[논문 리뷰] Data Augmentation for Deep Learning-Based Radio Modulation Classification - 2편
Preliminaries
이제, 사용한 radio signal dataset과 SOTA LSTM model의 구조에 대해 알아보자.
Radio Signal Dataset
Modulation classification의 평가를 위해 open radio signal dataset인 RadioML2016.10a를 사용한다. Dataset 안에 있는 radio signal은 sample rate offset과 center frequency offset, multi-path fading, additive white Gaussian noise를 고려하는데 이전 포스팅에서 코드를 한번 다뤄본 적이 있으니 필요하면 참고하자.
조금 더 설명해보자면, 11개의 다른 modulation category에 속하는 220,000개의 modulated radio signal segments가 존재한다. (e.g. BPSK, QPSK, PAM4, QAM16 etc.) 각 signal sample은 128개의 연속된 modulated I/Q signal로 구성되어 있고, SNR 값과 그에 해당하는 modulation category를 label로 갖는다. SNR 값은 -20dB 부터 18dB 까지 2dB 단위로 총 20개가 있는데, signal sample은 modulation category와 SNR 값들에 대해 동일하게 분포되어 있다. 즉, 각 modulation category에 대해 SNR 값마다 1,000개의 signal sample이 존재하는 것이다.
(+ 논문의 뒷쪽 파트에 나오는 내용인데 training set과 test set의 비율이 5:5 이다. 즉, 각각 110,000 개의 sample을 가진다.)
이제, raw I/Q signal을 바탕으로 radio modulation category를 자동으로 예측하는 deep learning 알고리즘에 대해 알아보자.
LSTM Network Architecture
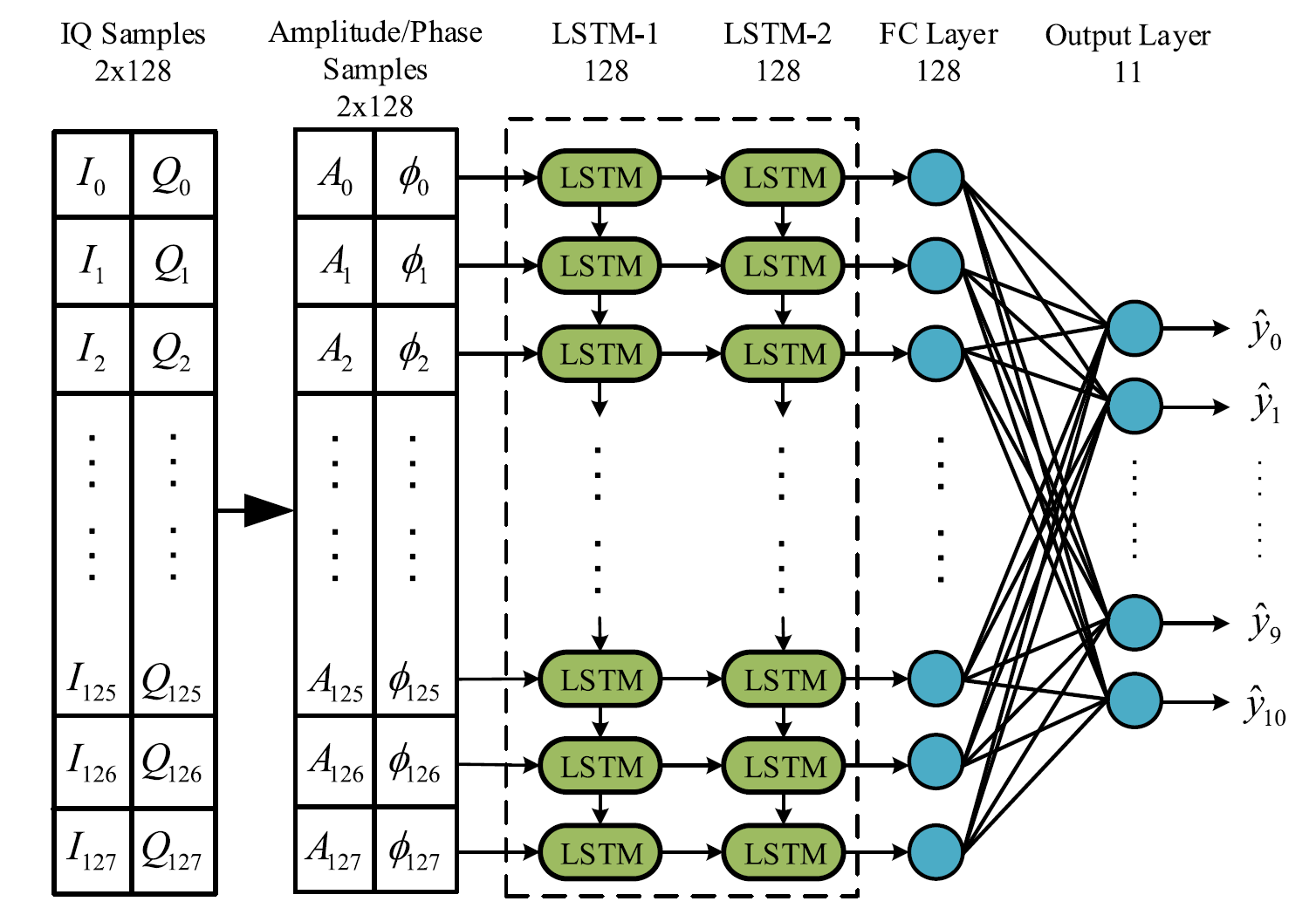
LSTM은 RNN의 한 종류로 time series data를 처리하기 위해 널리 사용된다. Network는 연속된 modulated I/Q 신호로 구성된 data sample을 input으로 받아 category로 mapping 시켜주는데, 아래의 그림을 보자.
LSTM network의 구조.
먼저 modulated I/Q 신호는 다음의 amplitude와 phase로 변환된다. (와 는 각각 modulated 신호의 amplitude와 phase를 의미)
변환된 신호는 characteristic feature를 추출하기 위해 2개의 layer로 구성된 LSTM network의 input으로 들어간다. 이때, 각 layer는 128개의 LSTM cell로 구성되어 있다. 마지막으로, radio signal sample을 11개의 modulation category 중 하나로 mapping 하기 위해 Softmax function으로 이어지는 FC layer를 사용한다.
한편, optimizer로는 dynamic learning rate를 가지는 Adam optimizer가 사용된다. 사용되는 loss는 cross-entropy loss로 (classification task 이기 때문) 식은 다음과 같다.
이때 는 class의 개수를 의미하고, 는 ground truth (GT) label을, 는 input sample이 번째 class로 예측될 확률을 의미한다.
Data Augmentation Methods
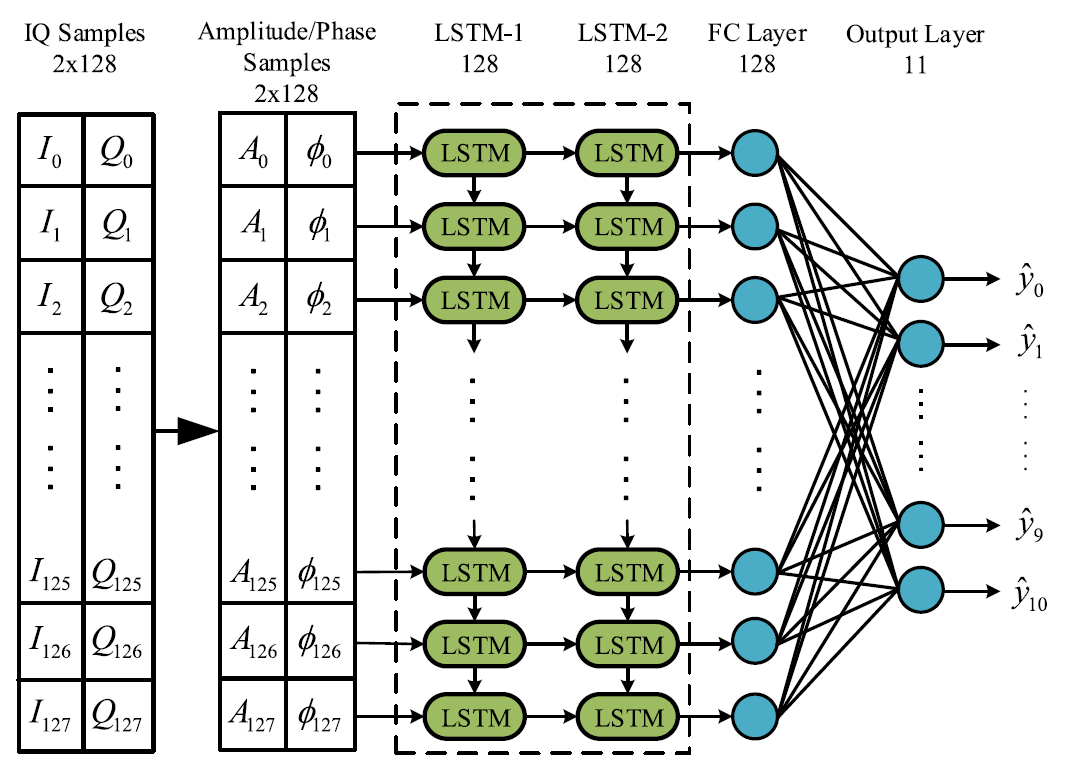
앞에서 언급된 3가지 augmentation 방법을 알아보자. 이때 dataset은 scale factor 만큼 확장된다고 하자.
각 augmentation method를 적용한 QPSK radio signal sample의 constellation diagram.
Rotation
원점을 중심으로 modulated signal 를 회전하면, 를 얻을 수 있다.
이때 는 rotation angle을 의미하는데, 논문에서는 그림과 같이 반시계 방향으로 각각 씩 신호를 회전시켰다.
Flip
Flip의 구현은 간단하게 와 성분의 부호를 바꾸는 식으로 구현했다. 아래의 식을 보자.
Horizontal flip:
Vertical flip:
(Horizontal flip이 수평선을 기준으로 flip 하는건줄 알았는데 그 반대라는 것을 알게 됐습니다...)
각각의 flip과 둘을 동시에 적용하면, scale factor 만큼의 dataset 증대를 얻을 수 있다.
Gaussian Noise
말 그대로 Gaussian noise 을 더하는 방식으로 적용된다.
위에 첨부했던 그림은 noise variance 값을 조절한 것에 대한 결과이다.
주목할 점은 값을 조절하면 충분히 많은 양의 data를 만들 수 있을 것 같지만, 다음 part를 읽어보면 Gaussian noise augmentation method가 radio signal에 적합하지 않다는 것을 알게 될 것이다.
Data Augmentation Time
이제 data augmentation을 하는 시점에 따라 어떤 영향이 있는지를 알아보자.
Train-Time Augmentation
Model을 학습하는 동안에만 augmentation을 수행한 경우이다. 즉, training set은 scale factor 만큼 늘어나고, test set은 동일하게 유지된다. Rotation method를 적용한 예를 들면, 110,000 개의 radio sample로 구성된 training set이 일 때 440,000 개로 늘어나는 것이다. 일반적으로는 training set이 커짐에 따라 더 높은 정확도를 얻을 수 있다.
Test-Time Augmentation
Inference 단계에서 test set에 속한 하나의 sample 는 개의 sample 로 늘어난다. 이후 늘어난 sample 은 LSTM network로 들어가, 우리는 최종적으로 predicted probability vector 를 얻게 된다. 이때 개의 sample들에 대하여, 해당하는 을 더해 maximum 값을 골라 modulation category를 선택하게 되는데 식은 다음과 같다.
Train-Test-Time Augmentation
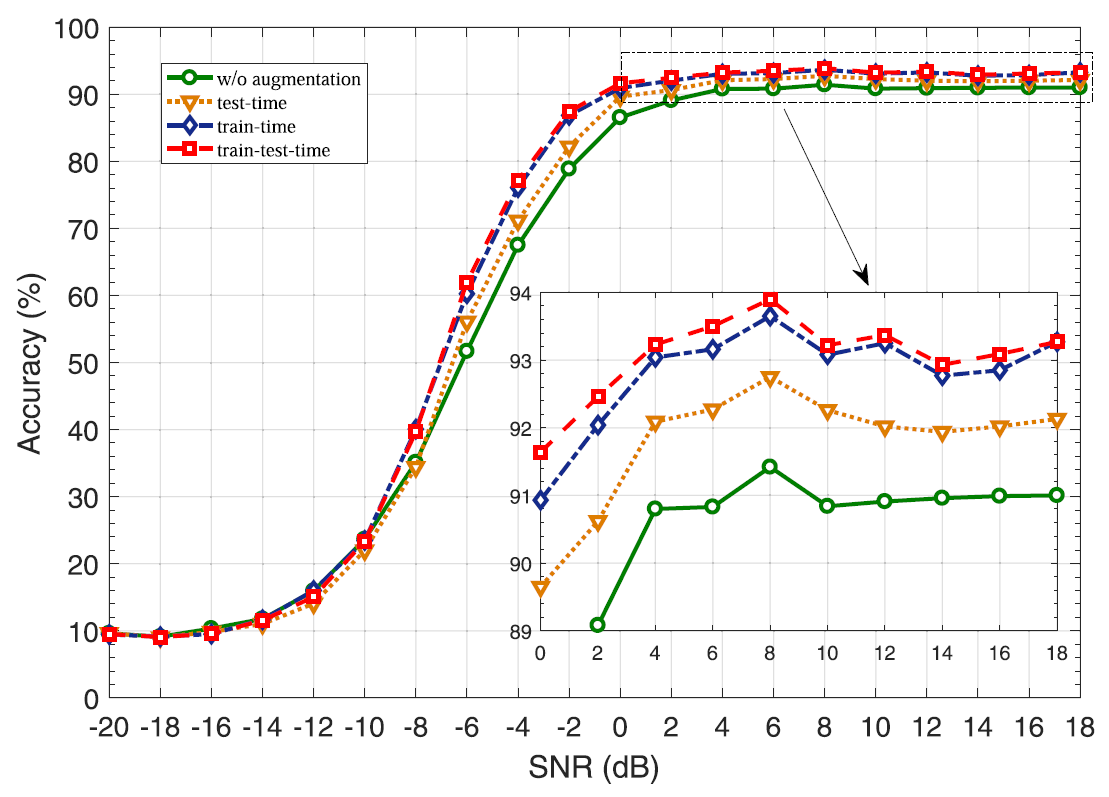
쉽게 말해 앞에서 언급한 두 가지 방식을 모두 적용한 방법이다. 즉, training set과 test set은 모두 만큼 증가하게 된다. 아래는 로 두었을 때 실험을 진행한 결과이다.
서로 다른 augmentation time 을 적용함에 따른 classification accuracy.
Accuracy (%): train-test-time > train-time > test-time
(이후의 실험에서부터는 train-test-time augmentation을 default로 둔다.)
Augmentation Performance
여기서는 augmentation method에 따른 accuracy의 결과를 보자.
실험 setting:
- Framework: PyTorch
- Overfitting을 피하기 위해 두 LSTM layer 모두에 대하여 dropout rate를 0.5로 설정.
- Training epoch = 80
- Mini-batch size = 128
- Learning rate = 0.001 (초기), training accuracy가 3번의 연속된 epoch 동안 개선되지 않는다면 절반으로 줄어든다.
Augmentations on Full Dataset
바로 다음 그림을 보자.
서로 다른 augmentation method 를 적용함에 따른 classification accuracy.
Accuracy (%): rotation > flip > Gaussian noise
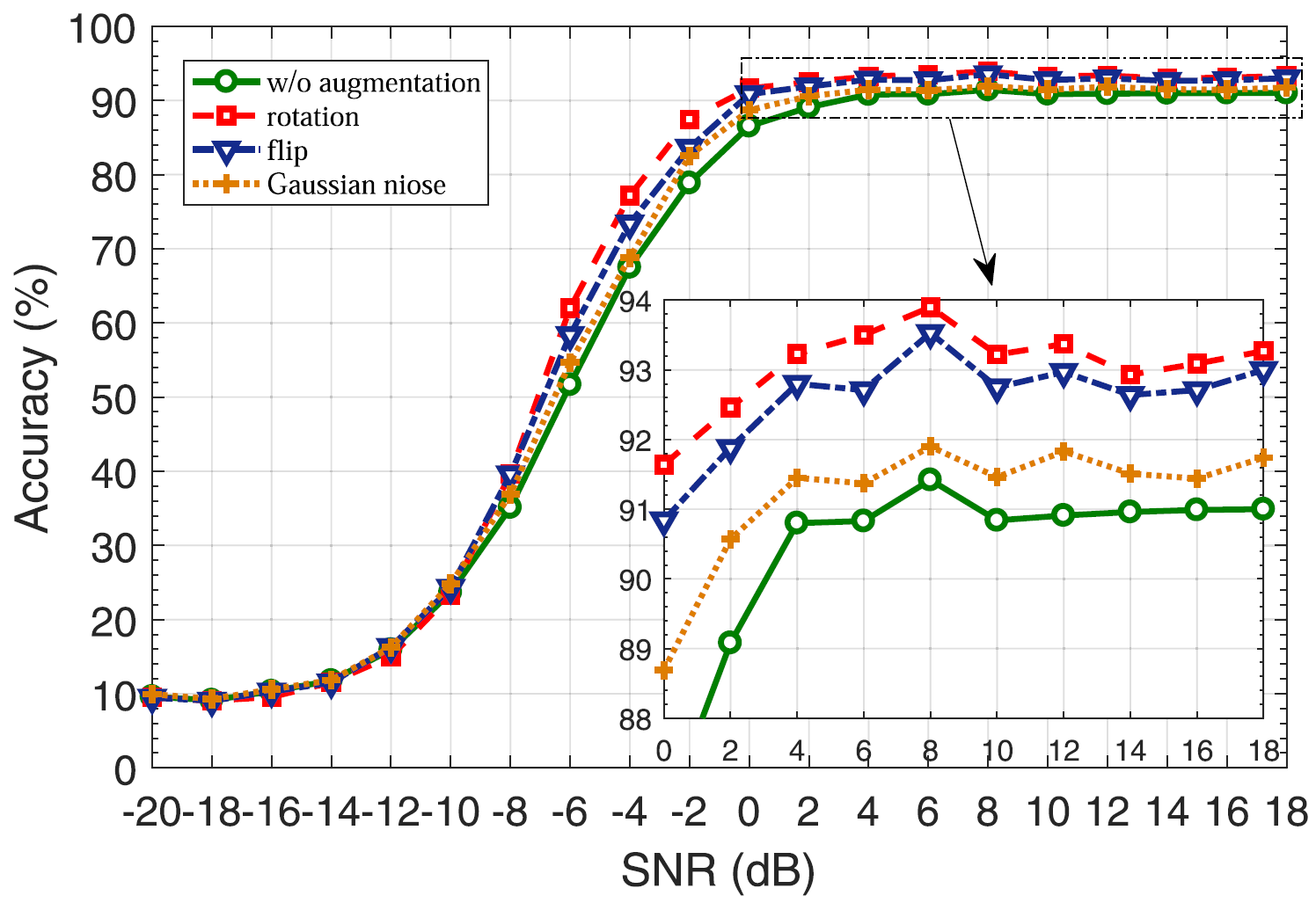
Gaussian noise method는 특이하게 낮은 SNR 구간 (-16dB to -10dB)에서 더 좋은 성능을 보여준다. 이를 직관적으로 생각해보면 Gaussian noise를 더한다는 것은 원본 sample의 SNR을 낮춘다는 것이다. 이 말인즉슨, 결국 낮은 SNR을 가지는 signal sample이 더 만들어진다는 것이기 때문에 SNR이 낮은 상황에서 진행되는 학습에 더 유리해지는 것이다. 하지만 개선되는 정도가 매우 낮은 것을 확인할 수 있기 때문에, rotation과 flip method에 비해 선호되지 않을 것이다.
추가로, 논문을 참조하면 각 method를 적용한 것에 대한 confusion matrix의 결과가 SNR 값(낮음/높음)에 따라 첨부되어 있다. 이를 통해서도 모든 modulation category에 대해 Gaussian noise를 사용하는 방식이, 일반적으로 나머지 두 방법을 사용하는 것보다 안 좋다는 것을 확인할 수 있다.
Augmentations on Partial Dataset
부족한 training set에 대해 augmentation method를 적용함에 따른 성능도 비교해보았다. 다음의 그림을 보자.
Training dataset 의 크기에 따라 여러 augmentation method 를 적용시킨 것에 대한 accuracy.
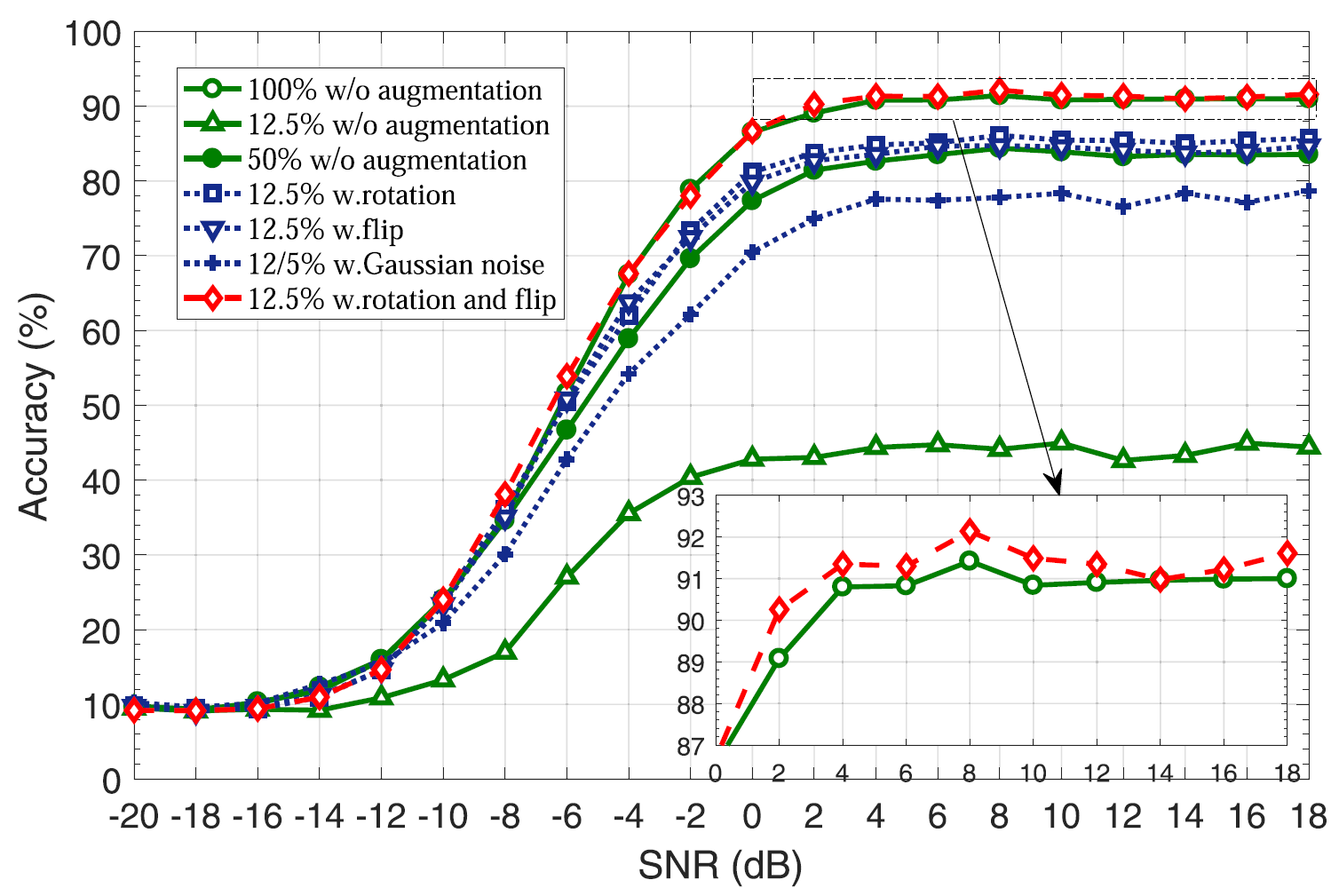
학습을 위한 새로운 sub-dataset을 구성하기 위해 논문에서는 110,000 개의 학습 sample들을 random 하게 12.5% 만큼 골랐다. 이러한 subset을 이용하여 학습을 진행하였고, test는 110,000 개의 testing sample에 대해 진행되었다. 참고로 위의 그래프에서 초록색 세모 선을 보면 알 수 있듯이, 이러한 training set은 LSTM network를 학습시키기에는 매우 부족한 양이다.
결과를 분석하면 다음과 같다. 우선 sub-dataset을 이용하여 로 설정한 다음 augmentation 없이 절반의 training set을 사용한 경우를 baseline으로 잡은 뒤 (data 크기를 맞추기 위함) 둘의 성능을 비교한 결과, rotation 및 flip method를 사용했을 때의 정확도가 baseline 보다 약 0.04% ~ 4.03% 만큼 더 좋다는 것을 확인할 수 있었다.
추가로 rotation과 flip method를 같이 사용하는 joint augmentation도 적용해보았다. 으로 두어 초기 dataset 크기 대비 75%의 크기를 갖는 dataset을 만든 다음, augmentation 없이 학습 dataset을 100% 사용한 경우와 비교해 보았는데, 둘이 비슷한 accuracy를 나타내는 것을 확인할 수 있었다.
아래의 그림을 통해 joint method의 효과를 더 확인해 볼 수 있다.
SNR = 18dB 일 때, 12.5% 의 학습 dataset을 사용하여 얻은 confusion matrix의 결과.
왼쪽부터 순서대로 No augmentation / Rotation / Flip / Gaussian noise / Rotation + Flip 이다.
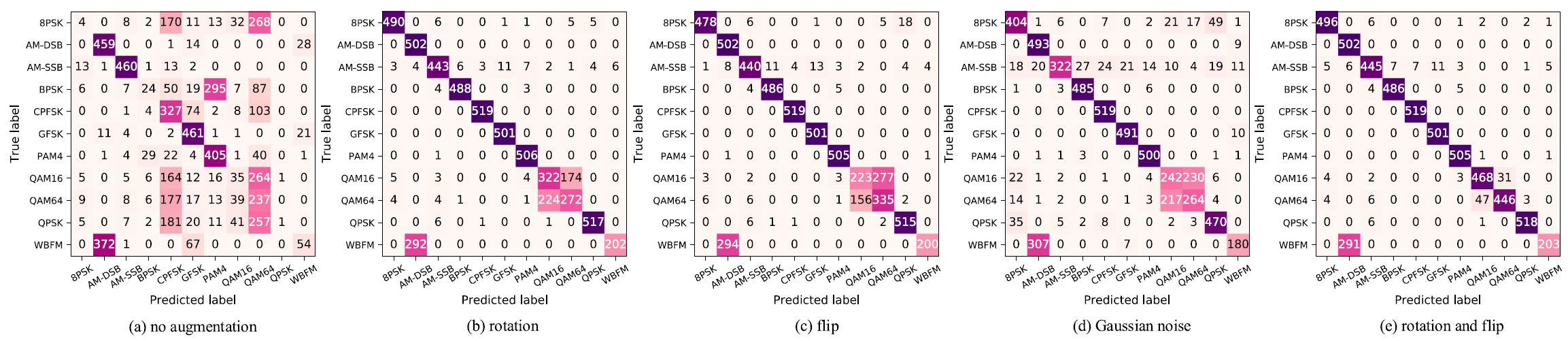
참고로 세 가지 method를 모두 조합한 joint augmentation 조합도 시도해보았지만, 오히려 성능이 낮아지는 것을 확인할 수 있었다.
Augmentations on Short Sample
여기서는 sampling point의 개수를 줄임에 따른 augmentation method의 영향을 알아본다.
논문에서는 각각 128개의 point로 구성된 기존의 radio signal sample을 두 개의 새로운 sample로 나눠, 각각 64개의 point를 가진 signal sample을 440,000개로 만들었다. 이후, 그 중에서 절반을 골라 LSTM의 network에 입력하고, 나머지 절반의 data를 이용하여 추가로 test를 진행했다.
(물론 각 LSTM layer의 cell 개수도 64로 줄였고, 그 덕분에 LSTM network의 parameter 개수도 줄어 (FLOPs = floating-point operations 의) inference complexity가 절반으로 감소했다.)
이제 아래의 그림을 보자.
Signal length 에 따른 accuracy 비교.
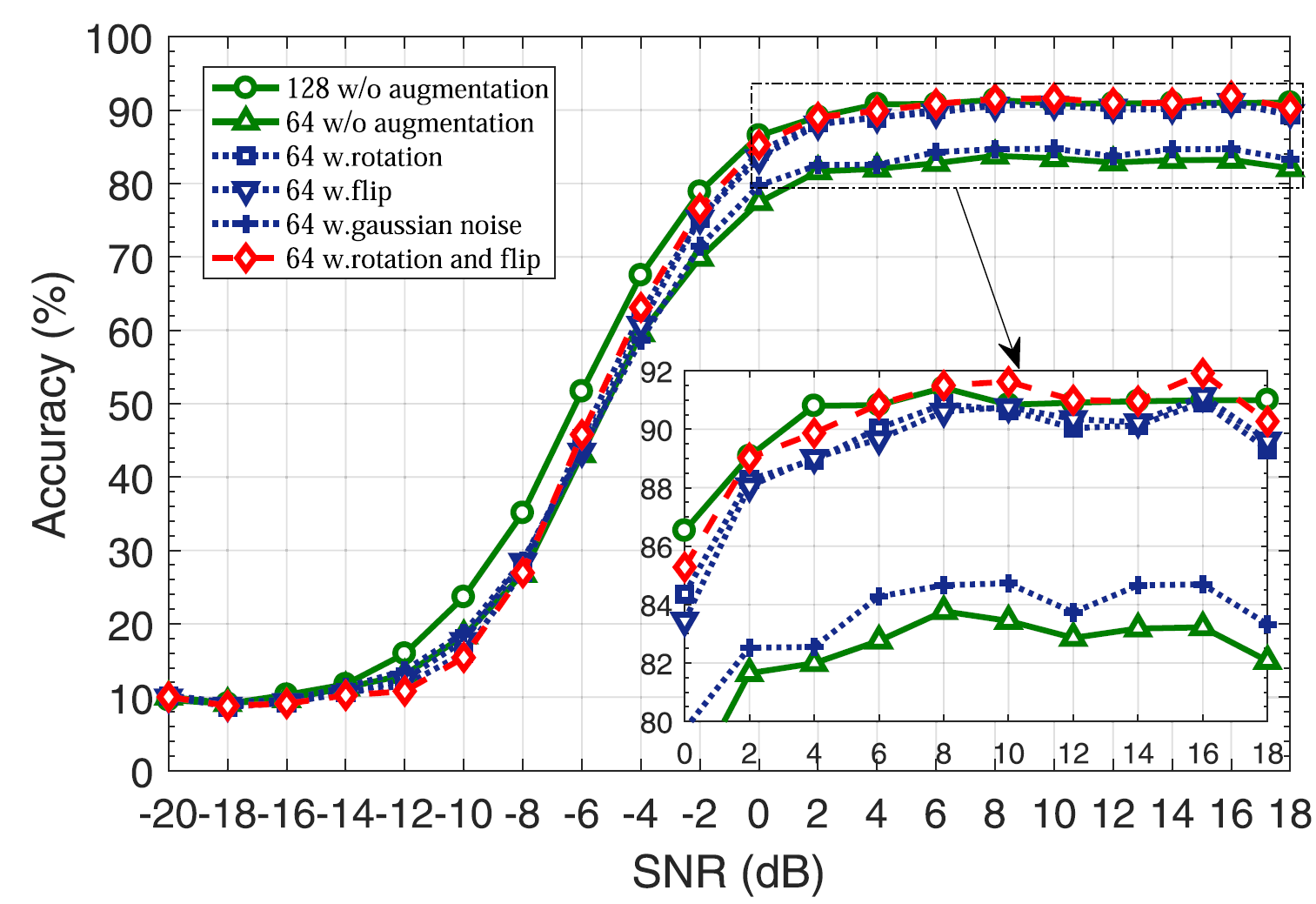
위의 결과를 정리해보면, sampling point를 절반 밖에 받지 못하는 상황에서도 제안한 data augmentation 방식을 사용하여 signal modulation을 잘 분류할 수 있다. 이는 곧 classification response time을 상당히 줄일 수 있다는 것을 의미한다.
Conclusion
본 논문에서는 deep learning을 기반으로 한 modulation classification task에 적용할 수 있는 augmentation 기술들을 알아보았다. LSTM model을 사용하여 rotation, flip, Gaussian noise의 총 3가지 method에 대한 결과를 분석해 보았는데, 위에서 설명했던 내용들을 그대로 정리한 것 뿐이라 이 부분은 생략하도록 하겠다.
Reference
Huang, Liang, et al. "Data augmentation for deep learning-based radio modulation classification." IEEE Access 8 (2019): 1498-1506.
