3.1 데이터 확보
- 이미 공개돼있는 말뭉치 데이터를 활용
3.1.1 한국어 위키백과
위키백과 : 누구나 자유롭게 수정, 편집할 수 있는 인터넷 백과사전
한국어 위키백과의 원 데이터(raw data)를 다운로드 하는 방법
위키백과 XML 문서상의 문학 항목
- 우리가 필요로 하는 본문 텍스트만 뽑아낸다.
- 특수문자, 공백, 이메일주소, 웹 페이지 주소 등을 제거
3.1.2 KorQuAD
KorQuAD : 한국어 기계 독해를 위한 데이터셋
- 질문과 답변 쌍을 사람들이 직접 만들었다.
3.1.3 네이버 영화 리뷰 말뭉치
감성 분석이나 문서 분류 태스크 수행에 제격인 데이터 셋
- 레코드 하나는 문서(리뷰)에 대응
3.1.4 전처리 완료된 데이터 다운로드
3.2 지도 학습 기반 형태소 분석
문장이나 단어의 경계를 컴퓨터에 알려주지 않으면 어휘 집합에 속한 단어 수가 기하급수적으로 늘어나서 연산의 비효율이 발생
특히 한국어는 조사와 어미가 발달한 교착어이기 때문에 섬세한 처리 필요
- 가다 - 가겠다 가더라 ...
형태소 분석 기법을 사용하면 어휘 집합을 줄일 수 있다.
- 가겠다 - 가, 겠, 다
- 가더라 - 가, 더, 라
태깅 : 모델 입력과 출력 쌍을 만드는 작업
- 입력 : 아버지가방에들어가신다
- 출력 : 아버지, 가, 방, 에, 들어가, 신다
3.2.1 KoNLPy 사용법
은전한닢(Mecab), 꼬꼬마(Kkma), 한나눔(Hannanum), Okt, 코모란(Komoran) 등 5개 오픈소스 형태소 분석기를 파이썬 환경에서 사용할 수 있도록 인터페이스를 통일한 한국어 자연어 처리 패키지
- 품사 태그 내용 확인 : https://docs.google.com/spreadsheets/d/1OGAjUvalBuX-oZvZ_-9tEfYD2gQe7hTGsgUpiiBSXI8/edit
3.2.2 KoNLPy 내 분석기별 성능 차이 분석
- 로딩 시간 : 분석기가 사용하는 사전 로딩을 포함해 형태소 분석기 클래스를 읽어 들이는 시간
- 실행 시간 : 10만 문자의 문서를 분석하는 데 소요되는 시간
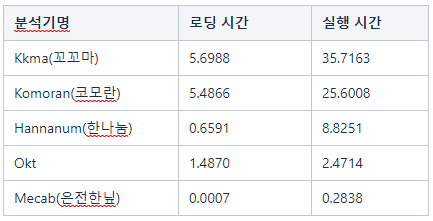
- Mecab이 다른 분석기 대비 속도가 빠른 편이다.
- 속도만큼 형태소 분석 품질도 중요하다.
- 자신이 가진 데이터로 시험 삼아 형태소 분석을 해보고 속도나 품질을 비교해서 고르는 것이 좋다.
3.2.3 Khaiii
https://tech.kakao.com/2018/12/13/khaiii/
Kakao Hangul Anlyzer Ⅲ, 카카오가 공개한 오픈소스 한국어 형태소 분석기
CNN 모델 적용
- 입력 문장을 문자 단위로 읽어 들인 뒤 컨볼루션 필터가 이 문자들을 슬라이딩해 가면서 정보를 추출
3.3 비지도 학습 기반 형태소 분석
데이터의 패턴을 모델 스스로 학습하게 함으로써 형태소를 분석하는 방법
3.3.1 soynlp 형태소 분석기
형태소 분석, 품사 판별 등을 지원하는 파이썬 기반 한국어 자연어 처리 패키지
하나의 문장 혹은 문서에서보다는 어느 정도 규모가 있으면서 동질적인 문서 집합에서 잘 작동한다.
- 데이터의 통계량을 확인해 만든 단어 점수 표로 작동
- 단어점수표 → 응집 확률, 브랜칭 엔트로피를 활용한다.
- 주어진 문자열이 유기적으로 연결돼 함께 자주 나타나고(응집 확률이 높을 때), 그 단어 앞뒤로 다양한 조사, 어미 혹은 다른 단어가 등장하는 경우(브랜칭 엔트로피가 높을 때) 해당 문자열을 형태소로 취급
# pip install soynlp
from soynlp.word import WordExtractor
import math
from soynlp.tokenizer import LTokenizer
corpus_fname = 'processed_ratings.txt'
model_fname = 'soyword.model'
# 예제 파일 문장 리스트로 저장
sentences = [sent.strip() for sent in open(corpus_fname, 'r', encoding='UTF8').readlines()]
# 객체 선언
word_extractor = WordExtractor(min_frequency=100,
min_cohesion_forward=0.05,
min_right_branching_entropy=0.0)
word_extractor.train(sentences) # 모델 학습
word_extractor.save(model_fname) # 모델 저장
scores = word_extractor.word_scores()
scores = {key:(scores[key].cohesion_forward * math.exp(scores[key].right_branching_entropy)) for key in scores.keys()}
tokenizer = LTokenizer(scores=scores)
tokens = tokenizer.tokenize("애비는 종이었다")
print(tokens)3.3.2 구글 센텐스피스
바이트 페어 인코딩(BPE) 기법 등을 지원
- BPE의 기본 원리 : 말뭉치에서 가장 많이 등장한 문자열을 병합해 문자열을 압축
- ex) aaabdaaabac
- aa → Z로 치환 : ZabdZabac
- ab→ Y로 치환 : ZYdZYac
- BPE를 활용한 토크나이즈 매커니즘의 핵심
- 원하는 어휘 집합 크기가 될 때까지 반복적으로 고빈도 문자열들을 병합해 어휘 집합에 추가
- 학습이 끝난 후 예측
- 문장 내 각 어절(띄어쓰기로 문장을 나눈 것)에 어휘 집합에 있는 서브워드가 포함돼 있을 경우 해당 서브워드를 어절에서 분리
- 어절의 나머지에서 어휘 집합에 있는 서브워드를 다시 찾고, 또 분리
- 어절 끝까지 찾았는데 어휘 집합에 없으면 미등록 단어로 취급
3.3.3 띄어쓰기 교정
- soynlp에서 띄어쓰기 교정 모듈 제공
- 말뭉치에서 띄어쓰기 패턴을 학습한 뒤 해당 패턴대로 교정을 수행
- soynlp 형태소 분석이나 BPE 방식의 토크나이즈 기법은 띄어쓰기에 따라 분석 결과가 크게 달라진다.
# pip install soyspacing
from soyspacing.countbase import CountSpace
corpus_fname = 'processed_ratings.txt'
model = CountSpace()
model.train(corpus_fname)
# model.save_model('space-correct.model', json_format=False)
# model.load_model('space-correct.model', json_format=False)
model.correct("어릴때보고 지금다시봐도 재밌어요")참고 서적
한국어 임베딩 - 이기창 지음


GitHub - https://github.com/jenu8628