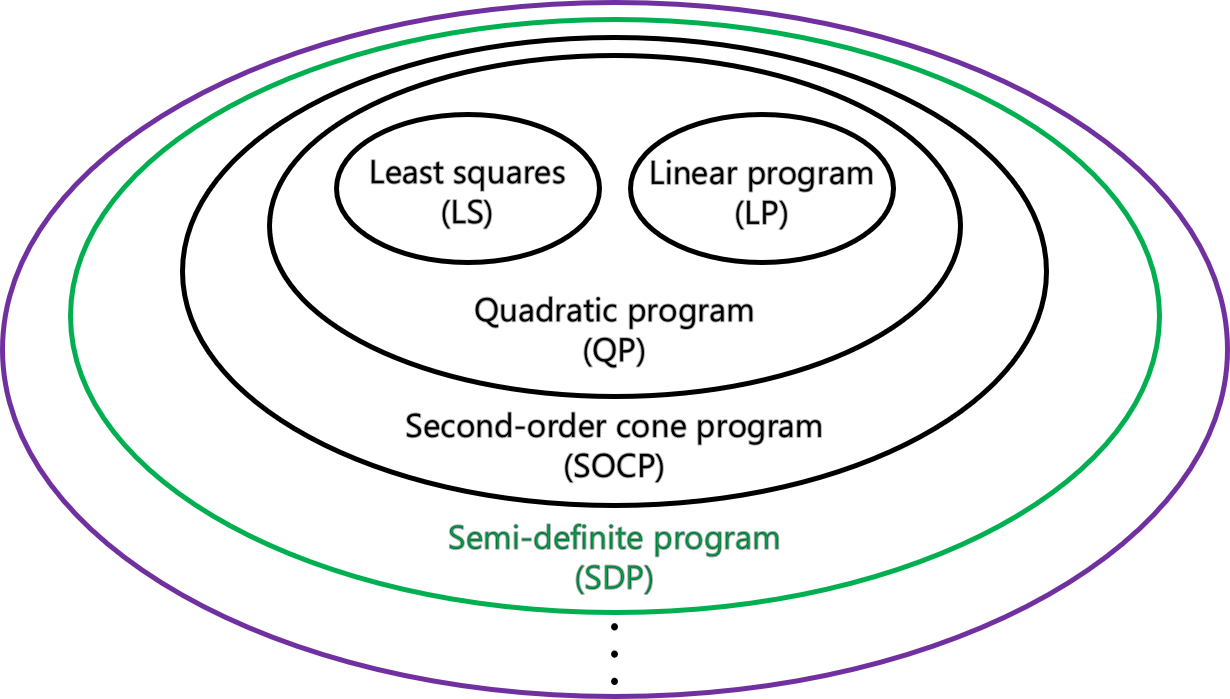
이전 포스팅에 이어 이번에는 SDP의 응용 방법에 대해 알아보자. 여기서 다룰 내용은 총 세 가지이다.
SDP가 중요하게 적용될 수 있는 두 가지 settings
SDP relaxation
MAXCUT problem
Two settings of SDP's interest
SDP가 잘 적용될 수 있는 문제는 무엇일까? 이에 대한 대답은 다음과 같다.
A class of very difficult non-convex problems SDP relaxation 을 이용하면 그러한 어려운 문제들을 잘 근사 할 수 있다.
Matrix가 가진 eigenvalue의 최대값 혹은 nuclear norm이 우리가 최소화 하고 싶은 값인 problems → Nuclear norm ∣∣A∣∣∗:=∑iσi(A), 이때 σi(A)은 A의 i 번째 singular value를 의미한다.
이와 관련된 가장 유명한 application은 matrix completion 인데, 이는 일부분만 공개된 행렬에서 missing entries를 확인하는 것이 목표인 문제이다.
본 강의에서는 이 중 SDP relaxation에 대해서만 다루었다. 이제 SDP relaxation을 적용할 수 있는 예시 문제를 통해 이를 더 자세히 알아보자.
MAXCUT problem
(SDP relaxation이 유용하게 적용될 수 있는 문제들 중 하나)
본 문제의 목적은 cut을 최대화 시킬 수 있는 set을 찾는 것 이다. 이 말의 의미가 무엇인지 알기 위해서는 먼저 set과 cut이 무엇인지를 알 필요가 있다.
먼저 해당 용어들은 graph를 다룰 때 등장하는데, graph는 edge set (edge, 간선) 과 vertex set (node, 정점) 두 가지로 이루어져 있다. MAXCUT 문제에서는 각 edge가 direction을 가지고 있지 않는 undirected graph 를 다루는데, E 안의 edge 중 하나인 (1,2)를 예로 들면 (1,2)=(2,1) 임을 의미한다.
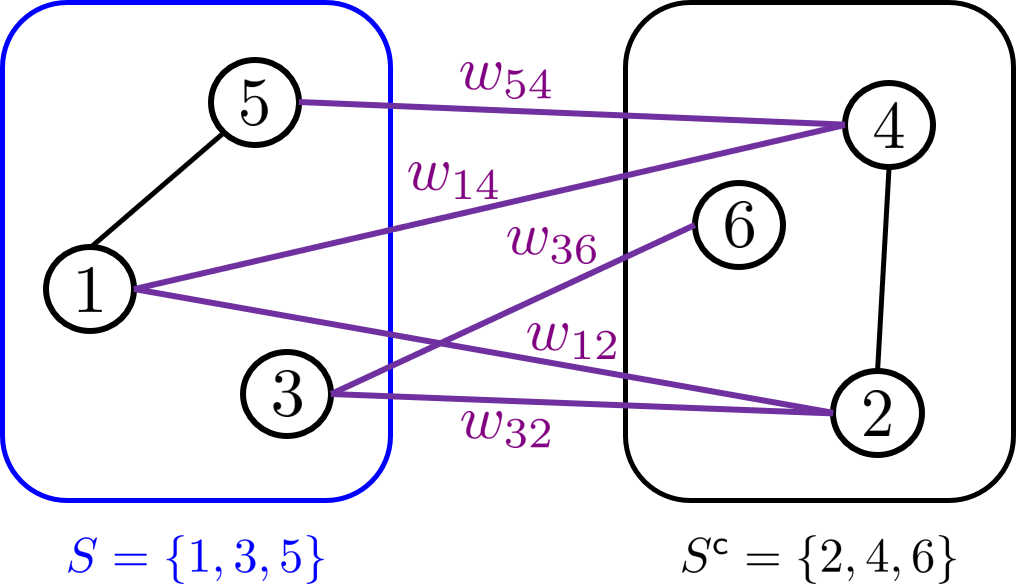
이제 아래의 그림을 보자. 이 경우 edge set은 다음과 같다.
E={(1,2),(1,4),(1,5),(2,3),(2,4),(3,6),(4,5)}
그림에는 weight (연결에 대한 가중치)도 같이 표기되어 있는데, 이는 edge와 같이 연결되는 개념이다. 따라서 아래 예제에서 weight의 개수는 총 7개 이다. (총 edge 개수와 동일, 보라색 선은 그 중 일부이다.)
그렇다면 set과 cut은 무엇을 의미할까. 먼저 set S 는 vertex (꼭지점) set V 의 subset을 의미한다. 예를 들면, 위의 그림에서 set은 S={1,3,5}⊂V 이다. 다음으로 cut은 set S 와 complement Sc 를 잇는 edge들이 가지고 있는 weights의 총합 (보라색 표시)으로 정의된다. 이 역시 같은 그림을 통해 예를 들면, crossing edge는 {(5,4),(1,4),(3,6),(1,2),(3,2)} 임을 알 수 있다. 따라서, set S 에 대한 cut은 아래와 같이 정의된다. (영어로는 'the cut w.r.t. the set S')
Cut(S)=w54+w14+w36+w12+w32
MAXCUT via optimization
MAXCUT을 위한 optimization problem을 정의하기 위해서는 먼저, 적절한 optimization variable을 선택해야 한다. 그런데 problem을 통해 우리는 cut이 set의 선택에 따라 달라지는 것을 알 수 있다. 문제의 목적은 cut을 최대로 만들 수 있는 set을 찾는 것이다. 따라서, 새로운 변수 xi를 다음과 같이 정의해보자. 이는 node i가 set S에 있는지 알려주는 변수이다.
xi={+1,−1,x∈Sotherwise.
주목할 부분은 xi=xj 인 경우이다. 이때는 edge (i,j) 가 두 set, S 와 Sc 를 잇고 있다는 뜻이기 때문에 wij가 Cut(S)에 기여하고 있음을 의미한다. 반대로 만약 xi=xj 라면, cut 값에 영향을 주지 못하게 된다. 이를 이용하면 우리는 다음의 optimization 식을 세울 수 있다.
위의 식에서 1/2 이 곱해진 이유는 xi=xj 일 때 wij 만을 얻기 위함이고, xi2=1 이라는 constraint는 xi가 오직 +1 혹은 −1 값만 갖도록 만들기 위함이다.
A translation technique: Lifting
(∗) 의 objective function에는 xixj 같은 quadratic term이 존재한다. 또한 quadratic equality-constraint가 있는 것도 확인할 수 있는데, 지금까지 배웠던 convex standard form 중 어떤 것도 이와 matching 되지 않는다. 따라서 이러한 원하지 않는 term을 원하는 형식 (e.g. affine term) 으로 바꾸는 과정이 필요한데, 이때 쓰이는 technique이 lifting 이다. 여기서 lifting은 optimization variable이 속해 있는 공간을 끌어올린다는 의미로 사용되었는데, 빠른 이해를 위해 예시를 보자.
앞선 예제에서 optimization variable xi 들은 vector x:=[x1,⋯,xd]⊺ 로 표현될 수 있다. 여기서 lifting은 vector x를 더 고차원의 entity 즉, matrix로 변환하는 것을 의미한다. 더 구체적으로는 (i,j)-entry Xij 가 xixj 로 정의된 matrix X를 생각해볼 수 있을 것이다.
Matrix X의 rank는 1이고, eigen-value는 x⊺x 이다.
Proof: Xx=(xx⊺)x=x(x⊺x)=(x⊺x)x
이때 eigen-value x⊺x는 non-negative scalar 값이다.
따라서, X의 eigen-vector와 eigen-value는 각각 x 와 (x⊺x) 이다.
이제 X의 등장으로, 기존의 constraint는 다음과 같이 대체될 수 있다.
Xii=1,X⪰0,rank(X)=1
여기서 'rank(X)=1' 조건이 생긴 이유가 납득되지 않을 수 있다.
이는 X=xx⊺ 과 같은 lifting을 진행할 때 주의할 점이 있기 때문인데, 우린 새로운 optimization variable을 도입할 때마다 그로 인한 추가 constraint가 생기지는 않는지 따져봐야 한다.
본 예제에서는 X 가 새로운 variable로 정의되었는데, 강의에서의 표현을 빌리면 xx⊺ 과 같은 형태는 매우 particular 한 (혹은 structured 된) 것이다.
이렇게 되면 보통 새로운 constraint가 등장하는데, 이러한 맥락에서 추가된 것이라 보면 된다.
이어서 정리하면 새로운 matrix variable X를 사용하여, (∗) 을 아래와 같이 다시 쓸 수 있다.