엘라스틱서치 개념
간만에 쓰는 개발블로그! 쓸게 쌓여버렸다... 일단 엘라스틱서치 개념! 이건 예전부터 써야지 써야지 하다가 ... 이제야 쓴다 증맬루~ 😣 퇴사하신 분이 ES를 주로 다루셨어서 나는 깔짝깔짝만 봤었는데, 이제 퇴사하셔서.. 자세히 봐야된다... ㅠㅠ esrally라는 테스트를 돌리기 위해서 보다가 내가 아직 개념이 잘 안 잡힌 것 같아 드디어 정리를 해야겠다고 마음 먹은것..!
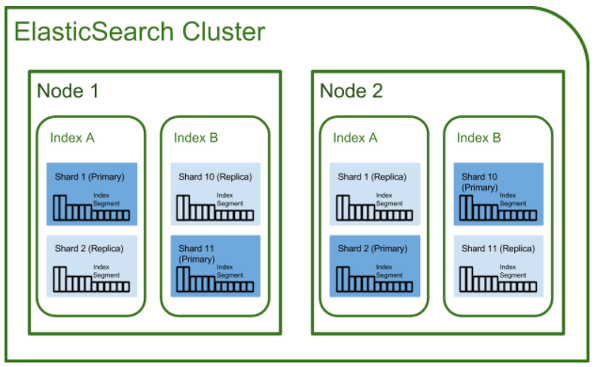
출처: https://github.com/exo-archives/exo-es-search
🎅Cluster란?
elasticsearch에서 가장 큰 단위. 노드들의 집합.
클러스터는 독립적이여서 서로 다른 클러스터끼리 접근할 수 없다.
여러대의 서버가 하나의 클러스터를 구성할 수 있고, 한 서버에 여러개의 클러스터가 존재할 수 있다.
🌉Node란?
Elasticsearch를 구성하는 하나의 인스턴스
elasticsearch를 시작하면 하나의 elasticsearch 노드가 생성된다. 이 노드는 동일한 네트워크상에서 클러스터명이 같은 클러스터가 존재하는 지 찾게 되는데, 연결가능한 클러스가 있으면 해당 클러스터에 연결되고 없다면 스스로 클러스터를 생성하게 된다.
최초 클러스터 생성시 노드에는 어떤 인덱스도 존재하지 않는다.
새로운 인덱스를 생성할 때 노드에 인덱스를 몇 개의 shard로 나누어 저장할 것인지 정의가 가능하다. shard 개수를 따로 지정하지 않으면 기본적으로 1개(elasticsearch 버전6 이하) 또는 5개(elasticsearch 버전7 이상)로 나누어서 저장된다.
- 노드의 종류
-
Master Node
클러스터에서 인덱스를 만들고 지우는 행위
클러스터에서 노드들을 트래킹하고 각각의 노드에 샤드를 할당할 것인지를 결정
데이터를 인덱싱하고 찾는 작업의 경우 컴퓨팅 자원을 많이 사용하기 때문에 큰 규모에서는 date node와 master node를 구별해준다.
coordinating node처럼 데이터를 라우팅하고 모으는 작업이 가능하지만 이건 마스터 노드의 주 목적이 아니다.기본 설정값: node.master: true node.data: false node.ingest: false node.ml: false xpack.ml.enabled: true cluster.remote.connect: false
-
Data Node
crud, 검색, aggregation과 같이 데이터와 관련된 작업이 가능
인덱싱된 문서를 포함하고 있는 샤드를 관리한다.
데이터를 직접적으로 다루기 위한 리소스 자원이 많이 필요하다
기본 설정값:기본 설정값: node.master: false node.data: true node.ingest: false node.ml: false cluster.remote.connect: false
-
Ingest Node
문서가 인덱싱되기 전에 노드를 변형하고 풍성하기 위해 문서를 ingest pipeline으로 적용이 가능한데, ingest node는 preprocessing 파이프라인 실행한 후 하나 또는 하나 이상의 ingest processor을 모으는 작업을 함
ingest를 로드하는 것은 무거운 일이기 때문에 data node나 master node에서는 node.ingest를 false로 지정할 것을 권장
많은 리소스를 잡아먹기 때문에 ingest node는 별도 지정을 권장기본설정값: node.master: false node.data: false node.ingest: true node.ml: false cluster.remote.connect: false
-
Coordinating Node
요청을 라우팅
검색구절을 조절
bulk indexing분배작업
본질적으로 로드 밸런싱 같은 역할
대량의 노드로 구성된 클러스터라면 코디네이션 노드를 지정하여 역할을 분리하는 것을 권장기본 설정값: node.master: false node.data: false node.ingest: false node.ml: false cluster.remote.connect: false
-
💫Shard란?
일종의 파티션
데이터에 대한 복사본이 아니라 데이터 그 자체(*아래그림참고)
노드가 추가된다면, 기존에 존재하던 shards는 각 노드에 균일하게 재분산
- 샤드 종류
- primary
각 인덱스별로 최소 1개 이상 존재해야함 - replica
- replica 기본값은 1
primary shard와 동일한 복제본이 1개 있다. 즉, replica의 갯수는 primary shard를 제외한 복제본 갯수 - replica가 필요한 이유 :
검색성능과 장애복구
- replica 기본값은 1
- primary
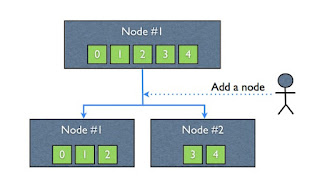 출처 : https://brownbears.tistory.com/4
출처 : https://brownbears.tistory.com/4
참고:
https://brownbears.tistory.com/4
https://wedul.site/622
https://velog.io/@dhjung/2.-Elasticsearch-구조
