MRI 뇌사진을 classification으로 질병을 판별하려고 한다.
카테고리는 MildDemented', 'ModerateDemented', 'NonDemented', 'VeryMildDemented'로 분류된다.
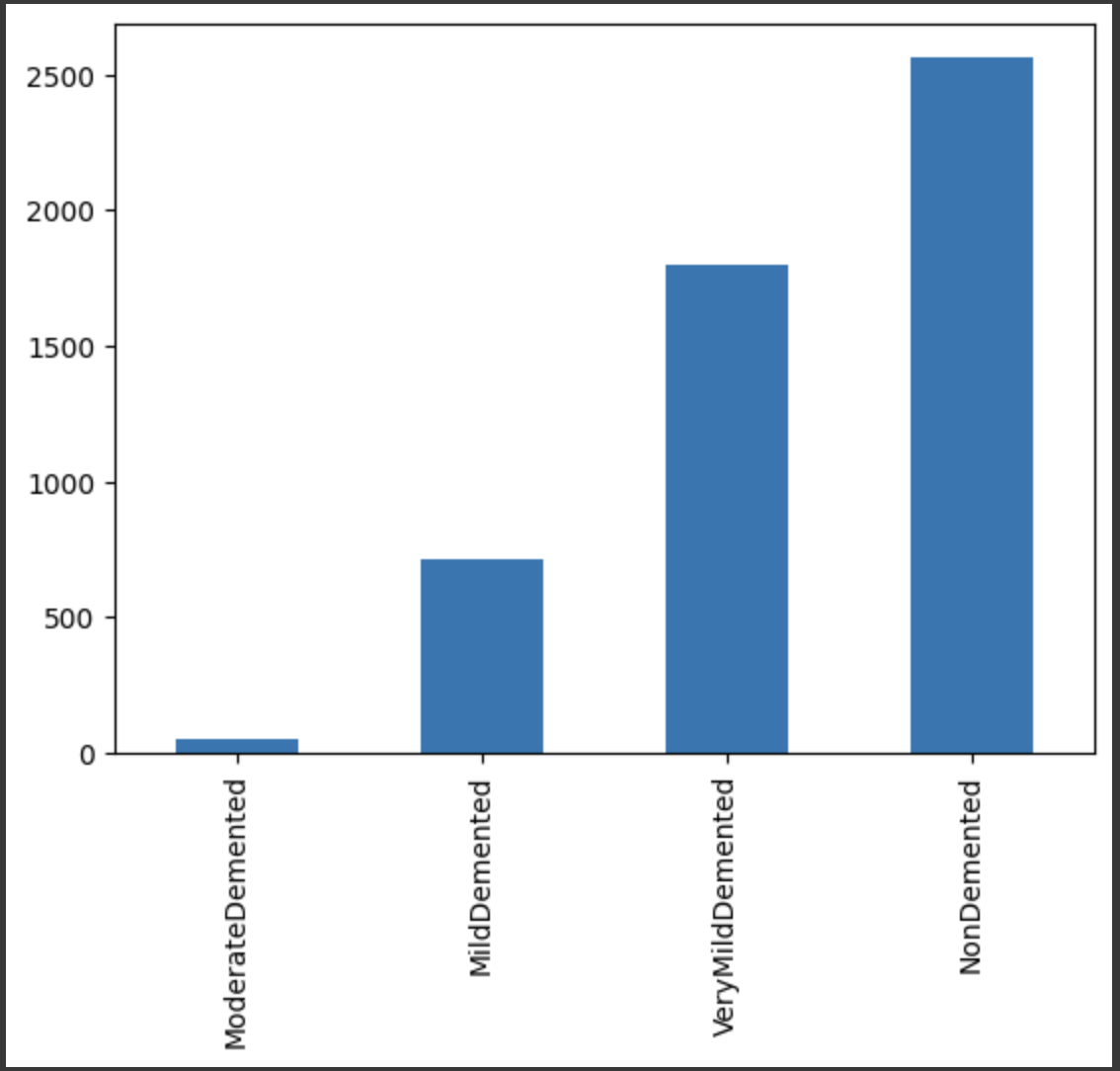
ModerateDemented 52
MildDemented 179
VeryMildDemented 448
NonDemented 650
데이터의 개수이다.
공부 할 때는 데이터의 개수는 일정할 수 있지만, 의료 데이터는 개수가 부족할 수 있다.
NonDemented은 데이터의 개수가 2563개로 가장 많다. 이러한 자료는 많지는 않지만 학습을 할 수 있는 수준이다. 하지만 가장 적은 ModerateDemented은 52개로 학습하기에는 부족한 데이터의 개수이다.
tensor을 이용하여 학습 시킨결과
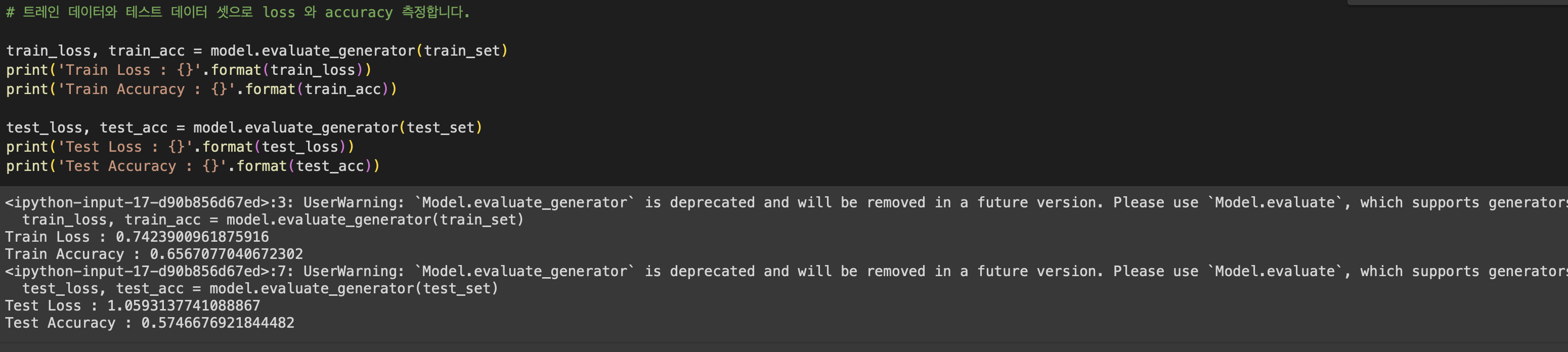
Train Loss : 0.7315366864204407
Train Accuracy : 0.666926383972168
Test Loss : 1.15609872341156
Test Accuracy : 0.567106306552887
의 결과가 나왔다.
손실률도 높고, 정확도도 낮은 상태이다.
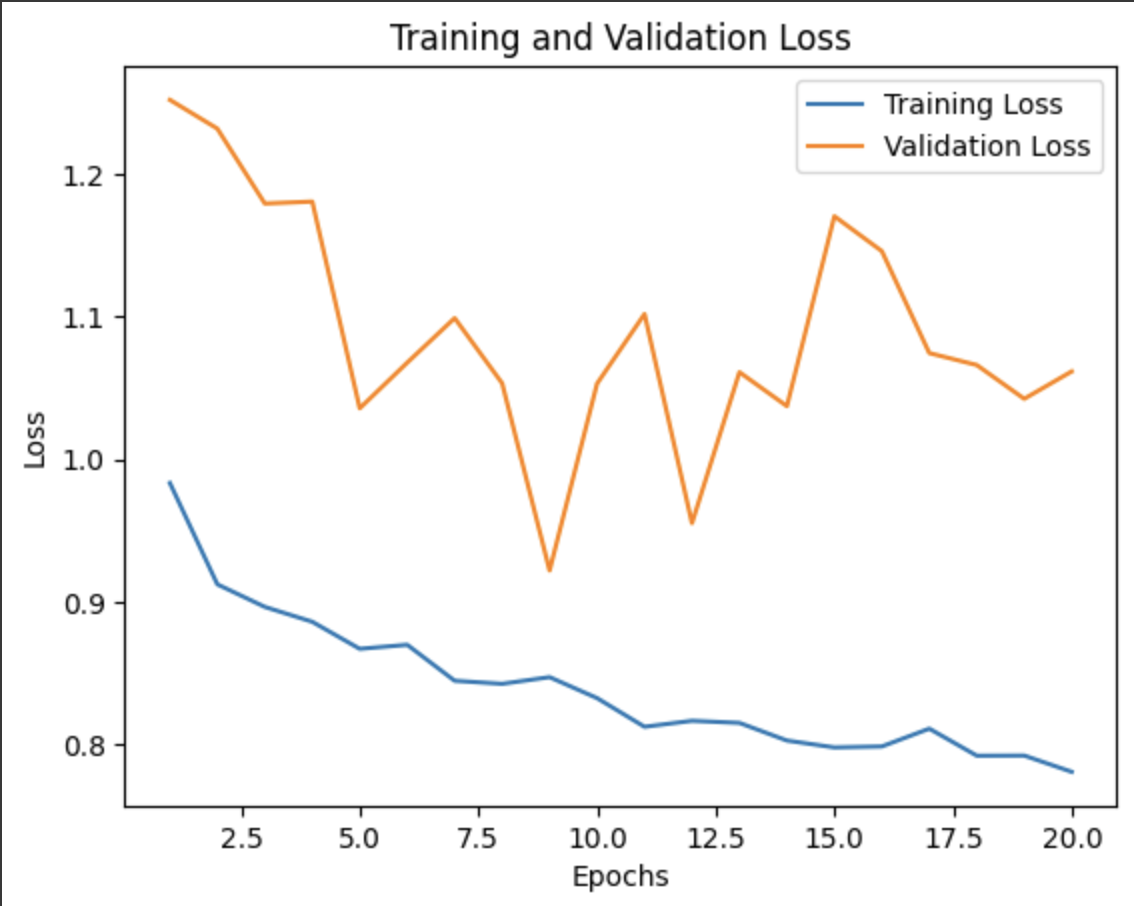
loss를 시각화 했을 때 과적합이 발생했다는 것을 볼 수 있다.
또, 학습에 사용하지 않은 임의 데이터를 사용했을 때
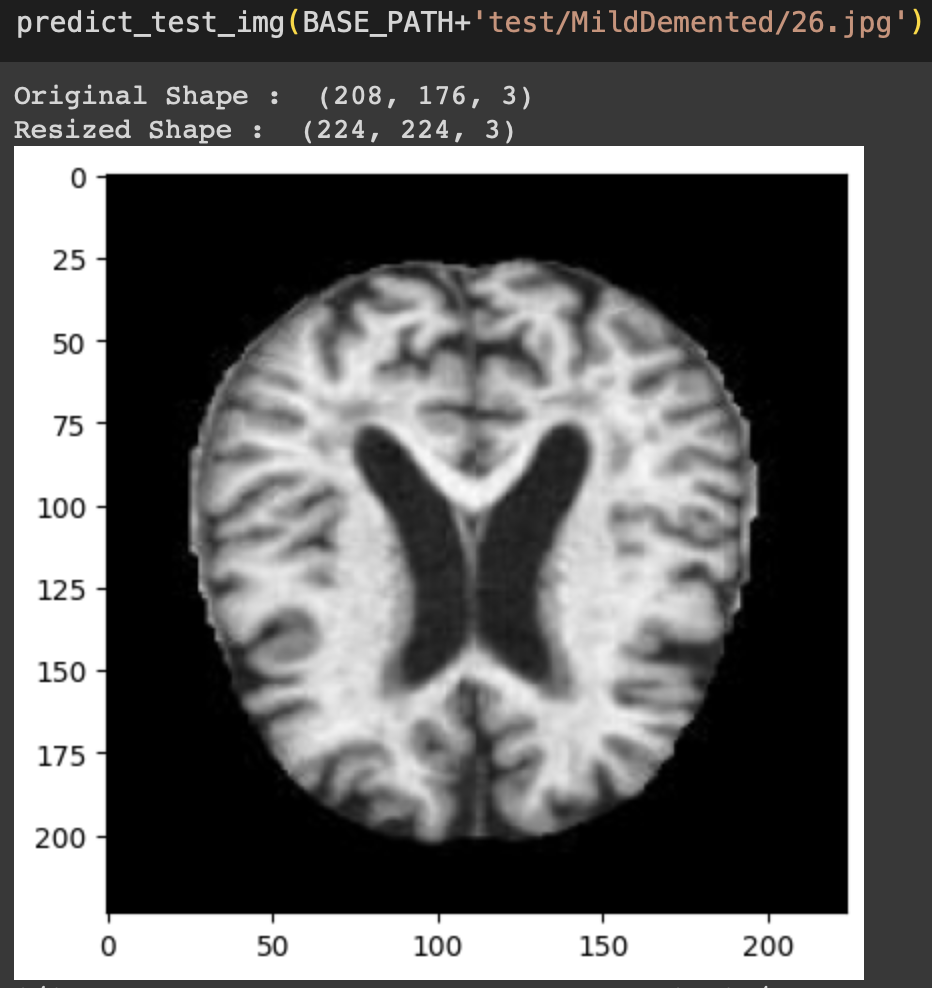
결과는 MildDemented가 나와야 하지만, VeryMildDemented가 판별된다.
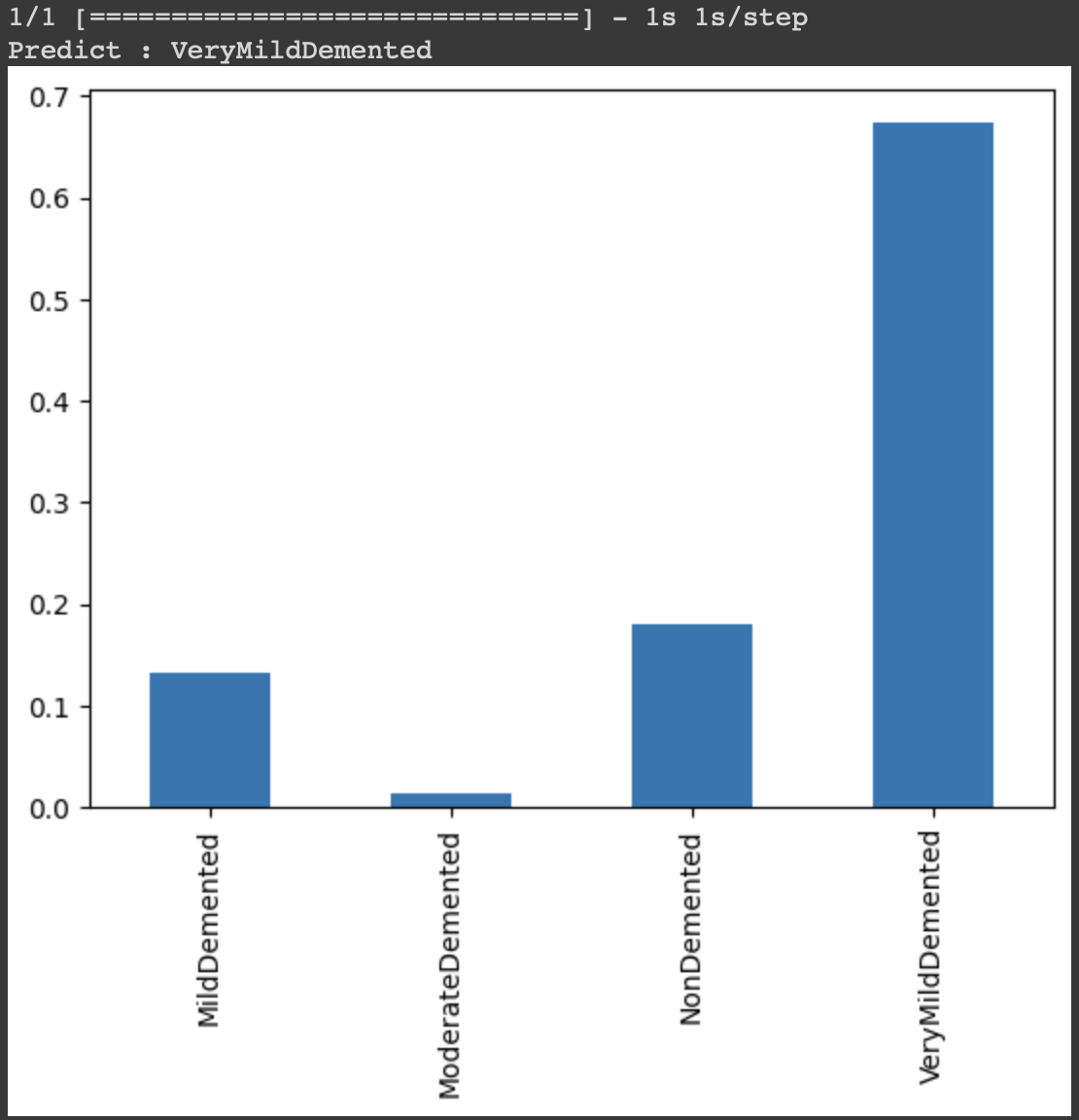
학습이 제대로 이루어 지지 않고 있다는 것을 의미한다. 이 결과는 좋지 않음을 의미하고 다양한 시도를 통해 개선을 하려고 한다.
두 가지의 문제를 발견했다.
-
첫 번째 문제 : 데이터가 선명하지 않다.
데이터의 사진 중 하나이다.
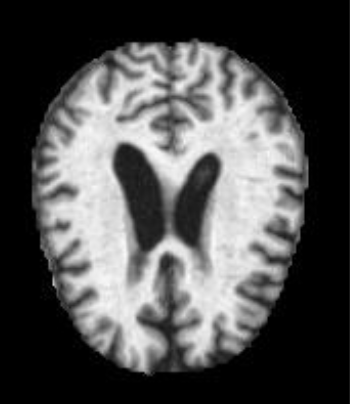
데이터가 사람이 보기에도 선명하지 않아 학습을 하는데 문제가 될 수 있고 판단했다.
알아보는 과정에서 선명한 데이터로 학습하더라도 화질이 저하된 것으로 평가하면 정확도가 떨어질 것이라는 정보를 보고 두 번째 문제를 해결하기로 했다. -
두 번째 문제 : 데이터의 개수가 적다.
ModerateDemented 52
MildDemented 179
VeryMildDemented 448
NonDemented 650
앞에 말한 것 처럼 ModerateDemented은 데이터의 개수가 52개로 학습을 하기에는 적은 데이터다. 학습하기엔 적은 데이터라서 정확도가 낮게 나오는 것으로 판단된다.
첫 번째 개선 : 데이터 증강
데이터 증강은 인위적으로 확장하여 과적합을 방지하거나, 초기 데이터가 적거나, 더 나은 성능을 만들기 위해서 사용되는 기술이다.
이미지 증강은
1. 기하학적 변환 - 이미지를 뒤집거나, 자르거나, 회전
2. 색상 공간 변환
3. 커널 필터
4. 무작위 지우기
5. 이미지 혼합
등의 기술이 있다. 여기서 1, 2번을 시도하려고 한다. 개선이 되지 않으면, 3번까지 시도해볼 생각이다.
mri 사진은 흑백 사진이기 때문에
train_datagen = ImageDataGenerator(rescale=1./255, # 픽셀 값을 0~1 범위로 변환
rotation_range=15, # 15도까지 회전
zoom_range=0.2, # 20%까지 확대
horizontal_flip = True # 20%까지 확대
)ImageDataGenerator을 사용하여 흔히 사용 되는 증강을 사용했다.
shear_range, width_shift_range, height_shift_range등 다양한 시도를 했지만, 의료데이터에 많은 노이즈를 주는 것은 좋지 않다는 판단하여 제외했다.
결과는 미세하게 변화했고 개선되지 않았다.
Train Loss : 0.7423900961875916
Train Accuracy : 0.6567077040672302Test Loss : 1.0593137741088867
Test Accuracy : 0.5746676921844482
이유는 예상하는 이유는 두가지이다.
1. 증강을 하면 epoch를 증가시켜야 하지만, 코랩 환경에서 학습을 하기 때문에 제한이 있기 때문에 증강하고 epoch를 증가시키지 않은 것
2. 의료 데이터의 증강의 문제
모델 변경(대회 당일)
대회에서는 뇌 데이터가 아닌, 관절, 폐렴유무로 총 4가지 카테고리로 분류해야했다.
위 문제를 해결하기 위해서는 모델과 방법을 새로 만들어야 한다고 생각이 판단되어 vgg-16모델을 사용해 보았고, DCNN을 사용해 보았다.
DCNN은 증강을 시키지 않았을 때
Train loss : 0.06662779301404953
Train Accuracy: 0.9765625Test Loss: 1.2026269435882568
Test Accuracy: 0.62890625
test의 loss도 높지만, 데이터 개선이 되었다.
폐렴은 잘 구별하지만, 관절염은 구별하지 못 하는 것이었다. ( DCNN모델에서 나온 결과 아님 )
-
데이터를 증강하여 시도해 보았지만, Train에서 epoch 13/20일 때 Accuracy가 50%미만이 나오는 것을 보고 사전에 학습을 중단시켰다.
-
이번에는 데이터의 양을 늘려 보았다. 정상 데이터는 1:1비율이었지만, 관절염 1809장, 폐렴데이터는 3419장으로 약 2배차이가 났기 때문에 관절염 데이터를 1800장을 추가하여 학습해 보았다. 결과는 정확도가 더 떨어졌다. 이번에는 모든 데이터를 약 2천장을 늘려보았다. 정확도는 1800장을 추가했을 때보다 정확도가 떨어졌다.
vgg-16모델 또한 마찬가지였다. 처음 가설 중 하나인 데이터를 증강시키는 것 보다 좋은 모델을 먼저 찾는 것이다라는 생각이 들었다.
vgg-16모델을 공부하기 위해 '만들면서 배우는 파이토치 딥러닝'책을 읽었고, 읽는 과정에서 파인튜닝, 전이학습을 알게 되었다.
'전이학습은 보유 중인 데이터가 적더라도 뛰어난 성능의 딥러닝을 실현하기 좋으며, 이력층에 가까운 층의 결합 파라미터도 학습된 값으로 생신하는 경우는 파인튜닝이다.'을 일게 되었고 이에 관심을 가지게 되었다. 파인튜닝은 전이학습의 한 형태로, 기존 모델의 일부 층을 조절하여 새로운 작업에 맞게 학습하는 것이다.
파인튜닝에 대해 알아보는 과정에서 ResNet-50v2 모델을 알게 되었다.
ResNet-50v2은 이미지 분류에서 많이 사용되는 비전 모델이다. ResNet 시리즈 중 하나이다.
50v2는 50개의 레이어로 구성된 깊은 신경망이다. 이 모델에 파인튜닝이 자주 활용이 된다하여 이 모델을 활용해 보려고 한다.
import tensorflow as tf
from tensorflow.keras.applications import ResNet50V2
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import Recall, Precision
# TensorFlow와 필요한 모듈을 가져옵니다.
# ResNet-50V2 모델을 불러옴
# - weights='imagenet'은 ImageNet 데이터셋에서 사전 훈련된 가중치를 사용한다는 의미
# - include_top=False는 네트워크의 최상위 완전 연결 계층을 포함하지 않고 네트워크의 특징 추출 부분만 불러옴
# - input_shape=(224, 224, 3)는 입력 이미지의 크기가 224x224 픽셀이고 RGB 컬러 채널임을 나타냄
resnet_model = ResNet50V2(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# Sequential 모델을 사용하여 새로운 모델을 생성
# - 이 모델은 ResNet-50V2 모델을 포함하고, 추가적인 층을 통해 구성
# - Flatten() 층은 3D 출력을 1D 벡터로 변환
# - Dense(256, activation='relu')는 256개의 뉴런으로 이루어진 완전 연결 은닉층을 추가
# - Dense(4, activation='softmax')는 출력층으로서 4개의 클래스에 대한 소프트맥스 활성화 함수를 사용하는 Dense 층을 추가
model = Sequential([
resnet_model,
Flatten(),
Dense(256, activation='relu'),
Dense(4, activation='softmax') # 분류할 클래스 수에 맞게 조정
])
# ResNet-50V2의 Convolutional 층들을 동결
# - 이는 이전에 학습된 가중치가 업데이트되지 않도록 설정
resnet_model.trainable = False
# - Adam optimizer와 categorical cross-entropy 손실 함수사용
# - 정확도, 재현율, 정밀도 지표를 사용하여 모델의 성능을 평가
model.compile(Adam(learning_rate=0.001), loss='categorical_crossentropy', metrics=["accuracy", Recall(), Precision()])
# 모델의 구조를 출력
model.summary()위 모델을 10 epochs로 실행한 결과
Epoch 1/10
485/485 [==============================] - 1800s 4s/step - loss: 1.1300 - accuracy: 0.8706 - recall: 0.8705 - precision: 0.8709 - val_loss: 0.4976 - val_accuracy: 0.8778 - val_recall: 0.8778 - val_precision: 0.8778
Epoch 2/10
485/485 [==============================] - 85s 175ms/step - loss: 0.1711 - accuracy: 0.9450 - recall: 0.9450 - precision: 0.9450 - val_loss: 0.4465 - val_accuracy: 0.8882 - val_recall: 0.8882 - val_precision: 0.8882
Epoch 3/10
485/485 [==============================] - 83s 172ms/step - loss: 0.1004 - accuracy: 0.9643 - recall: 0.9643 - precision: 0.9643 - val_loss: 0.4077 - val_accuracy: 0.9006 - val_recall: 0.9006 - val_precision: 0.9006
Epoch 4/10
485/485 [==============================] - 83s 171ms/step - loss: 0.0626 - accuracy: 0.9780 - recall: 0.9780 - precision: 0.9780 - val_loss: 0.3749 - val_accuracy: 0.9255 - val_recall: 0.9255 - val_precision: 0.9255
Epoch 5/10
485/485 [==============================] - 82s 169ms/step - loss: 0.0545 - accuracy: 0.9821 - recall: 0.9821 - precision: 0.9821 - val_loss: 0.3789 - val_accuracy: 0.9151 - val_recall: 0.9151 - val_precision: 0.9151
Epoch 6/10
485/485 [==============================] - 83s 172ms/step - loss: 0.0278 - accuracy: 0.9903 - recall: 0.9903 - precision: 0.9903 - val_loss: 0.4351 - val_accuracy: 0.9089 - val_recall: 0.9089 - val_precision: 0.9089
Epoch 7/10
485/485 [==============================] - 83s 171ms/step - loss: 0.0238 - accuracy: 0.9943 - recall: 0.9943 - precision: 0.9943 - val_loss: 0.4454 - val_accuracy: 0.9172 - val_recall: 0.9172 - val_precision: 0.9172
Epoch 8/10
485/485 [==============================] - 83s 172ms/step - loss: 0.0229 - accuracy: 0.9939 - recall: 0.9939 - precision: 0.9939 - val_loss: 0.5089 - val_accuracy: 0.8903 - val_recall: 0.8903 - val_precision: 0.8903
Epoch 9/10
485/485 [==============================] - 83s 172ms/step - loss: 0.0251 - accuracy: 0.9927 - recall: 0.9927 - precision: 0.9927 - val_loss: 0.4750 - val_accuracy: 0.9172 - val_recall: 0.9172 - val_precision: 0.9172
Epoch 10/10
485/485 [==============================] - 83s 171ms/step - loss: 0.0145 - accuracy: 0.9976 - recall: 0.9976 - precision: 0.9976 - val_loss: 0.4612 - val_accuracy: 0.9089 - val_recall: 0.9089 - val_precision: 0.9089
[ ]결과는 90에 가깝고 loss도 낮았다.
이 모델을 개선하기 위해서 Fine tuning을 추가적으로 수행했다.
from keras.callbacks import ModelCheckpoint
# ModelCheckpoint 콜백을 사용하여 훈련 중간에 모델의 가중치를 저장
# - filepath는 모델 가중치를 저장할 파일 경로
# - monitor는 콜백을 호출할 지표를 지정
# ('val_acc'), 훈련 정확도('acc'), 검증 재현율('val_recall'), 검증 정밀도('val_precision')
check_point_va = ModelCheckpoint(filepath='data_r/bin/resnet50v2-vaB_class4.h5', monitor='val_acc')
check_point_a = ModelCheckpoint(filepath='data_r/bin/resnet50v2-aB_class4.h5', monitor='acc')
check_point_r = ModelCheckpoint(filepath='data_r/bin/resnet50v2-aB_class4.h5', monitor='val_recall')
check_point_p = ModelCheckpoint(filepath='data_r/bin/resnet50v2-aB_class4.h5', monitor='val_precision')
# ResNet-50의 일부 층들의 동결을 해제
# - 이전에 동결했던 층들 중 일부를 미세하게 조정하여 새로운 데이터셋에 맞게 모델을 개선
resnet_model.trainable = True
# 모델을 다시 컴파일
# - Adamax 옵티마이저와 categorical_crossentropy 손실 함수를 사용
# - 학습률을 0.0001로 설정하여 Fine-tuning을 위한 새로운 학습률을 적용
model.compile(Adamax(learning_rate=0.0001), loss='categorical_crossentropy', metrics=["accuracy", Recall(), Precision()])
# Fine-tuning을 진행
# - fit_generator 함수를 사용하여 훈련 데이터 제너레이터를 활용하여 모델을 훈련
# - 검증 데이터를 사용하여 모델의 성능을 평가
# - 앞서 설정한 ModelCheckpoint 콜백 함수를 적용하여 훈련 중간에 모델의 가중치를 저장
history2 = model.fit_generator(train_gen,
epochs=5,
validation_data=valid_gen,
callbacks=[check_point_va, check_point_a, check_point_r, check_point_p]
)5 epochs를 수행했고 그 결과
Epoch 1/5
485/485 [==============================] - 149s 253ms/step - loss: 0.2786 - accuracy: 0.9027 - recall_1: 0.9019 - precision_1: 0.9030 - val_loss: 0.2732 - val_accuracy: 0.9048 - val_recall_1: 0.9027 - val_precision_1: 0.9046
Epoch 2/5
485/485 [==============================] - 129s 265ms/step - loss: 0.0863 - accuracy: 0.9691 - recall_1: 0.9685 - precision_1: 0.9693 - val_loss: 0.3793 - val_accuracy: 0.9068 - val_recall_1: 0.9068 - val_precision_1: 0.9068
Epoch 3/5
485/485 [==============================] - 125s 258ms/step - loss: 0.0431 - accuracy: 0.9861 - recall_1: 0.9861 - precision_1: 0.9861 - val_loss: 0.4123 - val_accuracy: 0.9089 - val_recall_1: 0.9089 - val_precision_1: 0.9089
Epoch 4/5
485/485 [==============================] - 116s 239ms/step - loss: 0.0412 - accuracy: 0.9857 - recall_1: 0.9857 - precision_1: 0.9857 - val_loss: 0.3526 - val_accuracy: 0.9255 - val_recall_1: 0.9255 - val_precision_1: 0.9255
Epoch 5/5
485/485 [==============================] - 120s 248ms/step - loss: 0.0293 - accuracy: 0.9905 - recall_1: 0.9905 - precision_1: 0.9906 - val_loss: 0.3071 - val_accuracy: 0.9337 - val_recall_1: 0.9337 - val_precision_1: 0.9337지금까지 볼 수 없었던 accuracy 0.99, loss 0.1이하를 볼 수 있었다.
최종 결과
Validation Loss: 0.4058515429496765
Validation Accuracy: 0.92578125Test Loss: 0.23914887011051178
Test Accuracy: 0.93359375
처음 했던 모델들에 비해 더 높은 정확도와 낮은 손실률로 만족스러웠다.
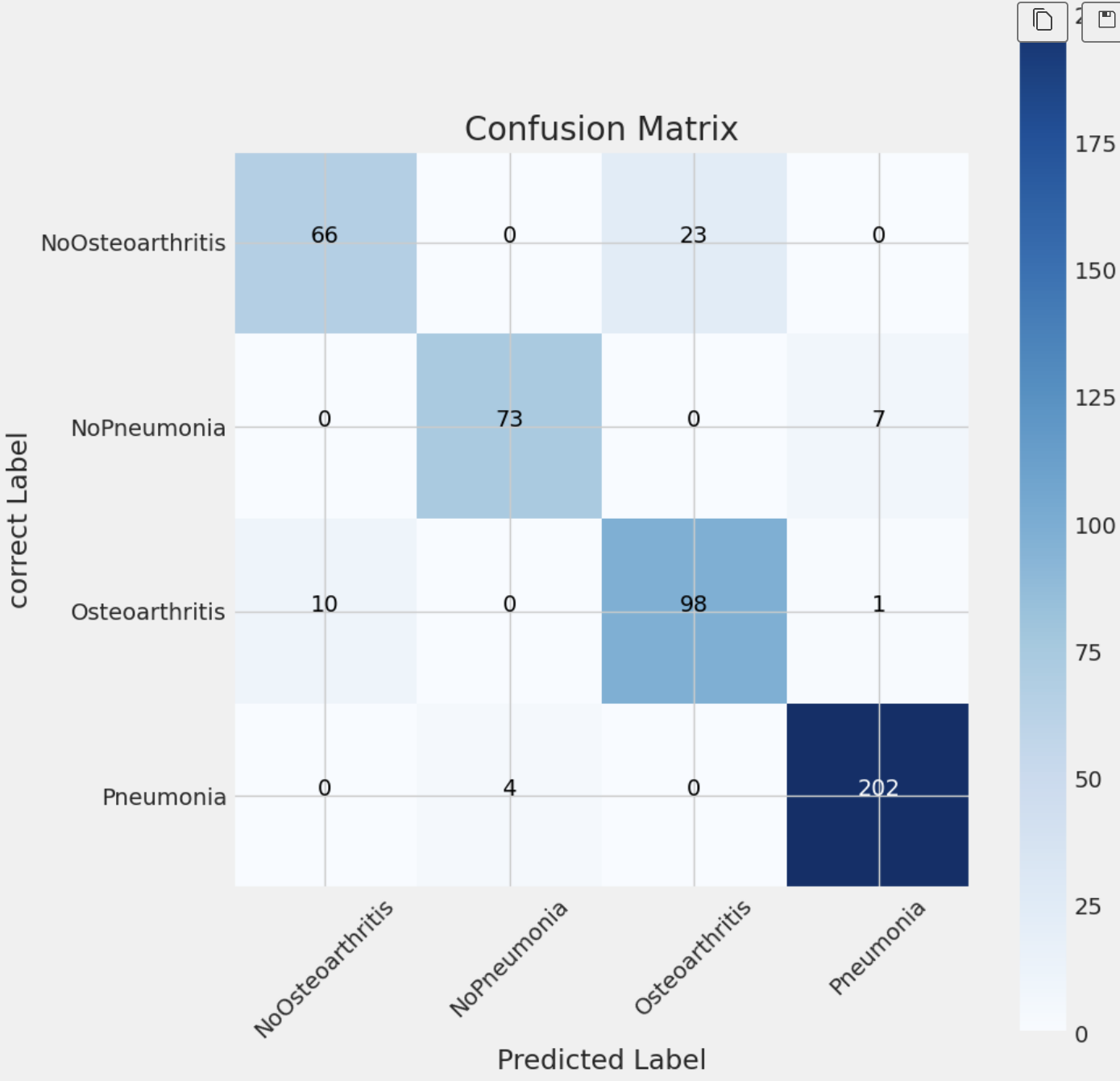
테스트 데이터에 대한 모델의 예측을 시각화 했을 때
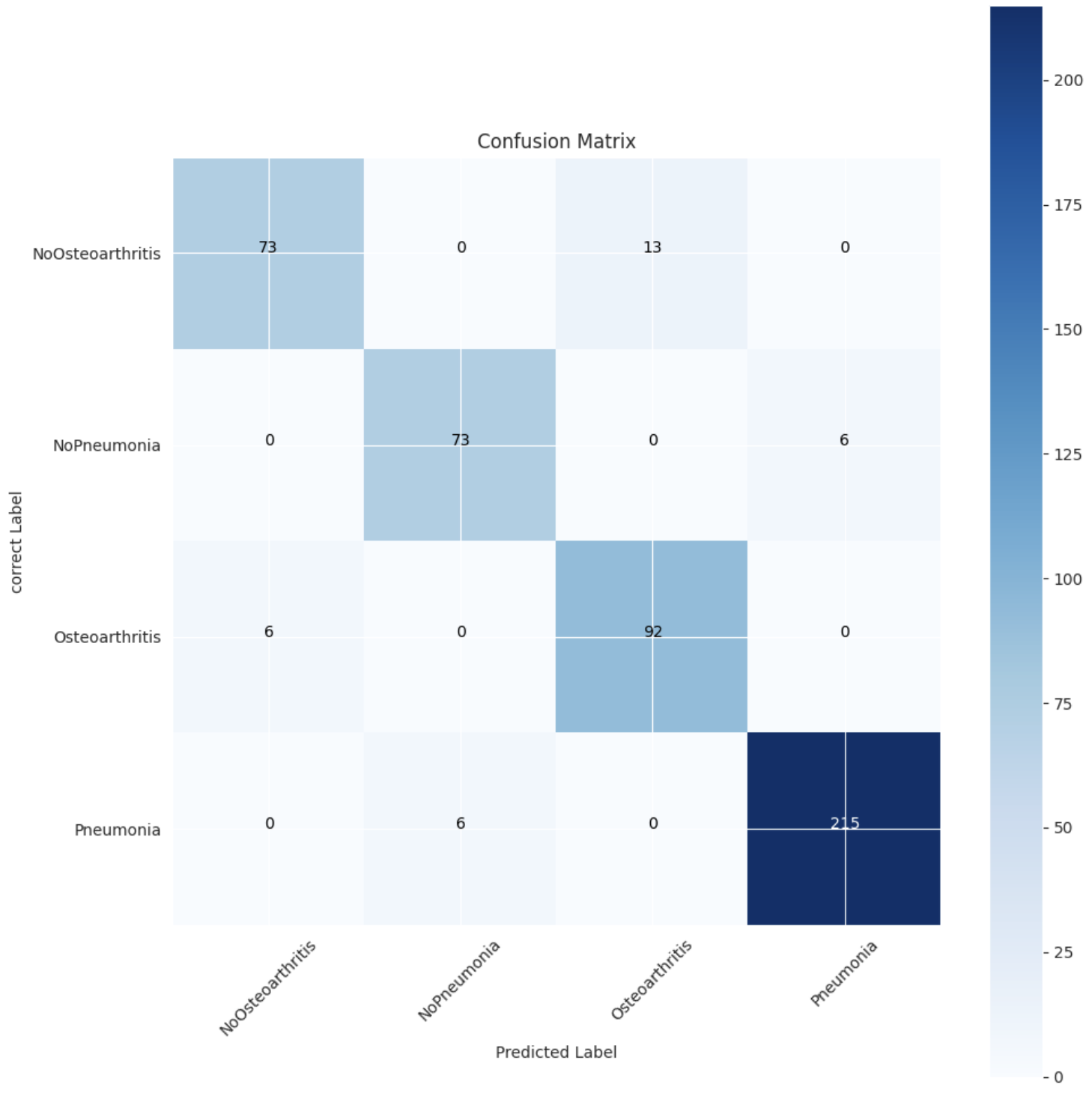
몇 개의 데이터를 제외한 대부분의 데이터를 맞춘 것으로 볼 수 있었다.
이 대회의 평가 기준은 f1-score였기 때문에 f1-score을 계산해 보았다.
precision recall f1-score support
NoOsteoarthritis 0.86 0.93 0.89 86
NoPneumonia 0.96 0.96 0.96 79
Osteoarthritis 0.93 0.87 0.90 98
Pneumonia 0.99 0.99 0.99 221
accuracy 0.95 484
macro avg 0.94 0.94 0.94 484
weighted avg 0.95 0.95 0.95 48495점의 결과가 나왔다.
점수를 개선하기 위해서 위에서 했던 데이터 증강을해 보았지만 결과는 93점 이었고, 데이터를 1:1 비율로 맞추기와 데이터의 양을 2천장씩 추가했을 때 각각 93, 94점이 나왔다.
최종으로 95점의 데이터를 제출했고 우리조는 20팀 중 1등의 결과가 나왔다.

대회에 참가하게된 이유는 배우기 위해서였다. 딥러닝에 대한 이론은 배우고 관심을 가졌지만, 모델을 활용하여 구현하는 경험이 적었기 때문이다. 대회를 참가하면서 나의 목표는 충분히 달성할 수 있었고 대상이라는 상도 받게 되었다. 대학원생들도 참여한다는 소식을 듣고 배워서 다음 기회에는 꼭 상을 받아야 겠다 생각을 했지만, 대상의 주인은 내가 되었다. 다른 사람들보다 아는 것이 없다고 생각을 했고, 3주전 부터 대회 준비를 했다. 준비는 나를 성장할 수 있게 도와주었다. 다양한 모델을 활용할 수 있었고, 전처리, 구현, 평가까지의 과정을 알 수 있었다. 이론으로 배우는 것보단 직접 구현하는 것이 배우는데 큰 도움이 되었다. 비전에 대해 공부할 때 설렘도 느끼고 재미도 느껴 재미있게 공부했던 기억이 남아있다. 인공지능은 나의 적성에 맞다고 생각이 든다. 이 대회를 나가기전 꾸준히 준비하면서 동안 궁금한 점이 생기고 해결하면서 다양한 것을 배웠다. 목표가 있으면 더 빨리 성장하는 것 같다. 꾸준한 목표를 세우며 꾸준히 성장하는 인공지능 개발자가 되고싶다.

