
이번 글은
- RDB에 소스 데이터 업로드하여 분석에 사용할 데이터 준비하는 글입니다.
- Data Engineering에 대한 내용으로 앞선 [혼공머신] 2-1. 데이터 준비하기 글을 읽고, 공시지가 데이터 구축에 대해서는 궁금하지 않다면 다음 글을 읽으셔도 좋습니다.
- 코드 파일 첨부(github)
소스 데이터 확인하기
패키지 불러오기
import pandas as pd import zipfile
사용변수 설정
source_file_path = 'D:/data/lot_public_price/2022/APMM_NV_LAND_OPEN_2022_11_01.zip' source_file_name = 'APMM_NV_LAND_OPEN_2022_11_01.txt' source_column_list = [ col.lower() for col in ['STDMT', 'PNU', 'LAND_SEQNO', 'SGG_CD', 'LAND_LOC_CD', 'LAND_GBN', 'BOBN', 'BUBN', 'ADM_UMD_CD', 'PNILP', 'JIMOK', 'PAREA', 'SPFC1', 'SPFC2', 'LAND_USE', 'GEO_HL', 'GEO_FORM', 'ROAD_SIDE'] ] source_year = '2022' table_name = 'lot_public_price'
10,000 rows 읽고 확인하기
zf = zipfile.ZipFile(source_file_path) source_dt = pd.read_csv( zf.open(source_file_name), sep = '|', # 구분자 encoding = 'CP949', # 한글 인코딩 dtype = 'string', # 명목변수의 문자형 유지 nrows = 10_000 # read 10,000 rows ) source_dt.head()

17, 18번째 컬럼의 컬럼명과 데이터에서 칸 밀림이 확인됨
pd.read_csv( zf.open(source_file_name), sep = '|', encoding = 'CP949', dtype = 'string', nrows = 1, # only header row header = None ).to_numpy()

header인 1번째 row를 skip한 뒤, 직접 column name 설정해서 해결
source_dt = pd.read_csv( zf.open(source_file_name), sep = '|', header = None, skiprows = 1, encoding = 'CP949', dtype = 'string', nrows = 100_000 ) source_dt.columns = source_column_list source_dt.head()

컬럼과 데이터가 올바르게 읽어진 상태
컬럼 속성 확인
source_dt.info()
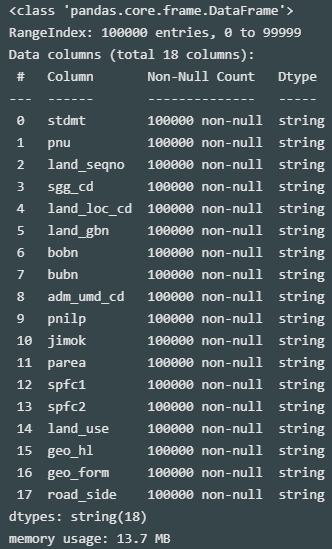
source_dt.describe()

테이블 스키마 작성(SQL)
- 테이블 정의서 토대로 작성
- 년도(year) 컬럼 추가, 업로드 일시(upload_at) 추가
- 데이터 ID인 PNU 컬럼에 Index 생성
- 지역별 데이터를 효율적으로 관리하기 위해 sub partitioning 적용
create table lot_public_price ( year varchar(4), -- 년도 stdmt varchar(2), pnu varchar(19), -- ID land_seqno numeric, sgg_cd varchar(5), land_loc_cd varchar(5), land_gbn varchar(1), bobn varchar(4), bubn varchar(4), adm_umd_cd varchar(3), pnilp numeric, jimok varchar(2), parea numeric, spfc1 varchar(2), spfc2 varchar(2), land_use varchar(3), geo_hl varchar(2), geo_form varchar(2), road_side varchar(2), upload_at timestamp default current_timestamp -- 업로드 일시 ) partition by list (substr(pnu,1,2)); -- sub partitioning 적용 create index index_lot_public_price_on_pnu on lot_public_price (pnu); -- Index 생성 create table lot_public_price_00 partition of lot_public_price default; create table lot_public_price_11 partition of lot_public_price for values in ('11'); -- 서울 create table lot_public_price_26 partition of lot_public_price for values in ('26'); -- 부산 create table lot_public_price_27 partition of lot_public_price for values in ('27'); -- 대구 create table lot_public_price_28 partition of lot_public_price for values in ('28'); -- 인천 create table lot_public_price_29 partition of lot_public_price for values in ('29'); -- 광주 create table lot_public_price_30 partition of lot_public_price for values in ('30'); -- 대전 create table lot_public_price_31 partition of lot_public_price for values in ('31'); -- 울산 create table lot_public_price_36 partition of lot_public_price for values in ('36'); -- 세종 create table lot_public_price_41 partition of lot_public_price for values in ('41'); -- 경기 create table lot_public_price_42 partition of lot_public_price for values in ('42'); -- 강원 create table lot_public_price_43 partition of lot_public_price for values in ('43'); -- 충북 create table lot_public_price_44 partition of lot_public_price for values in ('44'); -- 충남 create table lot_public_price_45 partition of lot_public_price for values in ('45'); -- 전북 create table lot_public_price_46 partition of lot_public_price for values in ('46'); -- 전남 create table lot_public_price_47 partition of lot_public_price for values in ('47'); -- 경북 create table lot_public_price_48 partition of lot_public_price for values in ('48'); -- 경남 create table lot_public_price_50 partition of lot_public_price for values in ('50'); -- 제주
RDB 연결 후 테이블 생성
사용에 익숙한 PostgreSQL을 localhost로 구축 후 연결
import psycopg2 conn = psycopg2.connect( 'host = localhost port = 5432 dbname = source user = postgres password = postgres' ) conn.set_session(autocommit = True) cur = conn.cursor()
테이블 생성
cur.execute( f''' select count(*) = 0 from information_schema.tables where table_schema = 'public' and table_type = 'BASE TABLE' and table_name ~ '{table_name}'; ''' ) if cur.fetchone()[0]: cur.execute( open('sql/source-create table lot_public_price.sql', 'r').read() # 테이블 생성 sql 파일 ) cur.execute( f''' select column_name from information_schema.columns where table_schema = 'public' and column_default is null and table_name = '{table_name}' order by ordinal_position; ''' ) column_list = [ col[0] for col in cur.fetchall() ]
생성된 테이블 확인(DBeaver)
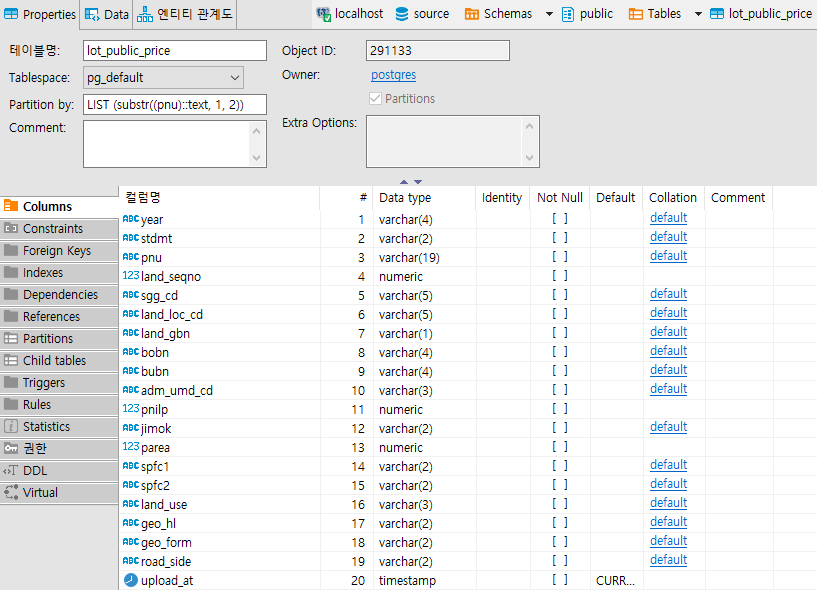
기존 데이터 제거
cur.execute( f''' delete from {table_name} where year = '{source_year}' # 업로드 해당년도만 제거 ''' )
데이터 업로드
import os from datetime import datetime zf = zipfile.ZipFile(source_file_path) source_chunks = pd.read_csv( zf.open(source_file_name), sep = '|', header = None, skiprows = 1, encoding = 'CP949', dtype = 'string', chunksize = 100_000 ) for source_dt in source_chunks: print('start :', datetime.now()) source_dt.columns = source_column_list source_dt['year'] = source_year source_dt = source_dt[['year'] + source_column_list] source_dt.to_csv( 'temp_source_dt.txt', sep = '|', index = False, header = False, encoding = 'CP949' ) file = open('temp_source_dt.txt','r') cur.copy_from( file, table_name, sep = '|', columns = column_list, null = '' ) file.close() os.remove('temp_source_dt.txt') del source_dt print('end :', datetime.now())
데이터 업로드 완료
다음 글에서 데이터 확인

가치를 만드는 데이터 분석가