
6일차 갓생일기 !
오늘은 앙상블 기법 중 스태킹(stackin)과 하이퍼파라미터 최적화(Hyperparameter Optimization, HPO)(stackin)에 대해 학습하고
Optuna 실습을 통해 실제로 값이 왜 달라지는지도 확인해보았다.
앙상블(Ensemble) - Stacking이란
스태킹(Stacking) :
여러 개의 개별 모델(Base Model)의 예측값을 모아서,
다시 하나의 최종 모델(Meta Model)이 학습해
최종 예측(Meta Model)을 수행하는 앙상블 기법.
개별 모델들이 낸 결과를
하나의 관리자 역할을 하는 모델이 종합해서 판단한다고 이해하면 편함.
* Base Model : LightGBM, RandomForest, XGBoost등 여러 개별 모델
* Meta Model : Bae Model들의 예측값을 입력으로 받아 최종 판단
* Meta = 관리자 역할
스태킹은,
- 단순 평균(averaging)이나 다수결(voting)이 아님
- 모델들의 예측 조합 방식을 '학습'함
- 예측값 사이의 복잡한 관계를 메타 모델이 학습
스태킹 특징 요약
- 이종 모델 결합(서로 다른 모델 사용)
- 동일 가중치 X ->서로 다른 가중치 O
- 메타 모델이 최적의 가중치 조합을 학습
스태킹을 쓰는 타이밍
- 단일 모델 성능이 더 이상 안 오를 때
- RF, LightGBM 튜닝 다해봄
- 서로 다른 성향의 모델이 2~3개 이상 있을 때
- 선형/트리/부스팅
- 성능이 중요할 때
- 대회,연구,의료/리스크 도메인
- 데이터가 너무 작지 않을 때
- (CV로 나눌 여유는 있어야함.)
Stacking 전체흐름
- 데이터 준비
- 전처리 (스케일링,인코딩 등)
- 파이프라인 구성
- Base Models 학습(CV기반)
- Base Models의 예측값 생성
- 예측값을 새로운 feature로 사용
- Meta Model학습
- 최종 예측
🥸여기서 질문 !
"그럼 배깅하고 스태킹은 차이점이뭐야?여러 모델이 학습해서 예측을 하나 내는건 비슷해보이는데? 그리고 언제 사용해야하는데?"
배깅 = 같은 모델 여러개 -> 투표/평균
스태킹 = 다른 모델 여러개-> "또 다른 모델"이 최종 판단. '모델마다 잘하는상황이 다를 때' 그차이를 학습해서 성능을 더 끌어올리려고 사용.
느낌적으론,
"내과,외과,영상의학과 의견을 모아서 교수님(메타 모델)이 최종진단"
하이퍼파라미터(Hyperoarameter)란
하이퍼파라미터 : 모델 학습 전에 사용자가 직접 설정하는 값으로, 모델 구조/학습방식을 결정하는 핵심요소
예시_
- learning_rate
- max_depth(Tree depth)
- regularizaion strength
- n_estimators
모델 파라미터(weight, bias)와는 다름!
->파라미터는 학습 과정에서 자동으로 학습됨.
모델 구축과정 : 모델의 구조및 학습 방식을 결정하는 핵심요소(예 : 학습률learning rate, 규제강조regularizaion strength, 트리 깊이Tree depth)
모델 구축 완료 : 모델파라미터(model parameter)와 명확히 구분.예를 들어 가중치(weight)
하이퍼파라미터 튜닝이 중요한 이유
- 같은 모델이라도 파라미터 설정에 따라 성능 차이가 큼
- 튜닝이 안되면 :
- 과적합
- 과소적합
- 성능 저하
- 즉,모델 성능의 절반은 튜닝에서 결정됨
->그래서 HPO(Hyperparameter Optimization)가 중요함
*HPO = Hyperparameter Optimization
-> 최적의 하이퍼파라미터를 자동으로 찾는과정
Optuna(HPO 도구)
Optuna는 지능적으로 하이퍼파라미터를 탐색하는 라이브러리임.
📌Optuna의 3가지 핵심 개념알기
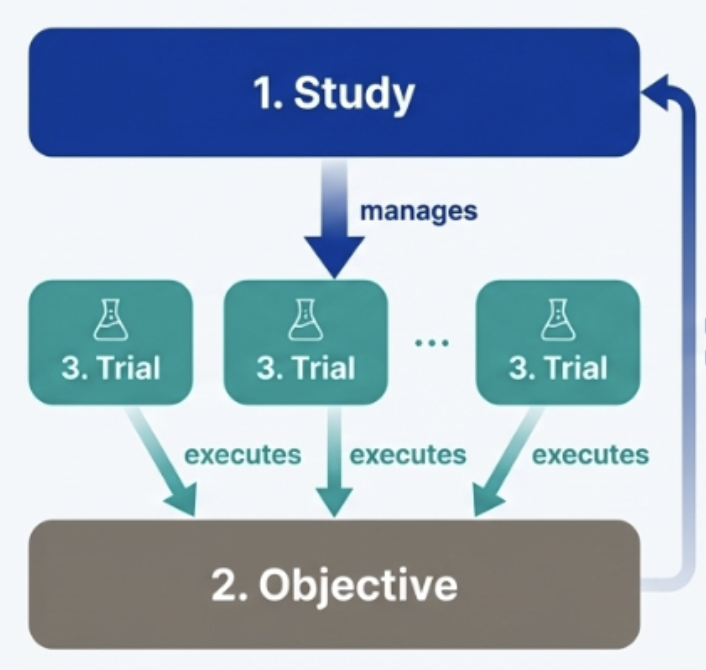
- Study : 전체 실험 관리 단위
- Trial : 하나의 실험 시도
- Objective : 최적화 목표 함수
흐름 :
Study -> Trial -> Objective 순
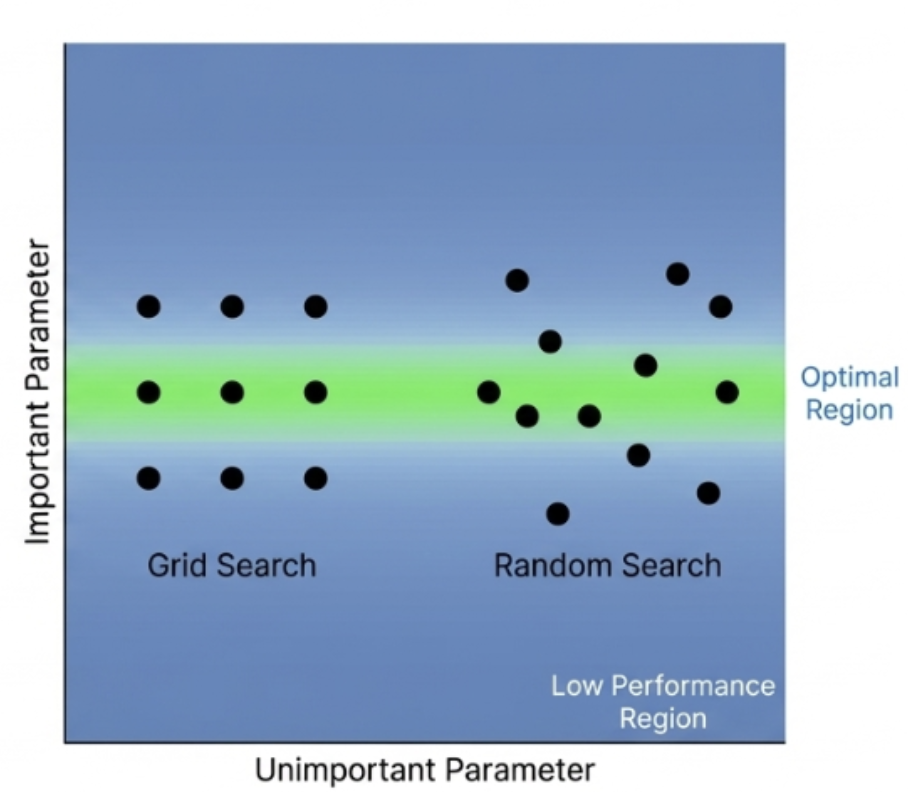
GridSearch vs RandomSearch(간단비교)
-
GridSearch
- 모든 조합을 전부 탐색
- 장점 : 결과가 안정적, 재현성 높음
- 단점 : 시간 오래 걸림, 비효율적
-
RandomSearch
- 랜덤으로 일부 조합만 탐색
- 장점 : 빠름, 넓은 탐색 가능
- 단점 : 운에 따라 성능 편차 발생

📌실습 결과에서도
GridSearch는 빠르고 안정적
RandomSearch는 때로 더 높은 성능을 기록
종종 Random Search가 나을때가 있음.
Random Search의 강점
- 탐색의 다양성 : 고정된 격자에 얽매이지 않고 매번 다른 값들을 테스트
- 중요 파라미터 발견 확률 : 동일한 예산으로 중요 파라미터의 '최적구간'을 발견할 확률이 수학적으로 높음.
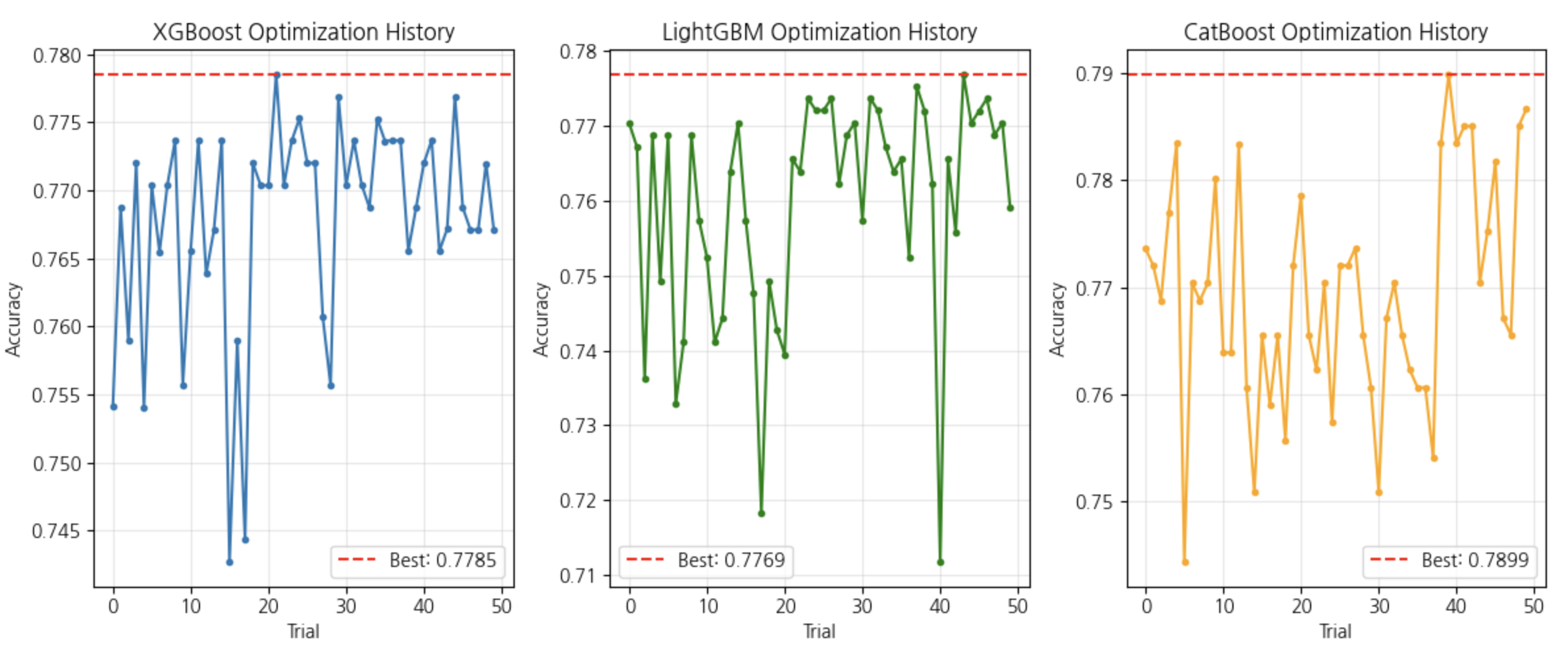
📌실습 결과
22.머신러닝 심화 .ipynb실습에서 강사님 포함 모든 사람이 서로 다른 결과값이 나옴.
이유 :
- Optuna의 파라미터 샘플링은 확률적
- Cross Validation 분할에 랜덤성 존재
-> 그래서 실행할 때마다 값이 달라질 수 있음 그럼에도 불구하고CatBoost가 전반적으로 약간 더 높은 CV Score를 기록
(나의 경우도 CatBoost가 가장 높게 나옴)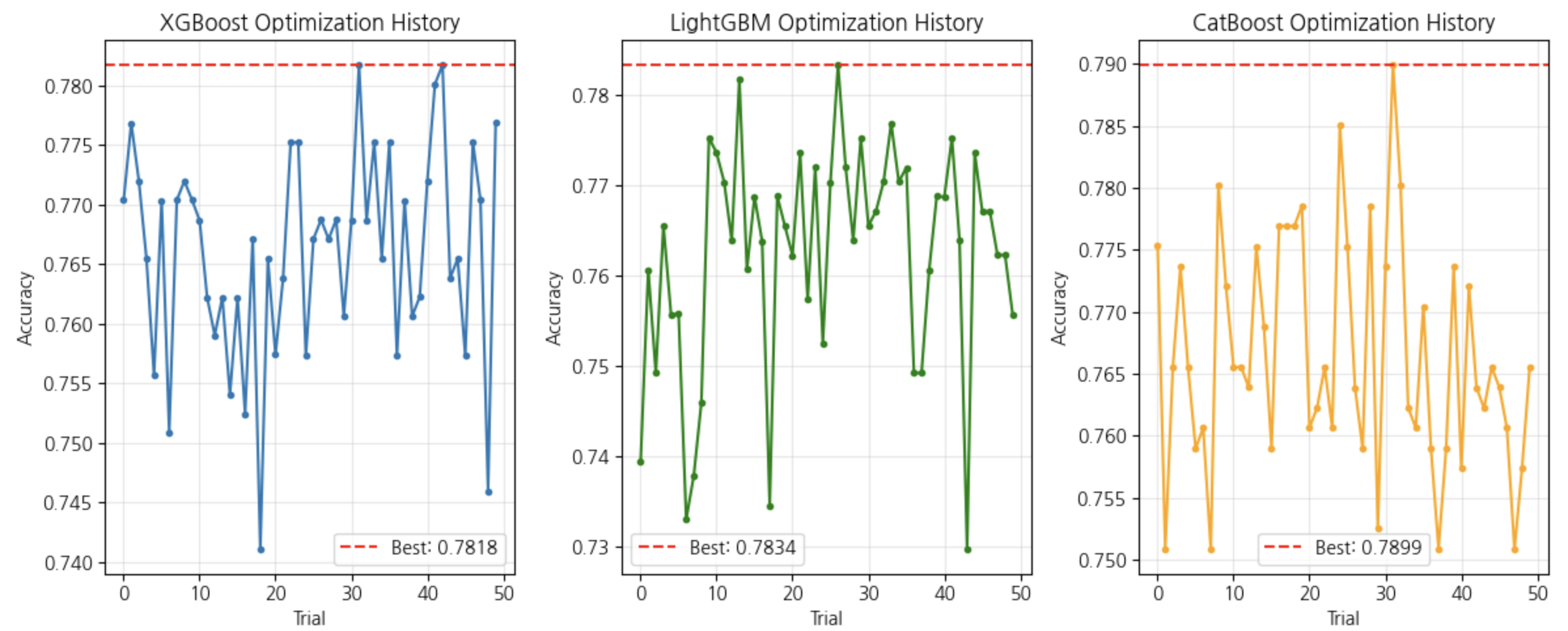
Epoch 뜻🌟🌟
Epoch = 전체 학습 데이터를 한 번 모두 학습한 횟수
- 1epoch
->전체 데이터 1회 학습 - epoch 수가 많을 수록:
- 학습은 더 많이 하지만
- 과적합 위험 증가
📌딥러닝에서 특히 중요한 개념
🖍️공부 정리🖍️
오늘은 하이퍼파라미터최적화,튜닝이 왜중요한거며 새로운 단어의 개념도 같이 배운날이다.
물론 실습과제로 5번 정도 코딩을 돌려봤을때 어떠한 결과가 나오는지 확인하고 코딩을 뜯어보는 거이긴했지만, 이렇게 까지 다양하게 나오는걸 눈으로 확인하면서 항상의심을하며 체크또 체크를하고 해당 데이터에 대한 모델을 잘사용해야겠다고 또 느꼇다. ʕo•ᴥ•ʔ✎
