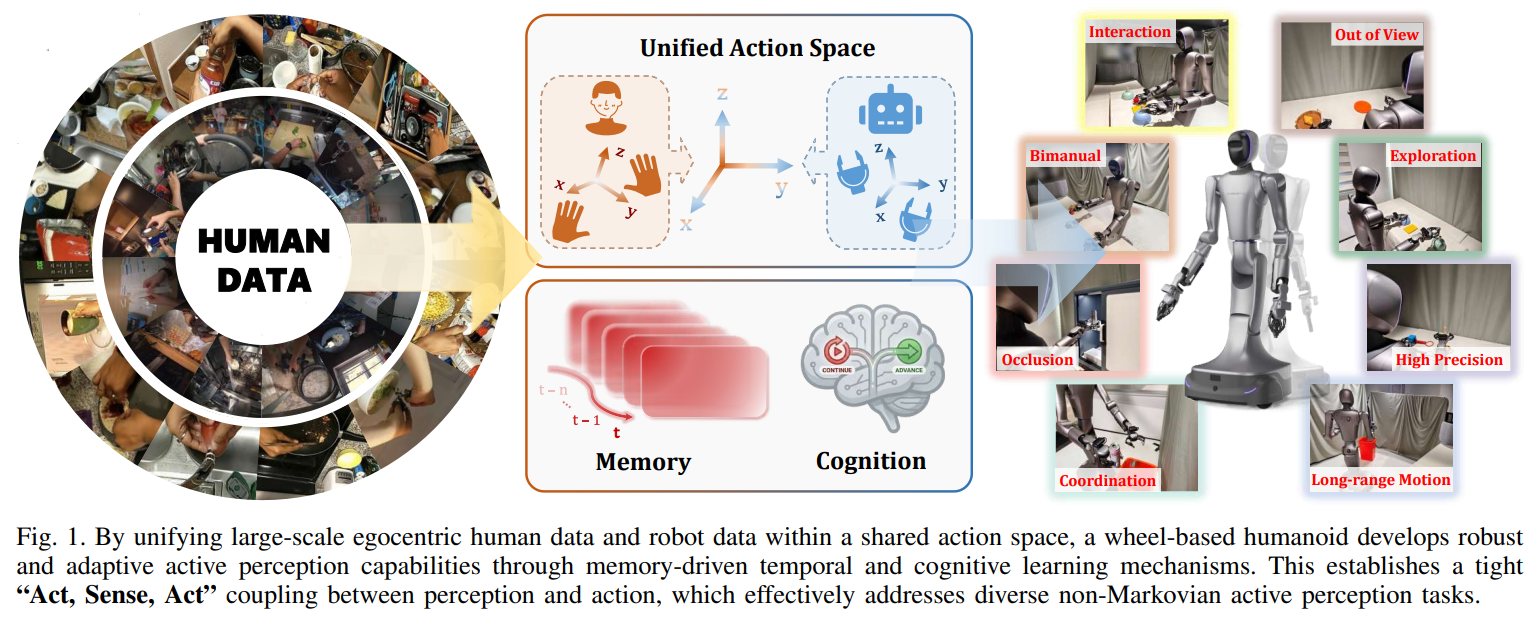
Title : π 0.7 : Act, Sense, Act: Learning Non-Markovian Active Perception Strategies from Large-Scale Egocentric Human Data (ArXiv 2026) 논문 링크 : https
17.[논문 리뷰] π0.5: a Vision-Language-Action Model with Open-World Generalization

Title : π0.5: a Vision-Language-Action Model with Open-World Generalization (CoRL 2025) 논문 링크 : https://arxiv.org/pdf/2504.16054 blog: https://www.pi.website/blog/pi05 1. Introduction Open-world Gene...