
🚩 프로젝트 개요 및 목적
프로젝트 개요
제로베이스에서 진행한 프로젝트로 시카고 매거진에 샌드위치 맛집 50개를 정리해놓은 사이트에서 데이터를 추출하는게 목표이다. 또한, 미국 지도에 시각화 작업을 진행한다.
url = https://www.chicagomag.com/chicago-magazine/november-2012/best-sandwiches-chicago/프로젝트 목표
총 50개의 샌드위치 페이지에서 각 가게의 정보를 가져온다
- 가게이름
- 대표메뉴
- 대표메뉴의 가격
- 가게주소
🚩 크롬 개발자 도구 - 태그 추출
🔎 메인페이지 태그 정보
- 사이트에 들어가서 스크롤하면 50개의 샌드위치가 순서대로 있다.
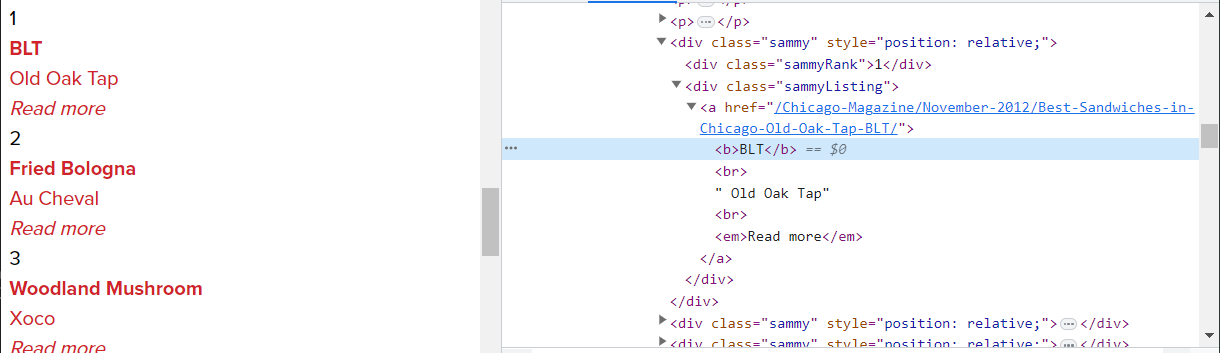
- 메인페이지에서 필요한 태그 정보
<div class="sammy" style = "position: relative;"> #상위 태그
<div class="sammyRank">1</div> #순위
<div class="sammyListing">
<a href ="~~"> # 주소
<b>BLT</b> # 메뉴 이름
<br>
" Old Oak Tap" # 가게 이름
<br>🔎 하위 페이지 태그 정보
- 그다음 각 샌드위치 하위 페이지를 들어가면 가격과 실제 주소의 정보를 얻자
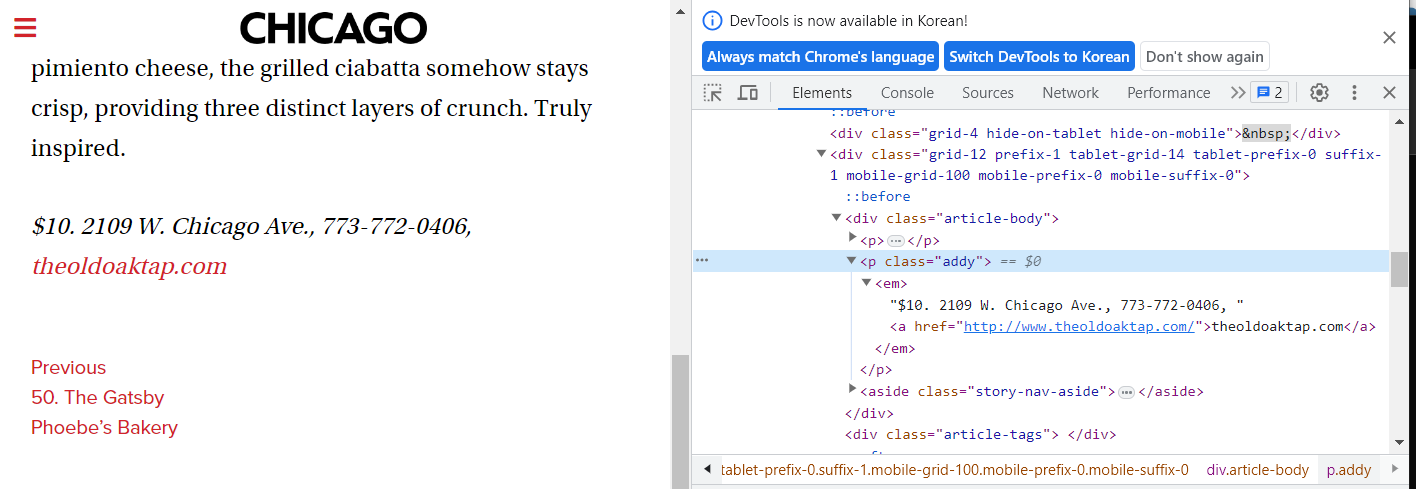
- 하위페이지에서 필요한 태그 정보
<p class="addy">
<em>
"$10. 2109 W. Chicago Ave., 773-772-0406, " # 가격, 실제 주소
<a href ="~~"> # 웹주소
</em>🚩 beatifulsoup 작업
🔎 사이트 불러오기
- 우리가 일반적으로 부르는 방법으로 불러보자.
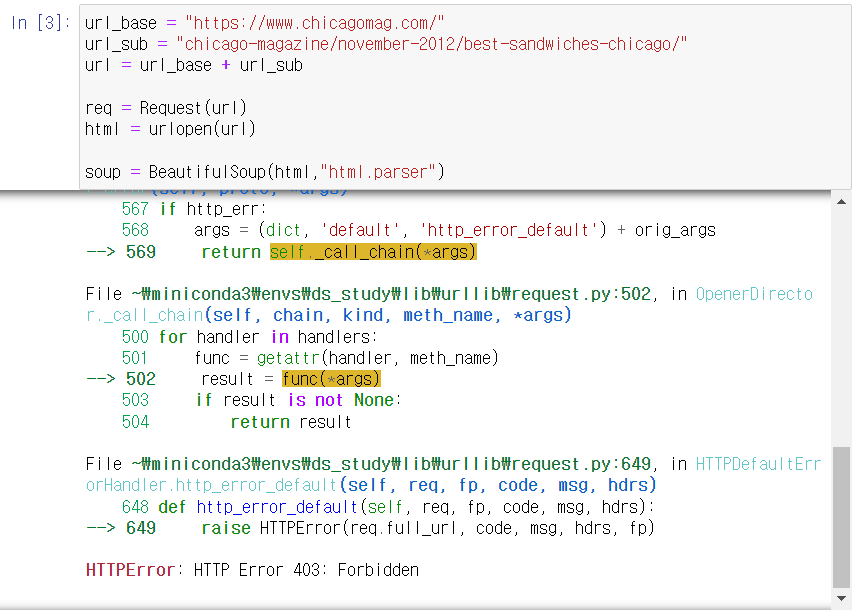
그러면 403 error가 뜰 것이다. 이 에러는 클라이언트의 요청이 서버에 전달되었지만, 권한 때문에 거절되었다는 것을 의미한다. 많은 사이트에서 무분별한 크롤링, 스크래핑을 막기 위해 정보를 주지 않는 곳이 꽤 많다. 이럴때는 User Agent 정보를 headers에 추가해서 전달해주면 해결된다.
정석적인 방법
# 개발자도구 -> 네트워크 탭 -> 왼쪽 아래에 접속하려는 홈페이지 클릭 -> headers 맨 아래에 User-Agent 정보 확인.
하지만 fake_useragent 모듈을 활용하면 간단하다. 모듈을 import하고 요청할때 헤더값을 추가하면 된다. 위의 정석적인 방법으로 헤더값을 가져올 수도 있다.
🔎 1위 샌드위치 정보 파싱
- sammyRank에 순위 정보
- sammyListing에 주소, 메뉴이름, 가격이름이 있다.
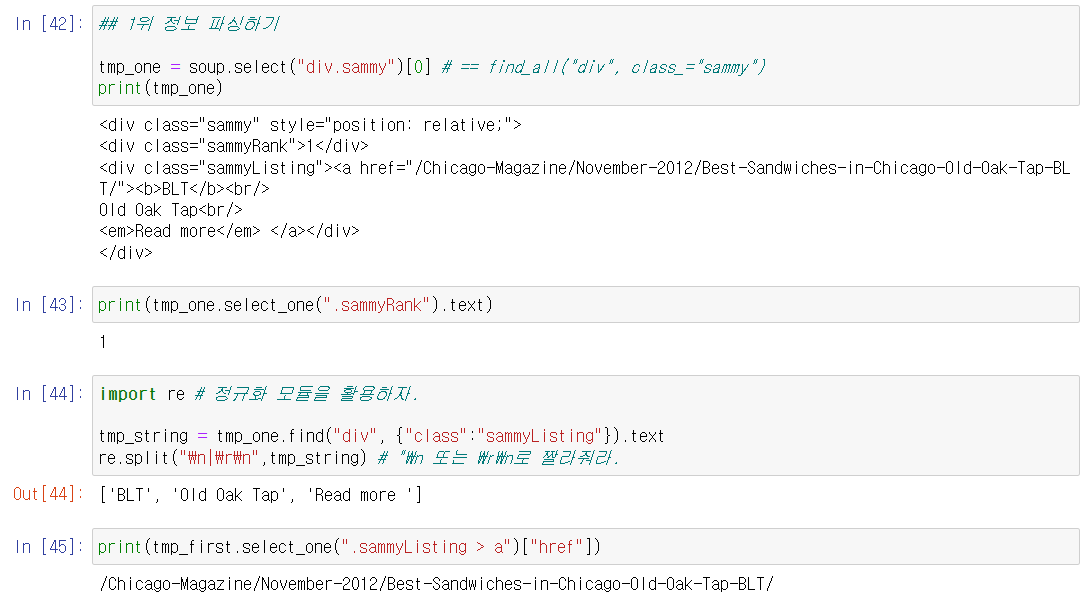
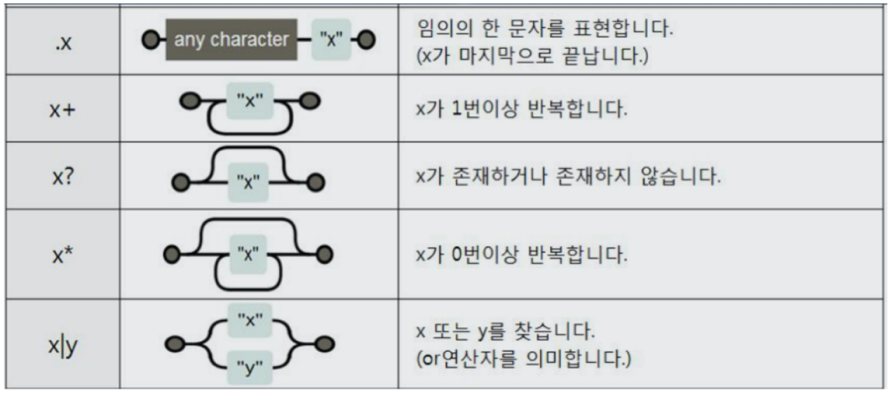
여기서 정규표현식 모듈(regular expression)을 사용했는데 매우 유용한 모듈이니까 알아두면 좋다.
🔎 모든 샌드위치 정보 파싱
- 위에서 파싱한 방법을 반복문으로 반복하여 50개의 샌드위치 정보를 추출하자.
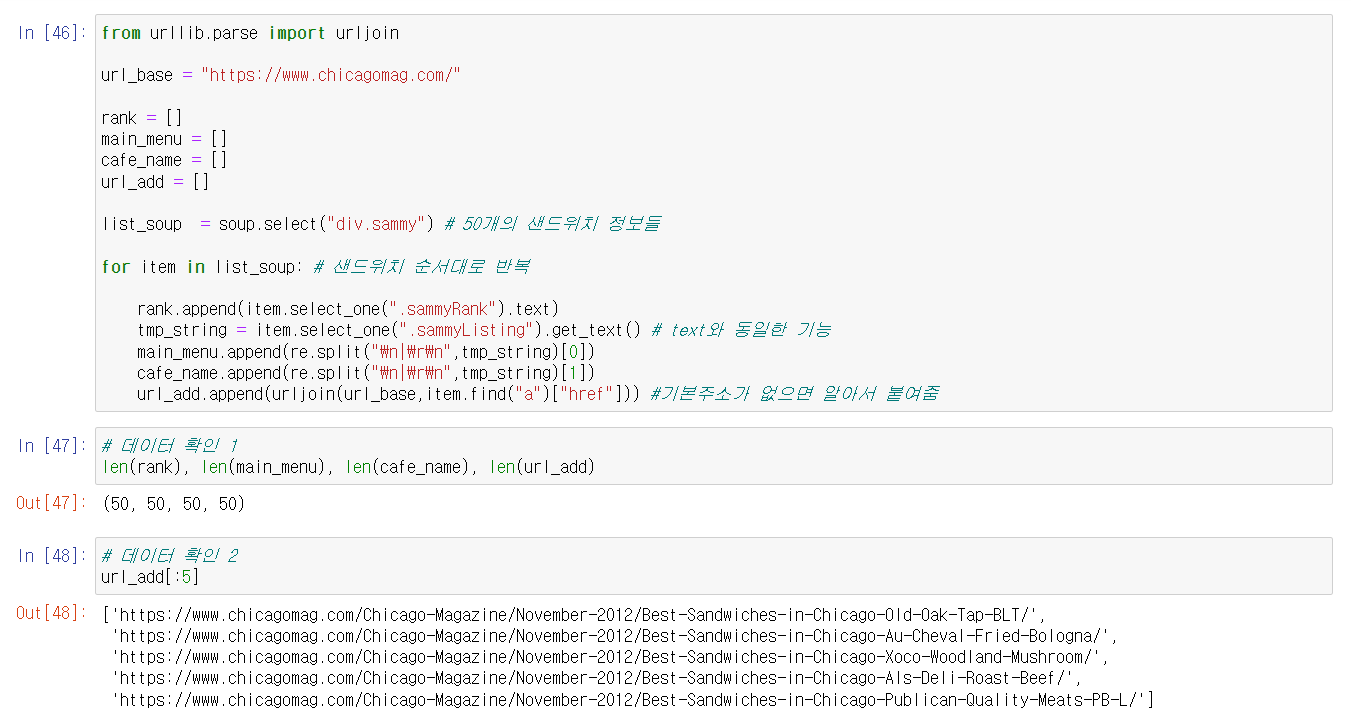
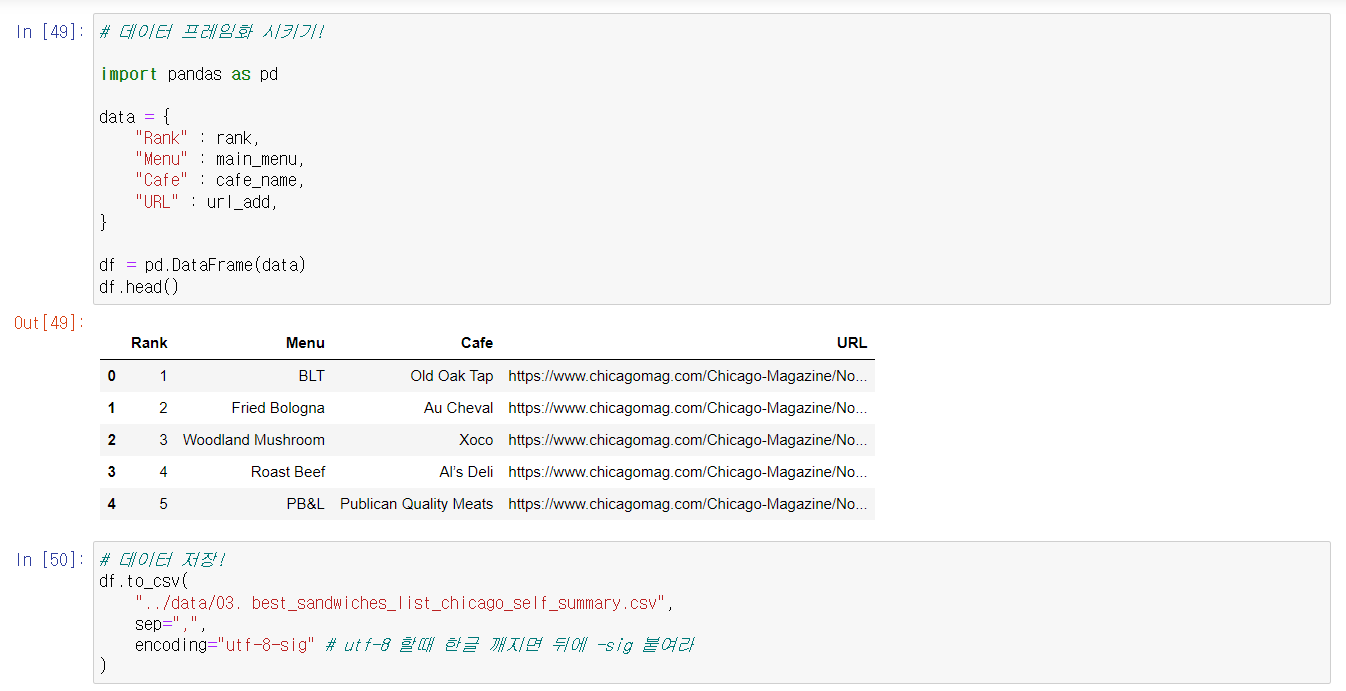
🔎 데이터 프레임화 시키기
- 데이터 분석하기 좋게 pandas 데이터프레임으로 만들자
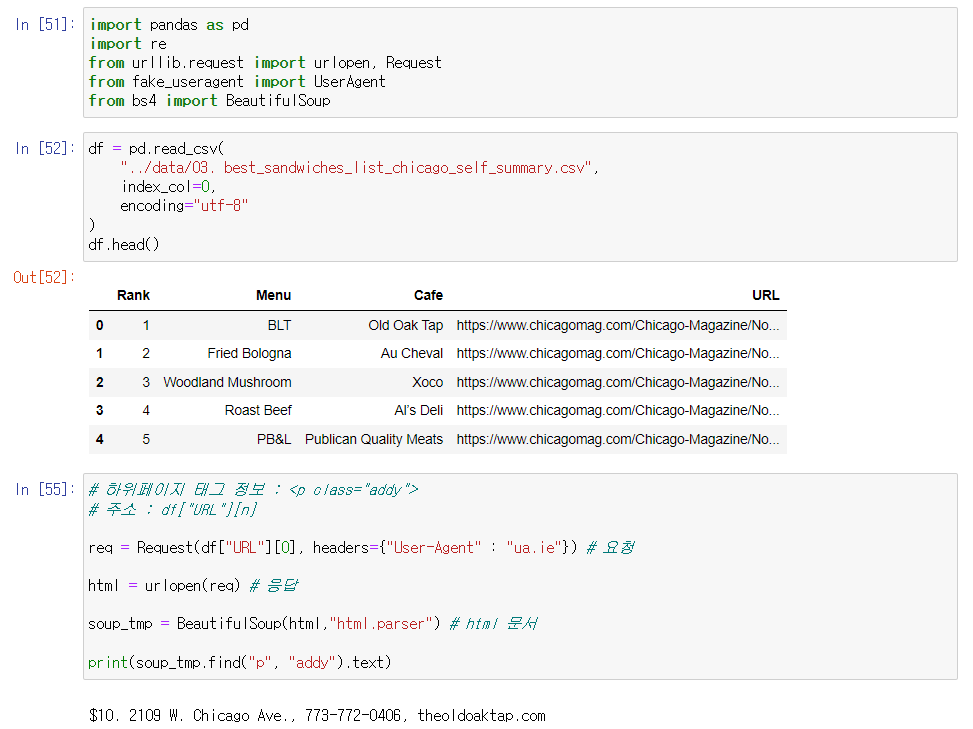
🔎 하위페이지 정보 추출
- 이제 저장파일을 불러와 각 샌드위치의 주소에 들어가서 추가 정보를 추출하자.(가격, 실제주소)
🔎 가격정보, 실제주소로 파싱
- 정규 표현 모듈을 활용해 텍스트를 잘라내자.

정규표현 모듈 간단 설명
위 표현식의 설명.re.search("\$\d+\.(\d+)?", text_tmp).group()
- 문자열을 스캔하여 정규식 패턴이 일치하는 첫 번째 위치를 찾는다. (찾지 못하면 None 반환)
- 패턴 : 숫자로 시작하다가 꼭 . 을 만나고 그 뒤에는 숫자가 있을 수도 있고 없을 수도 있다.
- group() : 찾은 위치까지 문자열로 반환
자세한 것은 아래 사이트 참조
출처 : https://toramko.tistory.com/entry/python-%ED%8C%8C%EC%9D%B4%EC%8D%AC-re-%EB%A1%9C-%EC%A0%95%EA%B7%9C%EC%8B%9D-%ED%8C%A8%ED%84%B4-%EB%AC%B8%EC%9E%90%EC%97%B4-%EC%B2%98%EB%A6%AC%ED%95%98%EA%B8%B0
🔎 파싱 50번 반복
- tqdm 모듈을 활용하면 진행상황을 보여준다.


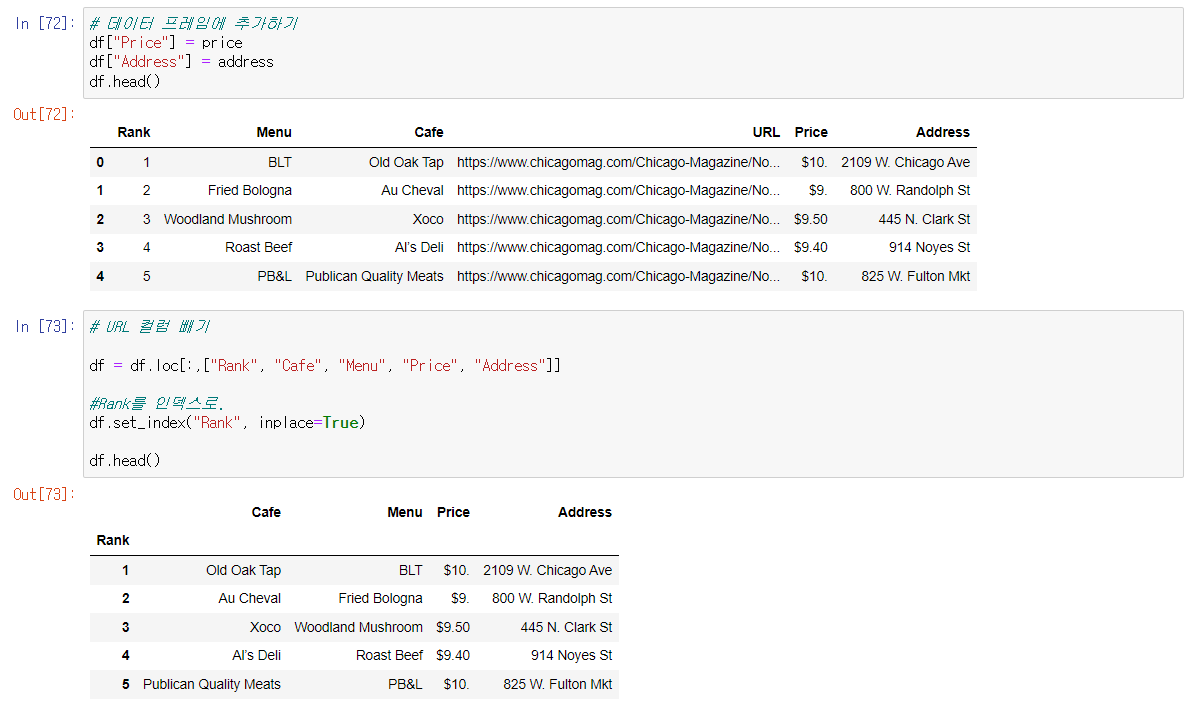
🔎 데이터프레임에 새로운 데이터 추가
- 가격, 실제주소를 데이터프레임에 넣자.
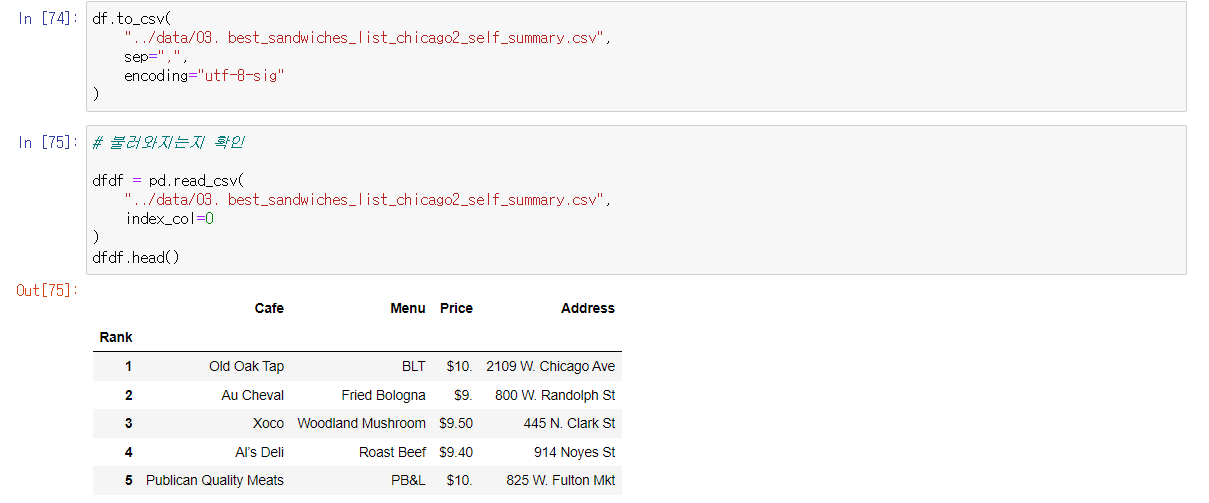
🔎 데이터프레임 저장
이제 다음 포스트에서 시각화를 해보겠다.

코린이 공부중