[오늘의 키워드]
프로젝트를 진행해오면서, 딕셔너리와 관련해 겪어오던 문제가 하나 있었다.
#1 Dictionary Key와 GetHashCode() TIL
#2 Chunk 생성 트러블 슈팅 TIL
#3 WorldMapData 딕셔너리 구조 변경 TIL
세 TIL의 트러블 슈팅의 공통점은, 딕셔너리 검색 시 병목이 발생한다는 것이다. 왜 병목이 발생했고, 어떻게 해결됐는지 정리해보기로 했다.
[문제 상황]
#1 Dictionary Key와 GetHashCode() TIL
이 TIL 작성 당시 문제는, ChunkCoord 구조체의 GetHashCode() 메서드를 항상 0을 반환하게 해서 발생했다.
작성해둔 내용을 보면, (딕셔너리의 Count * 접근 횟수 * @) 만큼 GC가 발생하고 있다고 한다.
#2 Chunk 생성 트러블 슈팅 TIL
[트러블 슈팅]
Chunk
기존 로직의 문제점
월드를 생성하면, 월드는 청크들을 미리 생성한 후 비활성화 해둔다.
기존 청크의 생성 로직에는 큰 문제점이 있었다.
현재 청크의 범위 내에 들어오는 모든 좌표에 블럭이 있는지 검사한다.
청크의 범위 안에는 대략 8120개의 블럭이 들어갈 수 있다.
검사 시, World의 모든 블럭이 들어있는 Dictionary를 이용한다.
이 Dictionary에는 약 60만개의 블럭 데이터가 들어있다.
1번과 2번의 환상의 궁합으로 엄청난 오버헤드를 일으키고 있었다.아무리 검색 속도가 O(1)인 딕셔너리라도 데이터가 60만개 들어있는 딕셔너리를 대략 8천번씩 TryGetValue를 호출하니깐 너무너무 느렸다.
이 TIL에서는 아무리 검색 속도가 O(1)인 딕셔너리라도 데이터가 60만개 들어있어서 접근속도가 느렸다 라고 언급하고 있다.
#3 WorldMapData 딕셔너리 구조 변경 TIL
[World 클래스와 Chunk 클래스의 맵 데이터 딕셔너리 구조 변경]
기존 구조
World 클래스에서 모든 블럭의 데이터를 딕셔너리로 관리
하나의 딕셔너리에 대략 70만개의 블럭 데이터가 있게 됨
-> 아무리 딕셔너리라도 검색 시 약간의 병목이 발생했다.하지만 청크에서 블럭을 생성할 때, 메시와 맞닿아있는 블럭이 있는지 검사하는데 블럭은 정육면체니까 6번 검사를 함.
-> 70만개의 블럭이 6번 검사하니까 420만번 검색을 해야하는데, 약간의 병목이라도 420만번 발생하는 중
이 TIL 역시 딕셔너리의 크기가 70만개 들어 있어서 검색 시 병목이 발생했다고 언급하고 있다.
[문제 원인]
그렇다면, 검색 시간복잡도가 O(1)인 딕셔너리는 왜 크기가 커질 수록 검색 속도가 느려질까?
이에 대한 힌트는 #1에서 찾을 수 있었다.
HashSet,Dictionary등등 해시를 이용하는 제네릭 컬렉션에서는 객체를 비교할 때GetHashCode()를 이용하여 비교한 후, 같은 해시를 가졌다면Equals()까지 체크한다.
해시 충돌 (Hash Collision)
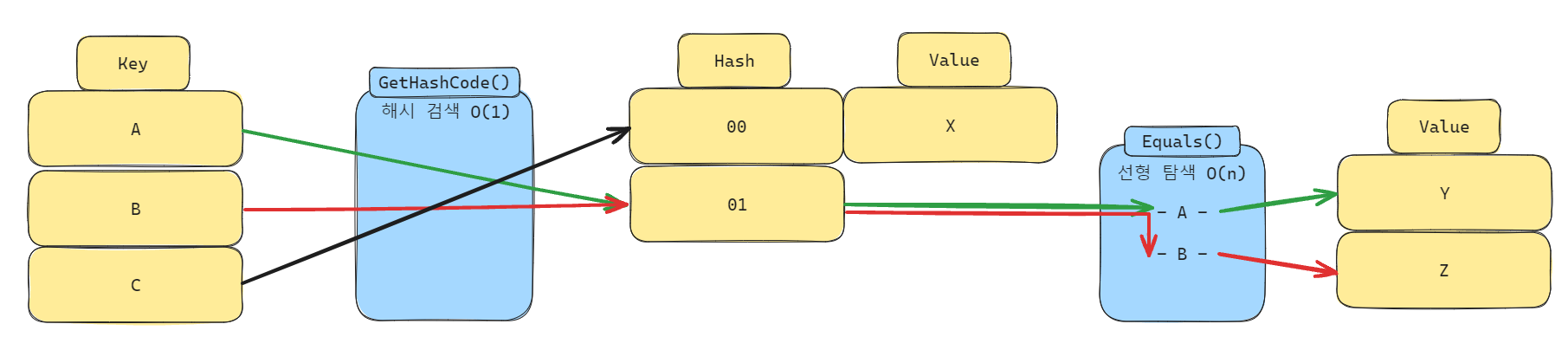
해시를 이용한 검색 시, 같은 해시를 가진 객체가 여럿일 경우가 발생할 수 있다. 이 를 해시 충돌이라고 하고, C#의 딕셔너리는 이런 경우 같은 해시를 가진 모든 객체들을 추가적으로 비교하는 작업을 거쳐서 검색을 진행한다.
때문에 해시 충돌이 많아질 수록 검색 속도는 O(n)에 가까워지게 된다.
서로 다른 객체가 같은 해시값을 가질 수 있는 이유는 해싱함수 때문이다.
C#에서는 int32형으로 해시값을 사용하는데, 잘 만들어진 해싱함수라면 충돌이 발생하지 않게 해시를 반환해줄 수도 있겠지만 아쉽게도 일반적인 상황에서 해시의 충돌은 불가피하다.
6 ~ 70만개의 Vector3Int값을 key로 저장하다보니 해시 충돌이 많이 일어나서 검색 속도가 느려진 것이었다 !!
[해결 방안]
1. 딕셔너리 접근 횟수 줄이기
처음에는 딕셔너리 검색 속도가 느리기 때문에, 딕셔너리에 접근하는 횟수를 줄이려고 했다.
그러다보니 #2에서는 청크가 자신이 생성할 블럭의 리스트를 초기화 단계에서 미리 알 수 있는 구조로 변경했었다.
하지만, 청크가 메시 데이터를 생성할 때 메시와 맞닿아 있는 면에 다른 블럭이 있는지 검사하는 메서드에서 또 딕셔너리 검색이 블럭마다 6회 실행되고 있었다.
따라서 이 방법은 근본적인 해결책이 될 수 없다고 판단했다.
근본적인 해결책이 되려면,
- 충돌이 발생하지 않는
Vector3Int의 해싱함수를 만들어내거나 - 충돌이 발생하지 않을 정도로 딕셔너리를 잘게 쪼개는 것이다.
2. 딕셔너리 구조 변경
World 밑에는 Chunk가 있고 Chunk는 블럭들의 덩어리이다.
하지만 World에서 맵의 모든 블럭 데이터를 관리하는 딕셔너리를 가지고 있다보니 60만개 이상의 블럭 데이터가 하나의 딕셔너리에 들어가게 돼있었다.
World는 Chunk에 접근할 수 있고, Chunk는 1번 해결방안을 적용하면서 자신의 범위 내의 WorldMapData에 접근할 수 있게 됐다.
따라서, World -> ChunkMap -> Chunk -> LocalMap -> WorldMapData를 순차적으로 접근하는 구조로 변경했다.
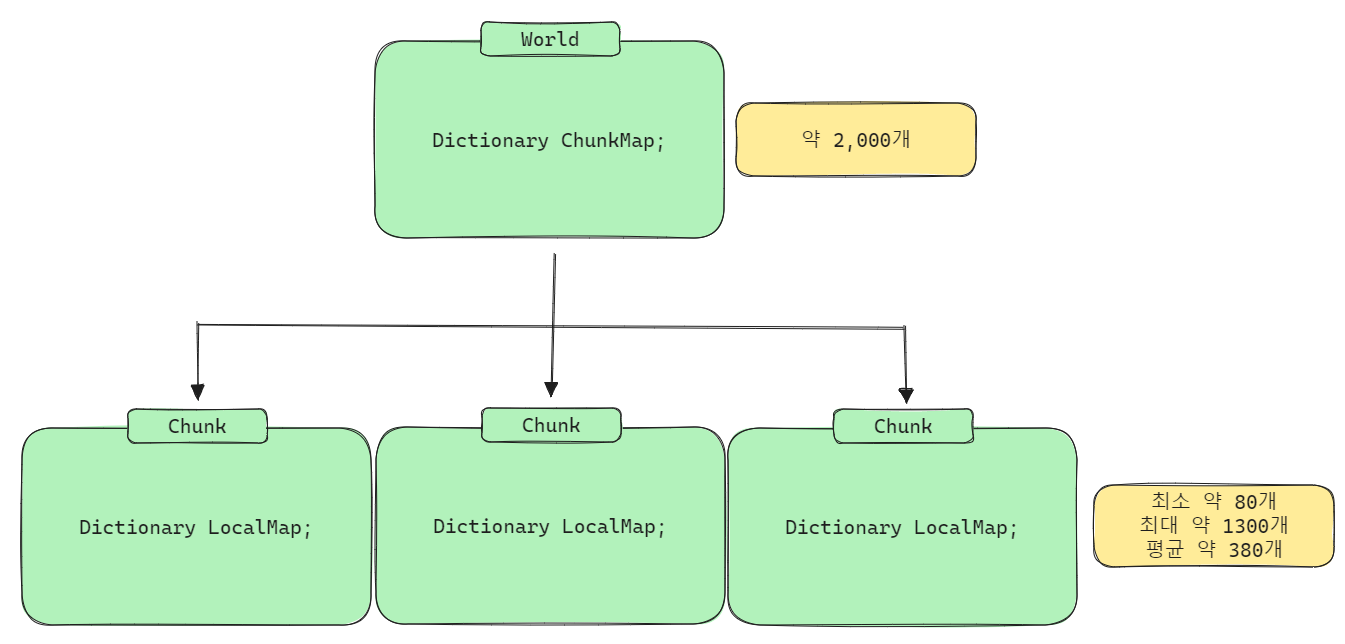
이렇게 구조를 변경함으로써 World의 ChunkMap 딕셔너리는 크기가 대략 2000개,
Chunk의 LocalMap 딕셔너리는 크기가 평균 약 380개가 됐다.
[결과]
데이터를 여러 딕셔너리에 분산해서 저장함으로써 해시 충돌 확률이 감소했고, 충돌이 발생하더라도 추가적인 비교 작업의 볼륨이 크지 않아서 검색 속도가 비약적으로 상승했다.
