이번 글은
- 지난 [혼공머신] 2-2. RDB에 데이터 업로드하기에서 DB에 업로드한 공시지가 데이터 중 학습에 적합한 항목을 추출하여 학습용 데이터를 구축합니다.
- 코드 파일 첨부(github)
데이터 읽기
DB연결 후 데이터 읽기
import psycopg2 conn = psycopg2.connect( 'host=localhost port=5432 dbname=source user=postgres password=postgres' ) conn.set_session(autocommit=True) cur = conn.cursor()
import pandas as pd cur.execute( f''' select * from lot_public_price where substr(pnu,1,2) = '11' ''' ) lpp_dt = pd.DataFrame( cur.fetchall(), columns=[ col.name for col in cur.description ] )
lpp_dt
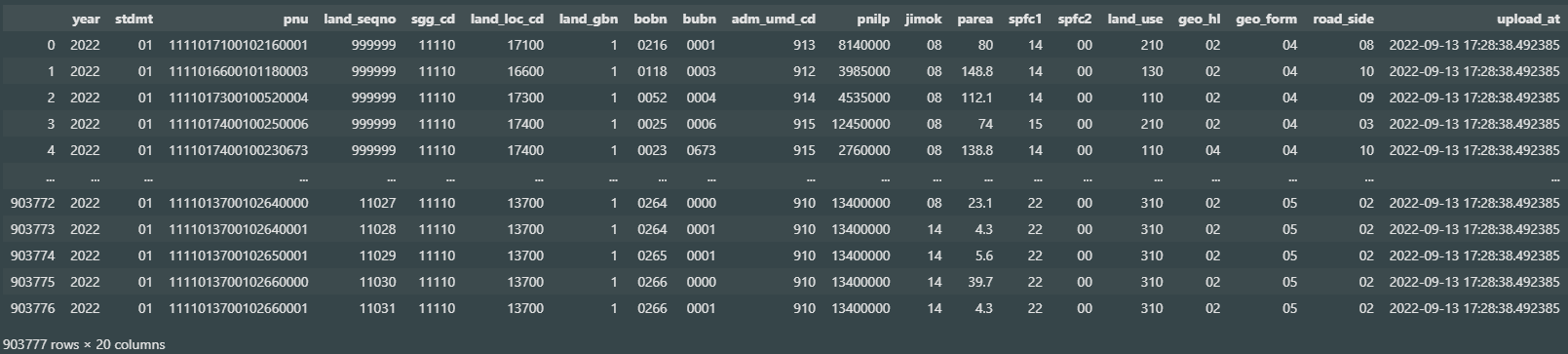
항목별 특성 확인
lpp_dt.info()
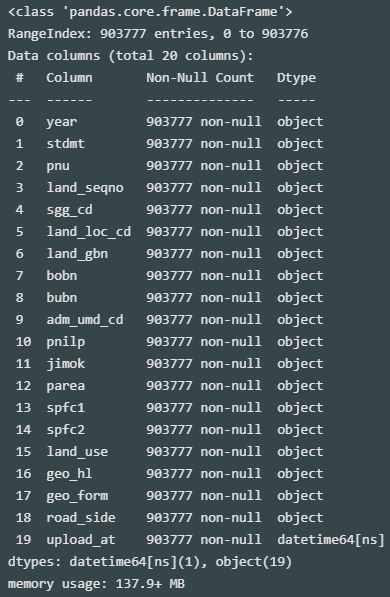
숫자형 데이터의 확인을 위해 형변환 필요
lpp_dt.land_seqno = lpp_dt.land_seqno.astype('int') lpp_dt.pnilp = lpp_dt.pnilp.astype('int') lpp_dt.parea = lpp_dt.parea.astype('float')
lpp_dt.info()
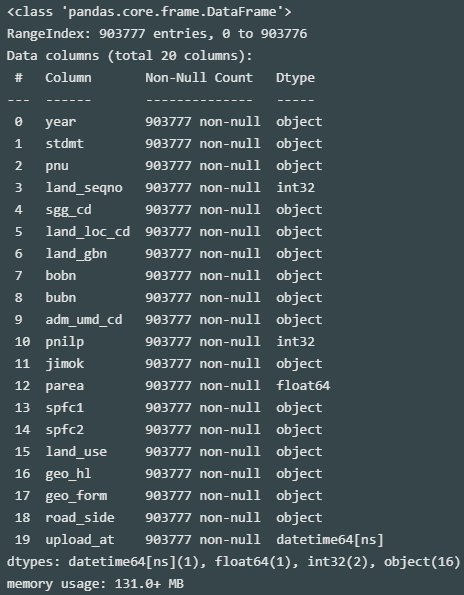
기초통계량 확인
import numpy as np lpp_dt.describe(include=np.number).transpose()

- land_seqno(토지일련번호)는 고유값이 아니며 활용성이 없는 항목
- pnilp(공시지가)는 테이블 내 종속변수의 특성이 강하며 단위가 크고 범위가 넓은 편
- parea(토지면적)는 대체로 값이 작으나 최대값이 이상치 수준으로 큼
lpp_dt.describe(include=np.object).transpose()
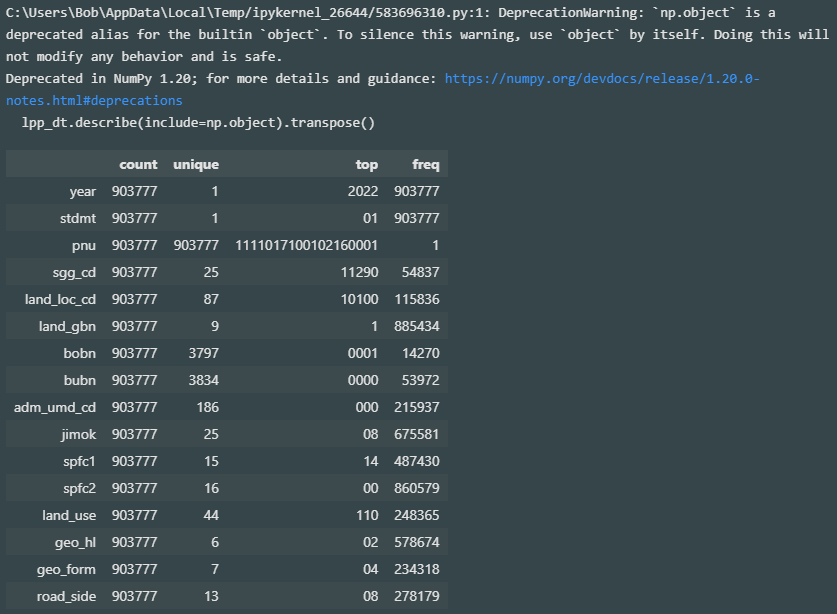
- year(년도)는 '2022' 유일값
- stdmt(기준월)는 '01' 유일값
- pnu(필지고유번호)는 'count == unique'인 primary key로 분석 내 ID로 사용
- sgg_cd(시군구코드)는 'unique:25'로 서울 자치구 25개의 코드
- land_loc_cd(토지소재지코드)는 'unique:87'로 서울 자치구 내 법정동 코드. 단 sgg_cd의 하위 분류코드로서 동일한 값이어도 다른 법정동을 의미할 수 있음
- land_gbn(토지구분), bobn(본번), bubn(부번)은 토지 주소의 부분 항목
- adm_umd_cd(행정읍면동코드)는 land_loc_cd가 나타내는 법정동이 아닌 행정동 기준의 코드
- jimok(지목)는 25개 지목 구분 코드
- spfc1(용도지역1), spfc2(용도지역2)는 용도지역 15개 구분 코드. spfc2는 공란에 해당되는 '00'이 추가되어 unique값이 1 높음
- land_use(토지이용상황)는 토지의 이용상황 44개 분류 코드
- geo_hl(지형고저)은 토지의 지형고저 6개 분류 코드
- geo_form(지형형상)은 토지의 지형형상 7개 분류 코드
- road_side(도로접면)은 토지에 접한 도로에 대한 13개 분류 코드
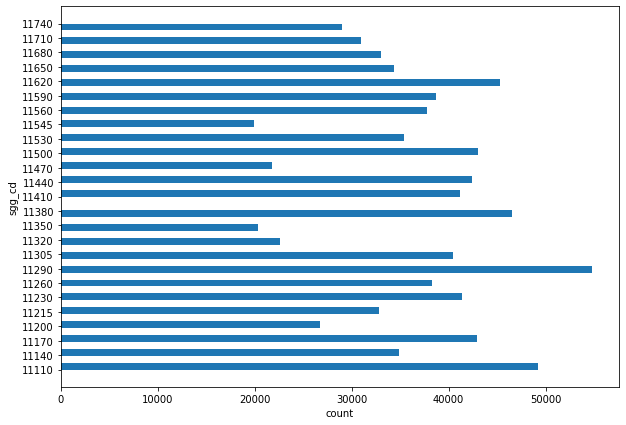
지역별 데이터 분포
import matplotlib.pyplot as plt plt.figure(figsize=(10,7)) plt.hist( lpp_dt.sgg_cd, bins=50, orientation='horizontal' ) plt.xlabel('count') plt.ylabel('sgg_cd') plt.show()
print(lpp_dt.sgg_cd.value_counts().mean()) print(lpp_dt.sgg_cd[(lpp_dt.sgg_cd=='11680') | (lpp_dt.sgg_cd=='11305')].value_counts()) print(lpp_dt.land_loc_cd[((lpp_dt.sgg_cd=='11680') & (lpp_dt.land_loc_cd=='10800')) | ((lpp_dt.sgg_cd=='11305') & (lpp_dt.land_loc_cd=='10300'))].value_counts())
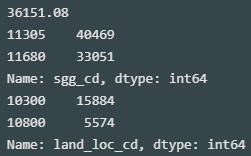
- 전체 데이터 개수 : 903,777
- 구별 데이터 개수 평균 : 36,151
- 강남구 데이터 개수 : 33,051
- 강남구 논현동 데이터 개수 : 5,574
- 강북구 데이터 개수 : 40,469
- 강북구 수유동 데이터 개수 : 15,884
※ 지역코드표에서 강남구 논현동과 강북구 수유동은 각 '1168010800', '1130510300'
- 강북구 수유동 데이터 개수 : 15,884
활용할 항목 및 데이터 고민
- 약 90만개로 모두 다 사용할 필요는 없음(책 예시는 49개)
- 구별 평균 3만개가 넘으므로 구 내에 동 단위로 분류하여 사용
- 공시지가 차이를 활용하기 위해 격차가 큰 강남구와 강북구 선정
- 토지의 지역적 분류 모델을 만들고자 sgg_cd를 종속변수로 사용
- 지역적 차이가 예상되는 강남구 논현동과 강북구 수유동 선정
- pnilp와 parea는 숫자형 데이터이므로 분류 예제를 구현해볼 수 있음
- 데이터 단순화를 위해 jimok, spfc1 두 항목은 필터를 거쳐 사용함
- jimok == '08' # '대지'
- spfc1 == '14' # '제2종일반주거지역'
- 모두 동일시점 '2022년 1월' 기준으로 시계열 데이터는 아님
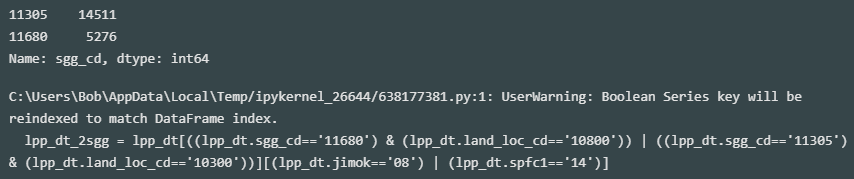
lpp_dt_2sgg = lpp_dt[((lpp_dt.sgg_cd=='11680') & (lpp_dt.land_loc_cd=='10800')) | ((lpp_dt.sgg_cd=='11305') & (lpp_dt.land_loc_cd=='10300'))][(lpp_dt.jimok=='08') | (lpp_dt.spfc1=='14')] print(lpp_dt_2sgg.sgg_cd.value_counts())
lpp_dt_2sgg['is_gangnam'] = lpp_dt_2sgg.sgg_cd == '11680' print(lpp_dt_2sgg.is_gangnam.value_counts())
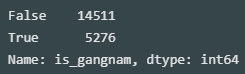
- jimok, spfc1 필터를 거쳐 강남구(논현동) 5,276개, 강북구(수유동) 14,511개 데이터 확보
- 분류에 사용할 pnilp(공시지가), parea(토지면적)
- is_gangnam 항목은 강남구인 경우 True, 강북구인 경우 False (타겟데이터)
github에 데이터 올려놓기
- DB를 활용할 수도 있으나, 학습예제와 동일한 작업을 하기위해 csv 데이터로 github에 올려놓음
def to_csv_from_dt_column(pd_col, save_file_name): f = open(save_file_name, 'w') f.write( ','.join(pd_col.to_list()) ) f.close() to_csv_from_dt_column( lpp_dt_2sgg.pnilp.astype('string'), 'lpp_pnilp.csv' ) to_csv_from_dt_column( lpp_dt_2sgg.parea.astype('string'), 'lpp_parea.csv' ) to_csv_from_dt_column( lpp_dt_2sgg.is_gangnam.astype('int').astype('string'), 'lpp_is_gangnam.csv' )

가치를 만드는 데이터 분석가