10장. 데이터 모델링과 정규화
- 그동안 데이터베이스의 기본적인 CRUD 작업부터 서브쿼리 활용까지 다양한 개념을 익히고 실습했습니다.
- 지금까지 배운 내용은 주어진 데이터베이스를 분석하고 조작하는 것이었습니다.
- 이 장에서는 마지막으로 현실 세계를 데이터베이스로 옮기는 방법인 데이터 모델링과 이를 검증하는 정규화에 대해 알아보겠습니다.
📗 데이터 모델링
📌 데이터 모델링이란?
- 데이터 모델링(Data Modeling)이란 현실 세계의 어떤 사물이나 현상을 추상화(모형화)해 데이터 간 구조와 관계를 정의한 데이터 모델을 만드는 과정입니다.
- 즉, 데이터 모델링은 데이터를 어떤 구조로 저장하고, 데이터 간 관계는 어떻게 설정할지 등을 정의하는 일입니다.
📌 데이터 모델링의 이점
- 만약 설계도 없이 건물을 짓는다면 어떨까요?
- 아주 간단한 종이집 같은걸 짓는다면 굳이 설계도가 필요없겠지만, 대형 아파트나 큰 건물을 설계도 없이 만들면 워험할 것입니다.
- 데이터베이스도 마찬가지로 무턱대고 테이블 부터 만들면 안됩니다.
- 안전한 건물을 설계하기 위해 설계도 부터 만드는 것 처럼 안정적으로 데이터베이스를 구축하려면 데이터 모델링을 해야합니다.
- 데이터 모델링의 이점은 총 6가지가 있습니다.
1. 비즈니스 요구사항을 반영한다.
- 데이터 모델링은 실제 비즈니스 운영 방식에 맞게 데이터베이스를 설계하는 과정입니다.
- 따라서 비즈니스가 지향하는 목표를 효과적으로 지원합니다.
2. 의사소통 개선에 기여한다.
- 데이터 모델링은 데이터의 구조와 관계를 명확하게 정의하는 과정입니다.
- 여러 비즈니스 관계자들이 프로젝트에 대해 소통할 떄 데이터 모델링을 통해 요구사항이 잘 반영되었는지 공유하고 지속적으로 피드백하는 과정을 통해 불필요한 혼란과 오해를 줄이고 이해관계자들이 같은 방향을 바라보며 협업할 수 있도록 합니다.
3. 데이터 무결성을 보장한다.
- 데이터 모델링은 데이터베이스의 구조와 규칙을 명확히해 데이터 무결성을 보장합니다.
- 데이터 무결성이란 데이터의 정확성, 일관성, 신뢰성을 유지하는 것입니다.
- 데이터 무결성을 유지함으로써 다양한 제약 조건과 규칙을 사용해 데이터의 오류나 왜곡을 방지합니다.
4. 성능을 최적화한다.
- 데이터 모델링은 핵심 데이터를 남기고 무의미한 데이터를 제거함으로써 데이터베이스의 성능을 최적화합니다.
- 성능 최적화란 주어진 컴퓨팅 자원을 이용해 데이터베이스의 응답 속도는 단축시키고, 처리 용량은 증가시키는 것입니다.
5. 유연한 확장이 가능하다.
- 데이터 모델링을 거친 데이터베이스는 추후 시스템을 확장하거나 변화로 인해 구조를 바꿔야 할 때 유연한 확장성을 발휘합니다.
- 데이터 모델링의 맨 처음단계부터 사용자 요구사항에 따라 데이터 모델이 바뀔것을 고려해 설계했기 때문에 이후에도 비즈니스 변화가 발생할때 데이터의 저장구조를 유연하게 조정할 수 있습니다.
6. 비용을 절감한다.
- 데이터 모델링을 통해 초기 설계 단계에서 잠재적인 문제 등을 식별할 수 있고, 해결할 수 있게 해줍니다.
- 따라서 개발 및 운영 단계에서 발생할 수 있는 비용을 절감할 수 있습니다.
📌 데이터 모델링 3단계
- 데이터 모델링은 개념적 모델링, 논리적 데이터 모델링, 물리적 데이터 모델링 3단계를 거쳐 최종 데이터베이스를 구현합니다.
데이터 모델링 3단계
- 개념적 데이터 모델링
- 추상적인 개념 정의- 논리적 데이터 모델링
- 구체적 세부 정의- 물리적 데이터 모델링
- 특정 DBMS로 최적화
1. 개념적 데이터 모델링
- 개념적 데이터 모델링은 현실 세계를 구성하는 주요 개체(entity이하 엔티티)와 그들 간 관계(relation)를 정의하는 단계입니다.
- 요구사항을 분석해 핵심 엔티티를 찾고, 이들 간 관계를 분석해 정의합니다.
- 쇼핑몰 사이트를 예시로 들자면 소핑몰이 운영되는 과정에 참여하는 핵심 엔티티를 사용자, 주문, 결제, 상품으로 뽑고, 이들 간의 관계를 주문하다, 결제하다, 장바구니에 담다로 연결합니다.
- 개념적 모델링을 할 때는 데이터베이스의 기술적인 부분은 고려하지 않습니다.
- 기술 팀, 비즈니스 관계자, 최종 사용자 등 모든 이해관계자가 시스템에 대한 큰 그림을 쉽게 그릴 수 있도록 진행합니다.
2. 논리적 데이터 모델링
- 논리적 데이터 모델링은 개념적 데이터 모델링의 결과로 만들어진 데이터 모델의 세부내용을 정의하는 단계입니다.
- 개념적 모델링이 무엇을 만들까?에 집중했다면 논리적 데이터 모델링은 어떻게 만들까?를 고민하는 단계입니다.
- 앞서 만든 뼈대에 살을 붙이는 과정이라 생각하면 좀 더 이해하기 쉽습니다.
- 이 단계에선 엔티티의 속성, 식별자, 관계의 유형을 정의하며, 데이터의 중복을 제거하고 데이터베이스 운영의 효울성을 높이기 위해 정규화를 진행합니다.
- 논리적 데이터 모델링은 특정 DBMS에 종속되지 않고 반복적인 검증을 통해 개선해 나가는 방식으로 수행합니다.
- 이를 위해 데이터베이스를 구축하는 기술 팀뿐만 아니라 비즈니스 관계자, 최종 사용자 간 지속적인 피드백이 필요합니다.
- 데이터 간의 관계를 지정하는 과정에선 E-R다이어그램(ERD)이 사용됩니다.
3. 물리적 데이터 모델링
- 물리적 데이터 모델링은 논리적 데이터 모델링의 결과로 만들어진 데이터 모델을 특정 DBMS에 맞게 최적화하는 단계입니다.
- 개념적 데이터 모델링과 논리적 데이터 모델링이 비즈니스 관점에서 무엇을 어떻게 만들까?에 초점을 맞췄다면, 물리적 데이터 모델링은 높은 성능과 적은 비용으로 어떻게 구현할까?에 초점을 둔 모델입니다.
- 물리적 데이터 모델링은 데이터베이스의 물리적 저장 방식, 접근 방식, 성능 등을 고려해 최적의 세부사항(테이블명, 칼럼명, 기본키, 외래키, 자료형, 제약조건 등)을 설계합니다.
- 건축 설계를 예로 들면 건물 내 기자재를 사용자 동선을 고려해 최적의 장소에 배치하는 것, 창문을 채광이 잘 드는 곳에 설치하는 것 등이 물리적 데이터 모델링과 같다고 볼 수 있습니다.
📗 데이터 모델의 구성 요소
📌 엔티티(Entity)
- 엔티티란 데이터베이스에서 관리하려는 핵심 대상으로 비즈니스에서 실제로 존재하거나 개념적으로 중요한 것을 모형화한 것입니다.
- 예를 들어 쇼핑몰 데이터베이스의 엔티티는 사용자, 상품, 주문 등이 있습니다.
- 엔티티와 연관된 용어로 테이블과 인스턴스가 있습니다.
테이블(table)
- 엔티티를 실제 데이터베이스에 구현한 것
- 행과 열의 표 형태임
- 실제 모델 = 엔티티
- 물리 구현 모델 = 테이블
인스턴스(instance)
- 엔티티의 실제 데이터
- 테이블에 저장된 행 단위의 전체 데이터를 말함
- 테이블 하나의 모든 튜플들을 인스턴스라고 부름
📌 속성(Attrubute)
- 속성은 엔티티의 특성이나 정보를 나타내는 항목입니다.
- 여러 속성이 모여 하나의 엔티티를 구성합니다.
- 예를 들어 사용자, 상품, 주문 엔티티는 다음과 같은 속성을 가지며, 이러한 속성을 통해 다른 엔티티와 구분됩니다.
엔티티의 속성
- 사용자 엔티티의 속성 : ID, 이메일, 이름
- 상품 엔티티의 속성 : ID, 상품명, 가격, 상품 유형
- 주문 엔티티의 속성 : ID, 주문 상태, 주문 일시, 사용자ID
- 속성과 연관된 용어로 칼럼(column)이 있습니다. 속성을 실제 데이터베이스에 구현하면 테이블의 칼럼이 됩니다.
- 실제 모델 : 속성
- 물리 구현 모델 : 칼럼
📌 식별자
- 속성 중 조금 특별한 속성으로 식별자가 있습니다.
- 식별자(identifier)는 엔티티의 각 인스턴스를 고유하게 식별하는 데 사용하는 속성 또눈 속성의 조합입니다.
- 속성이 식별자로 사용되기 위해서는 다음 4가지 조건을 만족해야 합니다.
속성이 식별자가 되기 위한 4가지 조건
1. 유일성
- 모든 인스턴스를 구분할 수 있도록 중복되지 않은 고유한 값을 가져야함
2. 불변성
- 값이 한 번 정해지면 다시 바뀌지 않아야함
3. 존재성
- 값은 반드시 존재해야함(NULL이 되어선 안됨)
4. 최소성
- 엔티티의 모든 인스턴스를 구분하기 위해 필요한 최소한의 속성으로 구성되어야함
- 입문 단계에서 필수로 알아야 할 식별자는 기본 식별자, 대체 식별자, 외래 식별자 정도를 알아야 합니다.
식별자 종류(일부)
1. 기본 식별자(기본 키)
- 엔티티 내 모든 인스턴스를 고유하게 식별하는 속성 또는 속성의 조합
- 값이 반드시 존재
- 값이 반드시 유일해야함
- 대체 식별자(후보 키)
- 기본 식별자로 선택되지 않은 후보 식별자
- 대체 식별자도 식별자이므로 값이 반드시 존재하고 유일해야함
- EX) 사용자 엔티티의 이메일
- 외래 식별자(외래 키)
- 한 엔티티의 식별자가 다른 엔티티의 식별자를 참조해 관계를 만드는 식별자
- 위에서도 키라는 단어를 붙였는데 식별자 = 키라고 보면 됩니다.
- 식별자는 현실세계에서 칭하는 용어고, 키는 물리 모델링에 사용되는 용어입니다.
- 실제 모델 : 식별자
- 물리 구현 모델 : 키
📌 관계
- 관계란 두 엔티티 간 연결된 방식을 나타내는 것입니다.
- 관계를 설명할 때 카디널리티(cardinality)라는 개념을 사용합니다.
- 카디널리티란 엔티티의 한 인스턴스가 다른 엔티티의 몇 개 인스턴스와 연결되는지를 나타냅니다.
- 관계는 카디널리티가 하나냐 여럿이냐에 따라 다음 3가지로 나뉩니다.
1. 일대일 관계
- 엔티티의 한 인스턴스가 상대 엔티티의 한 인스턴스와만 연결되는 관계
- 주로 사용빈도가 낮은 테이블에 외래키를 둠
2. 일대다 관계
- 엔티티의 한 인스턴스가 상대 엔티티의 여러 인스턴스와 연결되는 관계
- '다' 쪽 테이블에 외래키를 둠
3. 다대다 관계
-
두 엔티티 A와 B가 있을떄 A의 한 인스턴스가 B의 여러 인스턴스와 연결될 수 있고, 반대로 B의 한 인스턴스가 A의 여러 인스턴스와 연결될 수 있는 관계
-
중간 테이블을 만들어 양쪽 테이블의 기본키를 가져와 외래키로 사용
-
관계를 실제 데이터베이스에서 구현할 때는 기본키와 외래키의 참조를 통해 구현합니다.
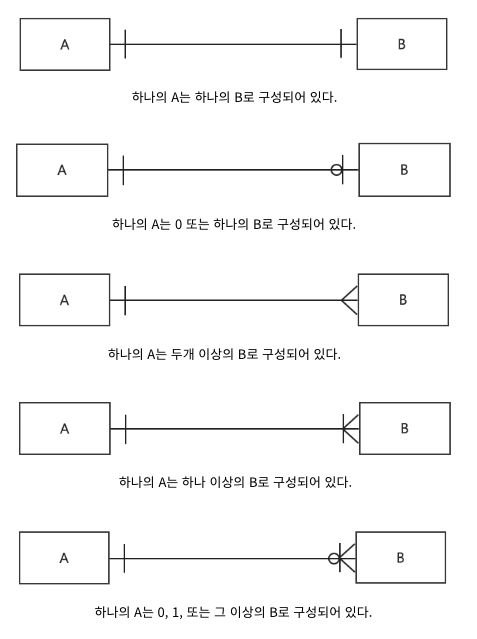
📌 ER 다이어그램
- ER 다이어그램(Entity-Relationship Diagram, ERD)은 데이터 모델을 정의하는 시각적 도구로, 엔티티, 속성, 관계를 기호로 그린 것입니다.
- ER 다이어그램에서 엔티티는 사각형, 속성은 엔티티 내부의 텍스트, 관계는 직선으로 나타냅니다.
- 특히 직선에는 관계의 카디널리티도 표시하는데, 카디널리티가 하나일 경우에는 직선 끝에 수직선을 그리고, 다수일 경우에는 직선 끝에 까치발 모양을 그립니다.
선택성(Optionality)
- ER 다이어그램에서 관계는 카디널리티뿐만 아니라 선택성도 나타낼 수 있습니다.
- 선택성이란 관계에 참여하는 엔티티가 선택적으로 관계를 맺을 수 있는지 아니면 필수로 관계를 맺어야 하는지를 나타내는 개념입니다.
- 선택적으로 관계를 맺을 수 있다면 선택적 관계, 필수로 관계를 맺어야 한다면 필수적 관계라고 합니다.
선택적 관계와 필수적 관계
선택적 관계
- 카디널리티가 0부터 시작하며, 관계를 나타내는 직선에 원(O)를 추가해 나타냄
필수적 관계
- 카디널리티가 1부터 시작하며, 관계를 나타내는 직선에 수직선(|)을 추가해 나타냄
- 관계의 선택성은 다음과 같이 구현됩니다.
- 선택적 관계 구현 : 아무런 설정을 하지 않음
- 필수적 관계 구현 : 두 엔티티 간에 관계를 맺기 위해 사용한 외래키에 값이 반드시 입력되도록 NOT NULL 제약 조건을 설정해야함
📗 데이터 모델링 실습 : 쇼핑몰 DB
- 모델링 실습은 책의 내용을 확인하는걸로 하고, 실습과정에서 나오는 개념에 대해 정리하고 가겠습니다.
📌 인덱스(Index)
- 인덱스는 데이터베이스에서 검색 및 정렬 성능을 최적화하는 데이터구조입니다.
- 테이블 전체를 스캔하지 않아도 인덱스를 통해 데이터를 효율적으로 찾을 수 있도록 해줍니다.
- MySql 같은 경우엔 PK(Primary Key), UK(Unique Key), FK(Foreign Key)에 자동으로 인덱스를 생성합니다.
- 만약 인덱스를 직접 생성하려면 CREATE INDEX문을 사용하거나 테이블을 생성할 때 INDEX 키워드로 특정 칼럼에 인덱스 처리를 합니다.
CREATE INDEX 인덱스명 ON 테이블명 (칼럼명);CREATE TABLE 테이블명(
칼럼명1 자료형1,
칼럼형2 자료형2,
...
INDEX 인덱스명 (칼럼명1)
);- 인덱스를 많이 생성하면 그만큼 많은 저장 공간이 필요해 비용이 듭니다.
- 따라서 자주 조회하거나 자주 정렬하는 칼럼에만 인덱스를 생성하는 것이 좋습니다.
CHECK 제약조건
- 속성을 설정할때 CHECK 키워드를 통해 해당 속성에 대한 더 상세한 조건을 표기할 수 있습니다.
- CHECK문 뒤에 비교연산자 등으로 해당 칼럼에 들어갈 수 있는 조건을 상세히 설정할 수 있습니다.
- 이전의 글에 나온적 있는 키워드지만 제가 까먹어서 다시 적습니다 😅
CREATE TABLE 테이블명(
칼럼명1 칼럼_타입 CHECK (조건문)
)📗 정규화
📌 정규화란?
- 정규화(normalization)란 데이터 모델링을 할 때 데이터가 중복으로 저장되는 것을 최소화하고 데이터 무결성을 보장하기 위해 데이터를 구조화하는 작업입니다.
- 정규화 과정은 총 3단계로 나뉩니다(정처기는 6단계 까지 있던데)
정규화 과정
제 1 정규형(1NF)
- 각 속성은 원자값(더 이상 분해할 수 없는 값)을 가져야 함
- 같은 속성이라면 모두 동일한 자료형을 가져야 함
- 각 인스턴스는 고유해야함
제 2 정규형(2NF)
- 제 1 정규형을 만족해야함
- 기본키가 아닌 일반 속성은 기본키의 전체 속성에 의해 결정되어야 함
제 3 정규형(3NF)
- 제 2 정규형을 만족해야 함
- 기본키가 아닌 일반 속성은 다른 일반 속성에 의해 결정되지 않아야 함
- 정규형은 이 외에도 보이스-코드 정규형, 제 4 정규형, 제 5 정규형이 더 있지만 제 3 정규형 까지만 지켜도 충분히 올바른 설계라 할 수 있습니다.
📌 이상 현상
- 만약 테이블을 정규형에 따르지 않고 설계를 하면 이상 현상이 발생할 수 있습니다.
- 이상 현상이란 테이블 설계가 잘못됐거나 비효율적일 때 발생하는 문제로, 테이블에 데이터를 삽입, 삭제, 수정할 때 비정상적인 결과가 나오는 것을 말합니다.
📌 제 1 정규형
- 제 1 정규형의 핵심은 속성 값의 원자화입니다.
- 속성을 더 이상 분해할 수 없을 때까지 잘게 나눠야 한다는 것입니다.
📌 제 2 정규형
- 제 2 정규형의 핵심은 부분 함수 종속을 제거하는것 입니다.
- 이는 기본키가 아닌 일반 속성이 기본키를 구성하는 전체 속성에 의해 결정되지 않으면 해당 일반 속성을 다른 테이블로 분리하라는 뜻입니다.
- 완전 함수 종속 : 일반 속성이 기본키 전체에 종속된 경우
- 부분 함수 종속 : 일반 속성이 기본키의 일부에만 종속된 경우
📌 제 3 정규형
- 제 3 정규형의 핵심은 이행적 함수 종속을 제거하는 것입니다.
- 쉽게 말해 기본키가 아닌 일반 속성에 의해 결정되는 또 다른 일반 속성이 있다면 이를 별도의 테이블로 나누는 것입니다.

frontend개발자가 되기 위해 노력합니다.