본 내용은 아래 Medium 글을 정리하였습니다.
https://towardsdatascience.com/10-ways-to-improve-the-performance-of-retrieval-augmented-generation-systems-5fa2cee7cd5c
- Improving
meansincreasing the proportion of queries for which the system- Finds the proper context
- Generates and appropriate response
👏 10 Ways to Improve the Performance of Retrieval Augmented Generation
1. Clean your data
- Retrieval 대상이 되는 데이터가 conflict 하거나 redundant information 일 경우, 올바른 context 를 찾는 데 어려움을 겪음
- Query 에 대한 대답을 제대로 할 수 있도록 문서 자체를 잘 구축해놔야 함
- 모든 문서의 Summary 를 만들어서 context 로 사용하는 것이 하나의 방법
- 검색 자체는 Summary 로 하지만, 실제 정보가 필요할 때는 세부 정보를 찾는 방법
2. Explore different index types
- 임베딩 기반의 retrieval 방식은 보통은 잘 동작하지만, 항상 Best 인 것은 아님
- e-commerce 에서 상품을 찾는 것에 대한 retrieval 은 키워드 방식이 더 적합할 수 있고, 많은 시스템에서 하이브리드 방식을 취함
- 특정 상품을 찾는 것은 keyword-based, 고객 정보, 지원에 대한 일반적인 것은 임베딩 기반의 retrieval
3. Experiment with your chunking approach
- Chunk 사이즈는 매우 중요하며, 일반적으로 작은 Chunk 일 때 더 성능이 좋으나 주변 정보의 부족한 문제가 발생함
- 저자의 실험 결과로는 작은 사이즈의 Chunk 가 가장 괜찮았음
- 참고 (Pinecone): Chunking Strategies for LLM Applications
4. Play around with your base prompt
- LLamaIndex 의 기본 Prompt
Context information is below. Given the context information and not prior knowledge, answer the query.
- 이를 바탕으로 작성한 Prompt
You are a ** agent. You are designed to be as helpful as possible while providing only factual information. You should be friendly, but not overly chatty. Context information is below. Given the context information and not prior knowledge, answer the query.
5. Try meta-data filtering
- meta-data 를 활용한 filtering 이 RAG 에 도움이 됨
- 예를 들어, 최신성 정보가 중요한 경우, Retrieval 이후 최신성 정보를 반영하는 것이 도움이 될 수 있음
- email history 같은 것
- 예시 (Recency 를 활용한 filtering)
- 방법
- Retrieval 할 때 K 개를 가져옴 (K > N)
- 가져온 K 개를 날짜 순으로 정렬 (최신성 유지)
- 정렬된 것 중 N 개만 실제 사용
- 고려할 점
- K 가 어느 정도 커지면 오히려 성능이 떨어진다 (관련도가 적은 Chunk 가 올 수 있고, 이 Chunk 가 가장 최신일 수도 있기 때문)
- N 이 커지면 도움이 된다. 그러나 아주 커지면 안될 것 같고, 기본 1 보다는 2일 때 성능이 더 괜찮았다. (2개를 참고하면 아무래도 바로 위의 에러 케이스가 보완되기 때문)
- 참고 페이지: https://www.mattambrogi.com/posts/recency-for-chatbots/
- 방법
[참고] Tuning a hybrid retrieval and reranking system is an extremely complicated task - it requires training models to combine dozens different ranking signals
(including semantic similarity, keyword match, document freshness, personalization features, and more)in order to produce a final relevance score.
- Glean (https://www.glean.com/blog/how-to-build-an-ai-assistant-for-the-enterprise)
- Glean’s Personalization - Knowledge Graph
- Node
- Contents – Individual documents, messages, tickets, entities, etc.
- People – Identities and roles, teams, departments, groups, etc.
- Activity – Critical signals and user behavior, sharing and usage patterns
- Edge
- Document linkage – Documents that are linked from other documents, or mentioned by other users are more likely to be relevant (PageRank - the paper that started Google)
- User-User interactions – Documents from authors who are on the same team, who I have interacted with in the past, whom I have an upcoming meeting with, … are more likely to be relevant to me.
- User-Document interactions – Documents that I (or someone from my team) created/edited/shared/commented/… are all more likely to be relevant to me
6. Use query routing
- LangChain:
MultiRetrievalQAChain - 인덱싱 할 때 용도에 맞게 다양한 인덱싱을 하면 더 좋을 수 있음
- 예를 들어, 요약 질문에 맞는 인덱싱, Pointed questions 에 대한 인덱싱, 날짜에 민감한 질문에 대한 인덱싱
- 이런 것들은 하나의 모듈에서 모두 최적화 하려고 하면 Retriever 자체의 성능이 좋지 않을 수 있음
- 각 인덱싱에 대하여 description 을 자세히 작성하고, LLM 에게 상황(쿼리)에 맞는 적절한 옵션을 고르게끔 맡기는 방법
retriever_infos = [
{
"name": "state of the union",
"description": "Good for answering questions about the 2023 State of the Union address",
"retriever": sou_retriever
},
{
"name": "pg essay",
"description": "Good for answering questions about Paul Graham's essay on his career",
"retriever": pg_retriever
},
{
"name": "personal",
"description": "Good for answering questions about me",
"retriever": personal_retriever
}
]
chain = MultiRetrievalQAChain.from_retrievers(OpenAI(), retriever_infos, verbose=True)7. Look into reranking
- Similarity 와 Relevance 와는 완전히 일치하지 않는데, 이를 보완하는 것이 reranking 임
- 이와 관련해
Cohere의 reranking 을 참조하면 좋음 (commonly used for this)-
Reranking model- 영국 모델:
rerank-english-v2.0 - 다국어 모델:
rerank-multilingual-v2.0
results = co.rerank(model="rerank-english-v2.0", query=query, documents=docs, top_n=3) - 영국 모델:
-
참고: Cohere Reranking
-
8. Consider query transformations
- Rephrasing
- query 에서 관련된 내용을 retrieval 하기 어려울 때 LLM 을 사용하여 query rephrase 후 다시 시도
- 사람이 보기엔 비슷해보이는 2개의 질문이 embedding space 상에서는 비슷하지 않을 수 있기 때문
- HyDE (Hypothetical Document Embeddings)
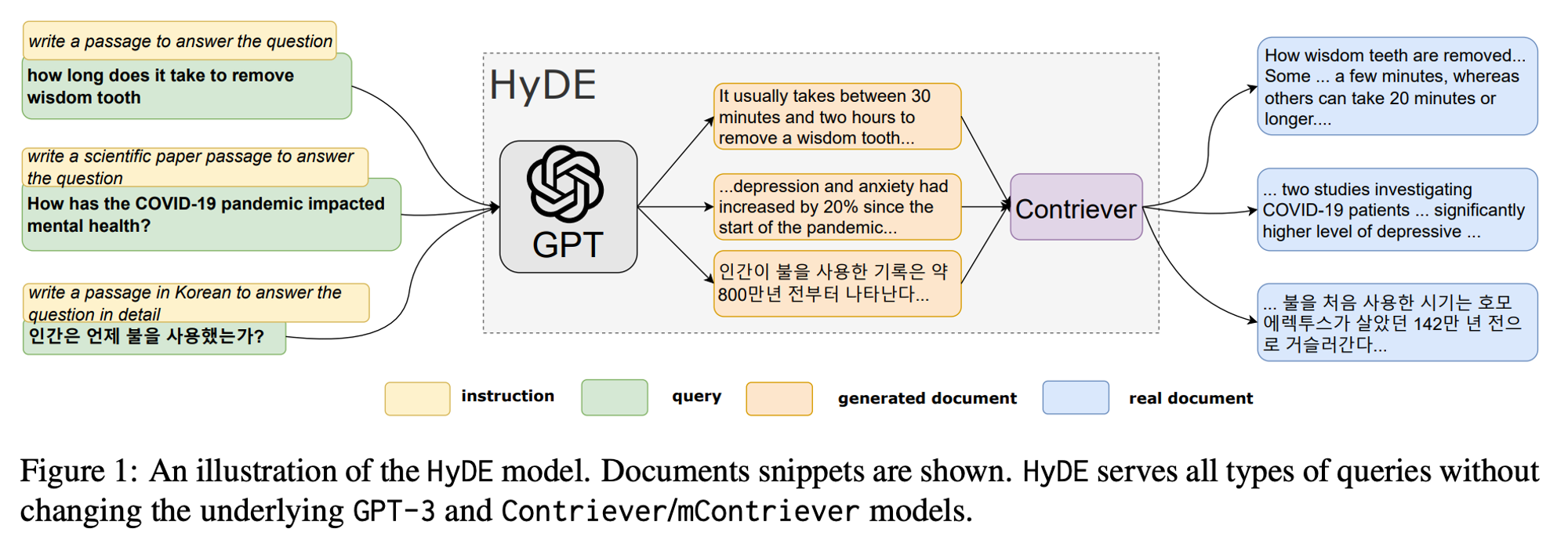
- LLM 을 통해 Query 와 Instruction 에 대한 Hypothetical Documents 생성
- Unsupervised Contrastive Learning 방식으로 학습한
Contriever-
복수 개의 Hypothetical Documents 에 대해 Contriever 로 Embeddings 을 구하여 평균 내어 한 개의 벡터로 표현
- 거짓 정보 생성에 대한 Hallucination 보완
- query 까지 포함하여 총 N + 1 개의 Documents 에 대한 평균
This second step ground the generated document to the actual corpus, with the encoder’s dense bottleneck
filtering outthe incorrect details.
-
- 새롭게 생성된 Vector Embedding 으로 Dense Retrieval 진행
- Sub-queries
- LLM System 은 복잡한 query 를 분석할 때 더 잘 동작하는 경향이 있음
- query 를 여러 개의 sub-queries 로 분해하여 RAG system 에 적용할 수 있음
9. Fine-tune your embedding model
- 일반적으로 embedding model 로 OpenAI 의
text-embedding-ada-002를 사용 - Context, Domain 에 맞지 않는 경우 fine-tuning 을 진행하여 성능을 높일 수 있음
- LLamaIndex 사용 예시
10. Start using LLM dev tools
- Arise AI: 어떤 context 때문에 retrieval 되었는 지 이유를 explore 할 수 있게 도와줌
- Rivet: 복잡한 agents 구현할 때 visual interface 제공
