elasticsearch
1.docker-elasticsearch 사용

windows10 기준required: wsl2, docker, docker-compose사용법아래 텍스트 .yml 확장자로 저장1) wsl -d docker-desktop2) sysctl -w vm.max_map_count=2621444 키바나에서 샘플 데이터 다운l
2.elasticsearch QueryDSL
정의쿼리를 정의하기 위해 JSON을 기반으로 하는 전체 쿼리 DSL(Domain Specific Language)을 제공.RDMS에 정해진 where문 같은 아이들.score문서와 얼마나 관련있는가에 대한 점수는 \_score 를 통해 알 수 있다.점수계산은 query
3.ES 쿼리문 연습
코딩 진행 방식 : request 로 각 필드값을 받아옴 → es가 원하는 query문 형식으로 변환 → es로 request → es가 준 response 받기 → 원하는 형태로 response 가공후 제공조건 : blue, swashbucklers 가 모두 들어가있
4.elastic filter vs query
.png)
회사에서 elastic를 사용하게 되면서, 나는 elastic에 쿼리를 던져야하는 일이 많아졌다. laravel 과 함께 쓰면서 처음에는 생쿼리로 짜서 elastic에 요청을 보냈으나, laravel-scout 라는 패키지를 알게 되면서 이것과 함께 laravel-sc
5.elasticsearch laravel-scout nested type 쿼리
회사에서 elasticsearch 와 라라벨을 혼용해서 사용하고 있는데, laravel-scout 라는 패키지를 도입해서 사용하고 있다. 사용하기가 어렵긴하지만 없는 것보다 낫다고 생각하고 쓰고있는데, 최근에 nested type 를 검색단에 넣어야되어 너무 고민이
6.match vs terms
💬 ElasticSearch 를 패키지를 사용하면서 되니까 넘어가자 라는 생각으로 했는데, 쿼리를 수정해야할 일이 생겼다. 패키지를 사용하여 검색쿼리를 살펴보니 모든 필드를 terms로만 검색이 되고 있었다. 사실 이 부분에 대해서 terms 사용보다는 검색할때마다
7.elastic fields
elasticsearch 를 하면서, 특정 필드들만 추출해야하는 경우가 있었다. RDB에서 사용하던 select 같은 애가 필요했다. 찾아보니 fields 라는 옵션이 있었다. 오늘은 fields 쿼리에 대해 정리해보고자 한다.검색 응답에서 특정 필드를 검색하기 위한
8.elastic alias
회사에서 alias 처리된 필드에 대해 검색할 일이 생겼는데, 검색해보면서 나온 결과에 대해 공유해보려고 한다. 😐alias 한 필드명과 기존 필드명에 대해서 모두 검색이 가능하다.response로 나온 결과에는 alias한 필드명으로 나오지 않고, 기존 필드명으로
9.Elastic paging 처리
우리가 알고 있는 일반적인 페이지네이션과 같다. 기본적으로 10개씩 조회된다.페이지 번호가 없고 next 버튼만으로 조절할 때 사용할 수 있다. 무한 스크롤시 사용할 수 있다.유저가 특정시간동안 같은 버전의 인덱스를 볼 수 있게 한다. 쿼리에 맞는 많은 양의 문서를
10.엘라스틱서치 개념
간만에 쓰는 개발블로그! 쓸게 쌓여버렸다... 일단 엘라스틱서치 개념! 이건 예전부터 써야지 써야지 하다가 ... 이제야 쓴다 증맬루~ 😣 퇴사하신 분이 ES를 주로 다루셨어서 나는 깔짝깔짝만 봤었는데, 이제 퇴사하셔서.. 자세히 봐야된다... ㅠㅠ esrally라
11.엘라스틱서치 esrally
ES 성능 테스트를 진행하게 되었다. ㅎr... 성장하는 나의 모습! 아쟈아쟈!^^ ㅋㅋesrally라는 것을 통해서 테스트를 진행하게 되었는데, 테스트를 진행하는 순서에 대해 알아볼까 한다.공식문서: https://esrally.readthedocs.io/e
12.엘라스틱서치 filter+must 조합의 텍스트쿼리 성능비교
풘풘한~ 성능테스트의 세계로~ GOGO 🎢서버 갯수: 10대형태소: nori 형태소분석기 사용중테스트하는 인덱스: 1개인덱스의 샤드: shard 3 replica 2인덱스의 문서수: 19,257,330결과\*self.get_random_words = “가나다라마사
13.mcrouter로 memcached add 함수 적용안되는 문제
라라벨에서 mcrouter을 호출하여 저장하면 저장이 제대로 안되는 문제가 있었다. 이것때문에 일주일을 애먹었는데 진짜 별거 아니였어서 너무 화났다..내자신 디버깅도 똑바로 못해... 😭라라벨에서는 캐시를 사용할 때 Cache 파사드 라는 것을 사용한다.이 파사드는
14.elasticsearch bulk insert
담다니담다니담다니담~ elasticsearch는 즐거워허... 🥴 프로젝트의 추가 기획을 위해 기존 ES에 데이터를 넣는 작업이 필요했다. 오히려...좋아..? 가보자고~ 🎢먼저 인덱스를 만들어줘야한다! 이것은 쉬움! REQUEST \-URL 성공시 RESPO
15.elasticsearch reindex 와 mapping
아 어제 당연히 keyword타입으로 ES에 데이터가 들어갈거라고 생각 못하고 한게 실수였다ㅠㅠ 어제 만든 타입들이 모두 text타입으로 들어가서 데이터들의 타입을 모두 바꿔줘야했댜... 찾아보니 보통 한번 넣은 데이터는 그것만 바꿀 수 없고 reindex을 통해 다시
16.elasticsearch 문서 삭제
이번에는 문서가 하나 잘 못 들어가있는 게 있어서 삭제가 필요했다. 🤦♀️ 고고싱...인덱스의 삭제와 마찬가지로 DELETE 메소드를 사용한다.REQUEST성공시 RESPONSEresult가 "deleted"로 표시된것을 볼 수 있다!SOO EASY! 🐸
17.elasticsearch msearch
이미 작성한 줄 알았던 쿼리문...msearch...다시 마주치게 되어서 보니 포스팅이 안되어있어서 작성시작! ✍️개념 🗯️ 여러번 요청을 보내는 것이 아니라 한번의 요청에 여러개의 요청을 담아 보내는 방법사용방법 👣URLBODY사용하면서 찾은 유의점 👩🚒{
18.elasticsearch node query cache + restart
elasticsearch query cache 세팅을 바꿔줘야한다고 해서 이것저것 찾아봤는데 움...이렇게 해도 되나 싶어서 일단 정리만 해봤다. 테스트 진행해보고 수정해줄 부분은 수정해줄 예정이다. 일단 query cache 를 바꿔서 테스트해봤으면 한다는 의견에 따
19.bool > filter > bool vs bool > filter 쿼리 성능차이
결론부터 말하면, "query" : { "bool" : {"filter" : {"must" : {}} } } 보다 "query" : { "bool" : {"filter" : {"bool" : {"must" : {} } } } } 이 성능이 좋다.우리회사에서 운영하는 서
20.elasticsearch 원하는 필드만 조회
elasticsearch BMT가 계속되고 있는 가운데, 나는 서포트하는 역할로 바뀌었다. 서포트라고 하지만, 내가 결과보고 다시 분석해보고 물어보는... 여튼, 그러고 있다! 그 와중에 흥미로운 결과가 하나 있었는데, 바로 원하는 필드만 조회하게 되었을 때 elast
21.should 쿼리 vs msearch
특정 쿼리들만을 가지고 ES검색을 해야하는 경우가 생겨서, 찾아보다가 msearch 와 should 사용하면 원하는대로 나올 수 있을거란 결론이 나왔다. (그런데 msearch 여러 쿼리에 대한 결과가 각각 나오기 때문에, aggregation을 한 후에 sort나 l
22.ES minimum_should_match
기능 수정 요청으로 인해 기존 ES쿼리를 수정했어야했는데, 뭔가 이상한 점이 있었다. (그런데 결국 이 수정요청은 취소됐다^^...ㅎ)아래 쿼리로 요청을 보냈는데 이상하게 결과에 should 에 있는 조건이 하나도 적용이 안된 것이였다. 그래서 검색하다 보니, bool
23.ES 일반SQL질의 사용법
한동안 시험공부에, 아마존 면접에 정신이 없었다.. ㅠㅠ 아마존 면접보고 진짜 내가 찐 바보구나 느낌… ㅎ 아마존 인터뷰 내용은 추후에 생각나는대로 올려볼까한다. 여튼, 본론으로 넘어가자면 회사에서 또 어떤 업무요청이 들어왔다. 그것이 뭐냐하면…예를들어 %꽃관% 라는
24.ES 특정 쿼리에 따른 update 처리하기
앞단에서 이제 찾았으니 데이터를 업데이트해야한다. 알고보니 나..이전에 해본적이 있어..?ㅋㅋㅋㅋ이전에 사용했던 형태는 바로 아래와 같았다.이 경우에는 데이터의 고유값(RDBMS의 pk값이라 할 수 있다)인 \_id 를 사용해야했다. 그런데, 우리는 ES SQL 를 사
25.elasticsearch `tier_preference`
ES 세팅값을 조회해보다가 아무생각없이 지나갔던 "\_tier_preference": "data_content" 이 부분이 뭐지? 하고 의문이 들어서 찾아보게됐다.이를 설명하기 이전에 시계열데이터라는 것을 알아야한다. 이야기가 너무 길어지니 짧게 설명하자면, 일정한 시
26.esrally 병렬 search처리
esrally를 돌릴 때, 특정 쿼리문 돌리고나서 다음 쿼리문을 돌린 후의 성능을 보고싶은 경우가 있었다. 음 그런데 결론적으로는 esrally 자체는 한 쿼리당 하나의 결과만을 보여주고, 요청보낼때도 각 쿼리마다 성능이 달라지니 굳이 한꺼번에 테스트를 할 필요가 없다
27.elasticsearch 인덱스가 사용하는 노드들 조회
BMT를 진행하기 위해 새로운 인덱스를 생성했는데, 팀장님께서 그 인덱스가 사용하는 노드들에는 어떤 게 있는지를 물어보셨다. 엄.. ㅎㅅㅎ.. 하고 있었는데 같은 팀원분이 딱 하고 보여주셨는데 한번 조회해봤던 API였떤 것이 아닌가..! 왜 기억을 못하는 것이여.. 나
28.elasticsearch enabled
회사에서 기획자분이 키바나를 사용하여 쿼리문을 날려 상품들을 QA하고 계신데, (기획자분인데 대단쓰..) 특정 필드가 검색이 안된다 그래서 한번 ES에 있는 그 필드를 쓱- 살펴봤다.💩 원인 : 필드를 살펴보니 아래 코드처럼 enabled: false 로 세팅이 되어
29.elasticsearch 특정 데이터 업데이트
BMT용 ES데이터를 야매로 만들다보니 업데이트 쳐줘야할 일이 많았다. 그래서 업데이트하는 방법을 알아봤는데 두가지 방법이 있었다.⚠️주의⚠️만약, 아래처럼 저장이 되어있었는데 위 필드로 업데이트한다면?띠용?! 😵 원래 저장되어있던 데이터가 사라지고 업데이트한 데이
30.elasticsearch script_field, sort script
script 를 사용했을 때, 성능이 어느정도 나오는지 측정하기 위해 script로 ES쿼리문을 짜봐야했다. 처음에는 계산한 값을 통한 정렬때문에 script를 생각했으나, 필드자체에도 script로 계산한 필드값이 들어가야했다.사용방법사용예시아래 조건을 간단히 설명하
31.elasticsearch nested 타입과 다른 타입의 조건들과 함께 추가, 수정, 삭제, 조회(CRUD) 하는 법
nested type을..아주 많이..사용해야하는 경우가 생겨버렸다…. 🥺 디테일하게 살펴보쟈..!처음에 nested type 필드를 매핑해놓고 아래처럼 몇개 데이터를 미리 넣어뒀다. 기본데이터에 nested 타입에 object 데이터를 추가해보고자 했는데, 처음의
32."caused_by": { "type": "illegal_argument_exception", "reason": "function reference [this::lambda$synthetic$0/3] matching [java.util.function.BiPredicate, test/2] not found due to an incorrect number of arguments" }
elasticsearch 계속하다 조회만 하다보니 이젠 막 헷갈린다.. 뭐가 뭐였는지 ㅠㅠ 이번에는 하다가 제목과 같은 에러가 났다. 그래서 원인찾기 돌입..!아래와 유사하게 코드를 짰는데, "caused_by": {"type": "illegal_argument_exc
33.elasticsearch nested type 필드안에 배열 수정하기
ㅎㅅㅎ… 후 재밌다… 진짜 별의별거 다하는듯 ㅋㅋㅋ 이번에는 데이터 형태를 바꿔서 nested type 필드안에 배열을 넣어 이것저것 해봤다. 다 쓰면 너무 또 길어지니.. 간단히 보겠다.데이터 구조를 보자면 아래와 같다.다행히도 script 로 nestedtypefi
34.sort script 느려짐
흠.. script를 사용해서 elasticsearch 쿼리문을 날려야하는 경우가 생겼는데, 역시나… 성능에 너무나도 문제가 생겨버렸다 ㅜㅜ⇒ 설명 ⭐처음에 clients를 1000으로 세팅해서 돌렸을 때 에러률이 자꾸 100% + all shards failed 라는
35.elasticsearch score로 정렬(sorting)
일반 sort에서 \_script 로는 성능이 너무 나오지 않아서 다른 방법을 강구해보다가 같은 팀원분이 score로도 sort가 가능하니 그걸로 해보자는 의견을 주셔서 바로 실행해봤다.두가지 방법이 있었다.1.function_score 안에 script_sort 사용
36.update_by_query version conflict in elasticsearch
새로운 기능에 대한 테스트를 진행하는 와중 \_update_by_query 라는 API를 사용하는데, VersionConflictEngineException 어쩌구 에러를 발견하게 됐다. 이건 또 뭔데… ㅠㅠ인덱스에 document 에는 각자 관리하는 version이
37.Elasticsearch 집계정보와 표본
후.. 일주일간 아파서 죽는 줄 알았다 ㅠㅠ 이번년도 들어 왜케 자주 아픈지..여튼! 이번에는 ES로 특정필드의 실데이터 표본 100개랑 최대값이랑 중간값, 평균,추출해야할 일이 생겼다. 그래서 구해봄!먼저, 통계집계를 구했다.Request : Response :여기까
38.elasticsearch sort _script
다시 정렬 지옥으로 왔다뤼… 🤯 이번에는 동적으로 정렬할 일이 생겨서 sort script 를 만들게 되었다. 가보자공\~\~~script를 하도 짰었더니 이제는 쉽게 만들었다..하핳…Request:Response :
39.filter vs must
이 내용에 관해 자세히 정리한 것이 없는 것 같아서 다시 정리하기로 결심했다! 또 이제와서 다시 보니 새삼 중요한 부분이라 생각한다.현재 검색할 때 bool>should>filter>must(>terms, >term, >nested 등) 또는 bool>should>mu
40.특정필드에 값이 존재하는 지 확인하는 exists query
가끔 특정 필드에 존재하는 값이 있는지 확인할 경우 exists 쿼리를 사용하는데, 이것도 정리해뒀는지 알았는데 아니였네.. ㅠㅠ쿼리문은 무척 심플하다!이때, 존재하지 않는 필드명을 검색하려면, must → must_not 으로 변경해주면 된다.그런데, nested t
41.ES 다중인덱스 조회시 향상을 위한 방안
회사에서 계속해서 다중인덱스 조회를 원하는 니즈가 있었다. 언젠가 해야지 해야지 했는데 이번에는 진짜 시작해야될듯했다… ㅠㅠ 그래서 찾아보니 검색스피드튜닝(https://www.elastic.co/guide/en/elasticsearch/reference/8.
42.rollover
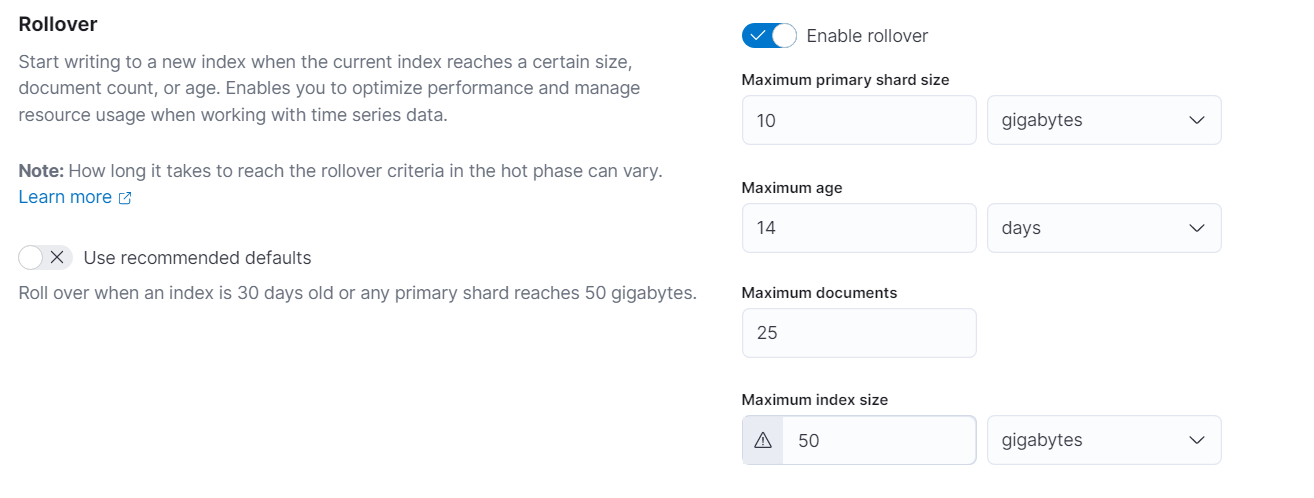
왜케 간만에 쓰는 기분이지 ? 했는데 정말 간만에 쓴다 ㅋㅋㅋ 한동안 다른일때문에 정신이 없었다. 이번주엔 회사에서 로그관련해서 키바나를 한참을 들여다봤는데 뭔가 이상한 것이다.. 자꾸 ElasticsearchSecurityException\[action \[indic
43.elasticsearch percentiles aggregation error
aggregation 을 사용하여 쿼리를 날리는 곳에서 특정 인덱스에 아래와 같은 에러가 생겼다. 그래서 이게 뭐지? 하고 찾아보게 됐다.원인을 찾다가 보니 아래처럼 percentiles aggregation 쿼리문을 사용하고 있는 곳에서 hdr 라는 단어를 발견했다
44.ES aggregation시 모든 카운트 세팅해주지 않음
이번에 생긴 문제는.. ES에 aggrgation 를 사용하여 아래 쿼리처럼 날렸을 때, 분명히 A필드에 a라는 값이 존재함에도 불구하고 count 가 0 으로 나오는 것이였다.agg 쿼리는 내가 짠 게 아니라서 공식문서를 한참 읽었는데, 처음에는 뭔소리인가 하다가 여
45._count API와 agg count가 다름
이건 이전 글과 이어지는데, 이전 글의 문제를 해결하고 나니 agg의 count는 존재했지만 \_count API 를 사용하여 나온 카운트와 값이 달랐다. 무슨 얘기인고 하니…ES agg 쿼리문⇒ 결과 : key a 의 doc_count = 24933count API
46.post_filter in elasticsearch
결과 내 재검색 이라는 기능을 새로 구현해야됐다. 처음에는 검색하지 않고, DB를 거치고 해야되나? 근데 그럼 aggregation,paging, sorting은 어떻게..? 이게 괜찮은건가..? 별의별 생각을 해봤는데 문득 이런 기능 가진 서비스가 많은데? 라는 생각
47.alias field란
인덱스 매핑을 할 때, alias 를 통해 대체 이름을 정의할 수 있다.타겟팅할(path에 지정할) 필드가 생성될 때 존재해야한다.타겟팅할 필드는 구체적인 필드여야한다.예를 들어, object타입의 경우, 타겟팅을 하고자 하는 필드를 명확히 적어줘야한다. ( ex: o
48.reindex 와 alias
회사에서 기존에 많은 데이터가 담긴 인덱스의 스탑태그를 변경해줘야할 작업이 생겼다. 변경하기 위해서는 리인덱싱이 필요했는데, 이전에 리인덱싱을 해본적이 있지만 이번에는 서비스 운영을 하는 도중에 작업을 해야해서 좀 큰 작업이 되었다. 아직 실제로 돌려보기 전이고, 회사
49.Logstash란
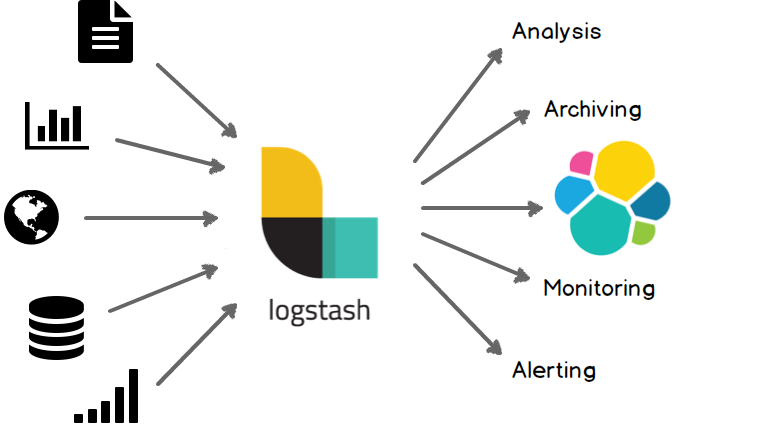
플러그인 기반의 오픈소스 데이터 처리가 가능한 파이프라인 도구데이터 전처리 과정을 별도의 어플리케이션 없이 간단한 설정만으로 수행이 가능함장애 대응 로직 또는 성능 저하 요인등을 쉽게 파악할 수 있는 모니터링 API 제공 https://www.elastic.
50.elasticsearch A필드의 count가 가장 큰 B필드 구하기
elasticsearch 마스터의 길은 멀고도 험하고..ㅠㅠ BMT테스트를 진행하려고 특정 필드(array) 값의 count가 가장 큰 아이가 필요했다. 갑오작오\~\~~ 🏃간단하니 걱정들마십쇼\~~ 아래 쿼리 베껴가심됩니다~A필드 = count 하는 필드 / B필
51.elasticsearch match vs query_string 의 score 계산법
기존에 match 쿼리를 쓰다가 최근 query_string 쿼리를 사용하는 것을 검토할 일이 생겼다. 그런데 결과가 생각한거랑 다르게 나왔다.조회결과내가 예상했던 결과는, 3번이 먼저 나오는 것이였다. 왜냐하면.. 아직 체리샴푸 소중한시간 라운드카라 맨투맨 에서 라운
52.elasticsearch score랑 explanation score 다름
이것도 query_string을 테스트해보다가 알게되었는데, 나는 explanation.value값으로 score 계산을 하는 걸로 알고 있어서 같은 값이겠지 했는데 실제 explanation.value값과 score값은 다르더라.조회결과이렇게 했을 때 내 생각에는 검
53.elasticsearch multi_match best_field와 most_field
점점 심화되는 elasticsearch 과정..ㅠ\_ㅠ 이번에는 muti_match 쿼리를 사용해볼 일이 있어서 살펴보다가 정리도 해야겠다 싶어서 작성하게 되었다.다중 필드에 쿼리를 한번에 날려서 질의를 하기 위한 match 쿼리이다.각 필드에 wildcard 사용도
54.ingest pipelines
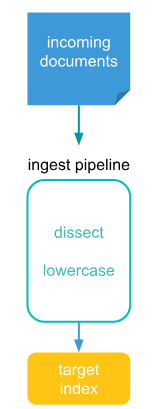
회사에서 서비스 확장을 위해서 특정 인덱스에 담겨있던 데이터를 다른 인덱스에 옮겨줘야할 일이 생겼다. 같은 팀원분이 pipeline으로 하면 된다고 알려줘서 그에 대해 알아보고자 한다.인덱싱전에 데이터를 보완처리하여 수집할 수 있다. 프로세서 를 통해 가능한 작업을 수