Title : LUMOS: Language-Conditioned Imitation Learning with World Models (by Iman Nematollahi, Branton Demoss, Akshay L Chandra, Nick Hawes, Wolfram Burgard, Ingmar Posner, published at 2025 IEEE International Conference on Robotics and Automation (ICRA)
1. Abstract
- language-condition multi-task imitation learning 프레임 워크 개발(LUMOS)
- 학습된 World Model의 latent space에서 long-horizon rollout을 통해 기술을 학습하여 zero-shot으로 실제 로봇에 전이
long-horizon rollout
- rollout : 강화학습이나 모방 학습에서 시작 state에서 action을 선택하면서 여러 시간 단계에 걸쳐 환경을 시뮬레이션 하는 과정
예: "문을 열어 -> 물건을 들어서 -> 서랍에 넣는" 일련의 action sequence - long-horizon : 오래 걸리는 작업 즉, action 수가 많은 task
- rollout : 강화학습이나 모방 학습에서 시작 state에서 action을 선택하면서 여러 시간 단계에 걸쳐 환경을 시뮬레이션 하는 과정
- world model의 latent space는 on-policy로 학습하여 off-policy에서 생기는 정책 공변량 변화(policy distribution shift) 문제 해결
- long-horizon CALVIN benchmark에서 실험 결과, 기존 학습 기반 방법들보다 뛰어난 성능을 보임
2. Introduction
Problem
- 일반적인 RL 알고리즘은 양질의 Policy를 학습하기 위해, 수백만 번의 에피소드가 필요하며, 이는 robot task에 비현실적임.
- 기존 Imitation Learning은 long-horizon task에서 오류 누적 문제로 일반화가 어려움
- language-conditioned policy를 실제 환경에 zero-shot으로 적용하는 데 한계
- RL은 시뮬레이터 또는 많은 인터랙션을 요구하고, behavior cloning은 짧은 horizon에만 강함
Proposed method
- LUMOS는 DreamerV2 기반의 world model을 통해 학습된 latent space에서 long-horizon imitation policy를 학습
- language instruction을 goal로 사용하며, offline play data로부터 학습
- 훈련은 ① world model 학습 -> ② latent policy 학습(actor-critic 구조)로 이루어짐.
- latent trajectory가 export의 trajectory를 따르도록 intrinsic reward를 정의함.
Contribution
- world model 기반 imitation learning을 통해 long-horizon task 성능 개선
- language-conditioned policy를 latent space에서 직접 학습
- real-world zero-shot transfer 가능
3. Problem Formulation
- Goal-conditioned imitation learning은 다음과 같은 조건에 따름
- Partially Observable Markov Decision Process(POMDP)
- 연속적인 행동 공간(Continuous actions)
- 고차원 시각 관측값(High-dimensional observations)
- 미지의 환경(unknown environment)
- 환경과 goal-conditioned policy 간의 상호작용을 goal이 확장된 POMDP로 모델링하며 다음과 같이 정의
: state-observation space
: Action space
: state-transition dynamics
: goal space
: discount factor(0,1) - 보상은 직접 관측 불가, 목표는 외재적 보상(extrinsic rewards)를 최대화하는것
- 즉, 특정 목표(goal)를 달성하도록 imitation policy 학습
입력 데이터(Dataset)
- 입력 데이터:
- 라벨 없는, 방향성 없는 play data
- 형태 :
- 재가공:
- 모든 방문 상태를 도달된 goal로 간주해 trajectory로 변환
- (trajectory , goal state ) 형태의 쌍으로 구성된 goal-conditioned trajectory dataset 생성
Language-Conditioned Learning
- 전체 데이터 중 일부만 언어로 주석(<1%)
- 일부 window에 대해 retroactive language instrunction 제공
- 이를 통해 다양한 작업에 대해 통합된 language-conditioned visuomotor policy 학습 가능
4. LUMOS
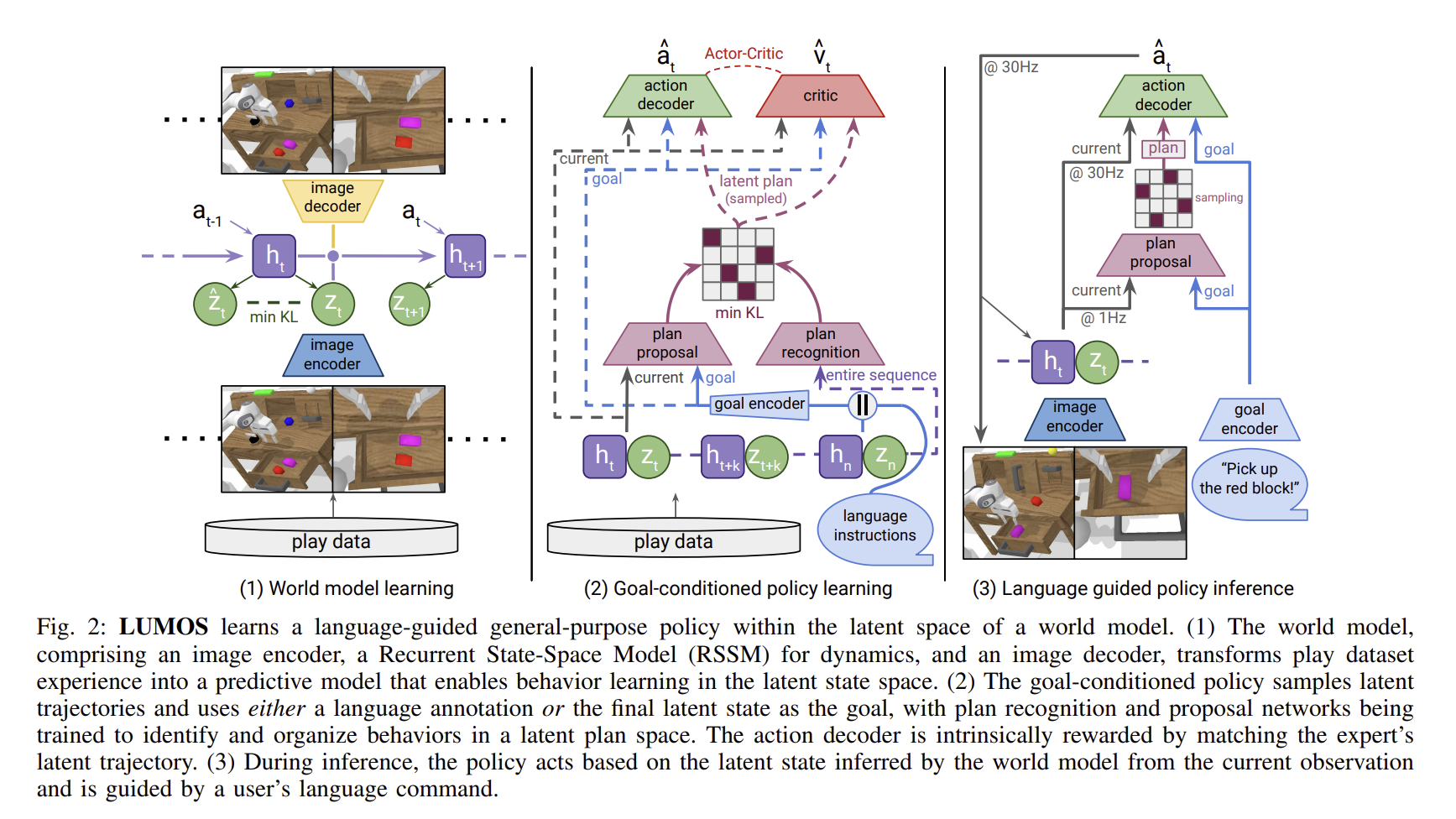
- 학습은 두 단계로 구성됨
- 라벨이 없는 play dataset 로부터 world model을 학습
- 학습된 world model안에서 actor-critic agent를 학습하여, goal-conditioned policy를 얻음, 이때 agent는 "상상(imagined)"된 latent model 시퀀스를 export demo의 latent trajectory와 일치하도록 유도하며 학습
inference 에서는 완전히 world model의 latent 공간에서 학습된 language conditioned policy이 실제 환경에 transfer
A. World Model Learning
- 환경과 상호작용 없이 행동을 학습할 수 있도록 에이전트의 경험을 예측 가능한 모델로 학습하는 것이 목적
- 즉, latent space 상에서 long-horizon rollout을 가능하게 하는 world model을 학습
구조
LUMOS는 DreamerV2 아키텍쳐를 기반으로 world model을 구성
- Image Encoder: 고차원 이미지를 compact한 상태 표현으로 변환(입력으로는 두 개의 카메라(static, gripper)사용
- RSSM : 환경의 동역학을 모델링
- Image Decoder: latent space로부터 원래 이미지를 재구성
학습 방식
- 변분 하한(Variational Lower Bound, ELBO)을 최소화하는 것을 목적
- Loss function은 reconstruction Loss + KL divergence loss로 구성
- 학습 후에는 이전 이미지만 사용해서 imagined trajectory 생성 가능(rollout)
B. Behavior Learning
- world model의 latent space 에서 long-horizon language-conditioned policy 학습
- zero-shot으로 실제 환경에 전이 가능한 policy 획득
구성 요소
- 입력
- state: world model의 latent state
- goal: free-form language instruction 또는 latent goal state
- action: 7-DoF continous space(XYZ position, Euler angular, gripper state)
Latent Plan Encoding(계획 인코딩)
- seq2seq CVAE로 다양한 trajectory를 latent plan 공간으로 인코딩
- 두 인코더 사용:
- Recongnition encoder : 학습시
- Proposal encoder : 추론 시
- KL divergence 최소화로 계획의 일관성 유지
Language-Latent Alignment(언어-계획 정렬)
- language와 latent trajectory를 CLIP-style constrastive loss로 정렬
- in-batch negatives로 학습 효율 향상
- 해당 손실은
Intrinsic Reward(내재 보상)
- export의 action과 유사한 trajectory 유도
- latent state 내적 기반의 similarity reward 사용
- 다양한 경로 허용하면서도 export와의 정렬 유지
5. Experiment
- 시뮬레이션과 실제 환경 모두에서 language-condition imitation learning 성능 평가
- 모델이 long-horizon language based task를 얼마나 잘 수행하는지
- 구성 요소 제거(Ablation)를 통한 중요도 분석
- 실제 로봇으로의 확장 가능성 평가
A. Experiments in Simulation
-
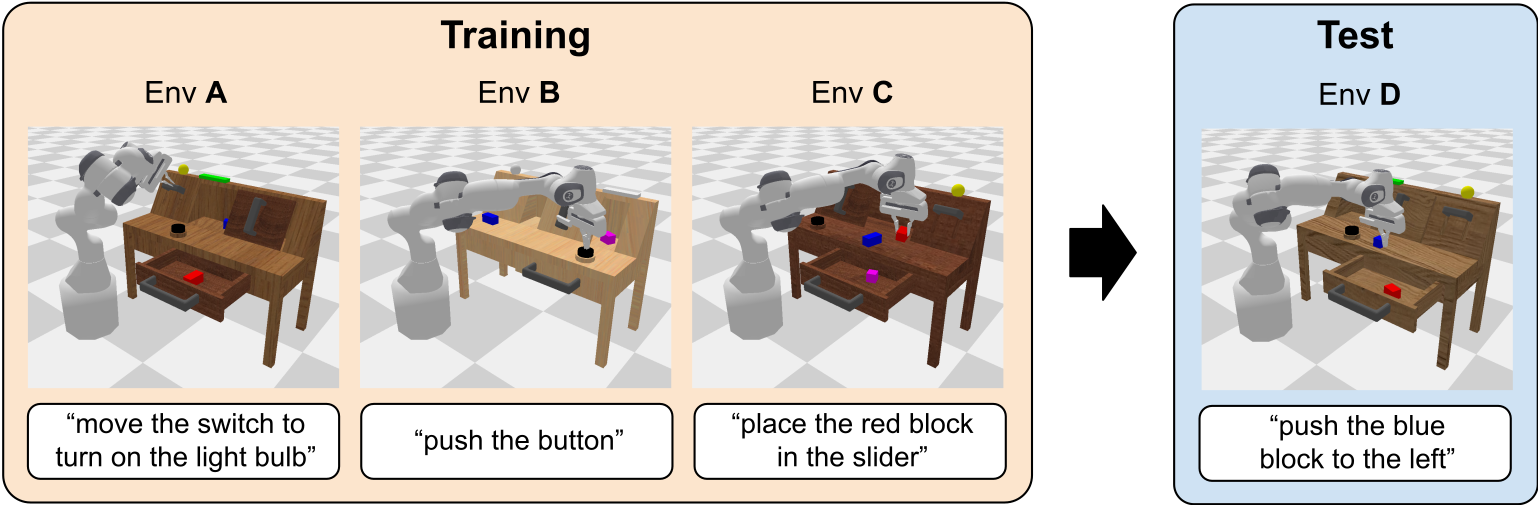
CALVIN Benchmark
-
시뮬레이션은 CALVIN Challenge의 환경 D에서 수행됨. CALVIN은 총 34개의 개별 Subtask를 포함하며, 1,000개의 고유한 language instruction chains을 통해 평가함.
-실험은 최대 다섯 개의 language instrcution을 순차적으로 해결하는 것 즉, 언어 단서(language cues)만으로 각 서브골(subgoal) 사이를 전환해야함.
비교 대상
- GCBC
- Latent Plan 없음, 단순 행동 예측(reconstruction loss 기반)
- MCIL
- Seq2Seq CVAE로 latent plan 모델링
- HULC
- MCIL 개선, contrastive loss 사용, language-vision align 강화
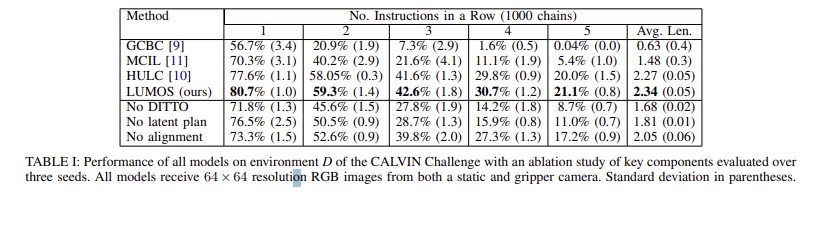
결과
- LUMOS는 모든 baseline을 능가하는 성능을 보임
- export의 trajectory로부터 벗어나는 정도를 측정하는 Intrinsic reward를 성공적으로 최적화하여 에이전트가 실수에서 회복 가능
- long-horizon task chain을 성공적으로 수행
Ablation 실험
1. Intrinsic Reward 제거
- instrinsic reward 대신 behavior cloning(MSE base)으로 에이전트 훈련
- 결과 : 성능 크게 저하
- latent matching 보상이 공변량 변화(covariate shift)완화에 효과적
- Latent Plan 제거
- actor에서 plan proposal/ plan recognition 모듈 제거
- 결과 : 시작은 잘하지만 long-horizon task 수행에 실패
- latent plan 공간 학습이 복잡한 작업 완성에 중요
- language-state Alignment 제거
- language와 latent state간의 alignment loss 제거
- 결과: 일정 성능 유지하지만 전체적으로 성능 감소, 특히 language와 vision 의미 매칭 실패
- language-state 의미 연관성 학습이 task 성공에 도움
B. Experiments in Real-world
실험 환경
- 로봇: Franka Emika Panda(7-Dof)
- 장소: 테이블 환경(스토브, 그릇, 캐비닛, 당근, 그릇, 가지 포함)
- 데이터:
- 3시간 VR 원격 조작 시연
- static + gripper 카메라로 RGB 이미지 기록
- 언어 주석은 1% 미만(약 2,800개 window)
World Model 평가
- RSSM 기반 world model을 학습
- hold-out 시퀀스의 5프레임만 보고 -> 195step까지 미래 예측
- world model이 latent space에서 long-horizon prediction과 action learning에 적합

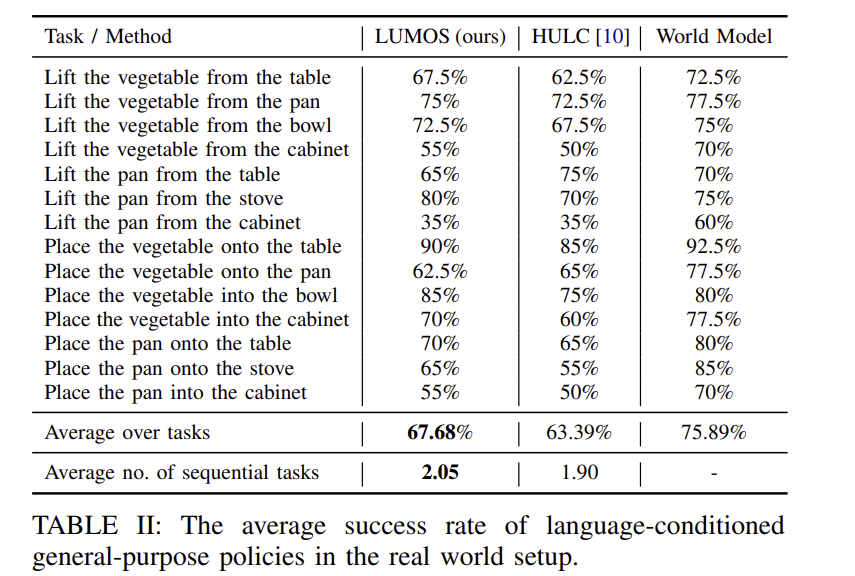
Language-conditioned policy 평가
- LUMOS의 latent space policy를 HULC와 동일 조건에서 비교
- 각 task마다 20회 rollout 수행
- 중립적인 시작 위치로 설정해 task 편향 방지 -> 언어만으로 행동 유도
- 단일 task에서 LUMOS가 HULC보다 높은 성공률을 보임.
- 연속적인 지시(5단계)에서 LUMOS가 평균 더 많은 task를 성공적으로 수행
-> 즉, LUMOS는 실수를 복구하는 능력과 convariate shift를 줄이는 안정성이 뛰어남.

6. Conclusion and Limitations
- LUMOS는 world model의 latent 공간에서 offline으로 long-horizon imitation learning을 수행하는 프레임워크
- 언어 지시만으로 long-horizon task를 수행 가능
- 온라인 상호작용 없이도 export 수준의 policy 복원
- CALVIN benchmark와 실제 환경에서 우수한 성능 입증
- zero-shot 실제 환경 trasition 가능성을 보임
- world model 품질 검증이 어려움
- 학습된 표현이 좋은 policy를 보장하는지 사전에 판단하기 어려움
- 해상도 향상 시 성능 증가
- 하지만 고해상도 이미지 입력 -> 계산량 급증

잘보고갑니다~