[논문] Deep Learning for Joint Acoustic Echo and Noise Cancellation with Nonlinear Distortions
[논문]
목록 보기
2/2

Summary
.
.
.
ABSTRACT
기존에 딥러닝을 이용한 노이즈 캔슬링에서 가까운 소리가 단일 마이크 녹음에서 분리되어 먼 쪽으로 전송되는 문제가 있다.이 논문에서는 이 문제를 해결하기 위해 CRN(Convolutional Recurrent Network)과 LSTM(Long Short-Term Memory)을 통합하는 인과 시스템을 제안한다.
평가 결과는 제안된 방법이 시뮬레이션 및 측정된 RIRs(Room Impulse Responses) 모두에 대해 비선형 왜곡이 있는 경우 음향 에코 및 배경 잡음을 효과적으로 제거한다는 것을 보여주며, 훈련되지 않은 노이즈, RIRs 및 스피커로 잘 일반화된다.
1. Introduction
전통적인 AEC(Acoustic Echo Cancellation)
-
음향 에코가 적절하게 처리되지 않을 경우, 시스템의 먼 끝에 있는 사용자가 에코에 의해 지연된 자신의 음성을 듣게 됨
-
기존의 알고리즘
- 더블 토크(가까운 스피커와 먼 스피커가 모두 대화하는 것), 배경 잡음(특히 비선형노이즈)이 있는 환경에서 성능 제한 문제
- 이에 대한 기존의 성능 개선 방법
- 더블 토크가 있을 경우
- 이중 대화 검출기 사용
- double-talk-roburt AES 알고리즘 사용
- 노이즈가 많은 환경일 경우
- 사후 필터링
- 칼만(Kalman) 필터링
- AES(Acoustic Echo Suppression) 알고리즘
- 더블 토크가 있을 경우
- 비선형 왜곡의 발생 원인 : 주로 전자 장치(증폭기, 확성기 등)의 품질이 좋지 않기 때문
- 이에 대한 기존의 성능 개선 방법
- 더블 토크(가까운 스피커와 먼 스피커가 모두 대화하는 것), 배경 잡음(특히 비선형노이즈)이 있는 환경에서 성능 제한 문제
-
전통적인 AEC 알고리즘은 본질적으로 비선형 왜곡을 겪는 선형 시스템임
딥러닝 기반 방법
-
전통적인 AEC와의 차이점
- 여기에서는 더블 토크 감지 또는 포스트 필터링을 수행할 필요가 없음
- 소음이 많은 환경일 경우
- AEC의 궁극적인 목표
- 에코 및 배경 소음을 완전히 제거하고 가까운 음성만 먼 곳으로 전송하는 것
- 딥러닝 기반 방법
- 감독된 음성 분리 문제로 다룸
- 여기에서 가까운 소리 신호는 마이크 녹음에서 분리될 대상 소스임
- AEC의 궁극적인 목표
2. Proposed method
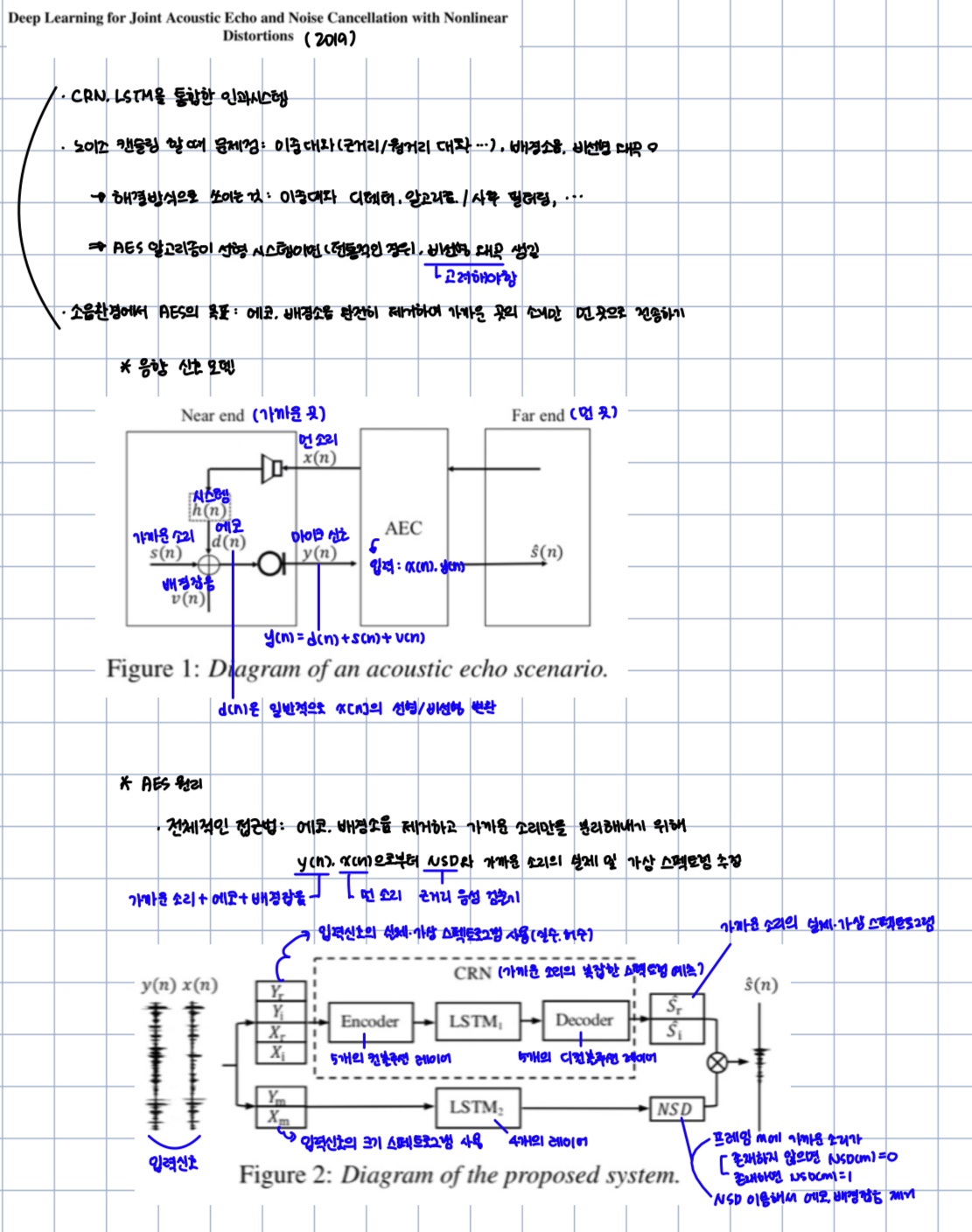
음향 신호 모델은 그림 1과 같다.
그림 1에서, 각 신호의 의미는 다음과 같다.
- y(n): 마이크 신호
- y(n) = d(n) + s(n) + v(n)
- n: 시간 샘플
- 라우드 스피커 신호를 RIR로 합성하여 에코 생성
- d(n): 에코
- 원단 신호 x(n)의 선형 또는 비선형 변환
- s(n): 가까운 소리
- v(n): 배경 잡음
2.1. Feature extraction
CRN은 입력의 실제 및 가상 스펙트럼을 취한다. 신호 x(n)과 y(n), LSTM2는 이들의 매그니튜드 스펙트로그램을 입력으로 사용한다.2.2. Training targets
이 연구에서 훈련 목표는 다음의 2가지이다.-
Complex spectrum of near-end speech
- 가까운 소리의 실제 및 가상 스펙트럼은 CRN의 훈련 대상으로 사용됨
- Sᵣ(m,c)과 Sᵢ(m,c)가 각각 시간 m과 주파수 c에서 T-F 단위 내의 타겟을 나타내도록 함
- 비교
- 크기 스펙트럼 매핑/마스킹 기반 방법
: 파형 재합성에 노이즈가 많은 위상을 사용함 - 복잡한 스펙트럼 매핑
: 크기와 위상 응답을 모두 향상 시킬 수 있음
- 크기 스펙트럼 매핑/마스킹 기반 방법
-
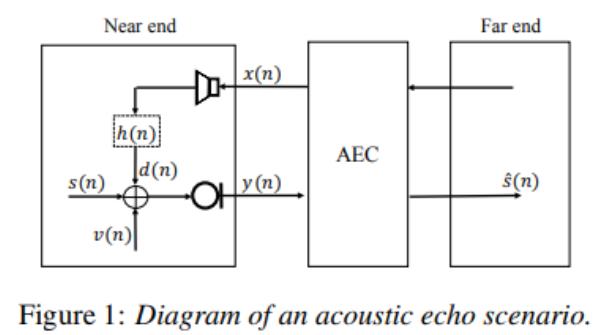
Near-end speech detector (근단 음성 검출기)
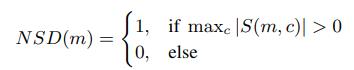
- NSD
- NSD는 가까운 소리의 활동을 감지하는 프레임 수준 이진 마스크로 간주할 수 있음
- 프레임 m에 가까운 소리가 존재하는지의 여부에 따라
- X: NSD(m)=0
- O: NSD(m)=1
- LSTM2에 의해 추정된 NSD
- 복잡한 스펙트럼 프로그램에 적용됨
- CRN에 의해 추정된 가까운 소리를 유지하면서 가까운 소리가 없는 프레임에서 잔류 에코와 노이즈를 억제함
2.3. Learning machines
제안된 시스템의 구성 요소는 다음의 2가지이다.
-
CRN
- 가까운 소리의 복잡한 스펙트럼을 예측하기 위해 사용됨
- 인코더-디코더 아키텍처임
- 인코더: 5개의 컨볼루션 레이어로 구성됨
- 디코더: 5개의 디컨볼루션 레이어로 구성됨
- 인코더, 디코더 사이에 그룹 전략이 있는 2계층 LSTM이 있음
- 마이크 신호(Yᵣ, Yᵢ)와 먼 신호(Xᵣ, Xᵢ)의 실제 및 가상 스펙트럼에 해당하는 4개의 입력채널을 가지고 있음
-
LSTM
- LSTM, LSTM₂는 입력 신호의 크기 스펙트럼(Ym,Xm)에서 NSD를 예측하는데 사용됨
- LSTM₂에는 각 레이어에 300개의 유닛이 있는 4개의 숨겨진 레이어가 있음
- 출력 계층은 완전히 연결된 계층임
- 시그모이드 함수는 출력에서 활성화 함수로 사용됨
2.4. Signal resynthesis
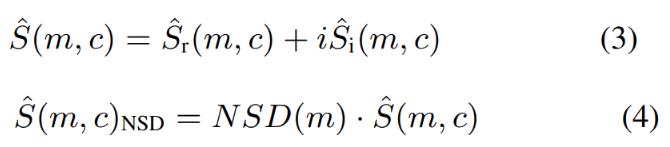
- CRN의 출력: 가까운 소리의 복잡한 스펙트럼 프로그램의 추정치임
- 위에서 i는 가상의 단위임
- NSD 추정 시 (3)은 (4)로 수정될 수 있음
- NSD가 정확하게 추정되는 경우
- (4)의 결과는 모두 0이어야 함
- 이는 (3)의 단일 토크 기간(single-talk period)의 잔류 에코 및 노이즈가 완전히 제거되는 것임
- 따라서 이 기간의 ERLE(Echo Return Loss Enhancement)는 무한대로 개선될 수 있음
3. Experimental results
3.1. Performance metrics
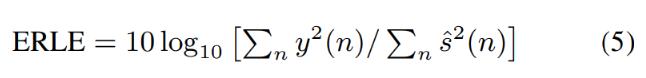
- 성능 평가 방법
- 단일 토크 기간에 대한 ERLE와 이중 토크 기간(double-talk period)에 대한 PESQ(Perceptual Evaluation of Speech Quality)의 지각 평가
- 본 연구에서 지정되는 ERLE는 (5)임
3.2. Experiment setting
- 사용한 데이터셋과 훈련 및 테스트 과정
- 데이터셋
- TIMIT 데이터셋
- 이중 통화, 배경 잡음 및 비선형 왜곡이 있는 상황에서 사용
- 테스트 혼합물에 NOISYX-92 데이터셋 및 Auditec CD 등이 사용됨
- TIMIT 데이터셋
- 훈련 및 테스트
- 20000개의 훈련 혼합물과 300개의 테스트 혼합물을 만듦
- 각 화자의 10개의 발화를 무작위로 선택하여 7:3으로 훈련 혼합물, 테스트 혼합물을 만들었음
- 과정
- 각 훈련 혼합물은 무작위로 선택된 라우드 스피커 신호와 RIR을 합성하여 에코 생성
- 무작위로 선택된 가까운 음성은 {-6, -3, 0, 3, 6}dB에서 무작위로 선택된 SER로 에코와 혼합됨
- 10000개의 소음에서 무작위로 잘라낸 것이 {8, 10, 12, 14}dB에서 무작위로 선택도니 SNR로 혼합물에 추가됨
- 더블 토크 기간 동안 평가되는 SER 및 SNR의 정의
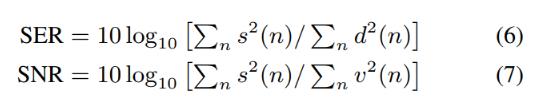
- 20000개의 훈련 혼합물과 300개의 테스트 혼합물을 만듦
- 데이터셋
3.3. Performance in double-talk and background noise situations
- 제안된 방법을 이중 대화 및 배경 잡음이 있는 시나리오의 일부 전통적인 방법과 비교
- 제안된 방법: CRN
- 전통적인 방법: JONLMS(Joint-Optimized Normalized Least Mean Square), ...
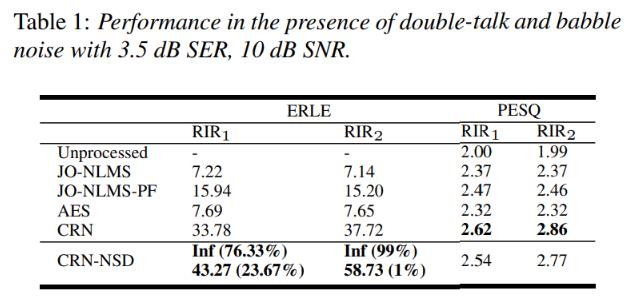
- 표 1은 서로 다른 RIR를 가진 더블 토크 및 옹알이 노이즈가 있는 300개의 테스트 혼합물의 평균 ERLE 및 PESQ 값을 보여줌
- 일반적으로 CRN 방법은 특히 ERLE 측면에서 기존 방법을 능가함
- NSD과 결합하면(CRN-NSD) 단일 토크 기간 동안 대부분의 테스트 혼합물의 ERLE가 무한대로 향상될 수 있음
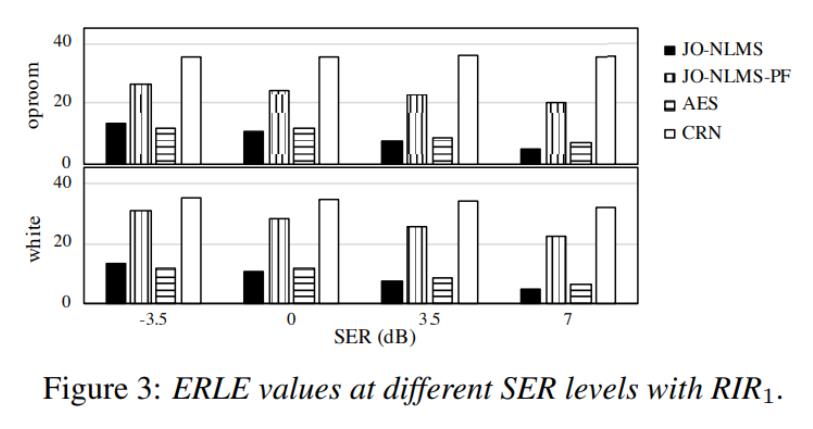
- 그림 4은 다양한 배경 소음과 SER의 비교 결과를 보여줌
- 제안된 방법은 기존 방법을 지속적으로 능가함
- 성능은 훈련되지 않은 노이지와 SER로 잘 일반화됨
3.4. Performance in double-talk, background noise and nonlinear distortions situations
-
비선형 왜곡의 시뮬레이션 단계
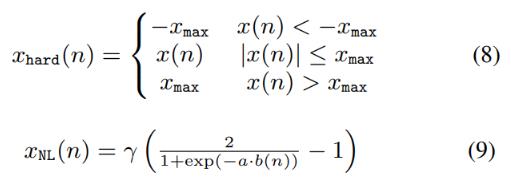
- 하드 클리핑이 각 원단 신호에 적용되어 전력 증폭기의 특성을 시뮬레이션함
- xmax는 |x(n)|의 최대 진폭으로 0.8로 설정됨
- 클리핑된 신호는 비대칭 스피커 왜곡을 시뮬레이션함
- b(n) = 1.5 × xhard(n) - 0.3 × x2hard(n)
- γ(sigmoid gain)은 4로 설정
- 시그모이드 기울기 a는 b(n) > 0이면 4로, 그렇지 않으면 0.5로 설정
- 라우드 스피커 신호인 xNL은 비선형 왜곡이 있는 에코를 생성하기 위해 RIR와 컨볼루션됨
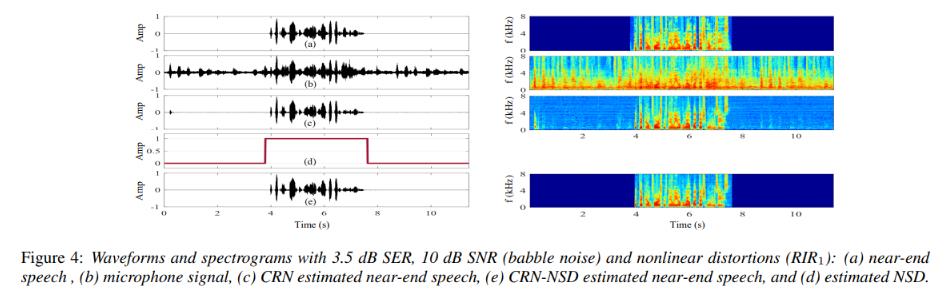
- 그림 4의 파형 및 스펙트로그램은 제안된 방법의 echo cancellation 예를 보여줌
- 'Amp'는 진폭을 나타냄
- CRN 기반 방법은 마이크 신호의 에코 및 노이즈 대부분을 제거 가능
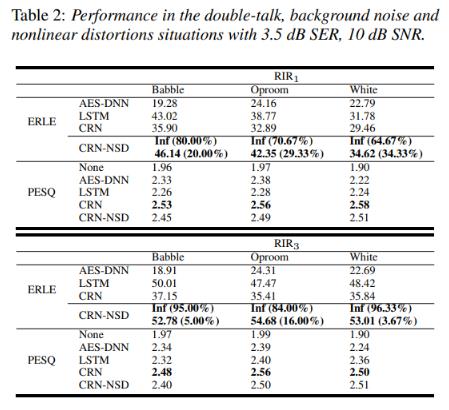
- 표 2는 제안한 방법과 DNN 기반 잔류 에코 억제 방법 및 LSTM 기반 방법과 비교한 결과를 보여줌
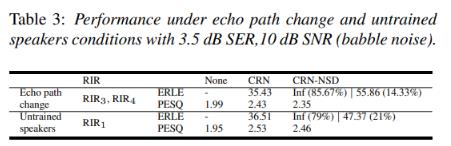
- 표 3은 에코 경로가 변경되고 테스트 스피커가 훈련되지 않은 경우 제안된 방법의 동작을 보여줌
4. Conclusion
이 논문에서는 비선형 왜곡이 있는 통합 에코 및 노이즈 캔슬링 문제를 해결하기 위한 복잡한 스펙트럼 매핑 기반 시스템을 제안하였다.제안한 방법의 성능은 NSD를 추정함으로써 더욱 향상된다.
평가에 따르면 제안된 시스템은 훈련되지 않은 노이즈에 대한 에코 및 노이즈를 제거하는 데 효과적이며 이전 기술들을 크게 능가한다.

정보통신공학과 / 웹 개발