정렬 알고리즘을 시리즈로 정리해볼까 한다.
정렬은 알고리즘 기본 중의 기본이니 하나씩 정복해보자..! ✍🏻
Bubble Sort
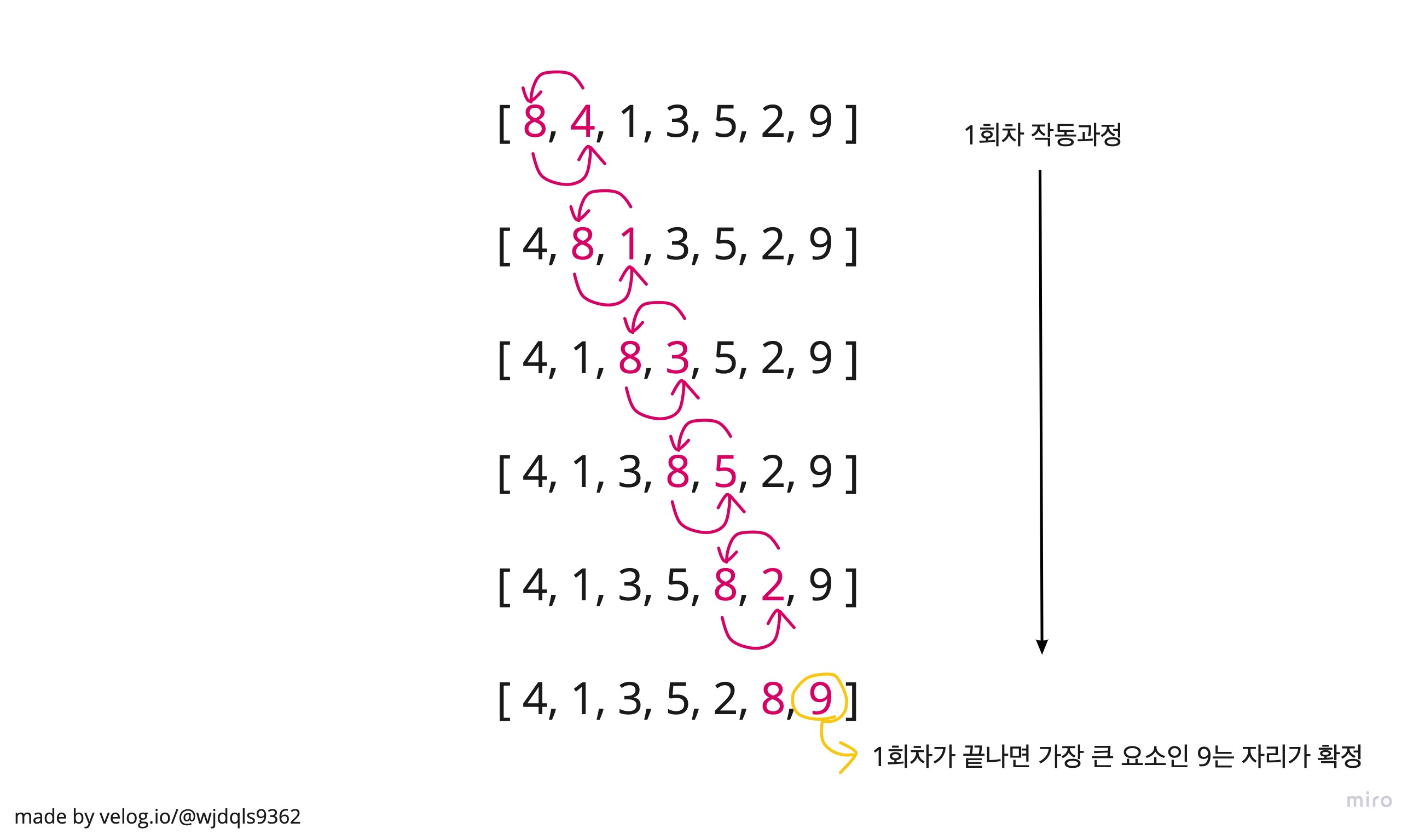
버블 정렬은 두 인접한 원소를 검사해 정렬하는 방법이다. 원소의 이동이 거품이 떠오르는 듯 보여서 지어진 이름이라고 한다.
순차적으로 인접 원소를 검사해 정렬하기 때문에, (index : (0, 1)>(1, 2)>(2, 3)...)
1회전이 끝나면 요소 중 가장 큰 요소는 가장 끝 자리로 정렬된다.
즉, n번째 정렬이 끝나면 뒤에서 n번째(로 큰) 요소의 자리가 확정된다.
정렬 시 추가적인 메모리를 사용하지 않고 데이터의 공간 내에서 정렬해 메모리가 절약되지만,
O(n^{2})의 시간복잡도로 상당히 느리고 성능이 안좋아 거의 잘 사용하지 않는다고 한다.
function bubbleSort(arr) {
for (let i = 0; i < arr.length; i += 1) { // 배열의 길이만큼 반복해서 정렬
for (let j = 0; j < arr.length - i; j += 1 { // n회차 정렬. n회차가 끝나면 n번째로 큰 요소의 자리는 확정되기 때문에 array.length - i 만큼 반복
if (arr[j] > arr[j + 1]) { // 인접 요소의 왼쪽 요소가 오른쪽 요소보다 크면 자리를 바꿔줌
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
return arr;
};Quick Sort
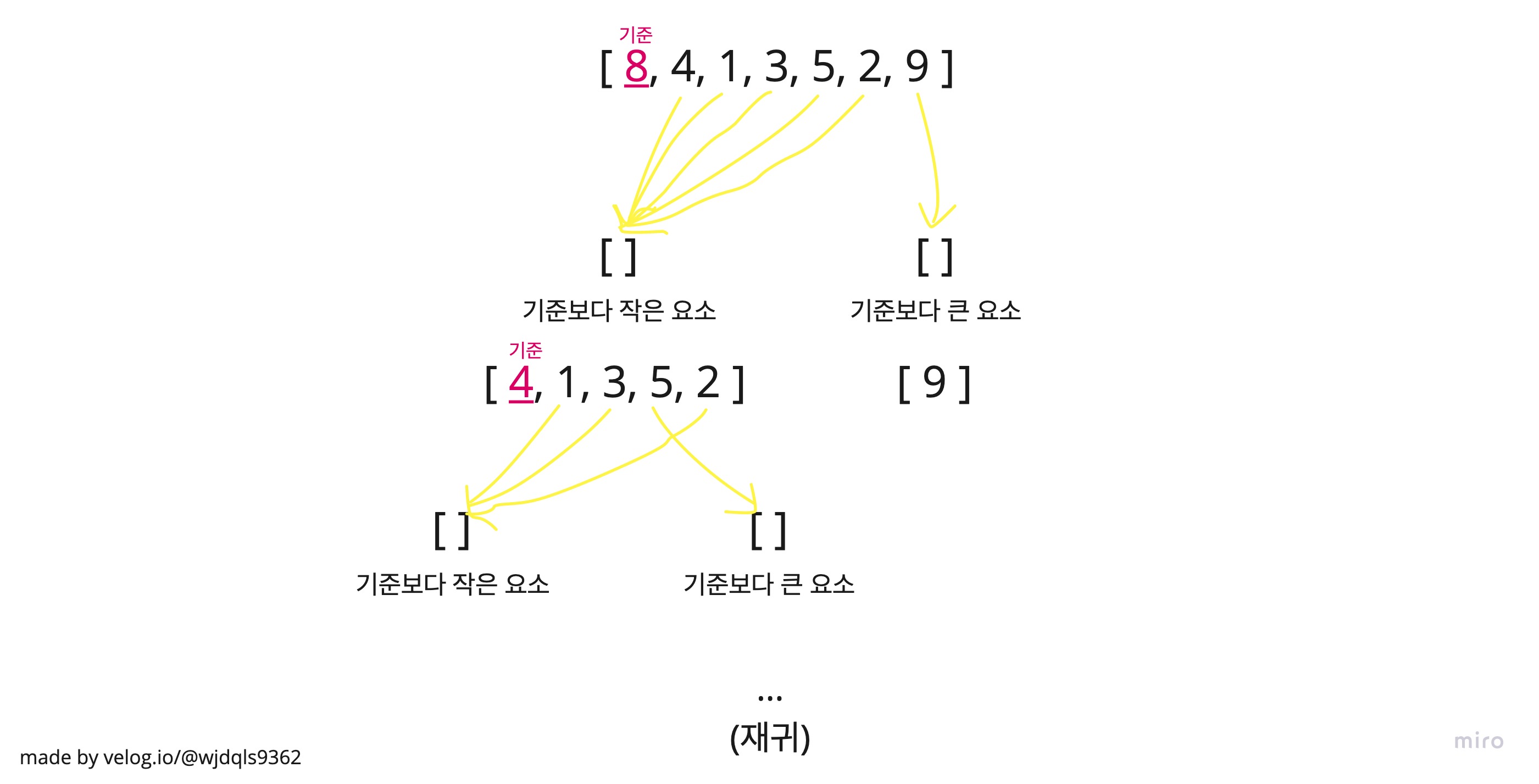
퀵 정렬은 분할-정복(Divide and Conquer) 알고리즘이다.
기준(pivot)을 정하고 중심축보다 작은 요소를 왼쪽으로, 기준보다 큰 요소를 오른쪽으로 보낸다. 그렇게 서로 나뉜 데이터들의 중심축에서 또 좌우 배분을 재귀를 통해 반복하면 최종적으로 요소들이 정렬된다. 보통 O(NlogN)의 시간복잡도를 가진다. (같은 O(NlogN)인 합병 정렬보다 두 배 더 빨라 더 많이 쓰인다고 한다!)
그러나, 로직에서 결정되는 모든 기준이 데이터의 가장 작은 요소이거나 큰 요소일 경우(최악의 경우)에 시간복잡도가 O(n^{2})로 성능이 낮아질 수 있다.
또한, 동일한 요소가 여러 개 있는 경우, 정렬 이후에 초기 순서와 달라질 수 있으므로 unstable한 성질을 가진다고 한다.
function quickSort(arr) {
if (arr 길이가 1보다 작은경우) return arr;
const pivot = arr[0];
const left = [];
const right = [];
for (let i = 1; i < arr.length; i += 1) { // 기준을 arr[0]으로 정했으므로 i는 1부터 시작
if (arr[i] <= pivot) left.push(arr[i]);
else right.push(arr[i]);
}
// 기준을 중심으로 나뉜 배열을 재귀로 다시 정렬 진행
const leftRecursion = quickSort(left);
const rightRecursion = quickSort(right);
return [...leftRecursion, pivot, ...rightRecursion];
}