✍️ DFS와 BFS를 알아보자
DFS와 BFS(백준 1260)를 보면서 기본적인 개념과 코드를 살펴볼 것이다.
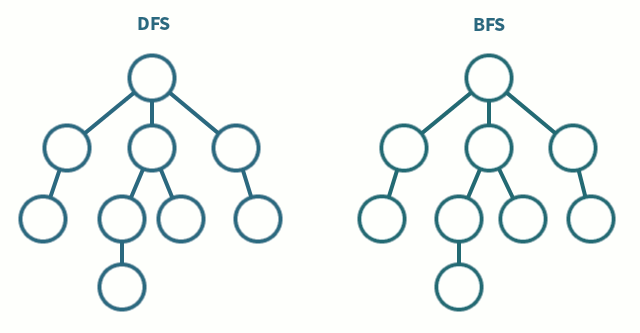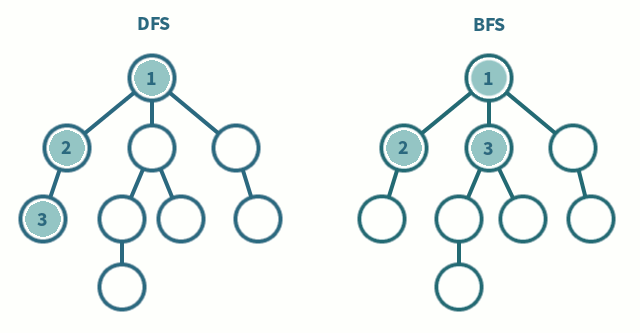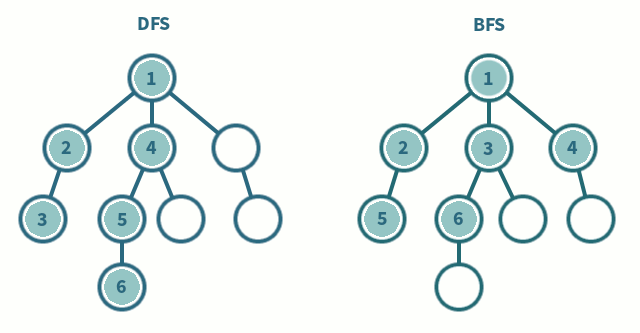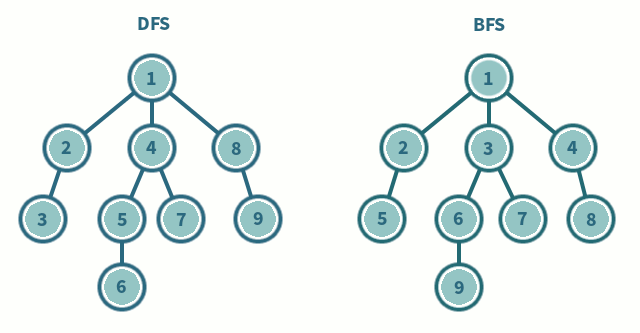
🎯 DFS (Depth First Search)
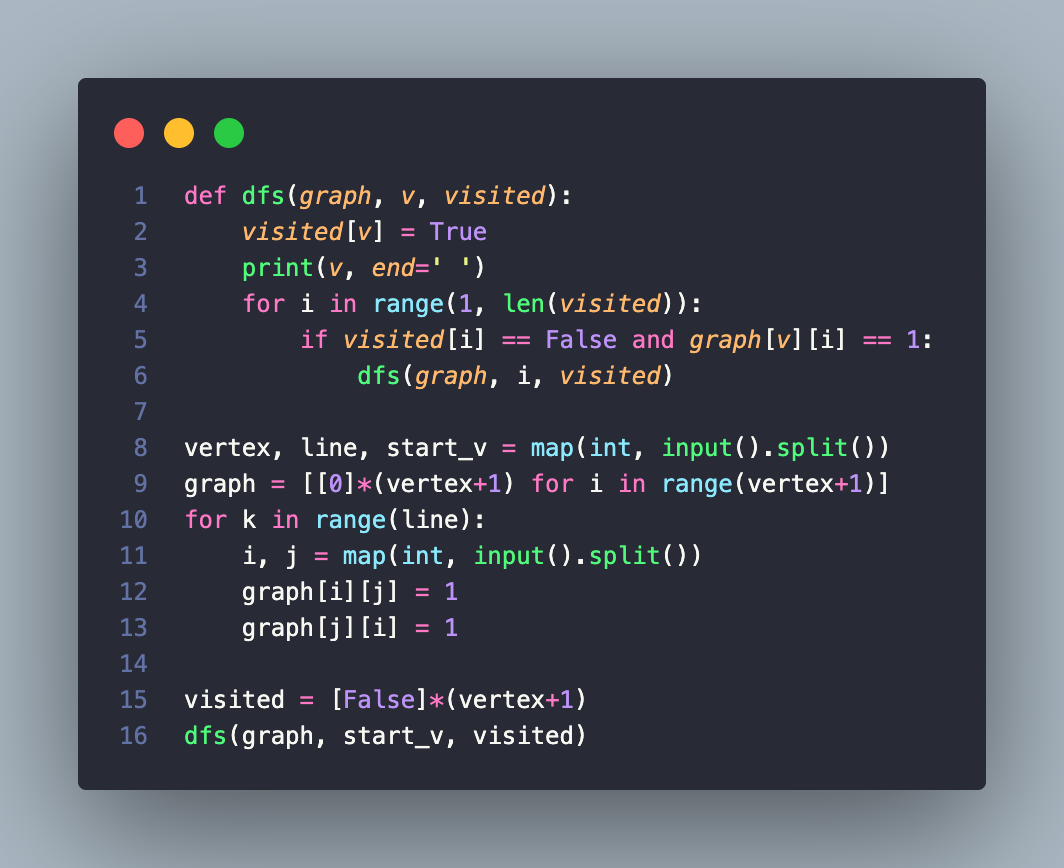
영어의 뜻에서 알 수 있듯이, 깊이 우선 탐색이라고도 부른다. 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘이다. DFS는 스택(stack) 자료구조에 기초한다는 점에서 구현이 간단하다. 실제로는 스택을 쓰지 않아도 되며 탐색을 수행함에 있어서 데이터의 개수가 n개인 경우 O(N)의 시간이 소요된다는 특징이 있다. 나는 스택보다는 재귀함수를 이용하여 푸는 것이 간단하게 구현할 수 있어 재귀함수를 활용했다.
🎯 BFS (Breadth First Search)
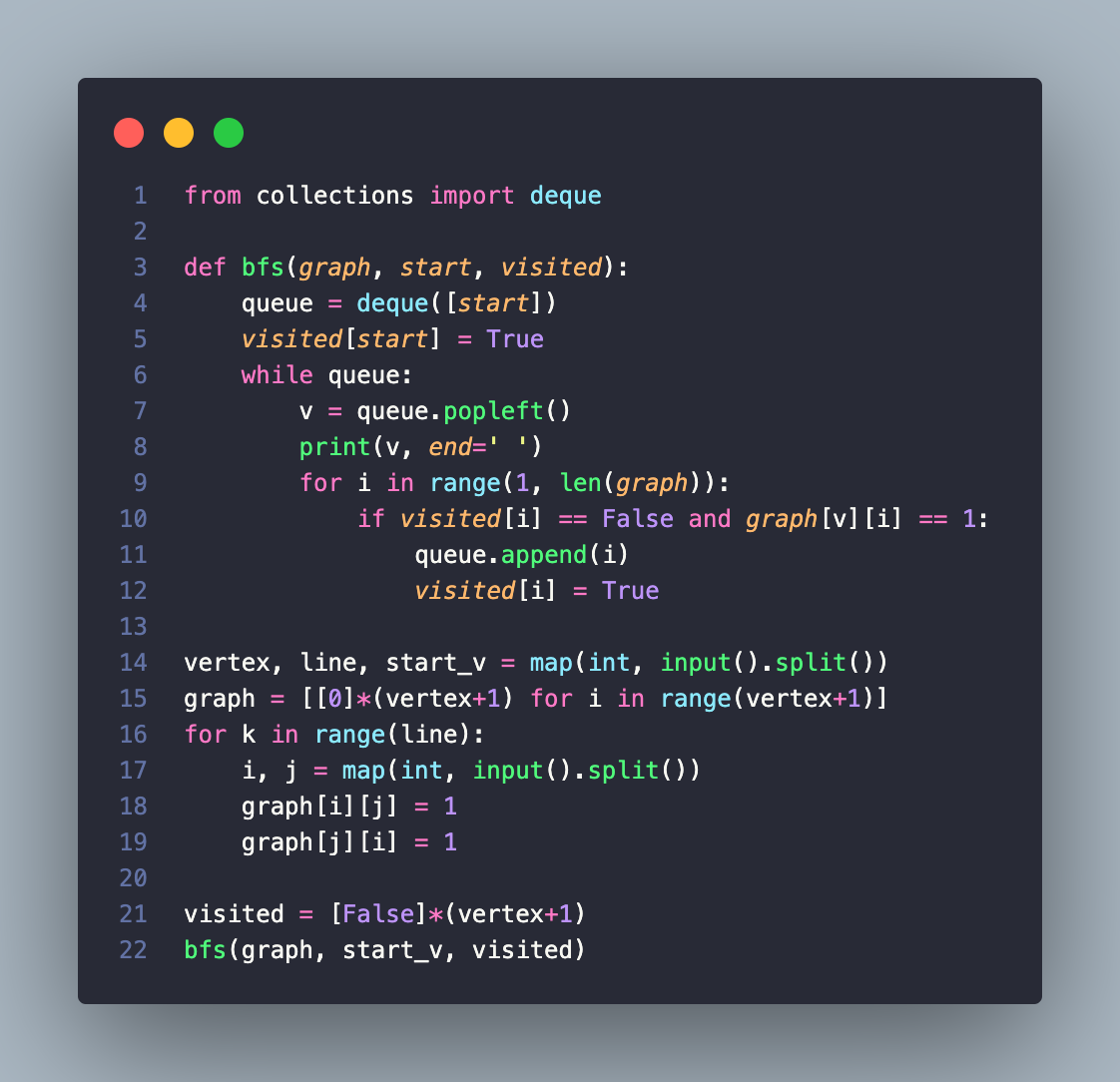
너비 우선 탐색으로, 쉽게 말해 가까운 노드부터 탐색하는 알고리즘이다. BFS 구현에서는 DFS에서 달리 큐(queue) 자료구조를 이용하는 것이 정석이다. 인접한 노드를 반복적으로 큐에 넣도로 알고리즘을 작성하면 자연스럽게 먼저 들어온것이 먼저 나가게 되어, 가까운 노드부터 탐색을 진행하게 된다. 일반적으로 DFS에 비해 수행 시간이 좋은 편이다.

문제를 통해서 DFS와 BFS구현을 알아보자!!!
일단 DFS와 BFS코드를 나누어서 살펴보자
DFS Code
BFS Code
💡 정리
DFS는 재귀함수를 이용하여 깊은 부분을 우선적으로 탐색을 하고, BFS는 큐를 활용하여 가까운 노드부터 탐색을한다. 여러문제를 풀어보면 알겠지만 대부분 기본 코드에서 벗어나지 않고, 조건이나 반복문을 추가하는 방향으로 문제를 풀어나가면 될것이다. DFS와 BFS의 코드만 보고서 서로의 차이를 생각하고 문제를 풀면 런타임에러로 틀리는 경우가 발생한다.
BFS
너비 우선 탐색으로 현재 나의 위치에서 가장 가까운 노드를 먼저 방문하는 것이므로, 미로탐색과 같은 알고리즘은 최단 거리만을 가지고 탈출하는 것이기에 BFS가 적합하다. 왜냐하면 BFS는 현재 노드에서 가까운 곳부터 찾기 때문에 경로를 탐색 시 먼저 찾아지는 해답이 곧 최단거리이기 때문이다.
DFS
하지만 미로를 탐색하는 것에 있어, 이동할때마다 경로의 특징을 저장해둬야 하는 문제(ex/ 각 정점에 숫자가 적혀있고, a부터 b까지 가는 경로를 구하는데 경로에 같은 숫자가 있으며 안된다는 문제 등), 각각의 경로마다 특징을 저장해둬야 할 때는 DFS로 구현하는 것이 좋다. 탐색시간은 더 걸리지만, 가중치에 대한 변수를 지속해서 관리할 수 있다는 장점이 있다.
📌 PLUS
- 검색 대상 그래프가 정말 크다면 DFS로 생각한다.
- 검색대상의 그래프가 크지 않고, 검색 시작 지점으로부터 원하는 대상이 별로 멀지 않다면 BFS를 고려하는 것이 좋다.
