
ABSTRACT
질병의 빠르고 정확한 진단은 적절한 치료를 제공하는 데 중요한 요소이다.신경망 네트워크 기술은 정확성과 시간 측면에서 제한이 있는 다른 기술과 달리 의학적 진단 작업에 강력한 식별 분류기로 사용된다.
이 논문에서는 RBFN을 활성화 함수로 사용하여 CKD 검출을 위한 특징 추출과 분류를 모두 수행하는 딥러닝 방법을 제안한다.
RBFN은 정확하고 빠르고 진단 능력이 뛰어나 의학에서 사용하기에 유용한 네트워크이다.
정확도, 특이성, 민감도 측면에서 더 나은 성능이 분류 모델로 선택된다.
RBF 모델의 성능을 테스트하기 위해 6개 질병의 임상 증상을 샘플로 하는 CDK 데이터셋을 사용한다.
훈련 방법을 적용한 후 네트워크는 이러한 증상을 샘플 환자로부터 얻은 증상과 매치하여 프로그램에 입력된 올바른 질병을 결정한다.
결과적으로 우수한 성능, 낮은 오류율, 높은 정확도를 보인다.
1. Introduction
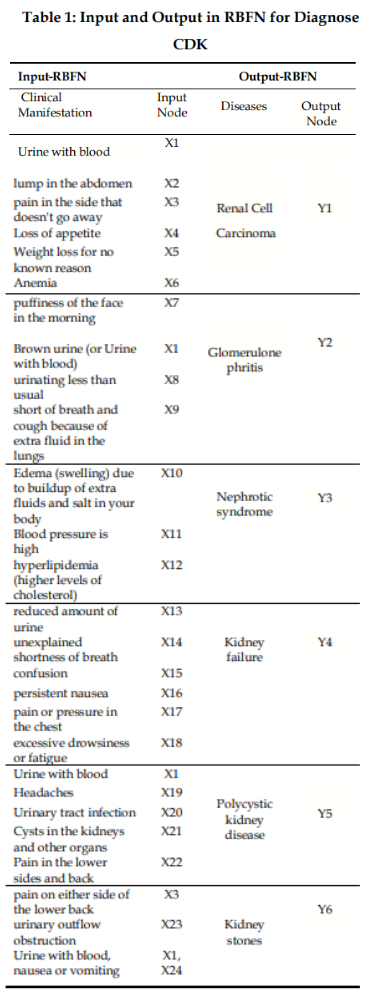
제안된 알고리즘에서는 6개의 CDK 질병에 대한 샘플로서 이러한 질병의 증상은 데이터셋에 저장된다.네트워크의 입력은 환자로부터 받은 임상 소견이다.
이 연구에서 사용하는 6가지 질병의 샘플은 다음과 같다.
1. 신장 세포 암종 (Renal Cell Carcinoma)
2. 사구체신염 (Glomerulonephritis)
3. 신증후군(Nephrotic Syndrome)
4. 신부전(Kidney Failure)
5. 다낭성 신장 질환(Polycystic Kidney Disease)
6. 신장결석증(Kidney stone disease)
2. Artificial Neural Networks ANN
ANN 일반 용어는 통계학과 컴퓨터 과학 모두에서 다양한 시스템과 다양한 유형의 접근 방식을 포함한다.RBNF은 보편적인 근사치와 빠른 학습 속도 때문에 다른 신경망과 구별되었다.
따라서 다른 네트워크와 비교하여 하이브리드 특성을 갖는 것이 특징이며, 적응 및 수정 능력을 갖춘 가장 중요한 인공신경망 중 하나이다.
2.1. Radial Basis Functions Network
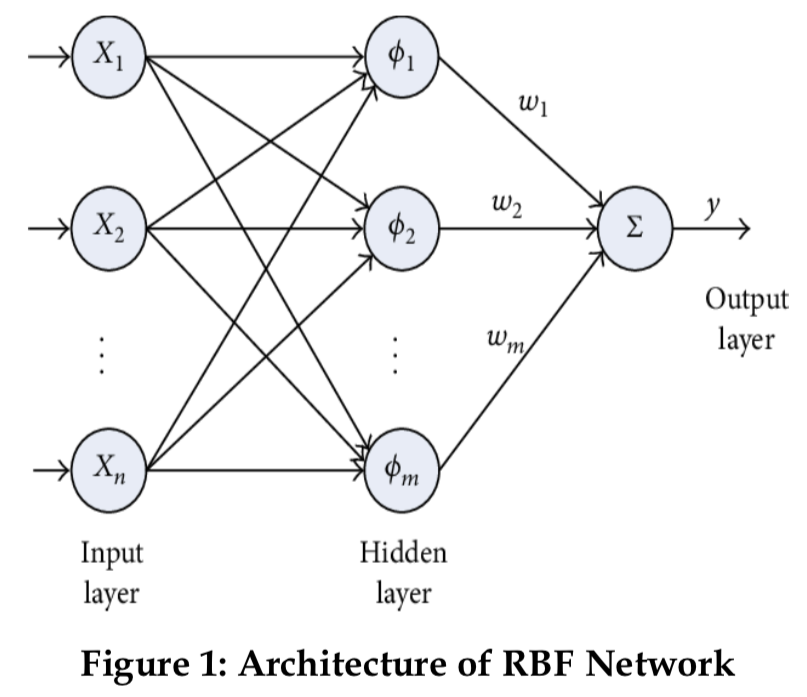
RBFN은 비선형 분류 작업에 특화되어 있고, 방사형 기저 함수(RBF)의 통합에 의존한다.
RBFN은 그림 1과 같이 입력층, 은닉층, 출력층의 3개의 층으로 구성된 피드 포워드 신경망의 일종으로, 각 층은 뉴런들의 집합으로 구성된다.
각 뉴런은 RBF 뉴런을 사용하며, 이 뉴런은 저장된 훈련 값을 입력과 비교하고 유사성 측정을 계산하여 입력 벡터와 비교함으로써 입력 벡터를 평가한다.
그런 다음 각 유사성 값에 가중치를 곱하고 출력 계층에서 합계를 구한다.
입력과 훈련 데이터 사이의 유클리드 거리 측정은 새로운 입력을 쉽게 계산하는 데 사용될 것이다.
어떤 계층의 각 셀은 그림 1에 나온 것처럼 weight에 의해 다른 계층의 모든 셀과 연관된다.
2.2. Mechanism of Radial Basis Function Network
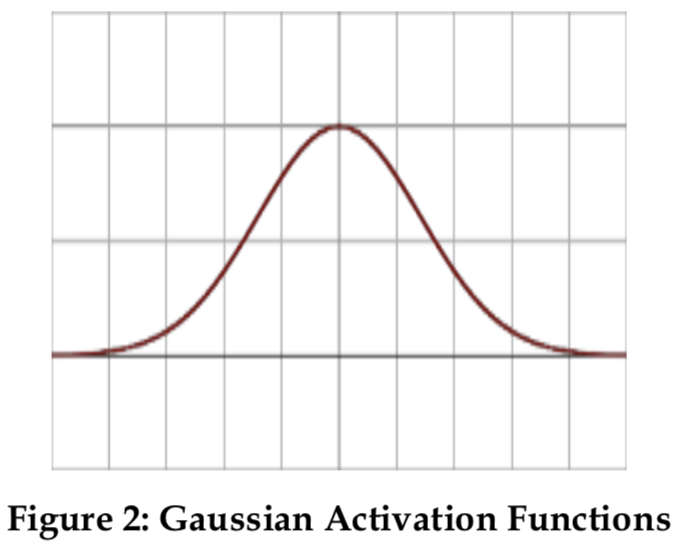
RBFN에서 사용되는 여러 활성화 함수는 다음과 같다.1. 가우시안 활성화 함수(Gaussian Activation Functions)
수용체(recepter) = t 로 정의한 다음, 수용체 주위에 마주보는 지도를 그은 다음 RBF에 대한 가우스 활성화 함수를 적용한다.
반경 거리는 r = ∣∣x-t∣∣ 로 정의되었고, 이때 x는 네트워크의 입력 벡터이다.
가우스 방사형 함수: φ(r) = exp (-r²/2σ²) ··· σ>0일 때
φ(r)은 실제 출력을 나타내며 출력 값은 그림 2와 같이 [0-1] 사이로 제한된다.
2. 시그넘 활성화 함수(Signum Activation Function)
오리지널 퍼셉트론을 사용한다.
입력 합계가 특정 임계값(항상 0)보다 높으면 출력이 특정 값(1)이 되고, 입력 합계가 특정 임계값(0)보다 낮으면 출력이 -1이 된다.
f(x) = +1 ··· if x>=0
f(x) = -1 ··· if x<0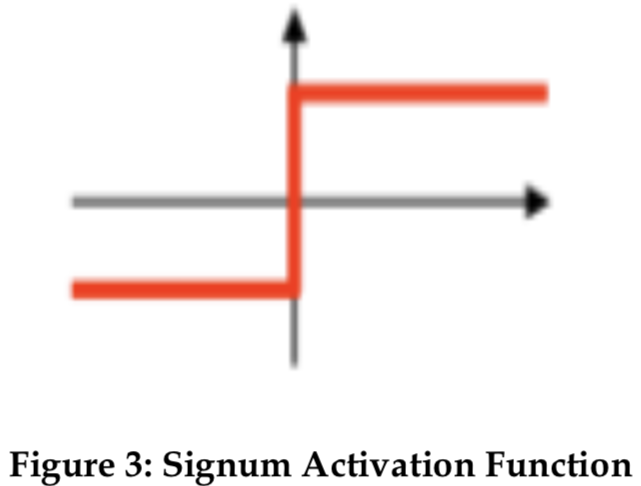
3. Proposed Algorithm
3.1. Train the Network
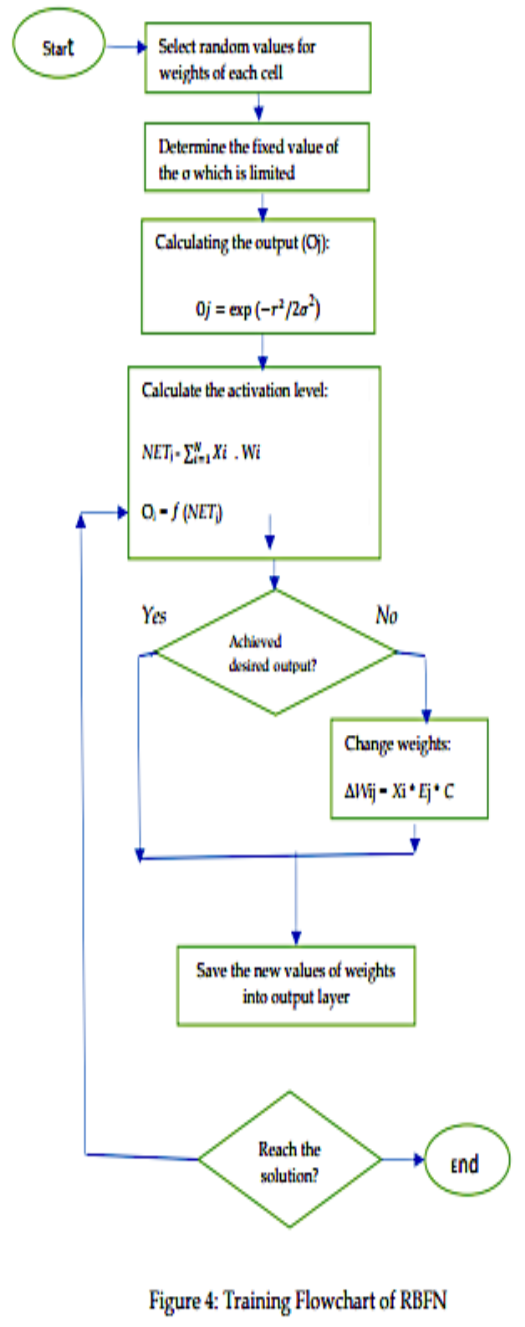
네트워크를 훈련시키기 위해 다음과 같은 단계를 거쳤다.1. RBFN에서 각 셀의 가중치에 대해 작은 기본값을 랜덤하게 선택한다.
2. σ의 고정값을 결정하며, 이 값은 [0-1] 사이로 제한된다.
3. 가우스 방사 함수를 통해 숨겨진 레이어의 출력(Oj)을 계산한다.
4. 아래 방정식을 통해 출력층의 활성화 레벨(실제 출력 Oj)을 계산한다.
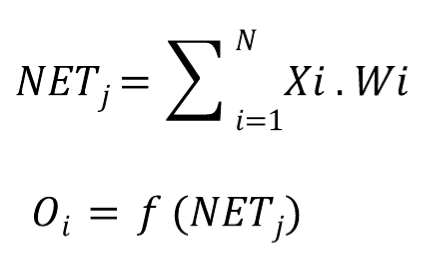
5. 원하는 출력이 달성되지 않으면 다음 방정식을 통해 가중치를 변경한다.
△Wij = Xi * Ej * C
Where:
Xi: 셀 j의 입력
C: 네트워크 내 학습 비율
Ej: 다음과 같이 계산된 오류의 비율
following:
Ej = Tj - Oj
Tj: 셀 j의 원하는 출력
Oj: 셀 j의 실제 출력
다음 단계에서 생성된 새로운 가중치 값은 출력 계층에 유지된다.
6. 원하는 솔루션에 도달할 때까지 4단계부터 5단계까지 단계를 반복한다.
훈련 알고리즘의 흐름도는 그림 4와 같다.
3.2. Calculate the Weights
출력층뿐만 아니라 제1 처리 레이어(숨김 레이어)의 초기 가중치는 [1-0] 사이로 제한된 랜덤 생성 수치로 구성된다.가중치 변경은 다음과 같이 수행되었다.
- 1-Hidden layer : weight은 훈련에 비협조적이기 때문에 변하지 않는다.
- 2-Output layer: 필요한 출력이 RBF 알고리즘에 설명된 수학적 방정식을 통해 얻어지지 않을 때 가중치가 변경된다.
3.3. Design and Implementation of RBFN
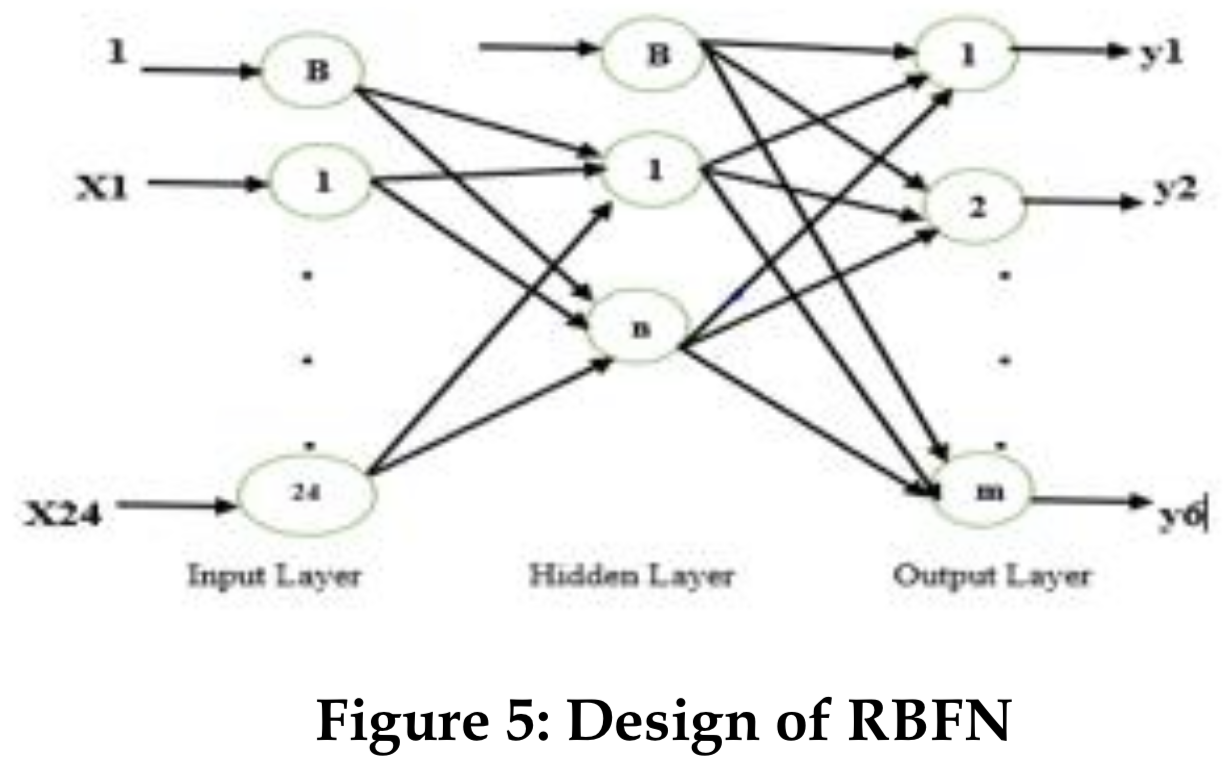
RBFN에서 숨겨진 계층의 모든 셀의 값은 뉴런과 관련된 특정 가중치를 곱하여 출력 뉴런으로 전달된다.제안된 알고리즘에서 설계된 RBFN은 입력 계층에 하나의 숨김 레이어와 바이어스 셀을 가지고 있으며, 출력 계층에 바이어스 셀을 가지고 있어 네트워크의 작업 속도를 높이고 올바른 솔루션에 접근한다.
바이어스 셀의 입력은 1이다.
이 알고리즘으로 진단된 질병은 분석이나 X선에 의존하지 않고 환자로부터 받은 RBFN에 입력되는 명백한 병리학적 증상에 의존한다.
입력 증상(데이터셋)은 표 1에 있는 질병 증상의 수에 따라 번호가 결정되며 알고리즘 훈련을 통해 RBFN이 질병과 매치할 것이다.
사용되는 RBFN은 세 개의 레이어로 구성된다.
- 1-input layer
- 한 층의 셀 수는 바이어스 셀뿐만 아니라 24개이다.
- 메인 프로그램을 실행하는 동안 증상을 선택하고 네트워크의 학습 비율과 중간 레벨 셀의 수를 결정한다.
- 병리학적 증상을 삽입한 후 질병에 해당 증상이 있는지 확인한다.
- 프로그램에 명시된 질병 중 하나와 동일한 경우, 진단 검사 결과가 된다.
- 프로그램에 명시된 질병과 완전히 동일하지 않은 경우, 결과는 하나 이상의 질병 또는 특정 오류율을 가진 다른 질병이 될 것이다.
- 2-hidden layer : 숨겨진 레이어에 있는 셀의 수는 N+1이므로, 이 레이어에 바이어스 셀을 더하면 24+1이다.
- 3-output layer : 연구에 명시된 질병의 수를 나타내므로 6이다.
4. Results
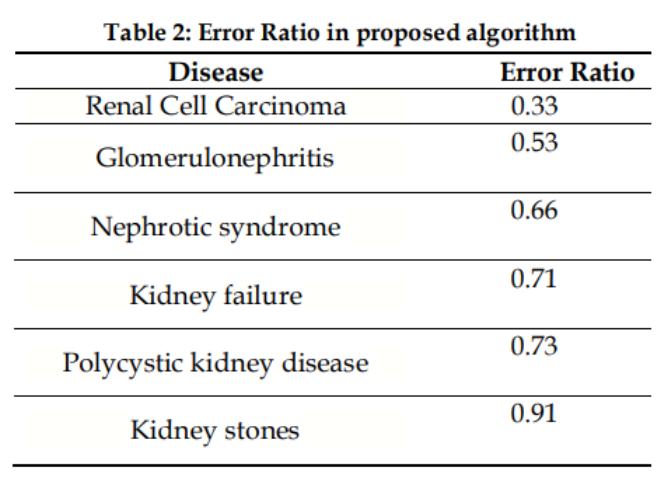
제안된 알고리즘에 따른 네트워크 훈련 과정을 통해 실제 출력에 가까운 만족스러운 결과를 얻었다.표 2에서 보듯이, 오차율은 낮고 정확도는 높았다.
4.1. Effect of Learning Ratio on the RBFN Training Times
숨겨진 레이어의 셀 수는 네트워크 복잡성과 일반화 능력에 영향을 미치기 때문에 이를 정하는 것은 중요하다.숨겨진 레이어의 셀 수가 부족할 경우
1. RBFN는 데이터를 적절하게 학습할 수 없다.
2. 셀 번호가 너무 높아질 수 있다.
3. 일반화가 잘 안 될 수 있다.
4. 과잉 학습 상황이 발생할 수 있다.RBFN이 훈련 과정 중 학습 비율을 사용할 때 [0-1] 사이로 제한되는데, 이는 훈련 네트워크 시간 수에 영향을 미친다.
이 비율이 매우 작은 것은 부적절하다.
예를 들어, 숨겨진 층 셀의 수가 2라면, 비율이 감소할 때 표 3와 그림 6에 보이는 것과 같은 결과를 볼 수 있다.
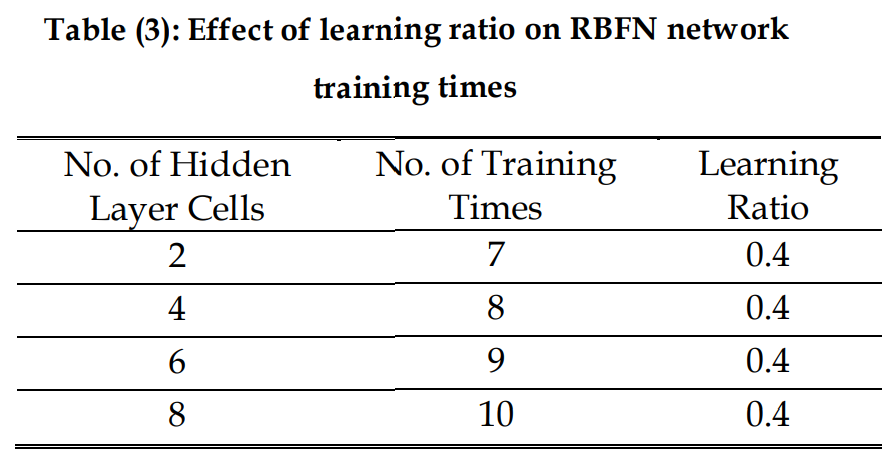
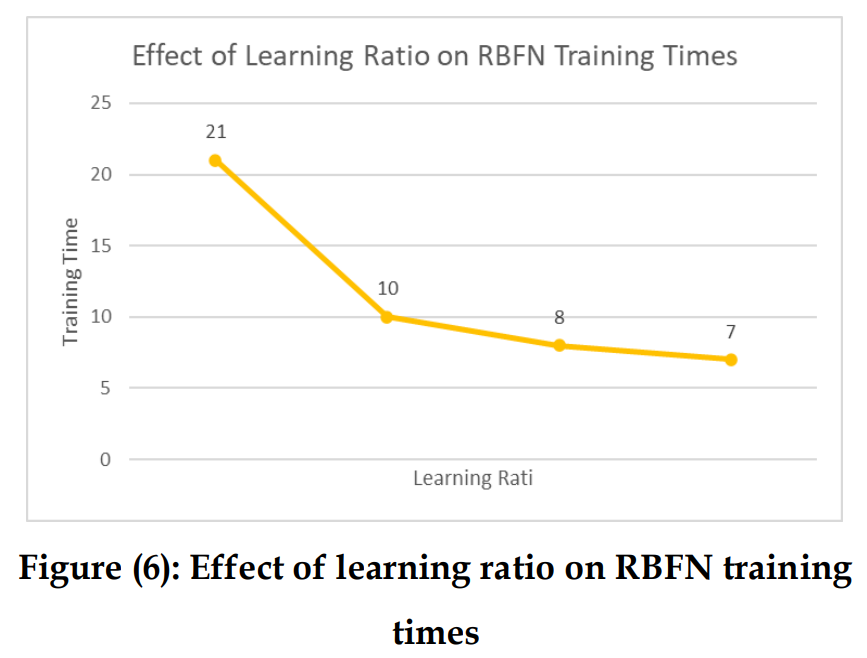
4.2. Effect Number of Hidden Layer Cells on the Number of Training Times
숨겨진 레이어 셀의 수는 원하는 결과에 액세스하는 데 걸리는 횟수에 영향을 미치며, 숨겨진 레이어 셀의 수가 증가하면 네트워크 훈련 시간도 증가한다.
5. CONCLUSION
RBFN을 사용하는 것은 다른 방법에 비해 일부 환자 그룹에 대해 더 나은 정밀도와 정확도의 진단을 제공했다.신경망 모델의 민감도와 특이성은 로지스틱 회귀에 비해 더 나은 예측력을 가지고 있으며, 이는 CDK와 같은 많은 질병을 진단할 가능성을 보장한다.
