Title : MEM: Multi-Scale Embodied Memory for Vision Language Action Models(Arxiv 2026)
논문 링크 : https://www.pi.website/download/Mem.pdf
blog: https://www.pi.website/research/memory
1. Introduction
-
기존 방식의 문제점
- 효율적인 VLA 정책을 구현하기 위해서는 상황에 따라 서로 다른 수준의 추상화된 기억이 필요.
- 기존처럼 모든 과거 관측치를 단순하게 입력(context)에 넣는 방식은 작업 시간이 길어질수록 계산량이 너무 많아져 실현 불가능해짐
- 따라서 아주 짧은 시퀀스만 사용하거나 데이터 샘플링을 심하게 줄여야 하는 제약이 발생함.
-
기억의 두 가지 측면: 장기(Long-term) vs 단기(Short-term)
- 단기 기억(short-term): 로봇 팔에 의한 occlusion 문제를 해결하거나 최근 이벤트를 파악하기 위해 몇 초간의 조밀한 이미지 기반 기억이 필요
- 장기 기억(Long-term): 요리 중 어떤 재료를 넣었는지와 같이 수 분 이상의 시간이 흐른 뒤에도 유지되어야 하는 기억으로, 단 몇 비트의 핵심 정보만 있으면 충분한 추상적인 개념.
-
MEM(Multi-Scale Embodied Memory)의 제안
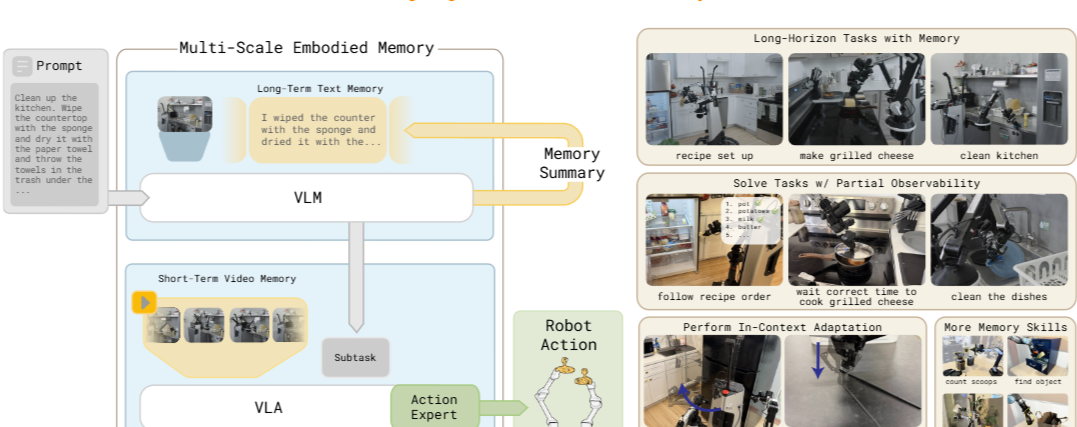
- 본 논문은 이 두가지 서로 다른 추상화 수준을 결합한 혼합 모달(mixed-modal) 기억 아키텍처를 제안
- 비디오 인코더 기반 단기 기억: 수 초간의 조밀한 영상을 압축된 표현으로 변환하여 미세한 조작 전략을 수정하거나 occlusion 상황에 대응
- 언어 기반 장기 기억: Semantic 이벤트를 압축된 텍스트 형식으로 기록하여 작업 맥락을 추적
-
주요 결과
- MEM을 사용한 VLA는 주방 청소나 샌드위치 만들기와 같은 최대 15분이 소요되는 Long-horiaon Task를 수행할 수 있음
- 과거 실패 경험을 토대로 조작 전략을 스스로 수정하는 In-context adaptation 능력을 보여줌
- MEM을 에 통합하여 복잡하고 장기 작업에 대해 SOTA 성능을 달성함.
- 즉, MEM은 VLA모델이 단기적인 물리적 역동성과 장기적인 의미적 맥락을 동시에 파악하도록 설계된 방법론
2. Multi-Scale Embodied Memory for VLAs
2.1 Problem Factorization
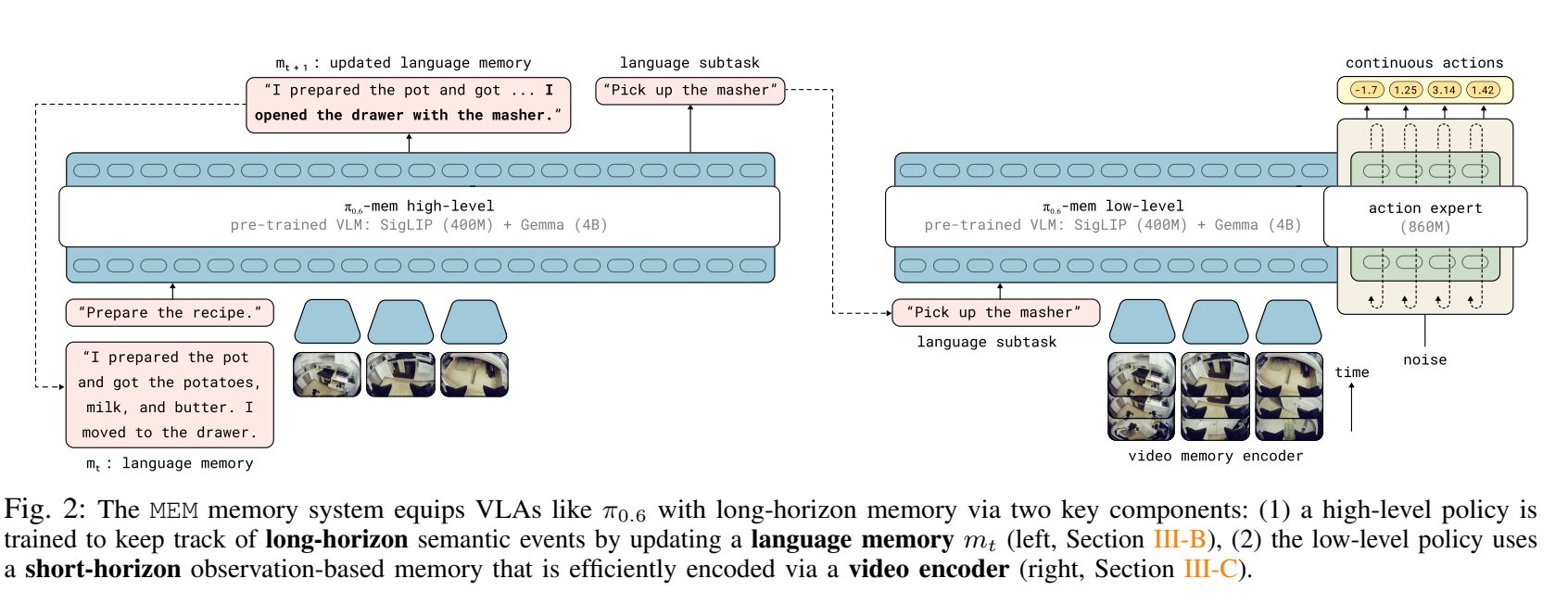
- 저자들은 행동 예측 문제를 고수준(High-level)과 저수준(Low-level) 정책으로 분리하여 공식화
- Action Prediction:
- High-level Policy(): 현재 Observation()과 이전의 language memory()을 입력받아, 다음 subtask instruction()와 업데이트된 language memory()을 생성
- Low-level Policy(): goal(), 짧은 관측 영상 시퀀스(), 그리고 고수준에서 내려온 subtask instruction()를 바탕으로 실제 continuous actions()을 실행함.
- Action Prediction:
2.2 Long-Term Memory(Language Memory)
- 장기적인 맥락(ex: 요리 단계 중 무엇을 완료했는지)을 유지하기 위해 자연어 형태의 요약본을 사용
- Self-updating Mechanism: 모델은 이전의 요약본()과 현재 상황을 보고 스스로 새로운 요약본()을 예측함. 예를 들어, "접시를 놓았다"는 기억에 "그릇을 집었다"는 정보를 추가하여 업데이트 함.
- Information Compression: LLM을 사용하여 훈련 데이터를 생성할 때, 불필요한 디테일(예: 파란 그릇, 빨간 그릇, 노란 그릇)은 버리고 핵심적인 정보(예: 그릇 3개)만 남기도록 compression을 수행. 이는 inference 속도를 높이고 데이터 분포의 차이(distribution shift)를 줄여줌.
2.3 Short-Time Separable Attention(Video Encoder)
- 미세한 동작 수정이나 팔에 의한 가려짐(self-occlusion)문제를 해결하기 위해 수 초간의 조밀한 관측 데이터를 처리.
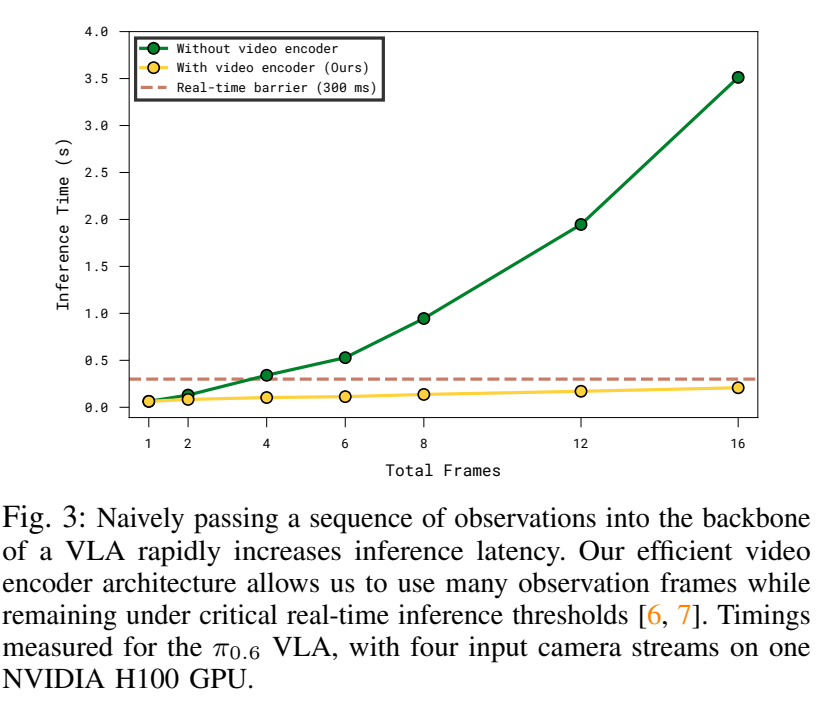
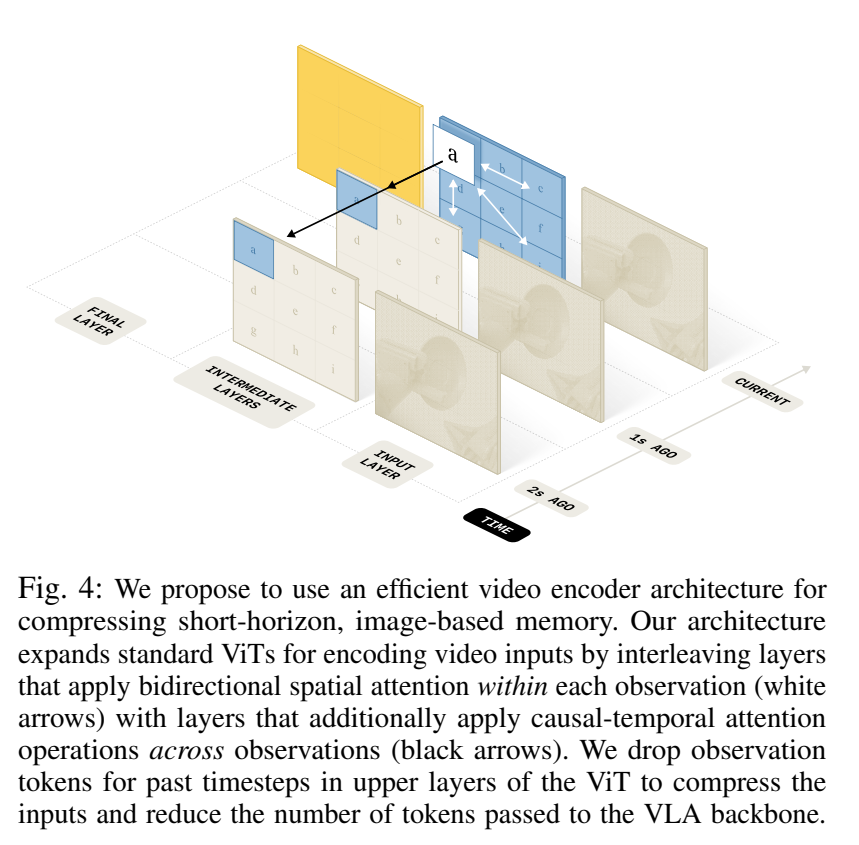
- Space-Time Separable Attention: 모든 프레임의 한 번에 처리하면 계산량이 기하급수적으로 늘어나기 때문에, Spatial attention과 Causal-temproal Attention을 분리하여 적용.
- 매 4번째 레이어마다 Time dimension에 대한 attention을 수행하여 시간적 맥락을 주입
- 계산 복잡도를 에서 로 낮춤.
- Token Compression: 인코더의 마지막 단계에서는 오직 현재 타임스텝의 representation만 백본으로 전달하고 과거 프레임의 토큰은 drop, 이를 통해 메모리가 없는 모델과 동일한 수의 토큰만 처리하면서도 과거 정보를 포함하게 됨.
- Pre-trained weight 사용: 새로운 학습 파라미터를 추가하지 않고 기존 ViT의 casual attention pattern만 수정하기 때문에, 이미 잘 학습된 VLM의 가중치를 그대로 초기값으로 사용할 수 있음.
메모리가 없는 모델이란? : 기존 방식의 VLA 모델, 즉, 현재 시점의 Observation만 보고 action 추론하는 방식
- Space-Time Separable Attention: 모든 프레임의 한 번에 처리하면 계산량이 기하급수적으로 늘어나기 때문에, Spatial attention과 Causal-temproal Attention을 분리하여 적용.
2.4 Implementation Details(-MEM)
- MEM을 모델에 통합하여 구현함.
- Backbone: Gemma3-4B VLM에서 초기화되었으며, 860M 파라미터 규모의 flow-matching action expert를 함께 사용
- Proprioceptive State: 과거의 로봇 상태 정보는 텍스트 대신 continuous state embedding으로 투영하여 토큰 수를 최소화함.
- Training Strategy: Pre-training 시에는 1초 간격의 프레임 6개를 사용하며, Post-training을 통해 최대 18프레임까지 메모리 범위를 확장함.
- Real-time Constraints(RTC): Action chunking 기술을 결합하여 비동기적인 실시간 추론이 가능하도록 구현.
3. Experimental Evaluation
- 저자들은 3가지 목표를 가지고 실험을 진행함.
- (1): VLA + MEM이 최대 15분이 걸리는 Long horizon task에 대해서도 강건하게 작업을 수행할 수 있는가?
- (2): MEM이 실시간 조작 전략을 수정하게 도와주는가?
- (3): MEM의 성능은 VLA모델에 메모리를 추가하는 이전 접근 방식과 어떻게 비교되는가?

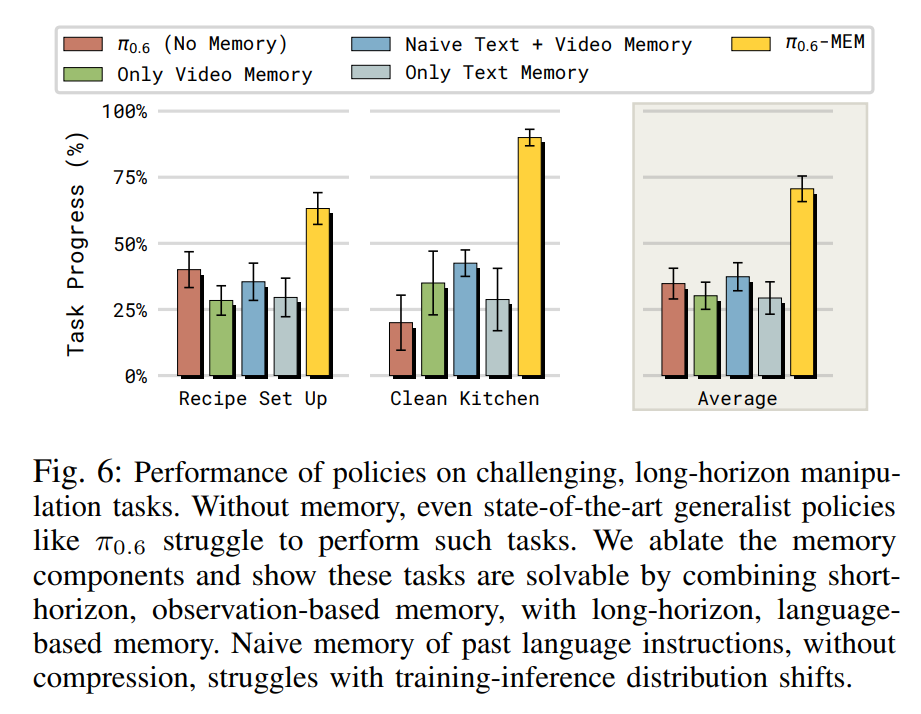
3.1 MEM Solves Tasks Requiring Long-Horzion Memory
- MEM은 최대 15분동안 지속되는 복잡한 시퀀스의 작업을 성공적으로 수행할 수 있음을 보여줌
- Recipe Setup(레시피 준비): 42개의 레시피 데이터를 학습하여, 냉장고나 수납장에서 재료와 도구를 꺼내 지정된 위치에 배치하는 작업을 수행함. 로봇은 어떤 아이템을 이미 가져왔는지 기억해야 하며, 사용 후 문을 닫는 등의 세심한 관리가 필요
- Clean Up Kitchen(주방 청소): 카운터 닦기, 설거지, 물건 정리 등을 포함하며, 비누칠을 했는지 혹은 접시의 앞뒷면ㅇ르 모두 닦았는지와 같은 세부적인 진행 상황을 기억해야 함.
- Result: 메모리가 없는 기존 모델은 이러한 장기 과제에서 매우 낮은 성공률을 보였으나, MEM은 Short-Term video Memory와 Long-term language memory의 결합을 통해 성능을 비약적으로 향상시킴.
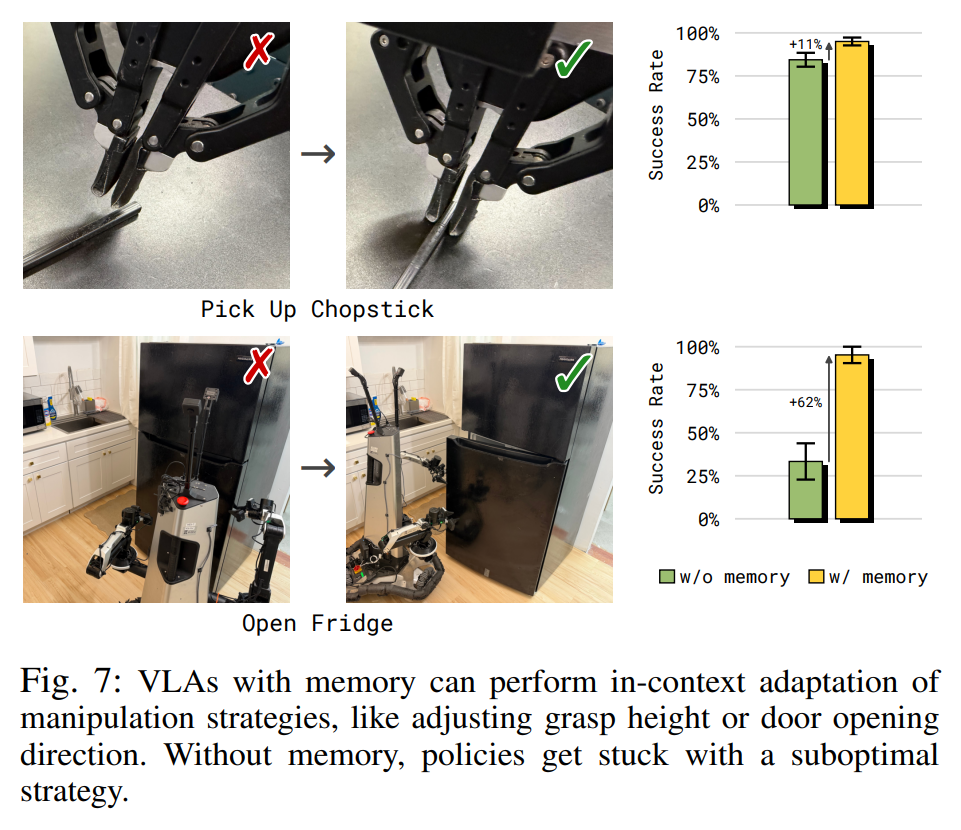
3.2 In-Context Adaptation
- 단기 비디오 메모리를 통해 로봇이 자신의 실수나 환경 변화에 즉각적으로 대응하는 능력을 테스트하였음.
- Pick up Chopstick: 테이블 높이가 평소와 다를 때 발생하는 미세한 mis-grasp를 단기 기억으로 인지하고, 다음 시도에서 집는 높이를 조절하여 성공
- Open Fridge: 냉장고 문의 경첩 방향이 불분명할 때, 한쪽으로 당겨보고 안 열리면 단기 기억을 바탕으로 즉시 반대 방향으로 시도
- 분석: 메모리가 없는 모델은 동일한 실패 전략을 반복하는 반면, MEM은 과거의 실패를 Context로 활용하여 전략을 수정함.
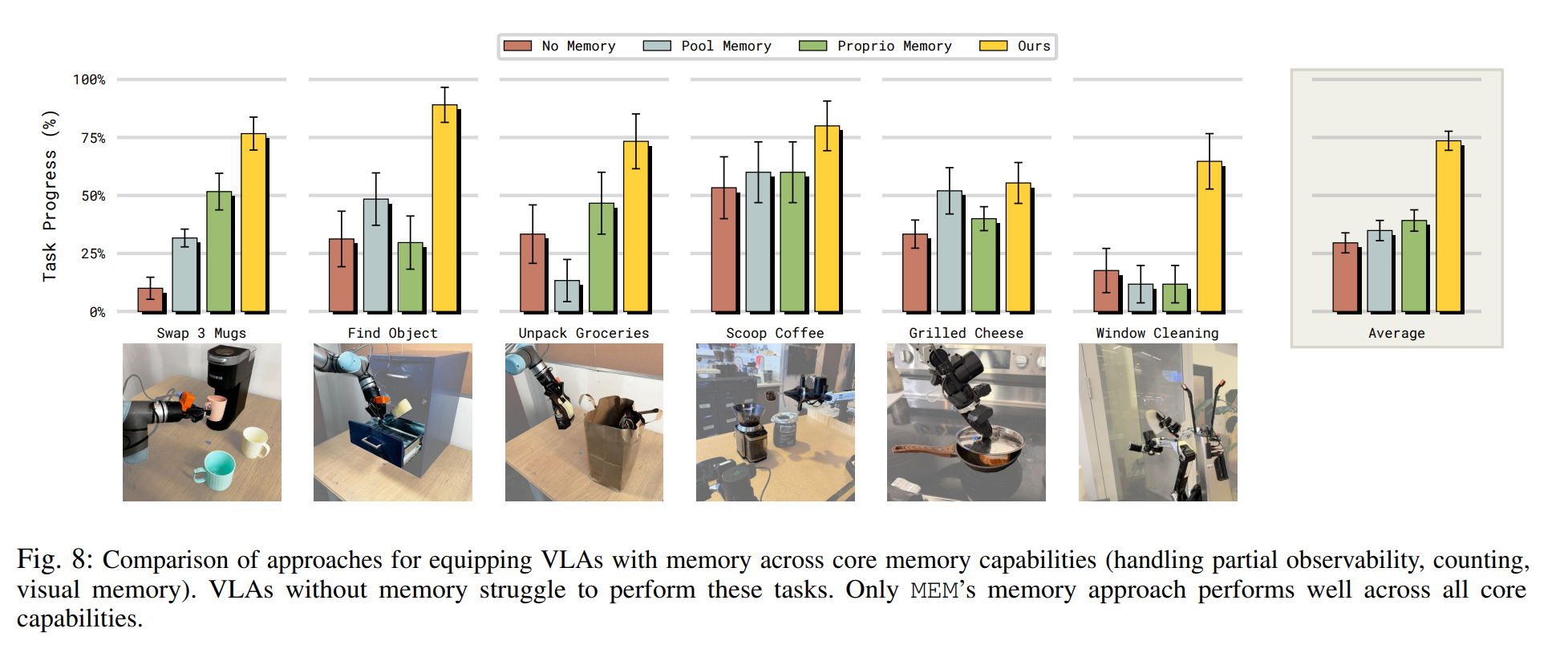
3.3 Core Memory Capabilities & Ablation
- 다양한 메모리 구현 방식(Pool Memory, Proprio Memory 등)과 비교 실험을 진행함.
- No Memory: 현재 프레임만 보고 판단, 부분 관측 상황에서 무작위 선택에 의존함. -> 가장 낮은 성능
- Pool Memory: 과거 프레임을 평균(Average Pooling)하여 압축, 장기적인 위치나 개수 기억에 취약 -> 단순 작업은 가능하나 복잡한 작업에서 한계
- Proprio Memory: 로봇의 관절 상태(state)만 기억, 환경의 변화(어느 서랍에 물건이 있는지 등)를 기억 못함 -> 로봇 자신의 상태 기억 과제에만 효과적
- MEM(Ours): Video Encoder와 Compressed Language Summary를 모두 사용 -> 모든 테스트 항목에서 SOTA 달성
3.4 Additional Experiment
-
Effect of Pre-training : 이 실험은 MEM의 핵심인 Video Encoder를 언제 학습시키는게 가장 좋은지를 보여줌
- Ours(Full): 다양한 로봇 및 인터넷 영상 데이터로 Pre-training 단계부터 메모리 기능을 학습
- Ours(Post-train only): 일반 VLA 모델에 사후 학습(Post-train) 단계에서만 비디오 메모리 구조를 추가한 모델
- Result: Pre-training부터 메모리를 학습 시킨 모델이 모든 과제에서 우수, 즉, 단순히 구조만 바꾼다고 되는게 아니라, 대규모 데이터를 통해 과거 영상을 어떻게 효율적으로 활용하는지를 미리 배우는 과정이 필수적임.
-
Performance on Non-Memory Tasks : 이 실험은 Memory 기능을 넣느라 오히려 원래 잘하던 기본 동작 실력이 줄어들지는 않았는가? 에 대한 실험
- 실험 내용: 기억력이 굳이 필요 없는 일반적인 조작 과제들(상 닦기, 옷 개기, 침대 정리 등)을 대상으로 기존의 SOTA 모델인 (No Memory)와 MEM을 비교
- Result: 대부분 과제에서 MEM은 기존 모델과 거의 비슷하거나 대등한 성능을 보임. 즉, MEM은 복잡한 장기 기억 기능을 추가하면서도, VLA 모델이 기본적으로 갖춰야 할 조작 능력(Dexterity)을 전혀 희생하지 않음.
4. Conclusion
- 장기 과제 해결
- In-Context Adaptation

Robotics