
4일차 갓생을 살기위해 오늘으으으으은~~~
머신러닝에서 자주 나오는 개념들을 정리해봤다.
그동안 그냥 외워서 쓰려고했던 것 들을 왜 쓰는지,언제쓰는지를 중심으로 정리해보는 게 목표!
그리하여어어어
머신러닝 회귀분석알아보기:심화 정리(표준화,로그변환,MAE,RMSE) !!
연속형 변수와 이산형 변수
-
연속형 변수(Continuous Variabels) : 값이 연속적으로 변할수 있는 변수다. 두 값 사이에 항상 다른값이 존재하고, 보통 '실수'로 표현된다. 예를 들면 키, 몸무게, 온도 같은 값들이 있다.
회귀문제에서는 보통 이런 연속형 변수가 예측 대상(종속변수)이 된다. -
이산형 변수(Discrete Variables) : 셀 수 있는 값으로 이루어진 변수다. 두 값 사이에 다른 값이 존재하지 않고, 주로 '정수'로 표현된다. 예를 들면 자녀수, 학생수, 제품 불량 개수 같은 값이 여기에 해당된다. 학생수가 30.5명처럼 나오는건 말이안됨.
*변수 타입을 정확히 이해는게 모델 설계와 해석에서 생각보다 중요함!
데이터 표준화 (StandardScaler)
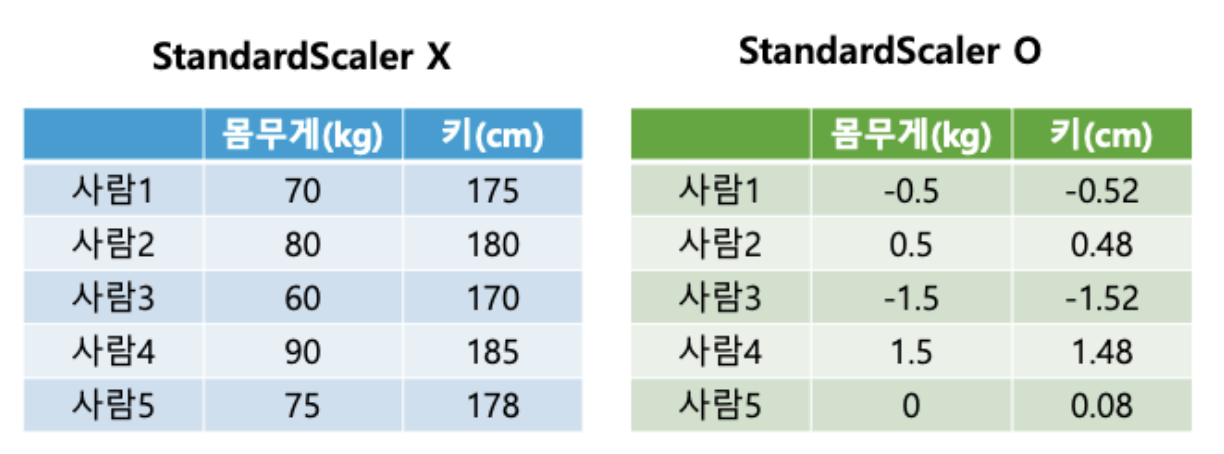
- 표준화는 각 특성의 평균을 0, 표준편차를 1로 맞추는 과정이다.(분산이아니라 표준편차 기준이라는점!)
- 숫자 크기가 큰 특성이 있으면 모델이 그 특성만 중요하다고 착각할 수 있는데, 표준화를 하면 이런 문제를 줄 일수 있다.
From sklearn.preprocessing import StandardScaler
scaler = StandardScaler() 
- 계산법 : (값 - 평균) / 표준편차
장점
- 특성들이 비슷한 스케일에서 학습됨
- 정규분포에 가까워져서 모델이 안정적으로 학습됨
- 최적화가 빨라지는 경우가 많다
단점
- 이상치가 있으면 평균과 표준편차가 크게 흔들릴 수 있다
- 원래 데이터 분포 해석이 어려워질 수 있음
자주 헷갈렸던 부분 정리
- 분산 != 표준편차
->분산은 표준편차의 제곱 - std()는 데이터가 얼마나 퍼져 있는지 볼 때
- sum()은 전체 크기나 누적량을 볼 때 사용
표준화 후 DataFrame으로 바꾸는 이유
: 컬럼 이름을 유지하면서 분석하고 시각화하기가 훨씨 편해지기 때문이다.
로그 변환 (Log Transform)

로그 변환은 데이터가 한쪽으로 심하게 치우쳐 있을 때 자주 사용한다.
값의 범위를 줄여서 극단적인 값의 영향을 완화하는게 목적이다.
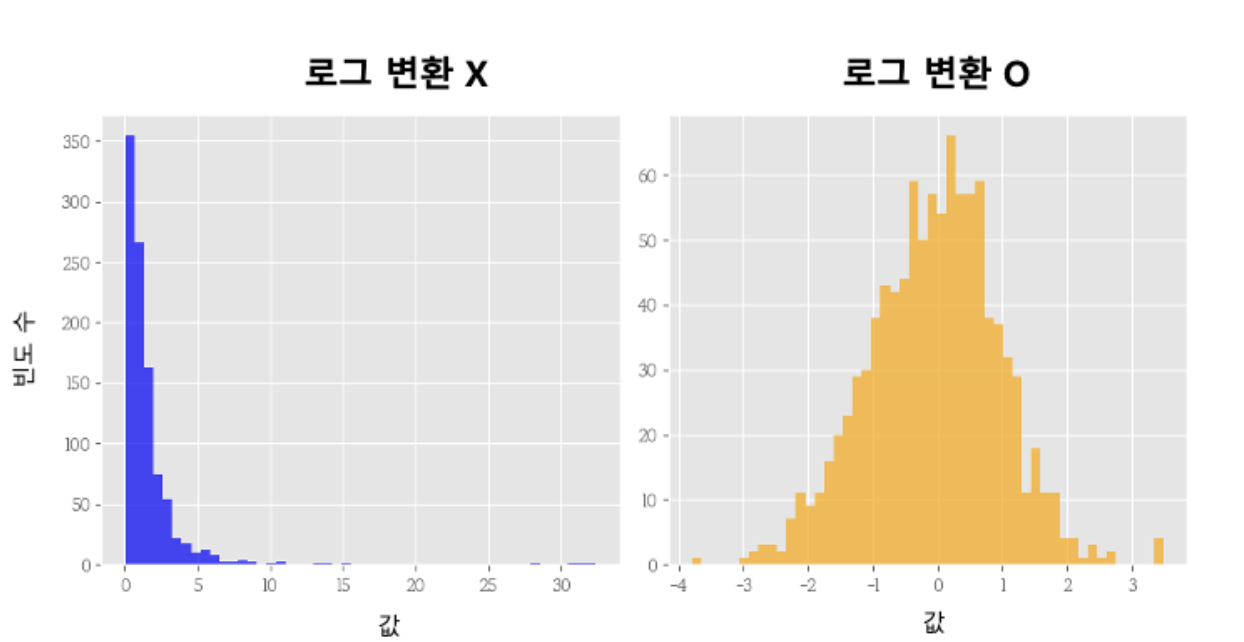
소득,매출,생물학적 측정값처럼
오른쪽 꼬리가 긴 분포에서 특히 효과가 좋다.
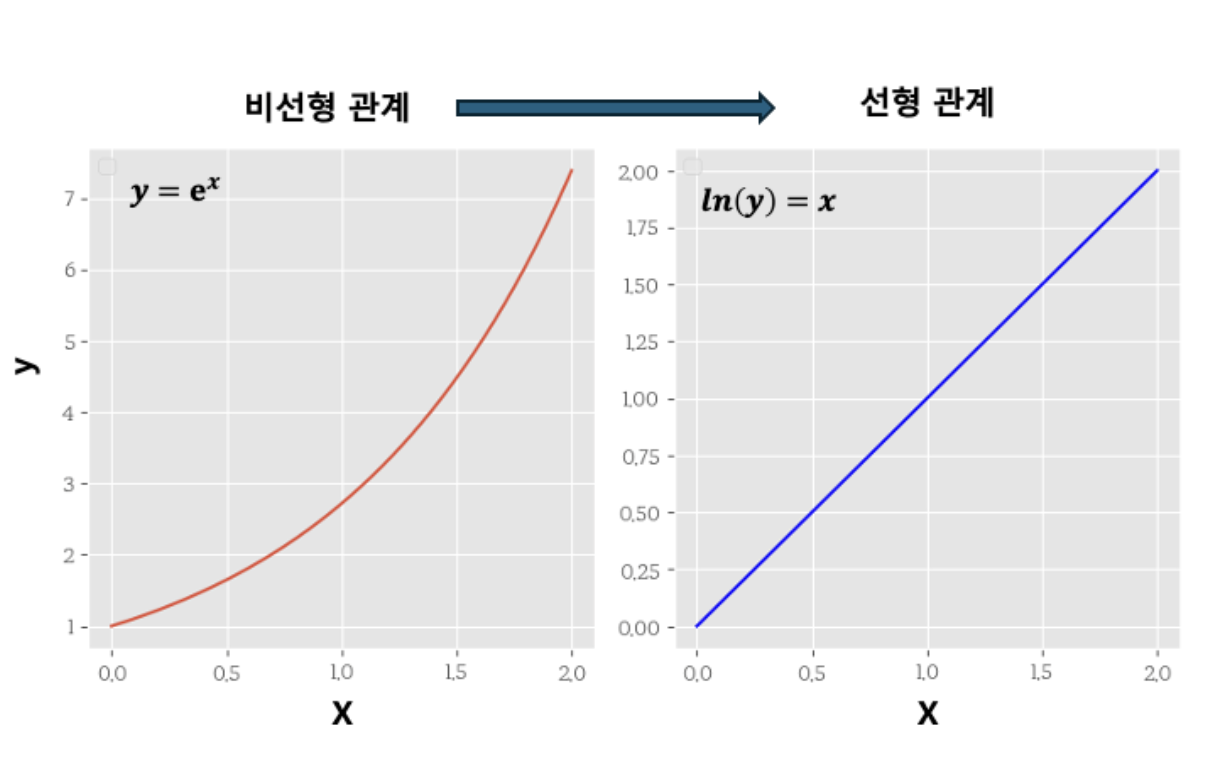
또 , 비선형 관계를 로그 변환을 통해 선형에 가깝게 만들 수 있다는 장점도 있다.
주의할 점
- 0이나 음수가 있으면 바로 적용할 수 없다
- 필요하면 log(x + 1)같은 방식 사용
*로그 함수는 numpy만 가능한 게 아니라 pandas나 math에서도 사용 가능하다.
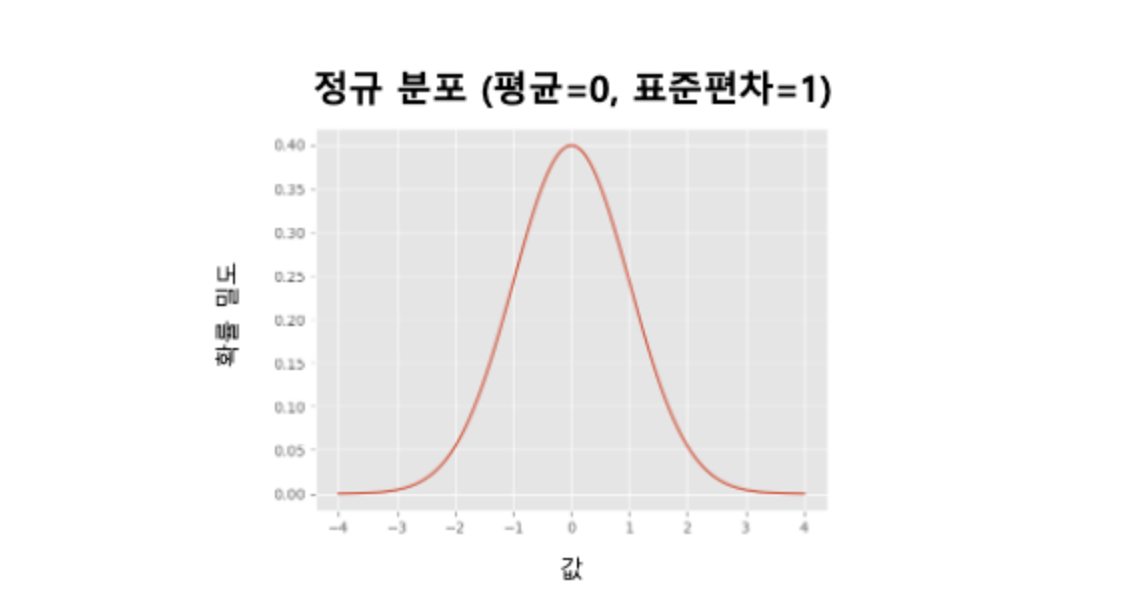
정규분포(가우스 분포)
정규분포는 종 모양의 대칭적인 분포다.
평균, 중앙값, 최빈값이 같은 위치에 있고 표준편차가 클수록 분포는 넓게 퍼진다.
- .select_dtypes()로 수치형 데이터만 고르고,
- .skew()로 왜도를 확인할 수는 있지만,
- 이것만으로 정규분포 여부를 완전히 판단할 수는 없다.
- 히스토그램이나 Q-Q plot까지 같이 보기!
머신러닝 기본 용어 정리
- Target variable : 예측하려는 값 (종속변수)
- Independent variables: 입력 변수 (독립변수)
- Features: 실제 모델에 사용되는 독립변수들
- Irrelevant variables: 예측에 도움 안 되는 변수
종속변수 = 결과값
독립변수 = 변화가능
-> 독립변수는 종속변수를 변화시킨다
*독립변수가 종속변수에 영향을 준다는 개념만 확실히 잡아두면 헷갈릴 일이 줄어든다!
학습과 예측
- 학습(fit) : 데이터에서 패턴을 찾는 과정
- 예측(predict) : 학습한 패턴을 새로운 데이터에 적용하는 과정
*데이터를 학습/검증/데이터로 나누는 이유 : 과적합을 막고 모델의 일반화 성능을 확인하기 위해서
회귀 성능 지표
MAE (Mean Squared Error)
from sklearn.metrics import mean_absolute_error
#실제 값과 예측값
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
#MAE계산
mae = mean_absolute_error(y_true, y_pred)
print("MAE:", mae)- 오차의 절댓값 평균
- 이상치에 덜 민감
- 해석이 직관적
👉 일반적인 회귀 문제에서 많이 사용
RMSE (Root Mean Squared Error)

- 오차를 제곱해서 평균 낸 뒤 제곱근
- 큰 오차에 더 민감
- 손실함수로 자주 사용
👉 큰 오차를 특히 줄이고 싶을 때 적합
from sklearn.metrics import mean_squared_error
import numpy as np
#실제 값과 예측 값
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
#RMSE계산
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
print("RMSE:", rmse)*손실함수란 실제 정답값과 예측한 값을 넣었을 때 함수
🖍️공부 정리🖍️
오늘은 모델보다도 데이터 전처리가 왜 중요한지 체감한 날이었다.
예전에는 표준화나 로그변환을 그냥 "해야하니까" 썼다면,
이제는 언제 쓰는 게 맞는지 조금씩은 판단할 수 있을 것같다.
아직은 익숙하지않아 차차 해야하지만 금방금방 아주 조금씩이라도 발을 내딛는 느낌이든다 𐔌՞・·・՞𐦯
