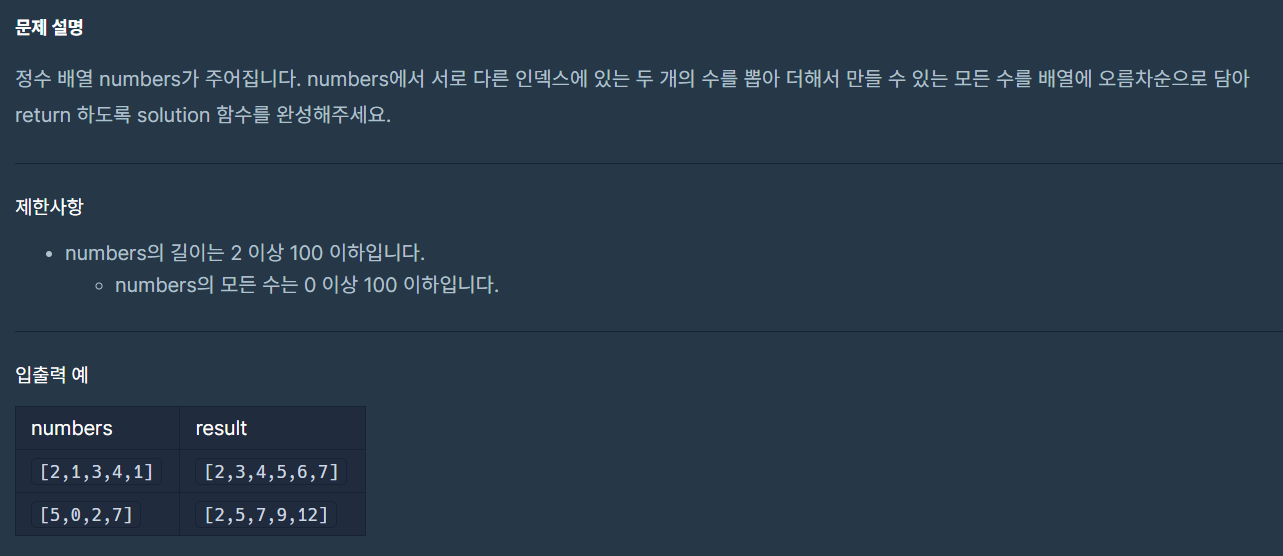
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
vector<int> solution(vector<int> numbers) {
vector<int> answer;
vector<int> temp;
for (int i=0; i<numbers.size(); i++)
{
for (int j=i+1; j < numbers.size(); j++)
{
temp.push_back(numbers[i] + numbers[j]);
}
}
sort(temp.begin(), temp.end());
temp.erase(unique(temp.begin(), temp.end()), temp.end());
answer = temp;
return answer;
}원래는 temp.earse(unique(temp.begin(), temp.end()), temp.end()); 대신에
for (int i=0; i<temp.size() - 1; i++)
{
if (temp[i]==temp[i+1])
{
temp.erase(temp.begin() + i);
}
}이렇게 지우려고 했는데 자꾸 몇 개는 안 지워진다.
그래서 그냥 찾아보니 unique stl을 발견했다.
std::unique
#include <algorithm>
#include <iostream>
#include <vector>
int main()
{
// a vector containing several duplicate elements
std::vector<int> v{1, 2, 1, 1, 3, 3, 3, 4, 5, 4};
auto print = [&](int id)
{
std::cout << "@" << id << ": ";
for (int i : v)
std::cout << i << ' ';
std::cout << '\n';
};
print(1);
// remove consecutive (adjacent) duplicates
auto last = std::unique(v.begin(), v.end());
// v now holds {1 2 1 3 4 5 4 x x x}, where 'x' is indeterminate
v.erase(last, v.end());
print(2);
// sort followed by unique, to remove all duplicates
std::sort(v.begin(), v.end()); // {1 1 2 3 4 4 5}
print(3);
last = std::unique(v.begin(), v.end());
// v now holds {1 2 3 4 5 x x}, where 'x' is indeterminate
v.erase(last, v.end());
print(4);
}output
@1: 1 2 1 1 3 3 3 4 5 4 //초기상태
@2: 1 2 1 3 4 5 4 //unique
@3: 1 1 2 3 4 4 5 //sort
@4: 1 2 3 4 5 //unique그냥 unique를 쓰면 붙어있는 것들에 대해서만 지운다.
목적에 따라 sort()를 적절히 쓰면 좋을 것 같다.
다른 사람들의 풀이를 보니까 set가 중복을 허용하지 않는 특성을 이용했다.
#include <string>
#include <vector>
#include <algorithm>
#include <set>
using namespace std;
vector<int> solution(vector<int> numbers) {
vector<int> answer;
set<int> st;
for(int i = 0;i<numbers.size();++i){
for(int j = i+1 ; j< numbers.size();++j){
st.insert(numbers[i] + numbers[j]);
}
}
answer.assign(st.begin(), st.end());
return answer;
}std::set
#include <algorithm>
#include <iomanip>
#include <iostream>
#include <iterator>
#include <set>
#include <string_view>
template<typename T>
std::ostream& operator<<(std::ostream& out, const std::set<T>& set)
{
if (set.empty())
return out << "{}";
out << "{ " << *set.begin();
std::for_each(std::next(set.begin()), set.end(), [&out](const T& element)
{
out << ", " << element;
});
return out << " }";
}
int main()
{
std::set<int> set{1, 5, 3};
std::cout << set << '\n';
set.insert(2);
std::cout << set << '\n';
set.erase(1);
std::cout << set << "\n\n";
std::set<int> keys{3, 4};
for (int key : keys)
{
if (set.contains(key))
std::cout << set << " does contain " << key << '\n';
else
std::cout << set << " doesn't contain " << key << '\n';
}
std::cout << '\n';
std::string_view word = "element";
std::set<char> characters(word.begin(), word.end());
std::cout << "There are " << characters.size() << " unique characters in "
<< std::quoted(word) << ":\n" << characters << '\n';
}output
{ 1, 3, 5 }
{ 1, 2, 3, 5 }
{ 2, 3, 5 }
{ 2, 3, 5 } does contain 3
{ 2, 3, 5 } doesn't contain 4
There are 5 unique characters in "element":
{ e, l, m, n, t }애초부터 중복허용 안 할거면 set를 쓰는 게 나은데, 데이터 쪼물딱 거리고 싶다면 unique를 쓰거나 multiset을 쓰면 될 것 같다.
