
선정이유
PyTorch는 Tensor를 사용하던 유저가 많이 갈아타게 된 library이다.
흔히 PyTorch가 왜 편리하고 위대한가에 대해 다루지만, 그에 관련된 자료를 찾아보지 않았다.
이번 기회에 Facebook AI 연구팀에서 개발한 PyTorch의 논문을 읽어보려고 한다.
이번에 읽을 논문의 이름은 PyTorch: An Imperative Style, High-Performance Deep Learning Library이다.
Abstract
PyTorch에는 두 가지 목표가 양립된다.
- 라이브러리의 일관성을 유지하면서 효율적이다.
- GPU와 같은 하드웨어 가속기를 지원하는 명령형 및 파이토닉 프로그래밍 스타일을 제공한다.
- 파이토닉 프로그래밍 스타일 : 파이썬 언어의 가독성, 간결성, 명확성에 중점을 둔 코딩 방법
PyTorch는 사용자가 완전히 제어할 수 있는 Python program이다.
또한, 효율성과 속도를 벤치마크로 두고 있다.
Introduction
Caffe, CNTK, TnsorFlow, Theano와 같은 인기 많은 프레임워크가 있다.이들은 정적 데이터 흐름 그래프를 구성하고 데이터 배치에 반복적으로 적용하고, 가시성을 미리 제공하고, 성능과 확장성을 개선하는데 활용할 수 있었다. 하지만, 일부 프레임워크는 성능을 희생하거나(Chainer), 표현력이 떨어지고 빠른 언어(Torch, DyNet)를 사용하므로 적용성이 제한됐었다.
PyTorch는 자동 미분과 GPU 가속을 통해 동적 텐서 연산을 즉시 실행하고, 가장 빠른 라이브러리와 비슷한 성능을 유지할 수 있었다.
Background
딥 러닝에서 중요한 네 가지 트렌드가 중요해 지고 있다. PyTorch는 아래와 같은 트렌드를 기반으로 GPU로 가속화된 배열 기반 프로그래밍 모델을 제공하고, Python ecosyste에 통합된 자동 차별화를 통해 차별화 가능한 배열 기반 프로그래밍 모델을 제공했다.
-
도메인 전용 언어가 개발되면서 다차원 배열(텐서)은 이를 조작하기 위해 포괄적인 수학적 기본 요소 세트가 지원하는 일급 객체로 바뀌었다. Numpy, Torch 등의 라이브러리는 배열 기반 프로그래밍을 생산적으로 만들었다. (일급 객체 : 다른 객체들에 일반적으로 적용 가능한 연산을 모두 지원하는 객체)
-
자동 미분의 개발로 산하는 힘든 작업을 완전히 자동화할 수 있게 되었다. 이를 통해 머신러닝 접근법을 훨씬 쉽게 실험하는 동시에 효율적인 그라데이션(기울기) 기반 최적화가 가능해졌다. 자동 미분 패키지는 Numpy 배열에 이 기법의 사용이 대중화됐다.
-
폐쇄적인 독점 소프트웨어에서 벗어나 NumPy, Pandas 같은 패키지가 포함된 오픈 소스 Python ecosystem으로 바뀌었다. 연구자는 수치 분석에 필요한 대부분의 요구 사항을 충족했고, 방대한 라이브러리 저장소를 활용하여 데이터 세트 전처리, 통계 분석, 플로팅 등을 처리할 수 있게 되었다.
-
GPU와 같은 범용 대량 병렬 하드웨어의 가용성과 사용화는 딥 러닝 방법에 필요한 컴퓨팅 성능을 제공했다. TensorFlow와 같은 프레임워크가 이러한 하드웨어 가속기를 활용할 수 있게 했다.
Usability centric design
Deep learning models are just Python programs
신경망 아키텍처를 PyTorch로 쉽게 구현할 수 있도록 보장한다. 레이어 정의, 모델 구성, 데이터 로드, 최적화 프로그램 실행, 훈련 프로세스 병렬화는 모두 범용 프로그램을 위해 개발된 친숙한 개념을 사용하여 표현했다. PyTorch로 쉽게 구현할 수 있도록 보장한다.
class LinearLayer(Module):
def __init__(self, in_sz, out_sz):
super().__init__()
t1 = torch.randn(in_sz, out_sz)
self.w = nn.Parameter(t1)
t2 = torch.randn(out_sz)
self.b = nn.Parameter(t2)
def forward(self, activations):
t = torch.mm(activations, self.w)
return t + self.b
class FullBasicModel(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(1, 128, 3)
self.fc = LinearLayer(128, 10)
def forward(self, x):
t1 = self.conv(x)
t2 = nn.functional.relu(t1)
t3 = self.fc(t1)
return nn.functional.softmax(t3)
간단하지만 완전히 신경망의 빌딩 블록(기초적인 구성 요소 또는 기본 단위)으로 사용되는 사용자 지정 레이어"모든 것은 하나의 프로그램이다"라는 철학은 모델에만 국한되지 않고 최적화 도구와 데이터 로더에도 적용된다. 이는 새로운 훈련 기법의 실험을 용이하게 한다. 생성적 적대 네트워크를 구현하려면 두 개의 개별 모델(생성기, 판별기)과 두 모델에 동시에 의존하는 두 개의 손실 함수를 지정해야 한다.PyTorch는 쉽게 적응할 수 있다.
discriminator = create_discriminator()
generator = create_generator()
optimD = optim.Adam(discriminator.parameters())
optimG = optim.Adam(generator.parameters())
def step(real_sample):
# (1) Update Discriminator
errD_real = loss(discriminator(real_sample), real_label)
errD_real.backward()
fake = generator(get_noise())
errD_fake = loss(discriminator(fake.detach(), fake_label)
errD_fake.backward()
optimD.step()
# (2) Update Generator
errG = loss(discriminator(fake), real_label) errG.backward()
optimG.step()Interoperability and extensibility
PyTorch는 외부 라이브러리와 양방향으로 데이터를 교환할 수 있다. torch.from_numpy()함수와 .numpy() 텐서 메서드를 사용하여 NumPy 배열과 PyTorch 텐서 간에 변환할 수 있는 메커니즘을 제공한다. DLPack 형식을 사용하여 저장된 데이터를 교환하는 데에도 유사한 기능을 사용할 수 있다. 이 교환은 데이터 복사 없이 이루어지며, 양쪽의 객체를 서로 공유되는 메모리 영역을 해석하는 방법만 설명한다. 이러한 작업은 실제로 매우 저렴하고, 크기와 관계없이 일정한 시간이 소유된다.
Automatic differentiation
PyTorch는 사용자가 지정한 모델의 그라데이션을 자동으로 계산할 수 있어야 하며, 이는 임의의 Python 프로그램이 될 수 있다. PyTorch 연산자 오버로딩 방식을 사용하여 계산된 함수가 실행될 때마다 그 표현을 구축한다. 또, 배열 수준의 이중 수를 사용하여 순방향 모드 미분을 수행하도록 쉽게 확할 수 있다.
PyTorch의 흔치 않은 특징은 명령형 프로그램의 기본 구성 요소 중 하나인 텐서에서 변이를 사용하는 코드를 통해 차별화할 수 있다는 것이다. 안전을 보장하기 위해 텐서용 버전 관리 시스템을 구현하여 텐서의 수정 사항을 추적하고 항상 예상 데이터를 사용할 수 있도록 한다. 트레이드오프는 임의의 프로그램을 지원하기 위해 카피 온 쓰기와 같은 기술을 활용할 수 있지만, 성능 측면에서 사용자가 코드 재작성하여 복사 작업을 수행한지 않는 것이 일반적으로 유리하기 때문에 이 방법을 사용했다.
Performance focused implementation
An efficient C++ core
PyTorch의 대부분 고성능을 달성하기 위해 C++로 작성되어있다. 이 핵심 라이브러리는 텐서 데이터 구조, GPU 및 CPU 연산자, 기본 병렬 프리미티브( 프로그래머에게 이용가능한 가장 작은 처리 processing의 단위 )를 구현한다. 대부분 내장 함수에 대한 그라데이션 공식을 포함한 자동 미분 시스템을 제공한다.
Separate control and data flow
PyTorch는 제어(branches, loops)와 데이터 흐름(tensors and the operations performed on them)을 엄격하게 분리하여 유지한다. Python과 CPU에서 실행되는 최적화된 C++ 코드에 의해 처리되며, 그 결과 기기에서 선형적인 연산자 호출 시퀀스가 생성된다. 연산자는 CPU 또흔 GPU에서 실행될 수 있다.
PyTorch는 CUDA 스트림 매커니즘을 활용하여 CUDA 커널 호출을 GPU에서 하드웨어 FIFO 큐에 대기시킴으로써 연산자를 GPU에서 비동기적으로 실행하도록 설계되었다. 이를 통해 시스템은 CPU에서 파이썬 코드의 실행과 GPU에서 텐선 연산자를 겹쳐서 실행할 수 있다.텐서 연산은 많은 시간이 걸리기 때문에, 이를 통해 파이썬과 오버헤드가 상당히 높은 해석 언어에서도 GPU의 최고 성능을 이용할 수 있다.
Custom caching tensor allocator
거의 모든 연산자는 실행 결과를 보관하기 위해 출력 텐서를 동적으로 할당해야 한다. 따라서 동적 메모리 할당자의 속도를 최적화하는 것이 중요하다. GPU에서는 모든 GPU에서 이전 큐에 대기 중인 모든 작업이 완료될 때까지 cadaFree 루틴이 호출자를 차단할 수 있다. 이러한 병목현상을 피하기 위해서 PyTorch는 사용자 정의 할당자를 구현하면서 CUDA 메모리 캐시를 점진적으로 구축한 후 CUDA API를 더 이상 사용하지 않고 나중에 할당할 때 재할당한다.
Multiprocessing
글로벌 인터프리터 잠금(GIL) 때문에 파이썬의 기본 구현에서는 동시 스레드가 병렬로 실행되는 것을 허용하지 않는다. 이 문제를 완화하기 위해서 Python 커뮤니티에서는 사용자가 쉽게 자식 프로세스를 생성하고 기본적인 프로세스 간 통신 프리미티브(기본 요소)를 구현할 수 있는 여러 유틸리티가 포함된 표준 멀티프로세싱 모듈을 구축했다.
그러나 프리미티브의 구현은 온디스크 지속성에 사용되는 것과 동일한 형태의 직렬화를 사용하므로 배열을 처리할 때 비효율적이다. PyTorch는 프로세스 격리를 약화시켜 일반 스레드 프로그램과 더 유사한 프로그래밍 모델을 구현할 수 있었다. 사용자는 독립적인 GPU에서 작동하지만 나중에 all-reduce style primitives를 사용하여 그라디언트를 동기화하는 고도로 병렬화된 프로그램을 쉽게 구현할 수 있었다.
Reference counting
훈련 중에 사용 가능한 모든 메모리를 활용하도록 모델을 설계하며, 배치 크기를 늘리는 것이 프로세스 속도를 높이는 일반적인 기법이다. 따라서 뛰어난 성능을 제공하기 위해서 PyTorch는 메모리를 신중하게 관리해야 하는 희소 자원을 취급한다.
런타임이 주기적으로 시스템 상태를 조사하여 사용된 객체를 열거하고 나머지는 모두 해제한다. 그러나 할당 해제를 지연시킴으로써 프로그램이 전체적으로 더 많은 메모리를 사용하게 되는 문제가 있었다.
PyTorch는 참조 카운팅 체계를 사용해 각 테선의 사용 횟수를 추적하고, 이 카운트가 0에 도달하면 즉시 기본 메모리를 해제하는 다른 접근 방식을 취했다. 이를 통해 텐서가 필요 없게 되는 시점에 정확히 메모리를 해제할 수 있었다.
Evaluation
Asynchronous dataflow
ResNet-50 모델의 처음 몇 가지 연상에 대한 대표적인 실행 타임라인을 보여준다. 작업을 큐에 대기시키는 CPU가 GPU의 연사자 실행을 빠르게 앞지른다. 이를 통해 PyTorch는 거의 완벽한 기기 활용도를 달성할 수 있다. 이 예제에서는 GPU 실행이 CPU 스케줄링보다 약 3배 더 오래걸린다.

ResNet-50의 처음 몇 개의 오퍼레이터의 추적. 맨 위 행은 호스트 CPU에서 실행되는 제어 흐름의 실행을 보여준다. 회색 영역은 인터프리터가 실행한 Python 코드이다. 색상이 지정된 영역은 호스트 CPU에서 다양한 연산자(컨볼루션, 배치 정규화 등)를 큐에 대기시키기 위해 수행되는 작업에 해당한다. 아래쪽 행은 GPU에서 해당 연산자의 해당 실행을 보여준다.
Memory management
NVIDIA 프로파일러를 사용하여 CUDA 런타임의 실행과 ResNet-50 모델의 한 트레이닝 반복 중에 실행된 CUDA 커널의 실행을 추적한다. 첫 번째 반복의 동작은 이후 반복의 동작과 크게 다르다. 처음에는 CUDA 메모리 관리 함수(cudaMalloc 및 cudaFree)에 대한 호출이 CPU 스레드를 장시간 차단하여 실행 속도를 크게 저하시켜 GPU의 활용도를 낮춘다. PyTorch 캐싱 메모리 할당기가 이전에 할당된 영역을 재사용하기 시작하면 이 효과는 이후 반복에서 사라진다.

Benchmarks
세 가지 인기있는 그래프 기반 딥 러닝 프레임워크(CNTK, MXNet, TensorFlow), 실행별 정의 프레임워크 및 프로덕션 지향 플랫폼과 비교하여 PyTorch의 단일 머신 에eager mode(명령을 실행하면서 즉각적으로 결과를 반환) 성능에 대한 전반적인 감각을 얻을 수 있었다.
모든 벤치마크에서 PyTorch의 성능은 가장 빠른 프레임워크의 성능의 17%이내이다. PyTorch의 성능이 매우 우수하며, 최고의 성능을 가진 프레임워크와 크게 뒤지지 않는다는 의미이다. 이러한 결과는 도구가 대부분 계산을 동일한 버전의 cuDNN 및 cuBLAS(딥러닝 연산을 가속화) 라이브러리로 오프로드하기 때문이다. PyTorch가 다른 프레임워크와 성능 면에서 큰 차이가 없는 이유는, 기본적으로 같은 GPU 가속 라이브러리(cuDNN, cuBLAS)를 사용하기 때문이라는 것 이다.
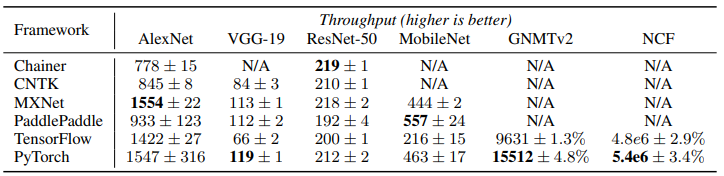
32비트 플로트를 사용하는 6개 모델의 훈련 속도
모델의 경우 초당 이미지 수로, GNMTv2 모델의 경우 초당 토큰 수로, NCF 모델의 경우 초당 샘플 수로 측정되었다. 각 모델에서 가장 빠른 속도는 굵은 글씨로 표시되어있다.
Adoption
다양한 머신 러닝 도구(g Caffe, Chainer, CNTK, Keras, MXNet, PyTorch,
TensorFlow, Theano)가 arXiv e-Prints(학술 논문을 공개적으로 공유하는 온라인 저장소, 학술지에 정식으로 출판되기 전의 버전)에서 얼마나 자주 언급되었는지 집계하여 머신 러닝 커뮤니티가 PyTorch를 얼마나 잘 수용했는지 정량화해 보았다. 딥러닝 프레임워크 중 PyTorch라는 단어의 월별 언급 횟수는 증가하는 것을 볼 수 있다.
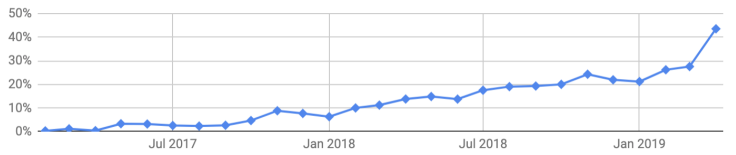
매월 일반적인 딥러닝 프레임워크를 언급하는 arXiv 논문 중 PyTorch를 언급하는 비율이다.
Conclusion and future work
PyTorch는 사용성에 중점을 두고 성능에 대한 세심한 고려를 결합하여 딥러닝 연구 커뮤니티에서 인기 있는 도구로 자리 잡았다. 딥러닝 최신 트렌드와 발전을 지속적으로 지원할 뿐만 아니라, 앞으로도 PyTorch의 속도와 확장성을 지속적으로 개선해 나갈 계획이다. 특히, PyTorch 프로그램을 PyTorch 인터프리터 외부에서 실행하여 더욱 최적화할 수 있는 도구 모음인 PyTorch JIT를 개발하고 있다고 한다. 또한 데이터 병렬 처리를 위한 효율적인 프리미티브와 우너격 프로시저 호출을 기반으로 하는 모델 병렬 처리를 위한 Python 라이브러리를 제공하여 분산 계산에 대한 지원을 개선할 계획이라고 한다.
