Hashing (해싱)
임의의 길의의 값을 해시함수(Hash Functio 를 사용하여 고정된 크기의 값으로 변환하는 작업을 말한다.

출처: The Definitive Guide to Cryptographic Hash Functions (Part 1) (varonis.com)
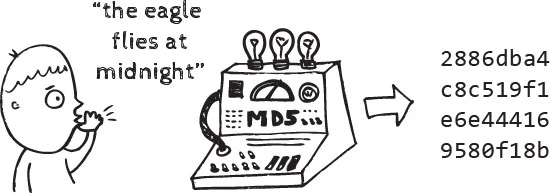
위 그림에서 dog 이란 문자열을 그대로 저장하는 것이 아니라, 해시함수를 이용해 새로운 값(32개의 이상한 문자)으로 변환하는 것을 볼 수 있다.
이 과정을 **해싱**이라고 하며, 그 결과물은 **해시** 라고 한다.일반적으로 암호 보안에서 보다 자주 사용된다.
Hash Table(해시 테이블)

출처: https://en.wikipedia.org/wiki/Hash_table
이처럼 해싱을 사용하여 변환한 값, 해시를 색인(index)으로 삼아 (Key, Value)로 데이터를 저장소(bucket, slot)에 저장하는 연관배열 자료구조를 해시 테이블 이라고 한다. 이는 기존 자료구조인 이진탐색트리나 배열에 비해서 굉장히 빠른 속도로 기본연산인 탐색(Search), 삽입(Insert), 삭제(Delete)가 가능하다.
연관배열 구조(associative array)란
키(Key) 1개와 값(Value) 1개가 1:1로 연관되어 있는 자료구조이다. 따라서 Key를 이용하여 Value를 도출할 수 있다.
연관배열 구조는 다음의 명령을 지원한다.
- Key와 Value가 주어졌을 때, 연관 배열에 그 두 값(Key & Value)를 저장하는 Insert(입력)
- Key가 주어졌을 때, 연관되는 값(Value)를 얻는 Search(탐색)
- Key와 Value가 주어졌을 때, 원래 Key에 연관된 Value를 새로운 Value로 교체하는 명령
- Key가 주어졌을 때, 해당 Key에 연관된 Value를 제거하는 Delete(삭제)
위의 명령은 해시 테이블에서도 동일하게 적용된다.

출처 : https://www.geeksforgeeks.org/implementing-hash-table-open-addressing-linear-probing-cpp/
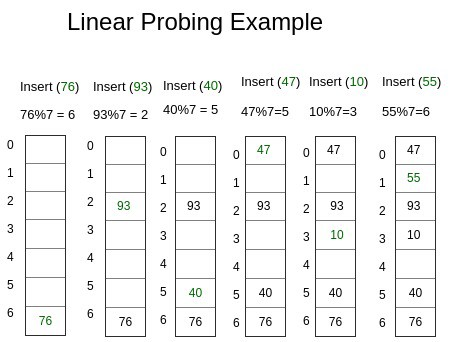
해시 테이블에서 자료를 저장하기 위해서는 해시 함수로 Key를 hash로 변경해야 한다.
위의 사진처처럼 해시 함수가 input key를 7로 나눈 나머지로 변경해서 출력했을 때, key는 ‘76’, hash는 ‘6’이다.
미리 준비해 놓은 0, 1, 2, 3, 4, 5, 6의 저장소(bucket, slot) 중에 맞는 hash값을 찾아 해당 value를 저장한다.
시간복잡도는 O(1)이다. key는 unique하며 해시 함수의 결과인 hash와 value를 저장소에 입력, 삭제, 검색 되기 때문이다. 해시함수의 시간복잡도는 고려하지 않는다.
하지만, 최악의 경우 O(N)이 될 수 있다. 해시 충돌 로 인해 모든 bucket, slot의 value들을 찾아봐야 하는 경우가 있기 때문.
이처럼 해시 테이블 개념 자체가 어렵지는 않다. 그러나 충돌(Collision)은 문제가 된다.
충돌에 대해서 이해하기 위해선 먼저 적재율(Load Factor)에 대해서 이야기 해야 한다.
적재율이란 해시 테이블의 크기 대비, 키의 개수를 말한다.
키의 개수를 K, 해시 테이블의 크기를 N 이라고 했을 때 적재율은 K/N 이다.
Direct Address Table은 키 값을 인덱스로 사용하는 구조이기 때문에 적재율이 1 이하이며 적재율이 1 초과인 해시 테이블의 경우는 반드시 충돌이 발생하게 된다.
만약 충돌이 발생하지 않다고 할 경우 해시 테이블의 탐색, 삽입, 삭제 연산은 모두 수행시간 O(1)에 가능하다. 그러나 충돌이 발생할 경우 탐색과 삭제 연산이 최악인 수행시간 O(N) 만큼 걸린다. 이는 같은 인덱스에 모든 키 값과 데이터가 저장된 경우로 충돌이 전부 발생했음을 말한다. 따라서 충돌을 최대한으로 줄여서 연산속도를 빠르게 하는 것이 해시 테이블의 핵심이다.
이에 중요하게 작용하는 것이 바로 해시함수를 구현하는 **해시 알고리즘** 이다. 해시 알고리즘이 견고하지 못하게 되면 해시함수로 도출된 값들이 같은 경우가 빈번하게 발생하게 되므로, 잦은 충돌로 이어지게 되는 것.
결론적으로 해시 테이블의 핵심은 충돌을 완화하는 것이며, 2가지 방법이 있다.
- 해시 테이블의 구조 개선
- 해시 함수 개선
해시 충돌을 완화하는 방법
1. 해시 테이블의 구조 개선
Chaining

체이닝이란 충돌이 발생했을 때 연결리스트(Linked List) 형태로 버킷에 저장하는 방법을 말한다. 위 그림에서 John Smith와 Sandra Dee가 인덱스 152에서 충돌하게 된 케이스를 볼 수 있는데, Sandra Dee를 John Smith 뒤에 연결함으로써 충돌을 처리하는 것을 볼 수 있다.
체이닝으로 구현한 해시테이블에서 시간복잡도는 다음과 같다.
삽입의 경우 연결리스트에 추가하기 때문에 O(1)
탐색과 삭제의 경우 최악의 경우 key의 개수인 K에 대해 O(K)이다.
하지만 최악의 경우보다 시간복잡도를 적재율을 이용해서 평균으로 표현하는 것이 일반적이다.
Open Addressing

Open Addressing 위에서 살펴본 동일한 충돌에 대해서 체이닝 방식을 적용하지 않고 그 다음으로 비어있는 주소인 153에 저장하는 것을 볼 수 있다. 이러한 원리로 탐색, 삽입, 사제가 다음과 같은 동작으로 이루어진다.
삽입: 계산한 Hash 에 대한 인덱스가 이미 차 있는 경우 다음 인덱스로 이동하면서 비어있는 곳에 저장한다. 비어있는 자리를 탐색하는 것을 탐사(Probing)라고 한다.
탐색: 계산한 Hash에 대한 인덱스부터 검사하며 탐사를 해나가는데 이 때 “삭제” 표시가 있는 부분은 지나간다.
삭제: 탐색을 통해 해당 값을 찾고 삭제한 뒤 “삭제” 표시를 한다.
Open Addressing의 3가지 충돌 처리기법
선형탐사(Linear Probing)
출처 : https://www.geeksforgeeks.org/implementing-hash-table-open-addressing-linear-probing-cpp/
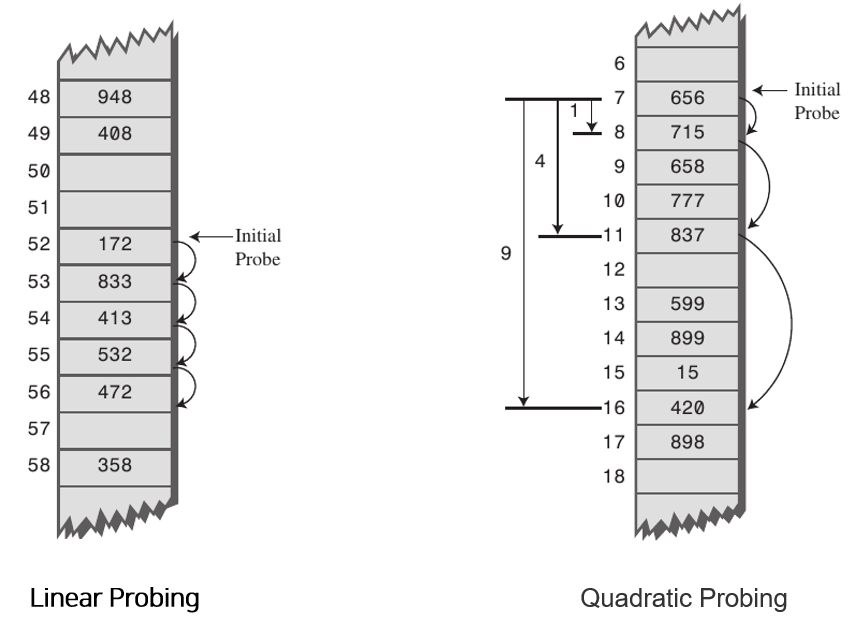
선형탐사는 가장 기본적인 충돌해결기법으로 위에서 설명한 기본적인 동작방식이다. 선형탐사는 바로 인접한 인덱스에 데이터를 삽입해가기 때문에 데이터가 밀집되는 클러스터링(Clustering) 문제가 발생하고 이로인해 탐색과 삭제가 느려지게 된다.
제곱 탐사(Quadratic Probing)
출처 : algorithm - What is primary and secondary clustering in hash? - Stack Overflow
제곱탐사는 n² 형태로 탐사를 하는 방식으로, 선형탐사에 비해 탐사 폭이 넓어 탐색과 삭제에 효율적일 수 있다. 그러나 결국 클러스터링 문제가 발생하게 된다.
이중해싱(Double Hashing)

출처 : Microsoft PowerPoint - Hashing_S05 (uml.edu)
이중해싱은 클러스터링 문제를 피하기 위해 도입되었다. 처음 해시함수는 해시값을 찾기 위해 사용하고, 두 번째 해시함수는 충돌이 발생했을 때 탐사폭을 계산하기 위해 사용한다.
2. 해시 함수 개선
나눗셈법(Division Method)
간단하게 해시값을 구하는 방법으로, 해시 테이블 크기인 N을 아는 경우에 사용할 수 있다. 해시 함수를 적용하고자 하는 값을 N으로 나눈 나머지를 해시값으로 사용하는 방법이다. 다음과 같다.
h(k) = k mod N
이 때 N은 소수(Prime Number)를 사용하는 것이 좋다.
곱셈법(Multiplication Method)
0 < A < 1인 A에 대해서 다음과 같이 구할 수 있다.
h(k) = ⌊N(kA mod 1)⌋
k A mod 1의 의미는 kA의 소수점 이하 부분을 말하며 이를 N에 곱하므로 0부터 N 사이의 값이 된다. 이 방법의 장점은 N이 어떤 값이더라도 잘 동작한다는 것이며 A를 잘 잡는 것이 중요하다.
이 외에도 다양한 해시 함수가 있다. 넘어가자.
위의 충돌을 방지하는 방법들은 클러스터링을 방지하기 위한 방법들이지만, 공간을 많이 사용한다는 치명적인 단점이 가지고 있다.
테이블이 꽉 찼을 경우 확장도 가능하지만, 매우 심각한 성능 저하를 가져온다.
때문에 가급적 테이블 설계를 초기에 잘 하는 것이 중요하다.
통계적으로 해시 테이블 공간 사용률이 70% ~ 80%가 되면 해시의 충돌이 빈번해진다고 한다.
해시 테이블에서 자주 사용하는 데이터를 Cache에 적용하면 효율을 높일 수 있다. 자주 hit하게 되는 데이터를 캐시에서 바로 찾음으로써 해시 테이블의 성능을 향상시킬 수 있다.
# Python program to demonstrate working of HashTable
hashTable = [[],] * 10
def checkPrime(n):
if n == 1 or n == 0:
return 0
for i in range(2, n//2):
if n % i == 0:
return 0
return 1
def getPrime(n):
if n % 2 == 0:
n = n + 1
while not checkPrime(n):
n += 2
return n
def hashFunction(key):
capacity = getPrime(10)
return key % capacity
def insertData(key, data):
index = hashFunction(key)
hashTable[index] = [key, data]
def removeData(key):
index = hashFunction(key)
hashTable[index] = 0
insertData(123, "apple")
insertData(432, "mango")
insertData(213, "banana")
insertData(654, "guava")
print(hashTable)
removeData(123)
print(hashTable)Reference
해시 테이블 - 위키백과, 우리 모두의 백과사전 (wikipedia.org)
[DS] 해쉬 테이블(Hash Table)이란? - 배하람의 블로그 (baeharam.netlify.app)
Hash, Hashing, Hash Table(해시, 해싱 해시테이블) 자료구조의 이해 (velog.io)
[자료구조] 해시테이블(HashTable)이란? - MangKyu's Diary (tistory.com)
