[논문 리뷰] Communication-Efficient Learning of Deep Networks from Decentralized Data - 2편
Federated_learning
The FederatedAveraging Algorithm
SGD는 한 번의 communication round에서 하나의 batch(random하게 선택된 client)에 대한 gradient 계산이 이루어지는 federated optimization problem에 적용할 수 있다. 이러한 방식은 계산적으로 효율적인 반면, 좋은 model을 얻기 위해 매우 많은 training rounds가 필요하다. 논문에서는 CIFAR-10 환경에서 이를 baseline으로 설정한다.
Federated setting에서는 더 많은 client를 포함시키는 것에 대한 cost가 거의 없기 때문에, 논문은 baseline으로 large-batch synchronous SGD를 사용한다. (논문의 reference에 의하면, 이러한 방식은 data center setting에 대해 SOTA이고, asynchronous approaches 보다 성능이 훨씬 좋다고 함)
위와 같은 접근을 federated setting에 적용시키기 위해 저자는 각 round 마다 비율의 clients를 선택하고, 이러한 clients들이 가지고 있는 모든 data에 대해 gradient loss를 계산한다. 이때 이다. 따라서 는 global batch size를 조절하고, 이면 full-batch (non-stochastic) gradient descent를 의미한다. 저자는 이 baseline algorithm을 FederatedSGD (혹은 FedSGD ) 라고 말한다.
과 고정된 learning rate , 명의 client를 가지고 있는 상황에서 FedSGD 의 일반적인 구현은 current model 를 이용, 각각의 local data를 이용하여 평균 gradient 를 계산하는 방식으로 이루어진다. 이후, 중앙 server는 각 gradient들을 모아 update를 진행하는데 식은 다음과 같다.
(논문에서 명시된 곳은 찾지 못했지만 은 data sample의 총 개수인 것 같다.)
즉, 모든 에 대해 똑같은 update가 다음과 같이 진행된다.
정리하면, 각 client는 local에서 현재 모델에 대한 one step gradient를 local data를 이용하여 계산하고, server는 결과 model의 weighted average 값을 반영한다.
이때, 우리는 각 client에게 local update를 반복시켜 averaging step에 도달하기 전, 더 많은 계산을 시킬 수 있는데 이러한 접근을 FederatedAveraging (혹은 FedAvg) 라고 한다.
다음의 세 parameter는 총 계산량을 control한다.
만약 이면, full local dataset은 single minibatch처럼 다뤄진다. 따라서 이면 이는 FedSGD 와 동일하다. 또한 local example을 만큼 가진 client의 round 당 local update 수는 와 같다.
FedAvg algorithm의 pseudo code는 다음과 같다. 자세한건 논문을 참조하자.

보다 일반적인 non-convex 문제에서 parameter를 평균내는 모델은 성능이 안 좋은 model을 생성할 수 있다. 아래의 두 그래프를 보자.
Parameter , 로 구성된 두 model의 parameter를 로 averaging 한 model의 loss plot. Loss 계산을 위한 dataset은 MNIST를 (전부) 사용하였고, 각 model은 서로 다른 small dataset에서 학습되었다. 이때, 두 그래프의 Y축 scale이 다르다는 것에 유의하자.
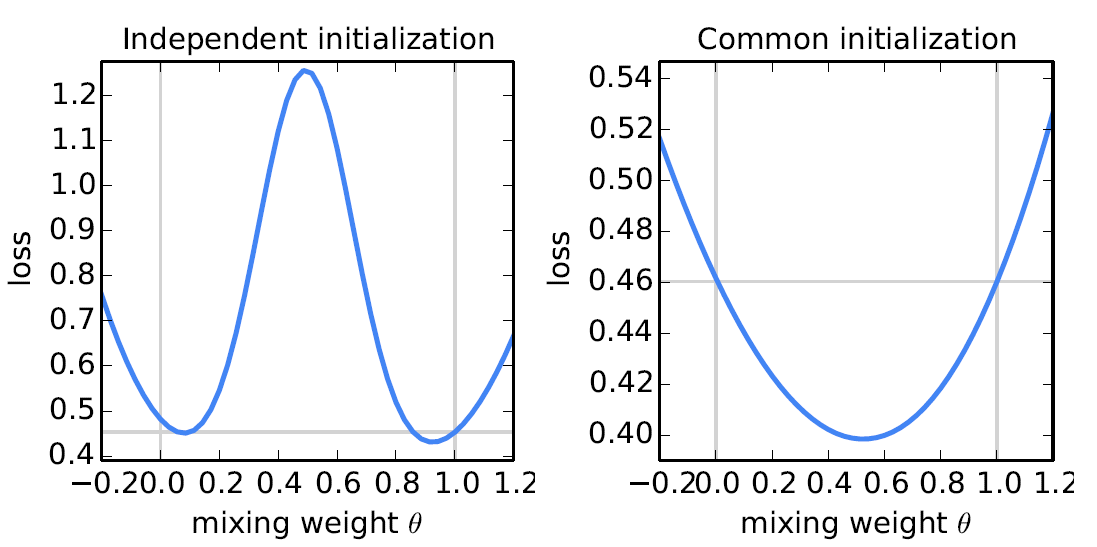
정리하면 다음과 같다. 우리가 두 model을 same random initialization 시킨 다음, data의 다른 subset(non-overlapping)에서 각각 학습시키면, 위 그림의 오른쪽 그래프와 같이 단순히 두 weight를 averaging 하는 것 만으로도 모델이 잘 작동하는 것을 확인할 수 있다. 주목할 점은 두 모델을 반반 섞은 뒤 계산한 loss의 결과가, (절반은 아닌) 작은 dataset에 대한 학습을 독립적으로 진행한 각 모델의 결과보다 더 좋다는 것이다.
참고로 FedAvg 의 각 round에서는 starting model 를 공유하여 사용한다.
Experimental Results
논문에서는 좋은 모델이 mobile device의 사용성을 크게 증대시키도록 만들 수 있는 image classification과 language modeling task에 대해 실험을 진행하였다.
기억할만한 내용을 정리하면 이라는 것은 round 당 한 명의 client가 참여한다는 것을 의미하고, data의 분포가 IID / non-IID 하게 이루어져있는 경우를 나눠 실험했다는 점, 적당한 batch size 를 설정해야 적은 communication round 안에 학습이 잘 진행된다는 점 등이다.
이외의 보다 자세한 내용은 논문을 참고하도록 하자.
Conclusions and Future Work
논문의 실험으로 FedAvg 알고리즘을 다양한 모델 구조에 적용시켜 상대적으로 적은 수의 통신으로 고성능 모델을 얻을 수 있다는 것을 알 수 있었고, federated learning이 practical하게 사용될 수 있음을 확인할 수 있었다.
하지만 federated learning만으로는 privacy benefit을 완벽하게 얻어낼 수 없기 때문에, 추후 differential privacy나 secure multi-party computation등의 기술들을 적용시키는 방향의 연구도 흥미로울 것으로 보인다.
참고로, 두 기술 모두 FedAvg 와 같은 synchronous 알고리즘에 자연스럽게 적용될 수 있다.
Reference
McMahan, Brendan, et al. "Communication-efficient learning of deep networks from decentralized data." Artificial intelligence and statistics. PMLR, 2017.
