[JavaScript] TWIL : 자료구조 2/3 linkedList, hashTable (20/10.22~10.27)

Data Structure sprint를 진행중이다.
2/3지점까지 진행했고, 이번에 구현한 자료구조는 총 2가지이다.
이번에도 직접 그린 자료구조와 함께.(ㅎ)
1. linkedList
2. hashTable
1. linked List
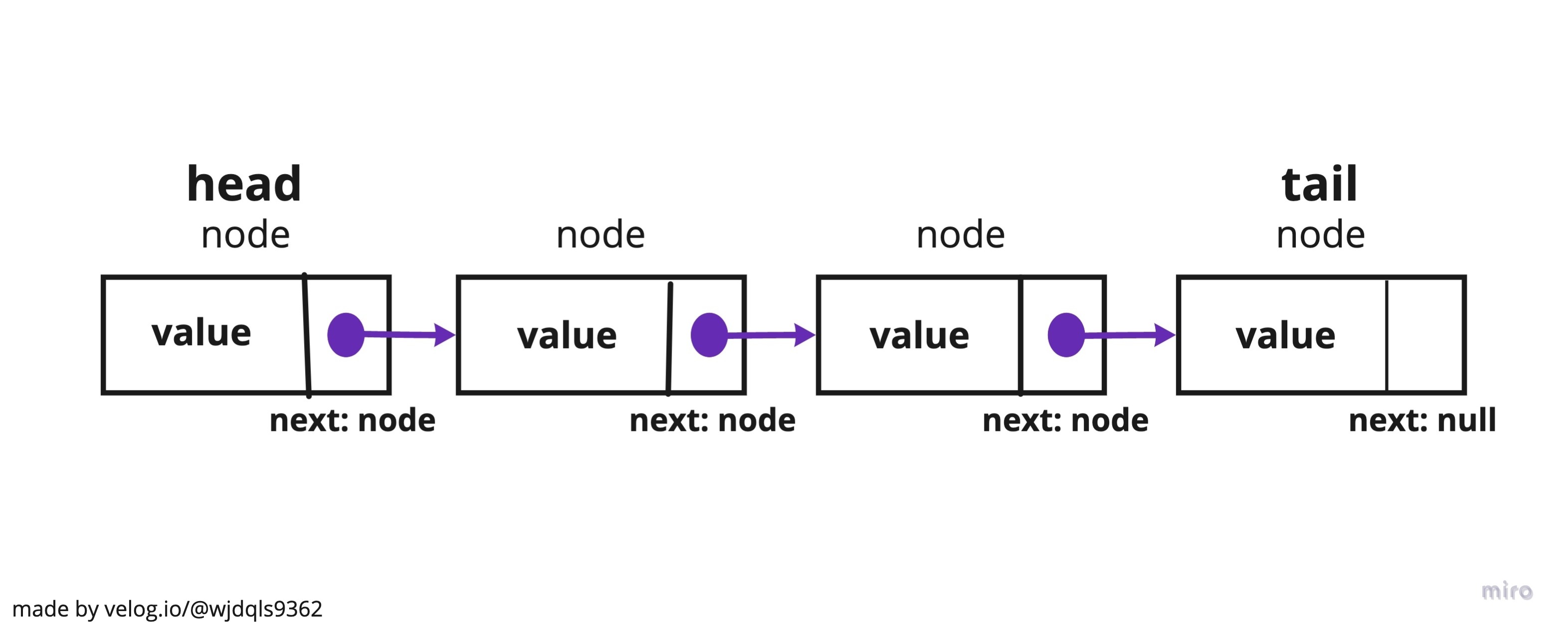
likedList는 요소가 node로 이루어진, 크기가 동적인 자료구조이다.
node는 value(data)와 next(pointer)라는 속성을 가지고 있고, 각 node들은 next 속성에 의해 연결되어 있다.
위의 그림은 data가 한 쪽 방향으로만 연결되어 있는 Singly-linkedList(단일 연결 리스트)이다.
data가 양 방향의 pointer를 가지는 Doubly-linkedList(이중 연결 리스트)도 있다. 이는 prev, next라는 2개의 pointer를 가지고 있어, 양 방향 순회가 가능하다.
linkedList가 쓰이는 대표적인 기능은 음악 재생 목록이다. 곡 건너뛰기, 이전/다음으로 넘어가기 등의 구현이 가능하다.
이번에 내가 구현한 것은 단일 연결 리스트이다. 이를 살펴보자.
Property
- value(data)
- 다음 노드를 가리키는 next
Method
- list의 끝에 data를 추가하는 addToTail(data)
- data를 찾아 제거하는 remove(data)
- 해당 index의 node를 가져오는 getNodeAt(index)
- data의 존재여부를 반환하는 contains(data)
- 해당 data의 index를 가져오는 indexOf(data)
- data의 총 개수를 알려주는 size()
- 그 외 구현 정도에 따른다.
Psuedo Code
addToTail(data) {
// 1. 입력받은 data를 가진 node를 생성
// 2. 만약, 리스트가 비어있다면 해당 node를 head이자 tail로 할당
// 3. 아니라면, 리스트의 tail의 next에 해당 node를 할당하고, 이를 tail로 지정
}
remove(data) {
// 1. data가 head일 경우 : head를 다음 node로 지정 (연결이 자동으로 끊길 것)
// 2. data가 tail일 경우 : 그 이전의 노드를 tail로 지정
// 3. 그 외 : data node의 이전 node와 다음 node를 연결(.next.next)
}
getNodeAt(index) {
// 해당 index만큼 node를 이동해 해당 node를 return
}
contains(data) {
// 리스트를 순회하여 해당 data를 찾으면 true를, 찾지 못하면 false를 return
}
indexOf(data) {
// 리스트를 순회하여 도중에 일치하는 값을 찾으면 해당 index를, 찾지 못하면 -1을 return
}
size() {
// 리스트를 순회하여 tail에서의 i(index)를 return
}2. hashTable
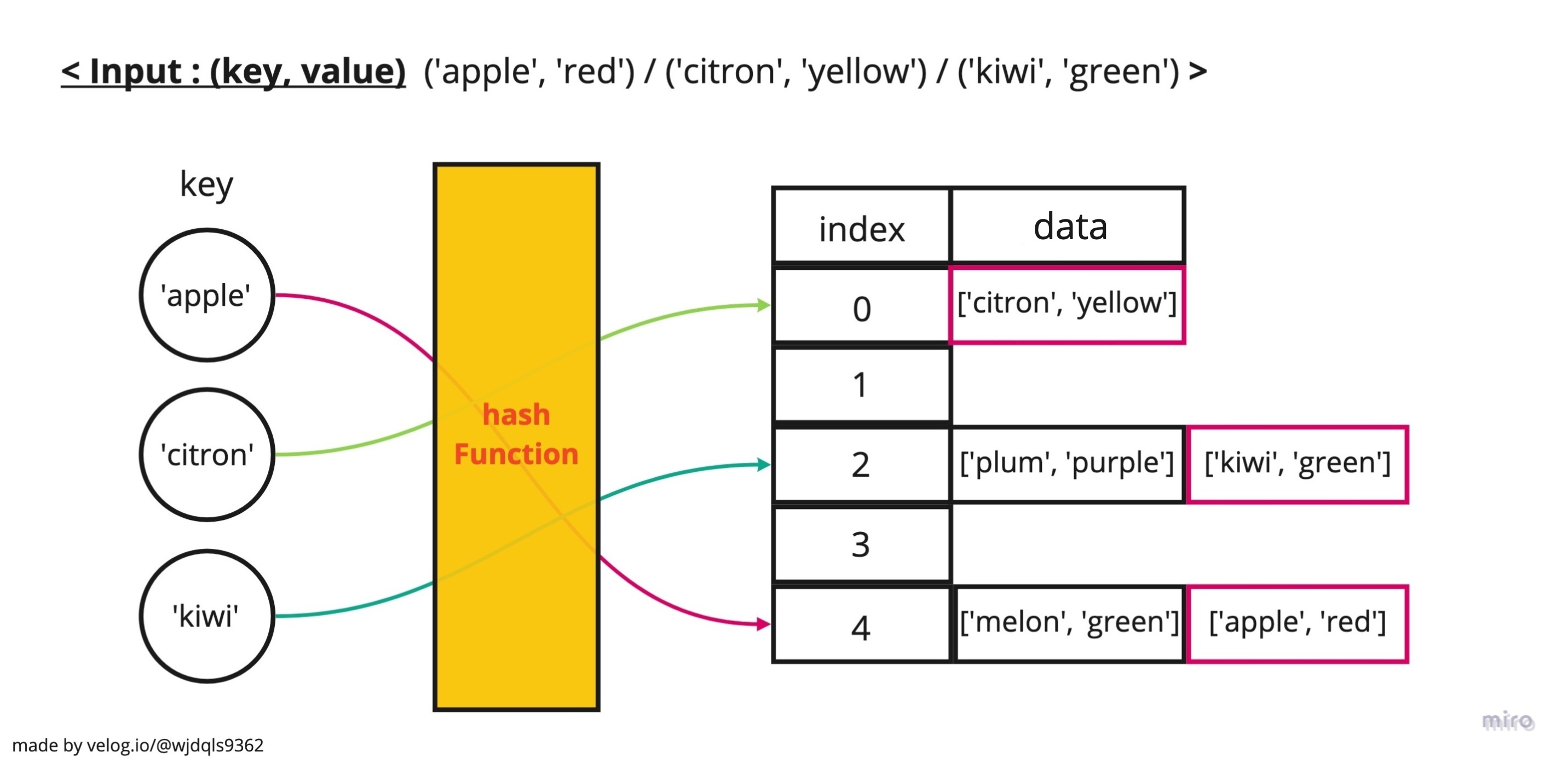
hashTable은 data가 키값(key, value) 쌍으로 이루어진, 크기가 동적인 자료구조이다.
입력받은 데이터의 key를 해시 함수를 통해 특정 index으로 바꾼 뒤, 해당 index에 키값을 저장한다. 저장공간의 효율을 위해 공간이 75%이상, 25%이하로 사용될 때, 공간의 크기를 조절한다. (double sizing, half sizing)
해시 함수로 한번에 index 조회가 가능하기 때문에, key의 value가 빈번하게 변화될 때 유용하다.
또한, key가 특정 index로 암호화되기 때문에, data의 보안이 중요할 때 암호화를 위해 사용하기도 한다.
대표적으로 멤버십 DB 구성, 게임 user의 score DB 구성 등 사용된다.
Property
- 저장된 data의 개수를 나타내는 size
- 현재 사용하는 storage의 크기를 특정하는 limit
- storage
Method
- 새로운 key, value를 삽입하는 insert(key, value)
- 입력받은 key의 value를 가져오는 retrieve(key)
- 입력받은 key의 data를 삭제하는 remove(key)
- storage의 크기를 조절하는 resize(newLimit)
Psuedo Code
// hashFunction과 LimitedArray는 이미 구현되어 있는 것으로 한다.
insert(key, value) {
// hashFunction(key) -> 특정 index 받음
// 1. 해당 index가 비어있는 경우
// --> 그대로 키값 쌍을 삽입
// 2. 해당 index에 이미 다른 data 1개가 존재 할 경우
// --> bucket을 만들어 기존의 data를 담고, 입력받은 키값 쌍을 삽입
// --> 만들어진 bucket을 해당 index에 삽입
// 3. 해당 index에 bucket이 존재할 경우
// --> bucket에 접근해 입력받은 키값 쌍을 삽입
// +) 삽입 후 storage 사용정도가 75% 이상 넘어가면 resize메소드를 이용해 double sizing
}
retrieve(key) {
// 1. 해당 key를 가진 data가 존재하지 않을 경우
// --> undefined를 return
// 2. 해당 key의 index에 유일한 data로 존재할 경우
// --> 바로 value 접근 가능
// 3. 해당 key의 index가 bucket일 경우
// --> bucket을 순회하며 일치하는 key 검색, 존재한다면 value를 return
}
remove(key) {
// 1. 해당 key의 index에 유일한 data로 존재할 경우
// --> 해당 index의 값을 undefined 처리
// 2. 해당 key의 index가 bucket일 경우
// --> bucket을 순회하며 일치하는 key 검색, 존재시 해당 bucket의 index를 undefined로 처리
// +) 제거 후 storage 사용정도가 25% 이하로 떨어지면 resize메소드를 이용해 half sizing
}
resize(newLimit) {
// 1. 현재 storage를 변수에 백업
// 2. size, limit, LimitedArray(double or half)로 초기화
// 3. 백업해둔 storage를 순회하며 data들을 rehashing하여 다시 삽입
}