
🚩 예제 1. 네이버 금융
🔎 크롤링 목표
https://finance.naver.com/marketindex/
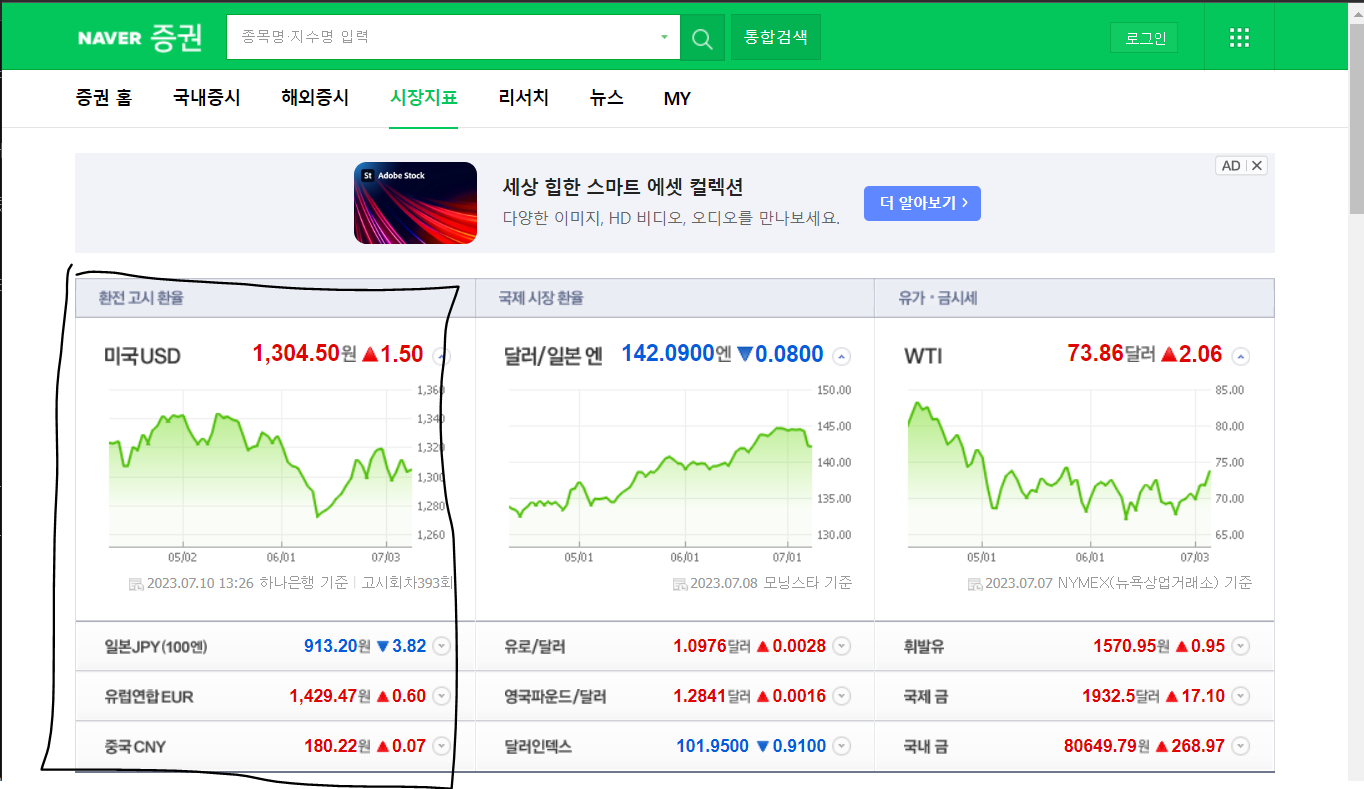
이번 예제에서는 네이버금융 시장지표에서 미국USD, 일본JPY, 유럽연합EUR, 중국CNY의 환율, 상승 or 하락, 지수를 추출해 보겠다.
🔎 크롬 개발자 도구 - 태그 추출
- 크롬에서 웹사이트의 Html 태크를 보기위해서는 크롬 개발자 도구에 들어가야한다.
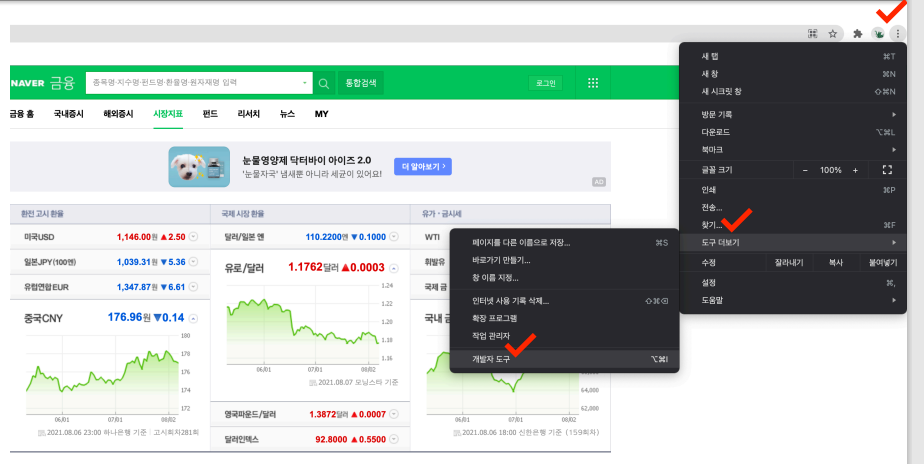
- 그 다음 element 선택 아이콘을 클릭한 후 웹사이트에서 내가 원하는 부분에 가져가서 클릭한다.
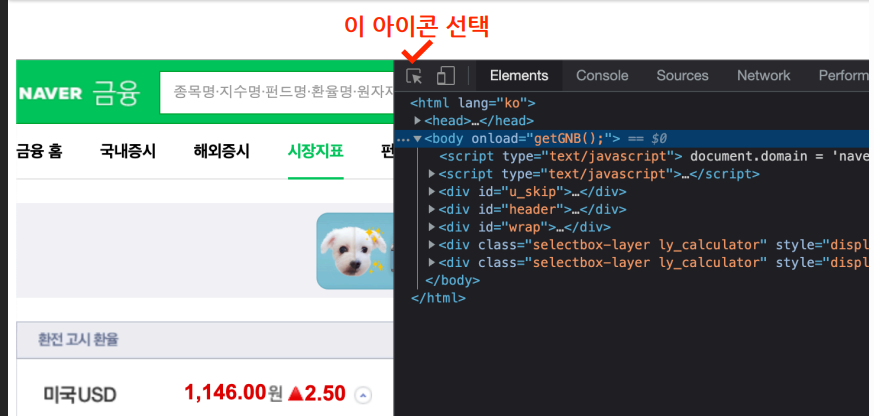
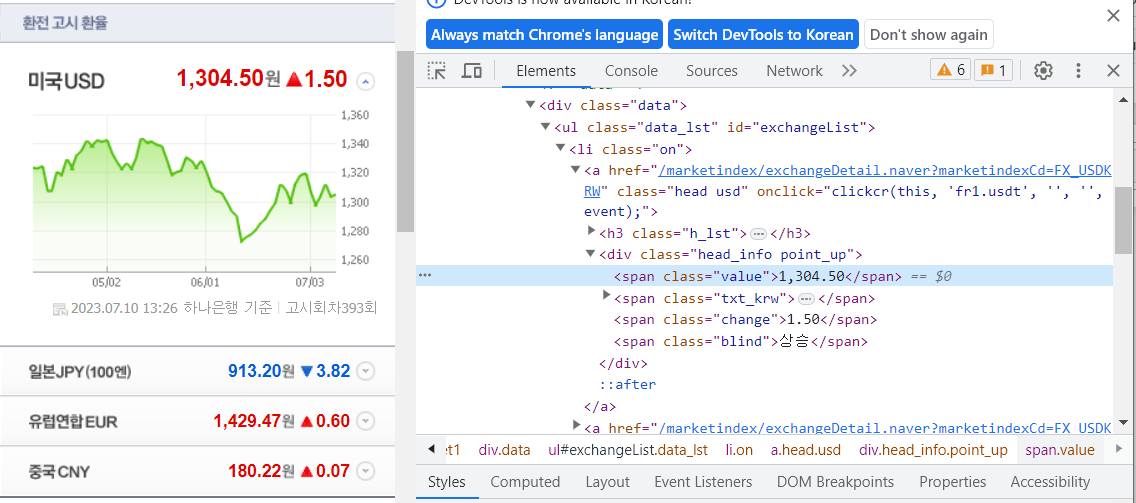
- 내가 필요한 태그 정보들
<ul class="data_lst" id="exchangeList"> : 상위 태그
<li class="on">
<a href ="~~"> : 주소
<h3 class="h_lst"> : # 이름
<div class="head_info point_up">
<span class="value">` : 환율
<span class="change">` : 상승 or 하락 지수
<span class="blind">` : 상승 or 하락🔎 beautifulsoup
- 먼저 네이버 금융 사이트의 html 문서를 불러오자.
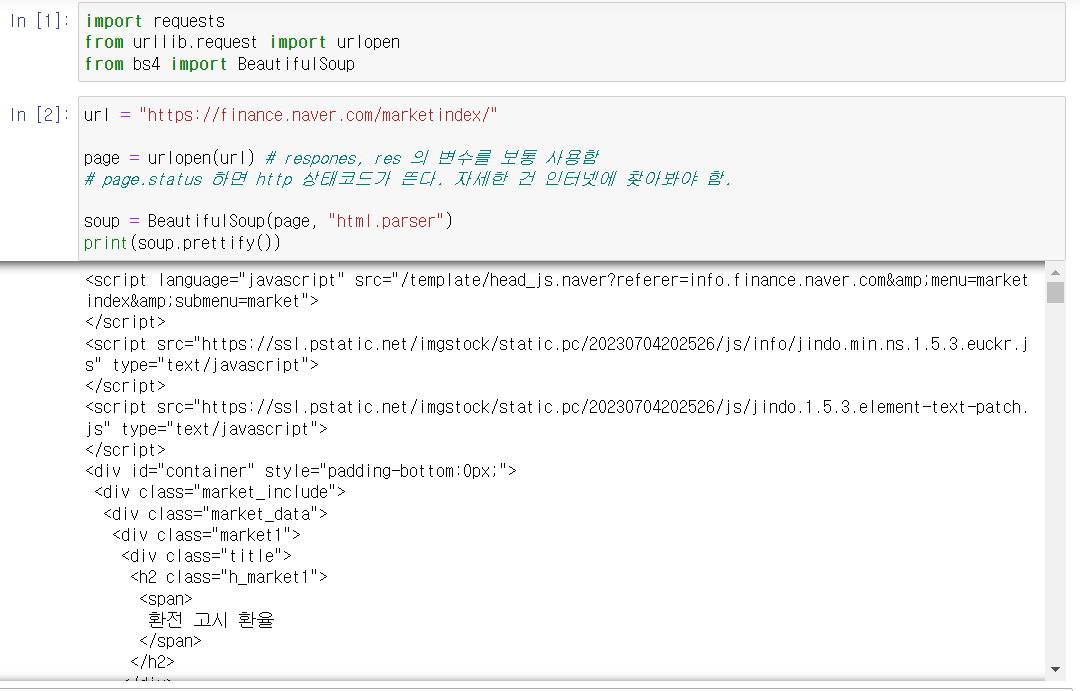
- 위에서 찾은 상위 태그의 ID로 검색한다.
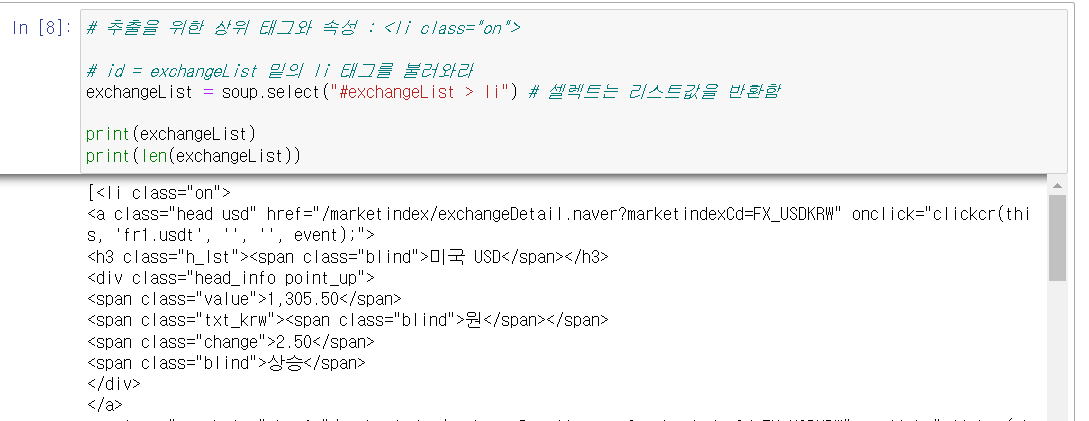
exchangeList에
미국 USD
일본 JPY(100엔)
유럽연합 EUR
중국 CNY
의 정보가 각각 리스트로 들어있다.- 이제 하위 태그들의 text 및 주소 정보를 추출한다.
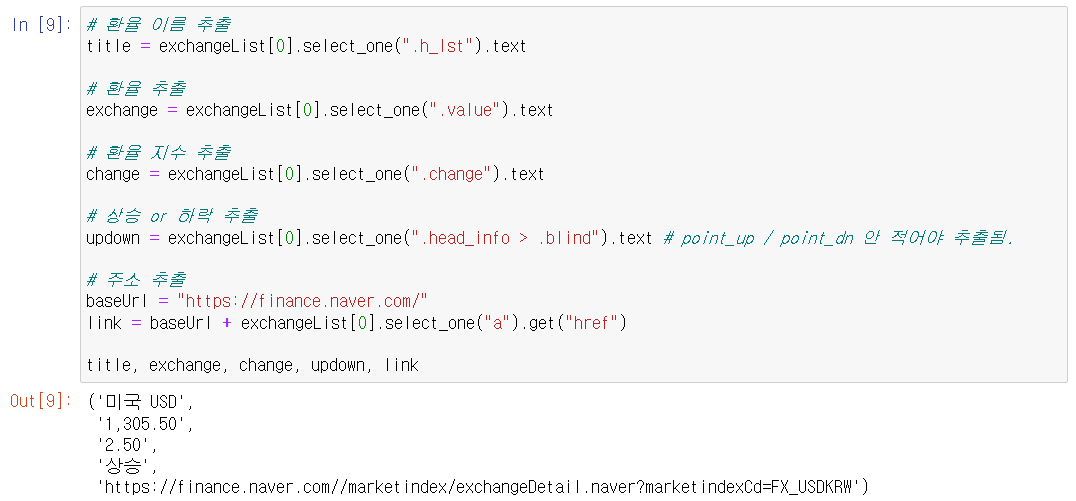
- 주소 앞부분이 짤려 나오기에 base 주소를 따로 만들어 합쳐준다.
- 속성에 띄어쓰기가 있는경우 하위 속성이라 취급한다.
- head_info point_up => .head_info.point_up 으로 검색하면 된다.
head_info_point_up 이슈
- 추출해보면 head_info_point_up과 head_info_point_dn으로 나뉜다.
- 이는 상승과 하락에 따라 속성값이 바뀌는 것을 볼 수있다.
- 그래서 이대로 반복문을 사용하면 none 값이 추출 된다.
- 그래서 point_up, point_dn은 빼주는 게 추출에 맞는 방법이 된다.
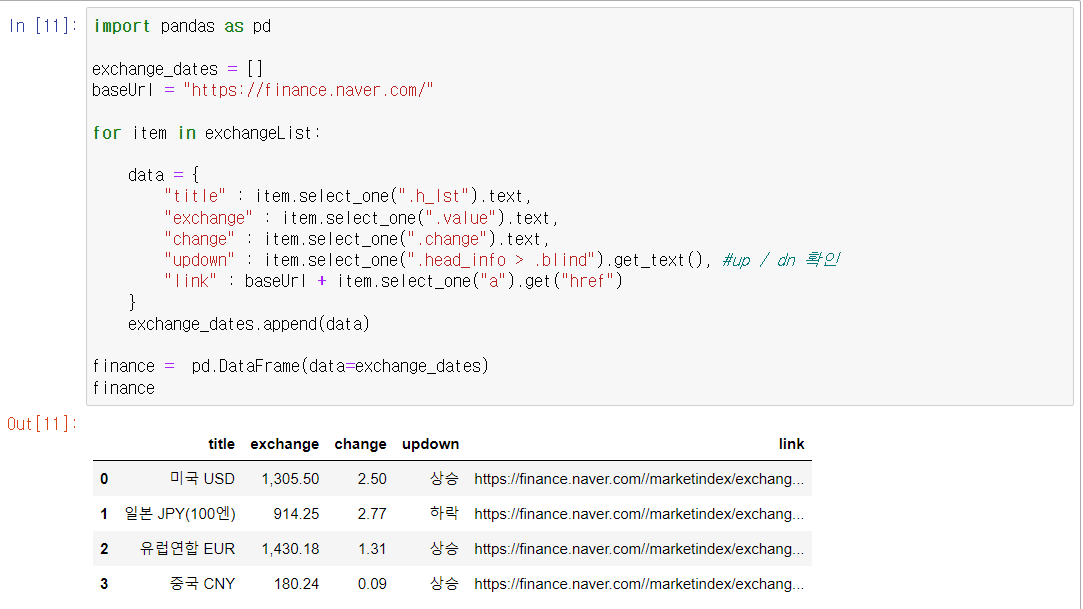
- 추출한 데이터를 반복문으로 리스트에 담고 데이터프레임으로 나타내자.
🚩 예제 2. 위키백과
🔎 크롤링 목표
https://ko.wikipedia.org/wiki/%EC%97%AC%EB%AA%85%EC%9D%98_%EB%88%88%EB%8F%99%EC%9E%90
이번 예제에서는 여명의 눈동자 위키백과 사이트에서 주요 인물 목록을 추출해보겠다.
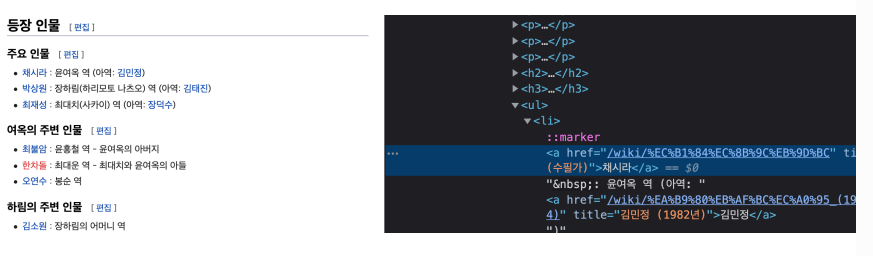
- 내가 필요한 태그 정보들
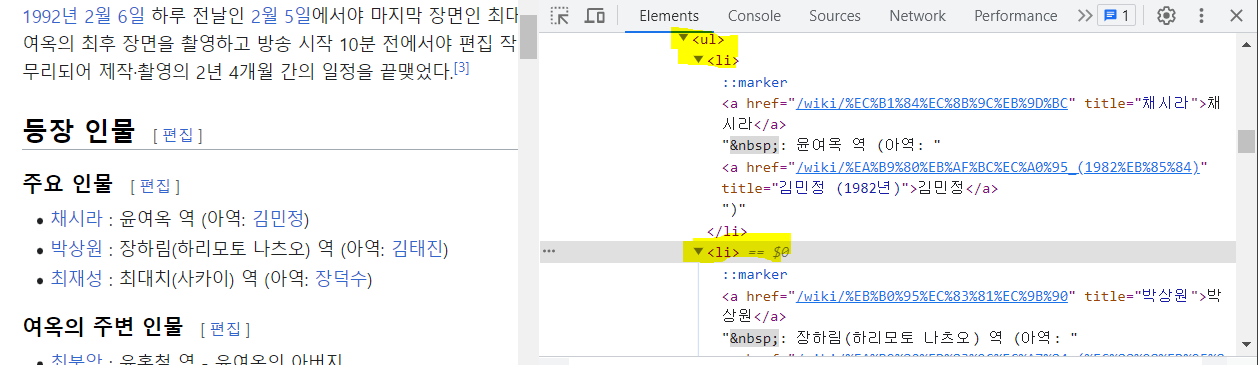
<ul> : 상위 태그
<li>
<a href ="~~" title="채시라"> : title 속성
채시라
</a>🔎 크롬 개발자 도구 - 태그 추출
🔎 beautifulsoup
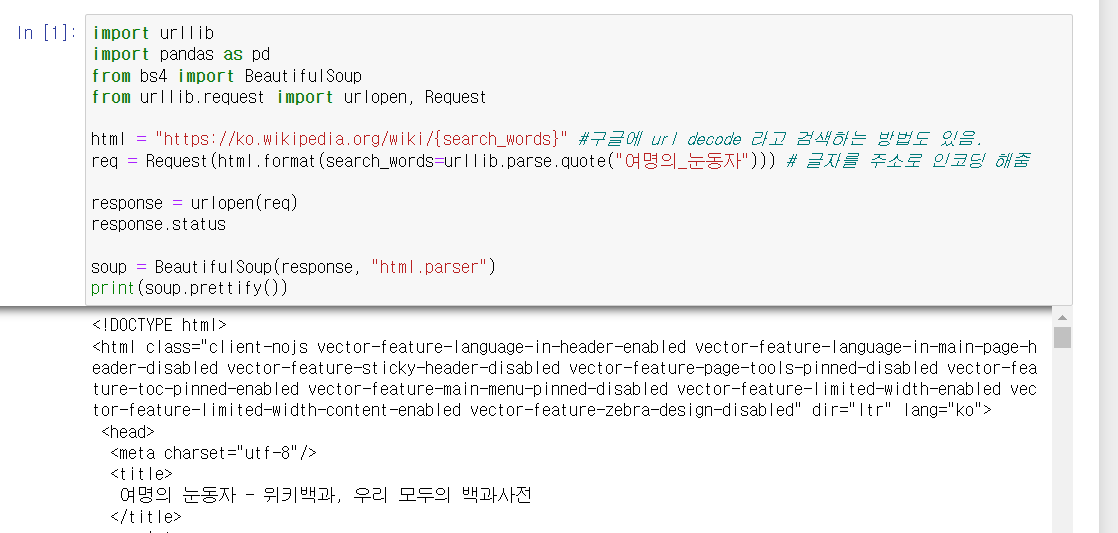
먼저 주소를 불러오자
- 이때 주소를 복사해서 붙여넣으면 이상하게 불러와진다.
- 한글주소는 디코딩을 해주어야 한다...
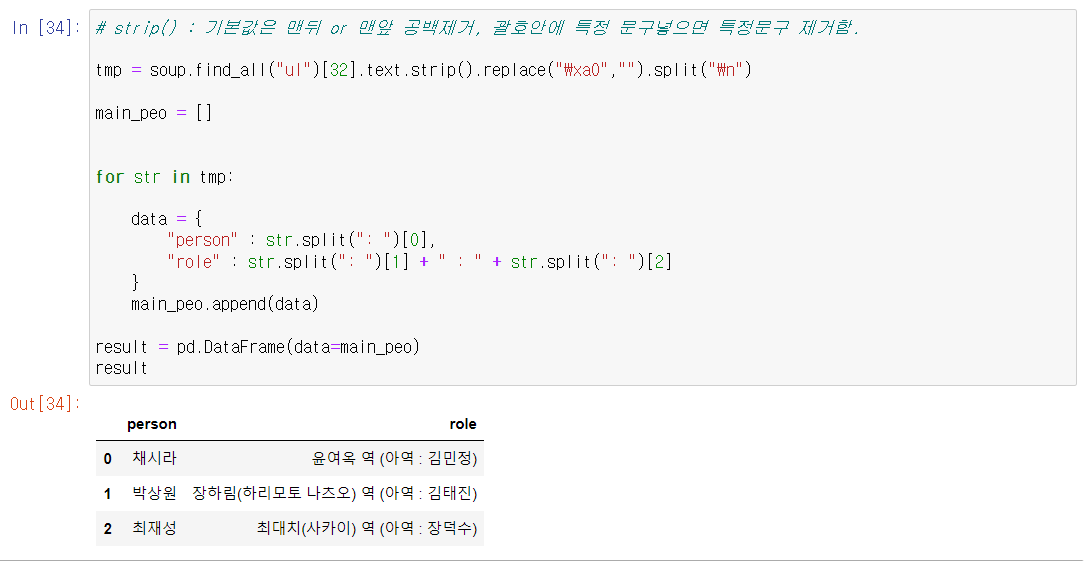
- ul 태그를 검색하면 너무 많아서 번호를 매겨서 추출해본다.
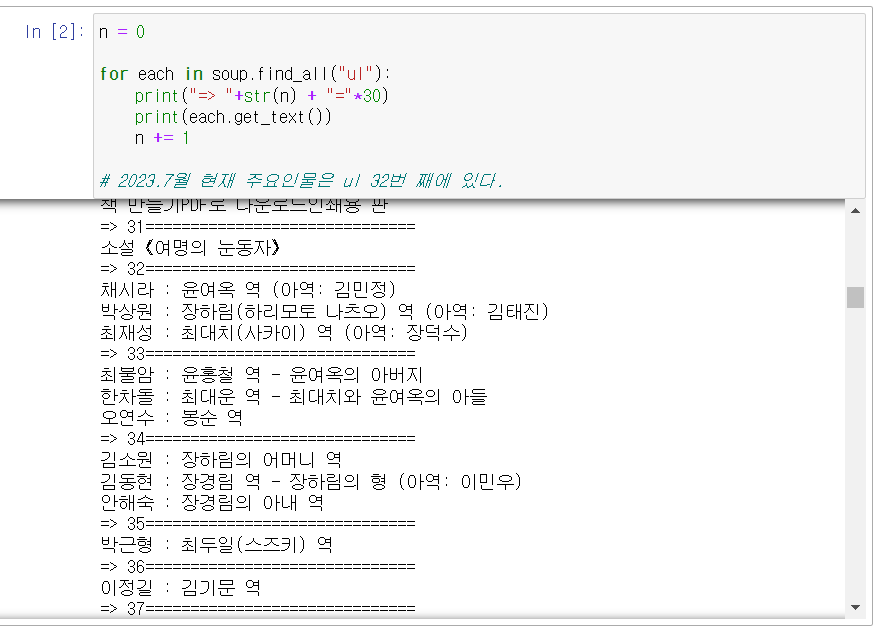
32번째에 주요 인물이 있음을 확인했다.- 이제 텍스트를 파싱하여 데이터프레임으로 만들자.

코린이 공부중