
5일차 갓생일기! 오늘도 갓생을 살기위해 책상에 앉았다.
요즘 머신러닝 모델들을 하나씩 뜯어보면서 느끼는건,
"아 그냥 쓰는 거"랑 "왜 이런 구조인지 이해하고 쓰는거"는
생각보다 차이가 크다는 점이다.
그래서 오늘은
그래디언트 부스팅 계열 모델 중에서도 자주 보이던 LightGBM을 정리해봤다.
LightGBM이란?
LightGBM(Light Gradient Boosting Machine)은
Microsoft에서 개발한 고성능 그래디언트 부스팅 프레임 워크다
정형 데이터(tabular data)를 다룰 때
빠른 학습 속도와 좋은 성능 덕분에
실무와 캐글에서 정말 자주 등장한다.
🥸여기서 질문
그래디언트 부스팅,프레임 워크이 뭔데? 어떤 상황일때 쓰는거지?
- 그래디언트 부스팅(Gradient Boosting) : 여러개의 약한 모델(보통 결정트리)을
순차적으로 학습시키는 앙상블 학습.이전 모델이 틀린 부분(오차)을
다음 모델이 보완하면서 학습한다.
-처음 모델 ->대충 예측
-그 오차를 기준으로 다음 모델 학습
-이 과정을 여러 번 반복
-점점 예측이 정교해짐
여기서 Gradient(경사)라는 말이 붙은 이유는
->오차를 줄이는 방향을 손실 함수의 기울기(gradient)로 계산하기 때문
그래서
-단일 모델보다 성능이 좋음
-대신 과적합 위험도 있어서 제어가 중요함
- 프레임워크(Framework) : 단순한 라이브러리보다 한단계 큰 개념임
미리 정해진 구조와 규칙 안에서
우리의 필요한 부분만 채워서 쓰게 해주는 틀
LightGBM을 프레임워크라고 부르는 이유
- 모델 구조
- 학습 방식
- 병렬 처리
- 콜백, 평가 방식
까지 전체 학습 흐름이 이미 설계돼 있기 때문
즉,
"이 규칙 안에서 모델을 학습시켜라"
라고 방향을 잡아주는 역할
LightGBM의 등장 배경
GBDT(Gradient Boosting Decision Tree)는
오래전부터 널리 쓰이던 강력한 알고리즘이다.
그 구현 중 하나가 바로 XGBoost.
다만, GBDT 계약 모델들은
특성 차원이 높아질수록 모든 분할 지점의 정보 이득을 계산해야 해서
학습 기간이 오래 걸리고 메모리 사용량이 커지는 문제가 있었다.
이런 한계를 개선하기 위해
대규모 데이터셋에서도빠르게 학습할 수 있도록
LightGBM이 등장했다.
LightGBM 특징과 인기 요인
데이터가 1만개 이하로 적을 경우 과적합 위험이 있다.
그럼에도 불구하고 다음 장점들 때문에 많이 사용된다.
1.빠른 학습 속도
- 병렬 처리 + 데이터 최적화
- 기존 그래디언트 부스팅보다 훨씬 빠른 학습 가능.
2.메모리 효율성
- 연속형 변수를 미리 구간(bin)으로 나눠 계산
- 메모리 사용량 감소
- 리소스가 제한된 환경에서도 효율적으로 동작
3.결측치 자동 처리
- 별도의 결측치 처리 없이도 학습 가능
4.범주형 변수 자동 처리
- 범주형 변수를 category 타입으로만 바꿔주면 됨
- 원-핫 인코딩 필수 X
5.스케일링 불필요
- 트리 기반 모델 -> 입력 변수 스케일에 민감하지 않음
6.높은 정확도
- XGBoost와 동등하거나
- 경우에 따라 더 높은 성능을 보이기도 함
🥸여기서 질문 !
"그럼 전처리 이후에 스케일링은 안해도 되는 건가 ? Pipeline에 LightGBM은 안 들어가는 건가?"
👉 결론부터 말하면
- 스케일링은 굳이 안 해도 된다
- 하지만 Pipeline에는 충분히 들어간다
LightGBM은 스케일에 민감하지 않지만,
Pipeline은
- 전처리 흐름 관리
- 데이터 누수 방지 를 위해 여전히 유용하다.
LightGBM이 빠른 이유
LightGBM의 고속 처리와 효율성을 가능하게 하는 핵심은
병렬 처리 + 데이터 최적화
특히 히스토그램 기반 분할 방식을 사용해
모든 값을 일일이 스캔하지 않고도 빠르게 분할기준을 찾는다
XGBoost vs LightGBM
둘 다 그래디언트 부스팅 기반 라이브러리지만
트리를 키우는 방식에서 차이가 있다.
차이점
1.트리 성장 방식
XGBoost : Level-wise
- 모든 노드를 같은 깊이로 확장
- 균형 잡힌 트리 구조
- 과적합에 상대적으로 강함
- 단점 : 메모리 사용량 큼
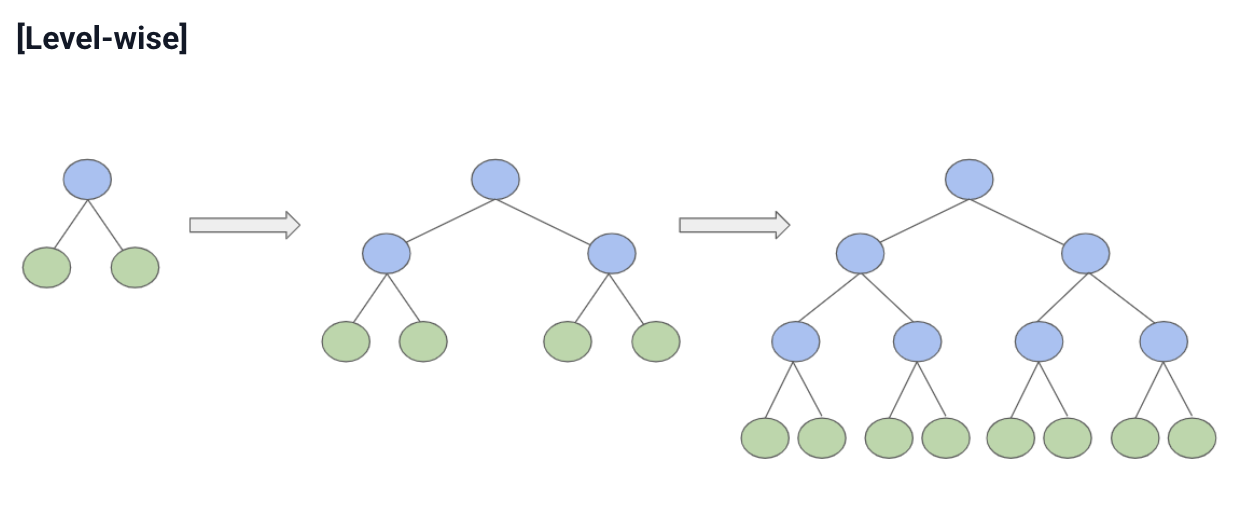
Level-wise 방식은
트리 높이를 최소화하면서 성장하기 때문에
과적합을 막는 데 유리하다.
🥸여기서 질문 !
"깊이나 가지 수는 하이퍼파라미터로 제한하는 건가? 안하면 끝없이 자라서 과적합이 생기나?"
-맞음. 트리 모델은 자동으로 적당히 멈추지 않음
그래서
- max_depth
- num_leves
- n_estimators
같은 하이퍼파라미터로 성장을 직접 제한해줘야함.
LightGBM : Leaf-wise
- 손실 감소가 가장 큰 leaf를 우선 확장
- 더 빠른 학습
- 더 깊고 비대칭적인 트리 생성 가능
- 괴적합 위험은 있지만 잘 조절하면 성능이 좋음
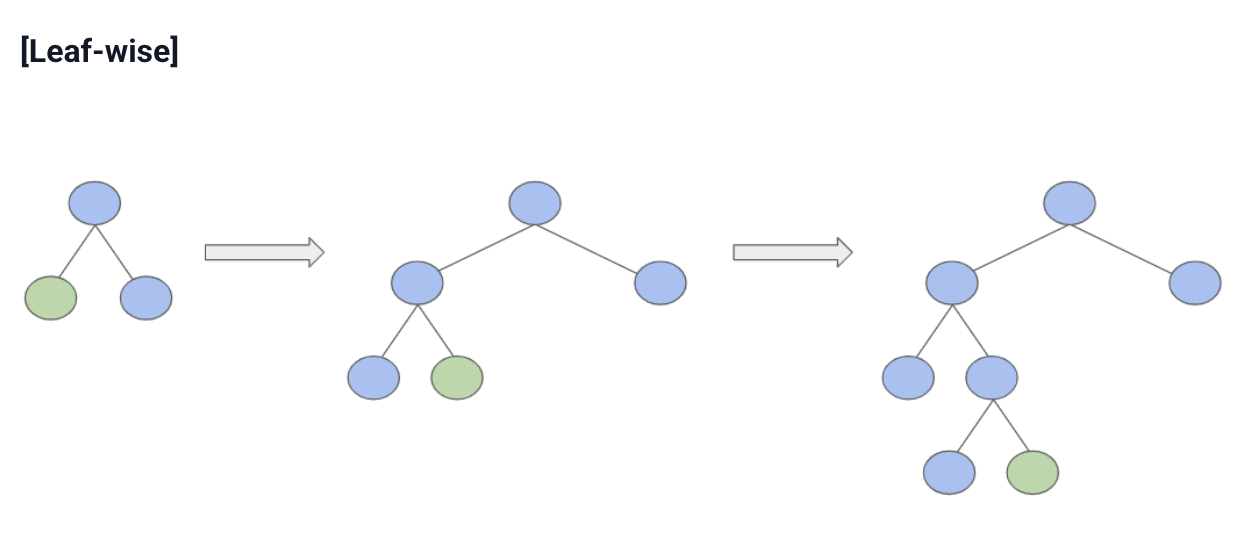
🥸여기서 질문 !
"그리드 탐색 같은건가? 눈앞의 이득으로 노드를 확장하는 건가?"
- 눈앞의 이득(손실 감소) 기준으로 확장한다. 하지만 Grid Search랑은 다르다.
- Grid Search ->하이퍼 파라미터 탐색
- Leaf-wise ->트리 내부 분할 전략
2.속도 & 대규모 데이터
- XGBoost : 모든 특성을 반복 스캔 -> 큰 데이터에서 부담
- LightGBM : 히스토그램 기반 -> 계산량과 메모리 사용 감소
3.범주형 변수 처리
- XGBoost : 인코딩 필수
- LightGBM : category 타입만 지정하면 바로 사용가능
LightGBM은 어떤 모델인가?
- 지도학습 라이브러리
- 분류 / 회귀 모두 가능
- 정형 데이터 분석에 특화
LightGBM 학습을 위한 데이터 준비
1. 독립변수 / 종속변수 설정
- target 분리
- 범주형 변수 ->category타입 변환
(문자열 그대로는 사용 불가)
2.학습 / 검증 데이터 분리
- 학습 데이터로 모델 학습
- 검증 데이터로 성능 확인
주요 하이퍼파라미터 정리
-
n_estimators
- 트리 개수
- 많을수록 복잡, 과적합 위험 증가
-
max_depth
- 트리 최대 깊이
-
num_leaves
- 리프 노드 수
- LightGBM에서 가장 중요한 파라미터 중 하나
early_stopping, log_evaluation은 뭐지?
from lightgbm.callback import early_stopping, log_ecaluation이 둘은 모델의 정의가 아니라 모델을 학습시킬때(fit할 때)사용하는 콜백(callback)이다.
-
early_stopping
- 검증 성능이 더 이상 좋아지지 않으면 학습 중단
-
log_evaluation
- 몇 iteration마다 학습 로그를 출력할지 설정
*과적합 방지 + 학습 과정 모니터링용
🥸여기서 질문 !
그럼 콜백(callback)이란?
콜백(callback) : 학습 도중 특정 시점에 자동으로 호출되는 함수
모델이 학습을 계속 진행하는 동안
- 몇 번째 반복인지
- 성능이 좋아지고 있는지
와 같은 상황을 중간중간 확인하고 개입할 수 있게 해준다.
쉽게 말해
"지금 이 시점에 이거 한 번 확인해줘"
"조건 만족하면 멈춰줘"
같은 역할을 하는 장치
피처 중요도(Feature Importance)
- 각 피처가 예측에 얼마나 기여했는지 수치로 표현
- 하지만 중요도가 높다고 항상 좋은 피처는 아님
- 경우에 따라 과적합의 원인이 될수도 있음
*항상 검증 성능과 함께 해석해야함 !
🖍️공부 정리🖍️
오늘은 LightGBM이 "빠르다"에서 끝나는 모델이 아니라 왜 빠른지,어떤 구조인지를 조금은 이해한 날이다.
예전에는 XGBoost랑 비슷한 모델 정도로만 봤다 . 전에도 적었다시피 결과값도 똑같이나오기도해서 단순 생각으로 !
이제는 언제 LightGBM을 쓰면 좋은지도 조금씩조금씩 이제는 감이 잡히는 느낌이다.
아직은 낯설지만, 이런 정리가 쌓이면
나중에는 스스로가 모델을 선택할 때 분명 도움이 될거라고 믿는중이다!! 아니 분명 도움이될꺼야!!
탑쌓듯이 아주 조그마한 돌도 옆에 올려가면서 쌓는중이다 𐔌՞・·・՞𐦯
