Abstract
VX2TEXT는 비디오 기반 텍스트 생성 문제를 다루는 최초의 통합적 접근 방식을 제시합니다. 기존의 텍스트 생성 모델은 주로 이미지 또는 텍스트와 같은 단일 모달리티에 초점을 맞췄으나, 이 연구는 멀티모달 입력(비디오 프레임, 오디오, 텍스트 등)을 활용하여 텍스트를 생성하는 시스템을 구축하는 데 목적이 있습니다.
-
핵심 목표
- 각 모달리티에서 중요한 정보 추출
- 정보를 결합하여 질의에 답변
- 사람이 이해할 수 있는 자연어로 텍스트 생성
-
수학적 토큰화 기법을 통해 다중 입력을 공동 의미 언어 공간에 매핑
- 서로 다른 입력 형태가 동일한 의미를 공유할 수 있도록 하는 것
- 크로스모달 융합 모듈 없이도 언어 공간에서 융합할 수 있다.
-
비분화 가능성 문제 해결
- 비디오나 오디오 같은 연속적인 입력의 토큰화를 위해 relaxation 기법 적용
- 연속적인 입력 데이터는 비분화 가능한 특성을 가짐
- 연속적인 데이터는 이산적 표현운 정수로 표현되어 미분 불가능 -> 역전파 불가능
- 연속적 입력 데이터를 soft token 변환 -> soft token은 학습 중에는 미분이 가능
-
생성 모델 설계
-
기존의 encoder-only models과 달리, autoregressive decoder를 포함하여 텍스트 생성 가능
-
다양한 입력 데이터를 결합해 사람이 이해할 수 있는 텍스트로 결과를 생성
-
encoder-only models
- 입력 데이터를 처리하고 중요한 정보를 추출하여 고정된 표현으로 변환
- 직접적인 텍스트 생성 불가능
-
autoregressive decoder
- 입력 데이터를 한 번에 하나의 토큰씩 순차적으로 텍스트를 생성
- 생성적인 작업이 가능함
-
RelatedWork
-
기존 연구들은 질문 생성 및 재구성을 통한 QA 모델 개선
- 선택형 응답에 국한되어 있어 개방형 텍스트 생성이 어렵다
-
텍스트 생성 연구
- 어텐션 기반 생성 모델을 사용해 대화를 생성했지만, 특화된 크로스모달 블록이 필요
- 멀티모달 데이터 융합을 위한 사전 학습에 의존
차이점
- 사전 학습 불필요
- VX2TEXT는 멀티모달 데이터를 공동 언어 공간에서 융합하여, 별도의 사전 학습 X
- 크로스모달 블록 없이도 간단히 설계로 구현 가능
- 텍스트 생성
- VX2TEXT는 기존의 선택형 응답 방식이 아닌, 디코더 기반 학습으로 질문 답변, 대화, 캡셔닝 같은 텍스트 생성 작업에 성능이 좋다.
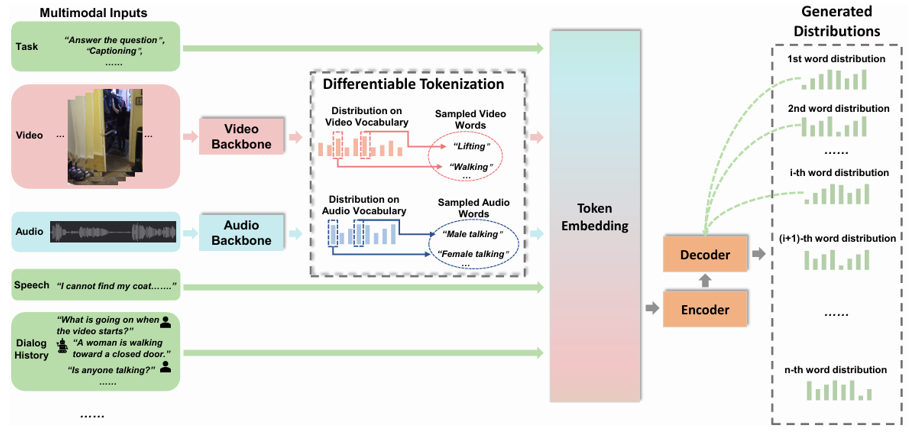
TechnicalApproach
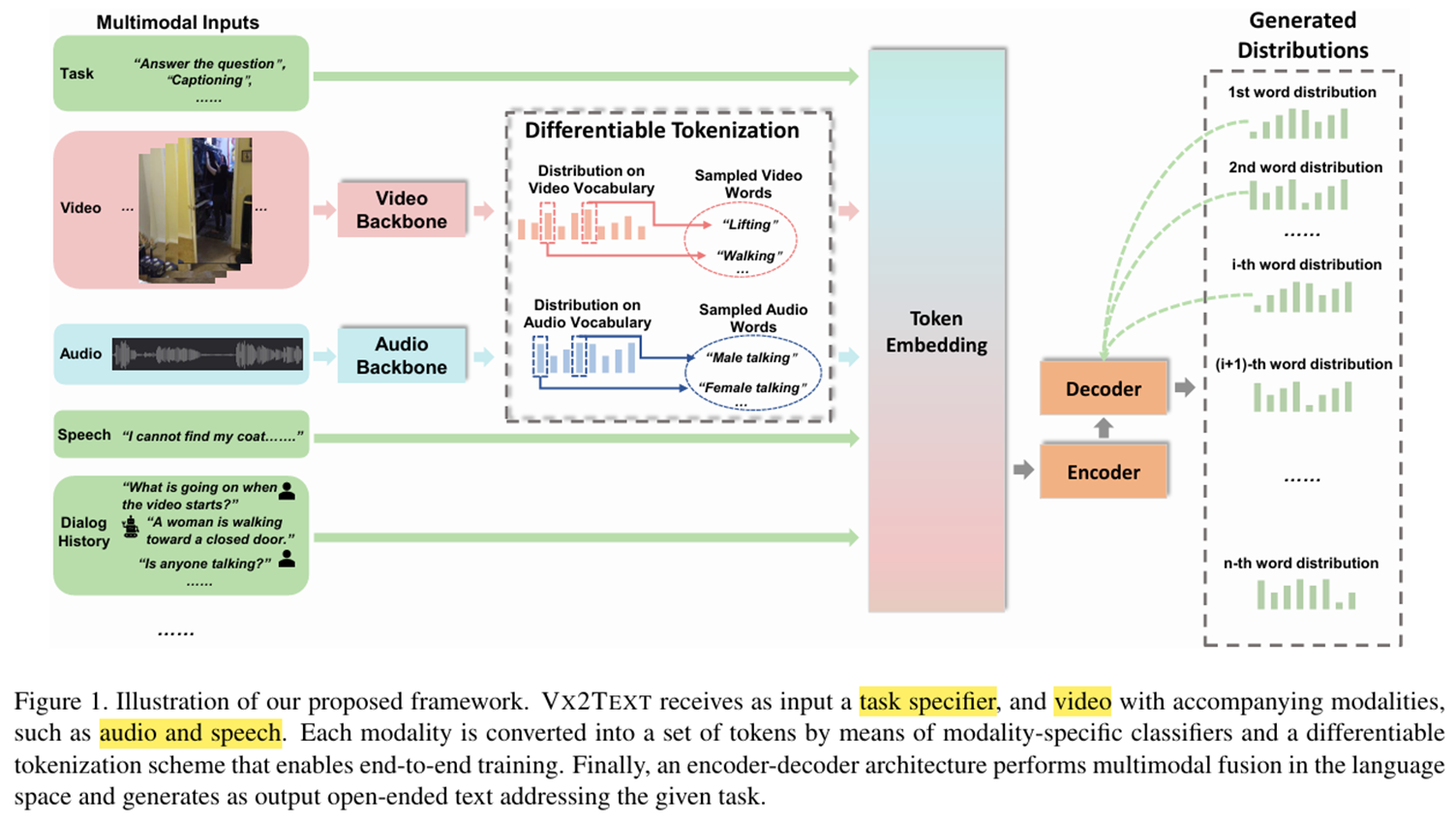
-
Task
- "Answer", "Caption", "Dialog“ 작업 명시 Task 토큰
-
modality-specific
- 사전 학습된 분류기로 각 입력 데이터를 카테고리 확률로 변환
- 비디오 -> 주요 action 카테고리 확률 출력
- 오디오 -> 주요 사운드 카테고리 확률 출력
-
샘플링과 임베딩
- 카테고리 확률 분포에서 상위 k개의 카테고리를 샘플링
- 샘플링된 카테고리를 사전 학습된 언어 모델에 맞게 변환해 공동 언어 공간에 매핑
-
Speech
- CNN14 네트워크(사전 학습된 오디오 분류 모델)를 통해 음성 신호를 카테고리 확률 분포로 변환
-
Dialog History
- 이전에 생성된 대화 내용이나 질문-응답의 히스토리
- 대화 기록은 이미 텍스트 형식으로 주어지므로, 별도의 신호 처리 과정 없이 그대로 언어 모델에 입력
-
Generated distributions
- 샘플링을 확률적으로 수행하여 비분화 가능성 문제 해결
- 샘플링된 결과는 모달리티 간 의미적 연결을 강화하는 임베딩으로 사용됨
Experiments
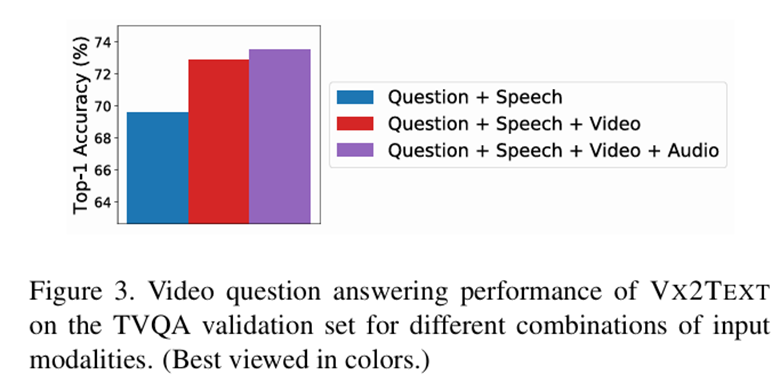
- VideoQuestionAnswering
- TVQA 데이터셋 사용
- TV 드라마의 비디오 클립과 해당 대화 스크립트를 기반으로, 다중 선택형 질문에 답변
- 각 질문에는 5개의 후보 답변이 주어짐
- Audio-Visual Scene-Aware Dialog
- AVSD 데이터셋 사용
- 비디오를 본 사람과 보지 않은 사람 간의 대화를 기반으로 질문-응답을 생성
- VideoCaptioning
- TVC 데이터셋 사용
- 비디오 클립과 해당 대화 스크립트를 기반으로 비디오 내용을 설명하는 텍스트
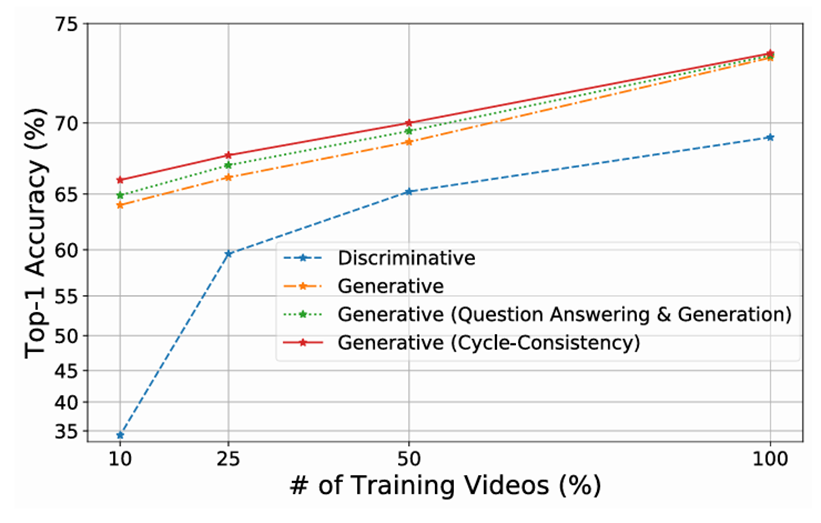
- Discriminative
- 디코더를 제거하고, 인코더에서 추출된 특징 벡터에 분류 헤드를 추가
- 모델은 5개의 후보 답변에 대한 확률 분포를 계산하여, 가장 높은 확률을 가진 답변을 선택
- Generative
- 디코더를 사용해 모델이 직접 텍스트 답변을 생성
- Generative (QA & Generation)
- 주어진 비디오와 질문을 입력으로 받아서 답변을 생성하는 작업
- 비디오 질의 응답(QA):
- 질문을 입력하면 답변을 생성
- 질문 생성:
- 기준 진실 답변(ground-truth answer)을 입력으로 사용해 모델이 질문을 생성
- "The person is cooking dinner" → "What is the person doing in the video?"
- Generative (Cycle-Consistency)
- 질문과 답변 사이의 순환적 일관성을 학습
- 기준 질문 Q → 답변 A′ 생성.
- 생성된 답변 A′ → 새로운 질문 Q′′ 생성.
- 새로운 질문 Q′′ → 새로운 답변 A′′ 생성.
- 최종적으로 A′′와 기준 진실 답변 A 사이의 일관성을 평가.
Conclusions
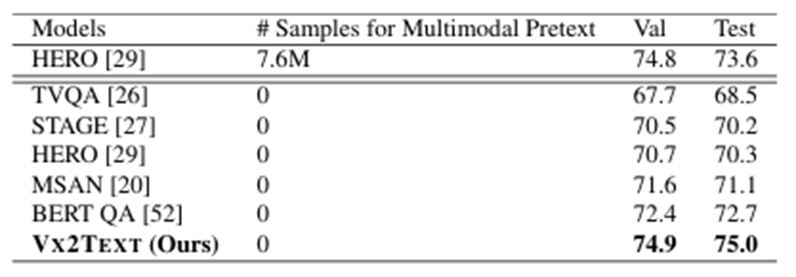
-
VX2TEXT는 추가적인 멀티모달 사전 학습(pretext training) 없이도, 사전 학습에 7.6M 샘플을 사용한 HERO 시스템보다 성능이 우수
-
VX2TEXT는 학습 데이터의 10%만 사용했을 때도 Generative 방식으로 64.1%의 정확도를 기록했고, Discriminative 방식보다 29.9% 더 높은 성능을 보여줌
- Cycle Consistency 학습으로 일관성을 강화해 성능이 더 높아졌기 때문
문제점 정의 및 아이디어(개인 생각)
21년 논문으로 Generation AI가 연구되고 있는 시기에 작성되어 현재에 비해 부족한 점이 있을 것이다. 그렇다고 이 논문이 잘못된 것이 아닌, 이러한 연구가 과거에 진행되었기 때문에 현재의 놀라운 기술발전이 가능했다고 생각한다. 앞으로도 이러한 문제점을 점차 개선해 나가는 것이 나의 Task가 아닐까 생각이 든다.
-
모달리티 간 불일치 처리 부족
- 비디오와 음성 내용이 다를 때 처리하는 기법이 부족
-> 이번 task에서는 360개 데이터라서 직접 라벨링 (플래그 등)
-> 비디오와 텍스트 간의 의미적 유사도를 Cosine Similarity, KL Divergence, 또는 Contrastive Learning으로 측정
-> Cross-Modal Attention: 비디오, 오디오, 텍스트 간 상호작용을 평가하고 불일치를 강조하는 Attention Layer 추가
-> 신뢰 점수 계산을 통한 가중치
- 비디오와 음성 내용이 다를 때 처리하는 기법이 부족
-
분류기의 한계
- R(2+1)D-34, CNN14를 사용하지만, 이들은 고정된 상태로 동작
- 특정 데이터셋에서 최적화되지 않으면, 정보 추출의 정확도가 낮아짐
- Youtube는 게임, 새로운 데이터가 많이 생길 것이기 때문
-> CNN14 feature extractor -> Multi-scale Feature Aggregation과 Temporal -Attention Mechanism을 활용
-> Multi-scale Feature Aggregation: 시간에 따라 다른 이벤트가 발생해 다른 크기의 정보 네트워크의 여러 단계에서 병합
-> Temporal Attention Mechanism: 중요한 순간에 가중치를 부여
-
사전 학습 없어도 높은 성능을 보였지만, 일반화 성능에서 큰 차이를 보일 가능성이 있다.
-> 사전 학습을 추가해 보는 테스트
