[JavaScript] TWIL : 자료구조 1/3 Stack, Queue (20/10.22~10.27)
0

Data Structure sprint를 진행중이다.
이번 스프린트는 대표적인 자료구조를 직접 구현해본다.
자료구조는, 자료(data)를 다루는 방식이다.
현재 1/3지점까지 진행했고, 구현한 자료구조는 총 2가지이다.
1. Stack
2. Queue
이번 sprint는 대학교에서 한 학기를 잡고 하는 정도의 양이라, 그렇게 깊은 속성까지는 이해하기 어렵다는 엔지니어분들의 말씀이 있었다. 나도 학습하면서 짧은 시간에 많은 구조를 다뤄야하는 탓에,, 적당히 공부하고 넘어간 듯 하다.
그래서 sprint를 진행하며 학습한 부분까지정도만, 일단 블로깅하려한다. (직접 그린 그림과 함께.. ㅎ)
추후에 이 구조들에 대해 더 깊이 공부하는 시간이 생긴다면 글을 더 보완, 추가 할 예정이다.
1. Stack
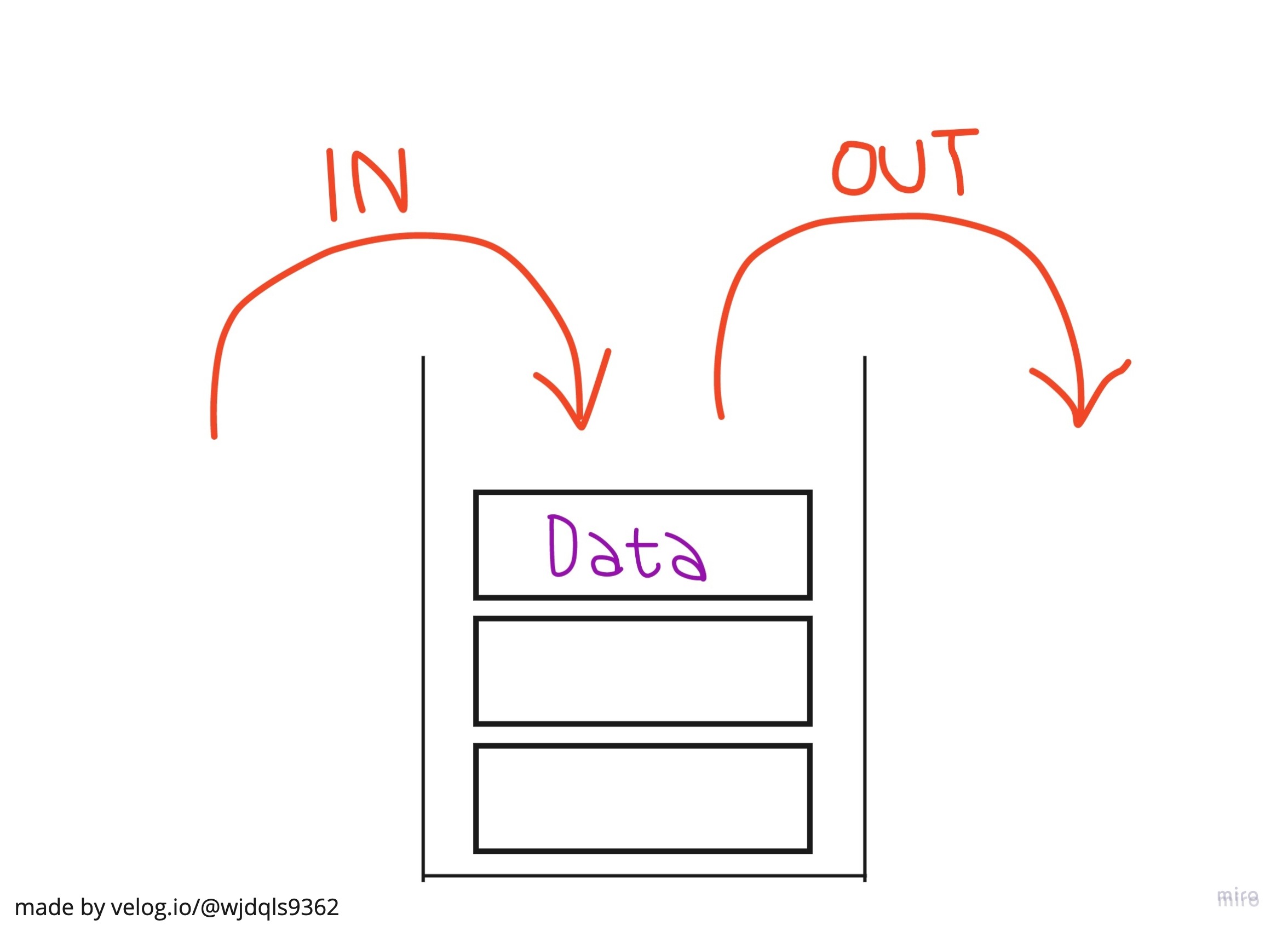
Stack은 LIFO(Last In, First Out)방식의 자료구조 이다. 소위 '쌓여있는 접시'라고 많이 비유한다.
data를 추가해도 가장 위(최신)에, 빼와도 가장 위(최신)의 것을 빼온다.
대표적으로 최근 방문한 사이트 history, 함수의 call stack 같은 기능이 stack을 이용한 것이라고 보면 된다.
Property(속성)
- 가장 위(최신)의 data를 가리키는 top
- 저장공간을 명시하는 storage
Method
- 데이터의 저장된 크기를 나타내는 size()
- 데이터를 삽입하는 push(data)
- 가장 최신의 데이터를 빼오는 pop()
- 그 외에도 isEmpty(), isFull() 등 구현 정도에 따른다.
Psuedo Code
size() {
// top속성을 활용, top은 push됨에 따라 top++될 것이므로,
// top을 return 하면 그것이 바로 size가 될 것임
}
push(data) {
// 1. storage의 top인덱스에 data를 할당
// 2. top을 ++처리
}
pop() {
// 1. 변수에 storage의 top에 해당하는 data를 찾아서 저장
// 2. 그 data는 삭제
// 3. 만약, 삭제 후의 top이 0이 아니라면 top을 --처리
// 4. data를 저장했던 변수를 return
}2. Queue
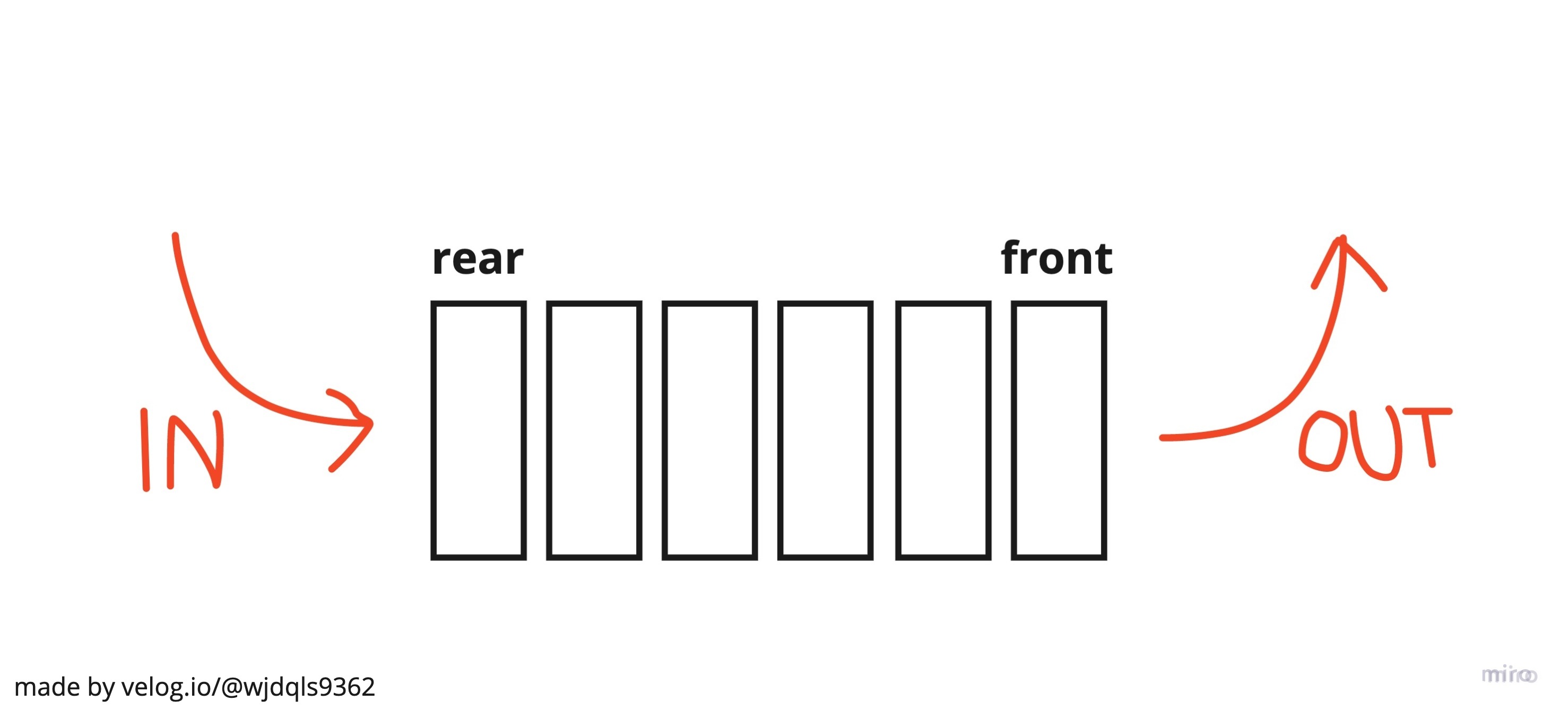
Queue는 FIFO(First In, First Out)방식의 자료구조이다. 소위 말하는 '대기열'이다.
가장 먼저 들어온 data가 가장 먼저 뽑혀나간다.
대기순번 call 등 대기열 기능을 필요로하는 기능에 쓰인다.
Property
- 저장공간 storage
- 가장 앞을 가리키는 front
- 가장 뒤를 가리키는 rear
Method
- 데이터의 저장된 크기를 나타내는 size()
- 가장 뒤에 데이터를 삽입하는 enqueue(data)
- 가장 앞의 데이터를 빼오는 dequeue()
- 그 외 peek() 등 구현 정도에 따른다.
Psuedo Code
size() {
// 가장 뒤를 가리키는 rear를 return하거나,
// 혹은 배열이면 length, 객체면 키만 뽑아내 그 길이를 return
}
enqueue(data) {
// 1. rear에 data 할당
// 2. 상황에 따라 front, rear 따로 처리해야 할 것
}
dequeue() {
// 1. 변수에 front가 가리키는 data 저장
// 2. 해당 data 삭제
// 3. 만약, rear가 현재 0이 아니라면 front++, rear-- 처리
// 4. 만약, rear가 0이라면 front는 0으로 처리
// 5. data를 저장해뒀던 변수 return
}
Back-end. You'll Never Walk Alone.