2.1 자연어 계산과 이해
임베딩에 자연어 의미를 함축하는 방법 : 자연어의 통계적 패턴 정보를 통째로 임베딩에 넣는 것
임베딩을 만들 때 쓰는 통계 정보의 세 가지 철학
- 문장에 어떤 단어가 (많이)쓰였는가 (백오브워즈 가정)
- 단어가 어떤 순서로 쓰였는가 (언어 모델)
- 어떤 단어가 같이 쓰였는가 (분포 가정)
위의 세 가지 내용은 통계적 패턴을 서로 다른 각도에서 분석하는 것이며 상호 보완적이다.
2.2 어떤 단어가 많이 쓰였는가
2.2.1 백오브워즈 가정
단어의 등장 순서에 관계없이 문서 내 단어의 등장 빈도를 임베딩으로 쓰는 기법
- 백(bag) : 중복 원소를 허용한 집합
- 문장을 단어들로 나누고 이들을 중복 집합에 넣어 임베딩으로 활용하는 것
- '저자가 생각한 주제가 문서에서의 단어 사용에 녹아있다 '는 가정이 깔려 있다.
- 정보 검색 분야에서 여전히 많이 쓰이고 있다.
2.2.2 TF-IDF
- 어떤 문서에든 쓰여서 해당 단어가 (많이) 나타났다 하더라도 문서의 주제를 가늠하기 어려운 경우가 있다.
- '을/를', '이/가' 같은 조사는 대부분의 한국어 문서에 등장하지만 이것 만으로는 해당 문서의 주제를 추측하기 어렵다.
- 이러한 단점을 보완하기 위해 제안된 기법이 Term Frequency-Inverse Document Frequency이다.
- 가중치를 계산해 행렬 원소를 바꾸는 것
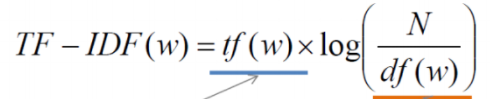

- TF : 특정 문서에서 특정 단어의 등장 횟수
- DF : 특정 단어가 등장한 문서의 수
- DF가 클수록 다수 문서에 쓰이는 범용적인 단어라고 볼 수 있다.
- TF는 같은 단어라도 문서마다 다른 값을 갖고, DF는 문서가 달라지더라도 단어가 같다면 동일한 값을 지닌다.
- IDF : 전체 문서의 수를 해당 단어의 DF로 나눈 뒤 로그를 취한 값
- 단어의 주제 예측 능력과 직결됨
- 특정 단어가 다수의 문서에서 발견될수록 IDF값이 줄어든다(중요도가 낮다) → 다수의 문서에 쓰였다면 조사와 같이 의미 없는 단어일 확률이 높다.
- N이 커질수록 그 값이 기하급수적으로 커지게 되어 로그를 취함
2.2.3 Deep Averaging Network
백오브워즈 가정의 뉴럴 네트워크 버전
2.3 단어가 어떤 순서로 쓰였는가
언어 모델 : 단어 시퀀스에 확률을 부여하는 모델
백오브워즈의 대척점으로 시퀀스 정보를 명시적으로 학습
단어가 n개 주어진 상황이라면 언어 모델은 n개 단어가 동시에 나타날 확률, 즉 P(w1, w2, ... , wn)을 반환
2.3.1 통계 기반 언어 모델
말뭉치에서 해당 단어 시퀀스가 얼마나 자주 등장하는지 빈도를 세어 학습
- n-gram : n개 단어
- 경우에 따라 n-gram에 기반한 언어 모델을 의미
- 말뭉치 내 단어들을 n개씩 묶어서 그 빈도를 학습했다는 뜻
'내 마음 속에 영원히 기억될 최고의' 라는 표현 다음에 명작이다 라는 단어가 나타날 확률을 조건부확률의 정의를 활용해 최대우도추정법으로 유도하면
- P(명작이다 | 내, 마음, 속에, 영원히, 기억될, 최고의) = Freq(내, 마음, 속에, 영원히, 기억될, 최고의, 명작이다) / Freq(내, 마음, 속에, 영원히, 기억될, 최고의)
- Freq : 해당 문자열 시퀀스가 말뭉치에서 나타난 빈도
- Freq(내, 마음, 속에, 영원히, 기억될, 최고의, 명작이다) = 0 (즉, 단어가 등장한 적이 없다.)
- 이런 경우 우변의 분자가 0이어서 전체 값이 0이됨.
바이그램 근사
- n-gram 모델을 쓰면 위의 문제를 일부 해결 가능
- 직전 n-1개 단어의 등장 확률로 전체 단어 시퀀스 등장 확률을 근사하는 것
- 이는 한 상태의 확률은 그 직전 상태에만 의존한다는 마코프 가정에 기반
- ex) P(명작이다 | 내, 마음, 속에, 영원히, 기억될, 최고의) ≒ P(명작이다 | 최고의) = Freq(최고의, 명작이다) / Freq(최고의)
바이그램 모델에서 '내 마음 속에 영원히 기억될 최고의 명작이다' 라는 단어 시퀀스가 나타날 확률은?
- P(내, 마음, 속에, 영원히, 기억될, 최고의, 명작이다)
- ≒ P(내) x P(마음|내) x P(속에|마음) x P(영원히|속에) x P(기억될|영원히) x P(최고의|기억될) x P(명작이다|최고의)
바이그램 모델 일반화
- P(Wn | Wn-1) = Freq(Wn-1, Wn) / Freq(Wn-1)
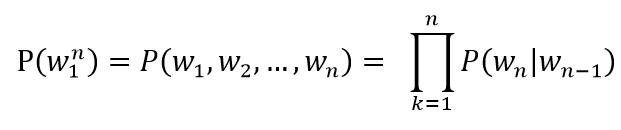
하지만 데이터에 한 번도 등장하지 않는 n-gram이 존재할 때 예측 단계에서 문제가 발생할 수 있다.
이를 위해 백오프, 스무딩 등의 방식이 제안됐다.
- 백오프 : n-gram 등장 빈도를 n보다 작은 범위의 단어 시퀀스 빈도로 근사하는 방식
- n을 크게 하면 할수록 등장하지 않는 케이스가 많아질 가능성이 높기 때문
- Freq(내 마음 속에 영원히 기억될 최고의 명작이다) ≒ αFreq(영원히 기억될 최고의 명작이다) + β
- α, β : 실제 빈도와의 차이를 보정해주는 파라미터
- 빈도가 1 이상인 n-gram에 대해서는 백오프하지 않고 해당 빈도를 그대로 n-gram 모델 학습에 사용
- 스무딩 : 등장 빈도 표에 모두 k만큼을 더하는 기법
- 빈도가 0인 케이스를 없앨 수 있다.
- Add-k 스무딩이라고 부르기도 함
- 만약 k = 1 이라면 라플라스 스무딩이라고 한다.
- 스무딩을 시행하면 높은 빈도를 가진 문자열 등장 확률을 일부 깎고 학습 데이터에 전혀 등장하지 않는 케이스들에는 작으나마 일부 확률을 부여하게 됨
2.3.2 뉴럴 네트워크 기반 언어 모델
ex) 발없는 말이 → 언어모델 → 천리
단어 시퀀스를 가지고 다음 단어를 맞추는 과정에서 학습됨
※ 마스크 언어 모델 : 언어 모델 기반 기법과 큰 틀에서 유사하지만 디테일에서 차이를 보이는 기법
- ex) 발 없는 말이 [MASK] 간다 → 언어 모델 → 천리
- 언어 모델 기반 기법은 단어를 순차적으로 입력 받아 다음 단어를 맞춰야 하기 때문에 태생적으로 일방향이다.
- But 마스크 언어 모델은 문장 전체를 다 보고 중간에 있는 단어를 예측하기 때문에 양방향 학습이 가능
- 이로 인해 마스크 언어 모델 기반의 방법들은 기존 언어 모델 기법들 대비 임베딩 품질이 좋음
2.4 어떤 단어가 같이 쓰였는가
2.4.1 분포 가정
자연어 처리에서의 분포 : 특정 범위, 즉 윈도우 내에 동시에 등장하는 이웃 단어 또는 문맥의 집합
- 개별 단어의 분포는 그 단어가 문장 내에서 주로 어느 위치에 나타나는지, 이웃한 위치에 어떤 단어가 자주 나타나는지에 따라 달라진다.
- 어떤 단어 쌍이 비슷한 문맥 환경에서 자주 등장한다면 그 의미 또한 유사할 것이라는 게 분포가정의 전제다.
- ex) 빨래, 세탁이라는 단어의 의미를 모른다고 했을 때 여러 문장들에서 빨래, 세탁은 각각 타깃 단어로 청소, 물 등은 그 주위에 등장한 문맥 단어이다.
- 빨래 : 청소, 요리, 물, 속옷과 같이 등장했다고 하자.
- 세탁 : 청소, 요리, 물, 옷과 같이 등장했다고 하자.
- 이웃한 단어들이 서로 비슷하기 때문에 빨래와 세탁은 비슷한 의미를 지닐 가능성이 높다!
- 아울러 빨래가 청소, 요리, 물, 속옷과 같이 등장하는 경향을 보았을 때 이들끼리도 직간접적으로 관계를 지닐 가능성 역시 낮지 않다.
2.4.2 분포와 의미 (1) : 형태소
형태소 : 의미를 가지는 최소 단위
- 언어 학자들이 형태소를 분석하는 방법은 조금 다르다.
- 대표적으로 계열 관계가 있다.
- 계열 관계 : 해당 형태소 자리에 다른 형태소가 '대치'돼 쓰일 수 있는가를 따지는 것
- 이는 언어 학자들이 특정 타깃 단어 주변의 문맥 정보를 바탕으로 형태소를 확인하는 것
- 즉, 말뭉치의 분포 정보와 형태소가 밀접한 관계를 이루고 있다는 것이다.
2.4.3 분포와 의미 (2) : 품사
품사 : 단어를 문법적 성질의 공통성에 따라 언어 학자들이 몇 갈래로 묶어 놓은 것
- 분류 기준 : 기능, 의미, 형식
- 예시
- 이 샘의 깊이가 얼마냐?
- 저 산의 높이가 얼마냐?
- 이 샘이 깊다.
- 저 산이 높다.
- 여기서 깊이, 높이는 문장의 주어로 싶다, 높다는 서술어로 사용됨.
- 이처럼 기능이 같은 단어 부류를 같은 품사로 묶을 수 있다.
- 품사 분류에서 가장 중요한 기준은 기능이다.
2.4.4 점별 상호 정보량(PMI)
두 확률 변수 사이의 상관성을 계량화하는 단위
- 두 확률 변수가 완전히 독립인 경우에 그 값이 0이 됨
- 독립 : A가 나타나는 것이 단어 B의 등장할 확률에 전여 영향을 주지 않고, 단어 B 등장이 단어 A에 영향을 주지 않는 경우
- 단어 A가 등장할 때 단어 B와 자주 같이 나타난다면 PMI값은 커진다
두 단어의 등장이 독립일 때 대비해 얼마나 자주 같이 등장하는지를 수치화 한 것
- PMI(A,B) = log(P(A,B) / (P(A) X P(B)))
- '개울가에서 속옷 빨래를 하는 남녀'
- 개울가, 에서, 속옷, 빨래, 를, 하는, 남녀
- 타깃 단어 : 빨래
- window = 2 라면
- 문맥 단어 : 에서, 속옷, 를, 하는
- 단어 문맥 행렬을 모두 구했다고 해보자.
- 전체 빈도 수는 1000회, 빨래 등장 횟수 20회, 속옷 등장 횟수 15회, 빨래와 속옷이 동시 등장한 횟수 10회라고 가정하면
- 빨래-속옷 간 PMI = PMI(빨래, 속옷) = log(P(빨래,속옷) / (P(빨래) X P(속옷))) = log((10 / 1000) / ((20 / 1000) X (15 / 1000)))
2.4.5 Word2Vec
분포 가정의 대표적 모델
2013 구글 연구 팀이 발표한 임베딩 기법
- CBOW 모델 : 문맥 단어들을 가지고 타깃 단어 하나를 맞추는 과정에서 학습됨
- Skip-gram 모델 : 타깃 단어를 가지고 문맥 단어가 무엇일지 예측하는 과정에서 학습됨
- 둘 모두 특정 타깃 단어 주변의 문맥, 즉 분포 정보를 임베딩에 함축
참고 서적
한국어 임베딩 - 이기창 지음

